深入探讨关于Redis的底层
1.1为什么Redis存储比关系型数据库快:
数据存储在内存中(比如企业项目中用户表中有一个亿的用户,如果再来注册一个用户,或者登录,必须先判断是否有这个数据,这个时候如果直接查询数据库的话,对服务器的压力是非常大的,而且返回的数据效率也不高,因为关系型数据库是将数据保存到磁盘中去的,这里又要考虑到网路传输的速度,所以直接查询Redis存储比较好)
单线程处理请求
高效的数据结构
异步 I/O
高效的持久化机制
1.2Redis存储具有的特定功能:
缓存:Redis 可以作为缓存系统,将热点数据存储在内存中,提高读写性能和响应速度,减少对后端数据存储的压力。
消息队列:Redis 的发布订阅功能和 List 数据结构可以实现消息队列的功能,实现异步处理任务、解耦系统组件之间的依赖关系等。
为什么使用消息队列:
【回答:1.业务解耦,2实现异步,3.流量削峰填谷(时间换空间)
消息队列:
?? ?同步:
?? ??? ?优点:时效性 强,立即得到结果
?? ??? ?缺点:1.耦合度高(加业务导致改代码困难)
、? ? ? ? ? ? ? ? 2.性能:每次执行调用需要等待上一个进程走完之后才进行
?? ??? ??????????? 3.cpu资源浪费,等待需要执行后再执行
?? ??? ????????????4.练级失败,一个服务或者进程甭溃,会导致集体阵亡
?? ?异步:
?? ??? ?优点:1.降低耦合度,2.cpu资源运用合理,3.流量削峰填谷(时间换空间)
?? ??? ?缺点:效率没有同步高】
计数器和排行榜:Redis 的原子操作和 Sorted Set 数据结构可以实现计数器和排行榜的功能,支持快速地增加、减少和排序操作。
消息队列模型:
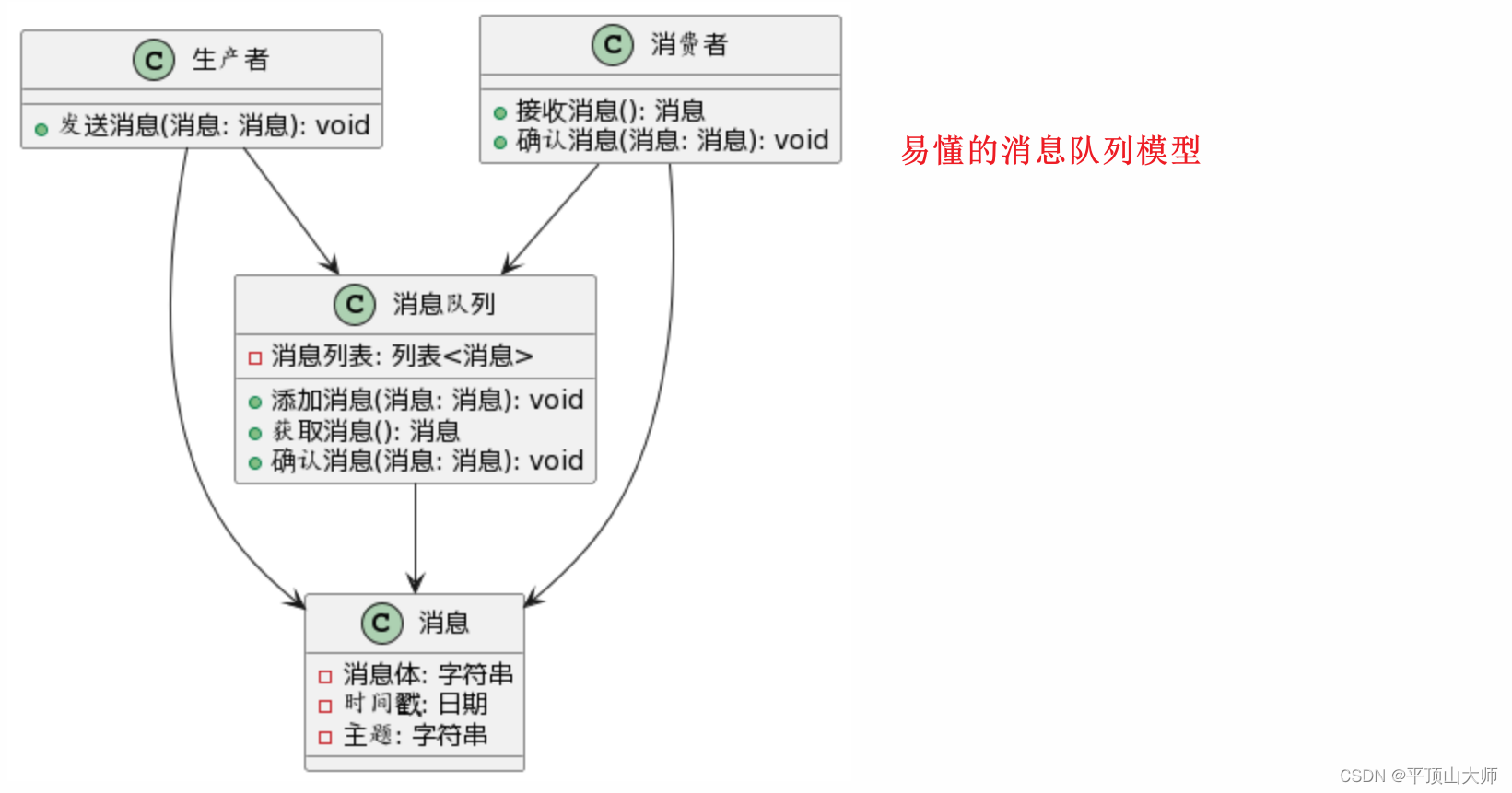
生产者(Producer)、消费者(Consumer)、消息(Message)和消息队列(MessageQueue)。生产者和消费者类负责将消息发送到消息队列和从消息队列中获取消息。消息类包含消息主体、时间戳和主题等信息。消息队列类负责存储消息列表,并提供添加、获取和确认消息的方法。
生产者和消费者类与消息类之间是一对一的关系,表示一个生产者或消费者可以与一个消息相关联。生产者和消费者类与消息队列类之间是一对多的关系,表示一个生产者或消费者可以与多个消息队列相关联。消息队列类与消息类之间是一对多的关系,表示一个消息队列可以包含多个消息。
1.3Redis存储数据类型:
- String(字符串类型)常见使用场景是:存储 Session 信息、存储缓存信息(如详情页的缓存)、存储整数信息,可使用 incr 实现整数+1,和使用 decr 实现整数 -1;
- List(列表类型)常见使用场景是:实现简单的消息队列、存储某项列表数据;
- Hash(哈希表类型)常见使用场景是:存储用户,Session 信息、存储商品的购物车,购物车非常适合用哈希字典表示,使用人员唯一编号作为字典的 key,value 值可以存储商品的 id 和数量等信息、存储详情页信息;
- Set(集合类型)是一个无序并唯一的键值集合,它的常见使用场景是:关注功能,比如关注我的人和我关注的人,使用集合存储,可以保证人员不会重复;
- Sorted Set(有序集合类型)相比于 Set 集合类型多了一个排序属性 score(分值),它的常见使用场景是:可以用来存储排名信息、关注列表功能,这样就可以根据关注实现排序展示了。
1.4Redis在使用中常见的三种问题:
雪崩(Cache Avalanche):雪崩是指当缓存系统中的大量缓存同时失效或清空时,请求将直接访问数据库,导致数据库压力骤增,性能急剧下降。这种情况可能发生在缓存过期时间设置不合理、服务器宕机、网络故障等情况下。为了避免雪崩效应,可以采取的措施包括合理设置缓存的过期时间、使用分布式缓存、通过多级缓存策略等。
穿透(Cache Penetration):穿透是指恶意请求或者非法请求绕过缓存直接访问数据库,由于缓存中不存在相应的数据,导致请求一直到达数据库。这种情况可能发生在攻击者故意构造不存在的数据进行请求,如果没有有效的防护措施,会导致数据库负载过高。为了避免穿透,可以在缓存层设置布隆过滤器或者简单的缓存空结果,来过滤无效请求。
击穿(Cache Breakdown):击穿是指在高并发情况下,某个热点数据过期后,大量请求同时访问数据库,导致数据库压力过大。与雪崩不同的是,击穿通常是由于某个特定的缓存项失效引起的,而其他缓存项仍然有效。为了避免击穿,可以采取的措施包括使用锁机制(例如分布式锁)来实现热点数据的单线程访问、及时更新缓存数据等。
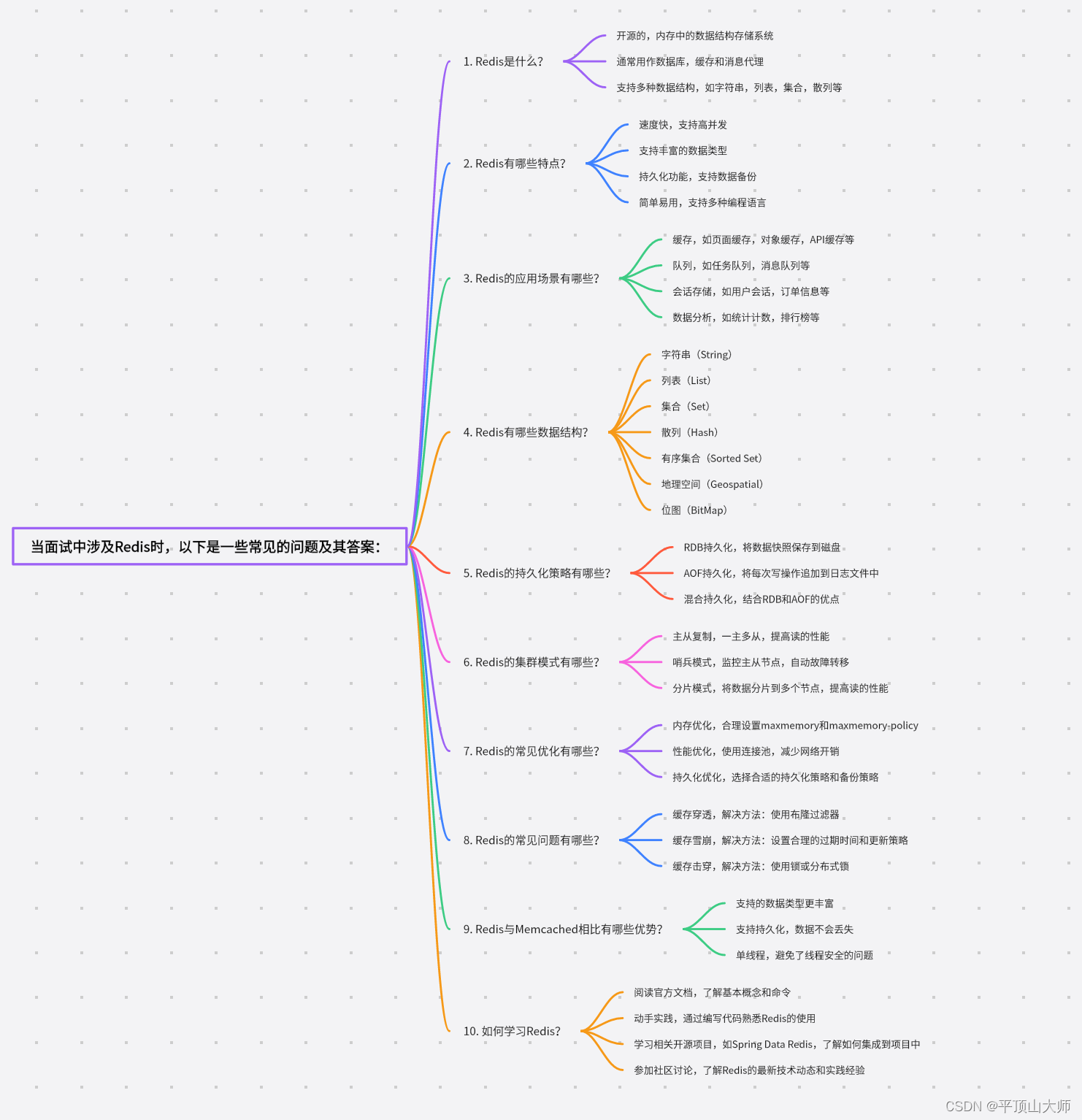
1.4总结图
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 基于ssm企业人事管理系统的设计与实现论文
- 36、什么是池化算法
- Transformer and Pretrain Language Models3-1
- 【已解决】浏览器小化或者切换标签,倒计时不准确解决方案
- 使用poco2 UI自动化测试框架编写一套电商全流程自动化测试!
- docker部署jenkins,发布任务执行scp免密传输
- LLM Agent零微调范式 ReAct & Self Ask
- 用户行为分析-小数据集
- MySQL所有常见问题
- 16k+ start 一个开源的的监控系统部署教程