用通俗易懂的方式讲解大模型:LangChain 知识库检索常见问题及解决方案
在之前的文章中,我们介绍了如何使用 LangChain 打造一个垂直领域的知识库问答系统。知识库问答系统包含了一系列的功能,包括:文档载入、文档分隔、文档 Embedding、文档存储、文档检索、组合问题上下文等。
在实际使用的过程中,每个环节都可能遇到一些复杂的问题,今天我们就来看看在实际应用中,LangChain 在进行知识库检索时会遇到的一些问题以及解决方案。
重复文档问题
在使用 LangChain 打造的知识库系统时,我们首先要进行知识库文档的上传,在上传文档的过程中有时候会上传一些重复内容的文档(文件名不同,内容相同),或者是上传一些类似的文档(文件名不同,内容不同),这些文档会导致我们的知识库中存在大量的重复文档,这些重复文档会影响我们的知识库检索效果。
举个例子,比如我们想收集用户评价中反馈最多的 10 类评价,这类评价有:非常好,很好,很好用,安装非常方便,用户体验很好,界面简洁等等,这些评价中有些评价是十分相似的,比如非常好和很好,很好用和用户体验很好,我们希望在收集的评价中可以听到尽可能多的声音,以便我们可以对系统进行改进,但相似的评价会阻碍我们看到更多不同的反馈。
下面再举一个具体的代码示例,假设我们用几个简单的句子来代替文档,比如有下面三个文档。
texts = [
"""见手青被触碰后菌肉迅速变蓝的食用菌。""",
"""见手青其菌肉遭受伤害后会快速变成蓝绿色。""",
"""见手青未煮熟或食用过量可能会导致中毒。"""
]
我们可以看到这三个文档的内容虽然是不同的,但是有些文档内容极其相似,比如第一个和第二个文档。如果我们使用普通的检索功能,检索出与问题最相关的 2 个文档,那么第一个和第二个文档都会被检索出来。
from langchain.vectorstores import Chroma
from langchain.embeddings.openai import OpenAIEmbeddings
persist_directory = 'docs/demo_mmr/'
embedding = OpenAIEmbeddings()
vectordb = Chroma(
persist_directory=persist_directory,
embedding_function=embedding
)
smalldb = Chroma.from_texts(texts, embedding=embedding)
question = "告诉我关于见手青的信息。"
smalldb.similarity_search(question, k=2)
# 输出
"""
[Document(page_content='见手青其菌肉遭受伤害后会快速变成蓝绿色。', metadata={}),
Document(page_content='见手青被触碰后菌肉迅速变蓝的食用菌。', metadata={})]
"""
这里我们使用Chroma来做向量存储,使用 OpenAI 的 Embedding 来做文档 Embedding(注意:如果想实际运行代码,需要在环境变量中设置 OpenAI 的 API Key)。 然后我们使用similarity_search来进行检索,这里我们检索出与问题最相关的 2 个文档,可以看到第一个和第二个文档都被检索出来了。 如果将这两个文档结合问题一起发给大语言模型(LLM),得到的答案可能会过于片面,我们希望能结合更多不同内容的文档来进行答案的生成。
技术交流
建了大模型技术交流群! 想要学习、技术交流、获取如下原版资料的同学,可以直接加微信号:mlc2060。加的时候备注一下:研究方向 +学校/公司+CSDN,即可。然后就可以拉你进群了。
方式①、微信搜索公众号:机器学习社区,后台回复:加群
方式②、添加微信号:mlc2060,备注:来自CSDN + 技术交流

解决方案
在 LangChain 的官方文档中介绍了如何使用最大边际相关性(Maximal Marginal Relevance,简称为 MMR)来解决重复文档的问题。
MMR 是一种广泛应用于信息检索和自然语言处理领域的算法。MMR 的主要目标是在文档排序和摘要生成等任务中平衡相关性和新颖性。换句话说,MMR 旨在为用户提供既相关又包含新信息的结果。MMR 的基本思想是在选择下一篇要呈现给用户的文档时,不仅要考虑其与查询的相关性,还要考虑其与已经呈现给用户的文档之间的相似性。如果一篇文档与查询非常相关,但与已经呈现给用户的文档非常相似,那么这篇文档的边际收益可能就不大。通过这种方式,MMR 算法可以生成一个既包含相关信息又包含新信息的结果列表,从而帮助用户在大量信息中找到他们真正需要的信息。
在 LangChain 中我们可以用 vectordb 对象中的max_marginal_relevance_search来进行 MMR 检索。
smalldb.max_marginal_relevance_search(question, k=2, fetch_k=3)
# 输出
"""
[Document(page_content='见手青其菌肉遭受伤害后会快速变成蓝绿色。', metadata={}),
Document(page_content='见手青未煮熟或食用过量可能会导致中毒', metadata={})]
"""
这里的fetch_k参数表示在进行 MMR 检索时,每次从 vectordb 中取出多少个文档进行计算,然后再从中选择最相关的文档。这里我们设置为 3,表示每次从 vectordb 中取出 3 个文档进行计算,然后再从中选择最相关的文档。这里我们可以看到,第一个和第三个文档被检索出来了,第二个文档没有被检索出来,这是因为第二个文档与第一个文档的相似度太高,所以在进行 MMR 检索时,第二个文档被过滤掉了。
多维检索条件错误
在使用知识库进行提问时,系统除了会根据知识库内容进行回答,还会说明引用了知识库中的哪些文档,常见的引用信息有文件的文件名和引用内容的行数。但是在实际应用中,我们可能会遇到一些错误的引用。
比如我们的知识库有 2 个文档,分别是2022年高评分电影 和 2023年高评分电影,这两个文档包含了两个年份的电影信息,如果我们提问:请帮我找XX导演的,在2023年上映的电影,那么系统返回的引用文档中,可能既包含了2023年高评分电影,也包含了2022年高评分电影,因为 2022 年的文档中也包含了该导演的电影,这样的引用信息就是错误的。
我们再用代码示例来说明这个问题。
from langchain.schema import Document
all_docs = [
Document(page_content="通过九儿与余占鳌的爱情故事,描述了1930年代中国北方农村的生活景象,展示了人性的激情与冷酷。", metadata={"year": 1987, "rating": 8.2, "genre": "剧情", "director": "张艺谋", "name": "红高粱"}),
Document(page_content="描述了在戏曲舞台上与幕后生活中,程蝶衣、段小楼两位'京剧人'半个世纪的悲欢离合,是一部跨越五十年的人性史诗。", metadata={"year": 1993, "director": "陈凯歌", "rating": 9.5, "genre": "剧情", "name": "霸王别姬"}),
Document(page_content="一个关于复仇,爱情,自我牺牲和道德责任的故事,融合了武侠动作和浪漫剧情元素,被誉为是现代武侠电影的杰出代表。", metadata={"year": 2000, "director": "李安", "rating": 8.8, "genre": "动作", "name": "卧虎藏龙"}),
Document(page_content="描绘了一段充满讽刺和黑色幽默的中国西南地区的权力斗争,全片充满了荒诞和激进的政治讽刺。", metadata={"year": 2010, "director": "姜文", "rating": 8.5, "genre": "剧情", "name": "让子弹飞"}),
Document(page_content="描述了地球面临毁灭,人类联合构建地球发动机,推动地球离开太阳系,展现了人类对未知宇宙的探索和对生存的渴望。", metadata={"year": 2019, "director": "郭帆", "rating": 7.9, "genre": "科幻", "name": "流浪地球"}),
Document(page_content="根据真实事件改编,中国特警队在湄公河流域的金三角地带进行卧底行动,破获一个特大毒品案件,表现了中国警察的决心和勇气。", metadata={"year": 2016, "rating": 8.0, "director": "林超贤", "genre": "动作", "rating": 8.0, "name": "湄公河行动"})
]
假设我们有以上这些文档内容,每个文档是一部电影信息的信息,在这里我们使用 LangChain 的 Document 对象来存储电影信息,其中page_content字段存储电影的简介,metadata字段存储电影的其他信息,比如电影的年份、导演、评分、类型等。
然后我们再用 LangChain 中的普通方法进行检索。
from langchain.vectorstores import Chroma
from langchain.embeddings.openai import OpenAIEmbeddings
embedding = OpenAIEmbeddings()
persist_directory = 'docs/demo_sq/'
vectordb = Chroma.from_documents(
documents=all_docs,
embedding=embedding,
persist_directory=persist_directory
)
question = "请帮我推荐一些剧情类电影"
docs = vectordb.similarity_search(question, k=2)
# 输出
"""
[Document(page_content='一个关于复仇,爱情,自我牺牲和道德责任的故事,融合了武侠动作和浪漫剧情元素,被誉为是现代武侠电影的杰出代表。', metadata={'year': 2000, 'director': '李安', 'rating': 8.8, 'genre': '动作', 'name': '卧虎藏龙'}),
Document(page_content='描绘了一段充满讽刺和黑色幽默的中国西南地区的权力斗争,全片充满了荒诞和激进的政治讽刺。', metadata={'year': 2010, 'director': '姜文', 'rating': 8.5, 'genre': '剧情', 'name': '让子弹飞'})]
"""
我们可以看到,使用普通的方法进行检索剧情类电影,返回的结果中,包含了卧虎藏龙和让子弹飞两部电影,但是卧虎藏龙是动作片,这样的结果是不符合我们的预期的。
解决方案
元数据过滤
为了解决这个问题,许多向量存储支持了对元数据的操作。LangChain 的 Document 对象中有个 2 个属性,分别是page_content和metadata,metadata就是元数据,我们可以使用metadata属性来过滤掉不符合条件的电影。
question = "请帮我推荐一些剧情类电影"
docs = vectordb.similarity_search(
question,
k=3,
filter={"genre":"剧情"}
)
# 输出
"""
[Document(page_content='描绘了一段充满讽刺和黑色幽默的中国西南地区的权力斗争,全片充满了荒诞和激进的政治讽刺。', metadata={'year': 2010, 'director': '姜文', 'rating': 8.5, 'genre': '剧情', 'name': '让子弹飞'}),
Document(page_content='通过九儿与余占鳌的爱情故事,描述了1930年代中国北方农村的生活景象,展示了人性的激情与冷酷。', metadata={'year': 1987, 'rating': 8.2, 'genre': '剧情', 'director': '张艺谋', 'name': '红高粱'}),
Document(page_content="描述了在戏曲舞台上与幕后生活中,程蝶衣、段小楼两位'京剧人'半个世纪的悲欢离合,是一部跨越五十年的人性史诗。", metadata={'year': 1993, 'director': '陈凯歌', 'rating': 9.5, 'genre': '剧情', 'name': '霸王别姬'})]
"""
我们可以看到,使用元数据过滤后,返回的结果中,只有剧情类的电影,这样就解决了上面的问题。
自查询检索器
元数据过滤的方法虽然有用,但需要我们手动来指定过滤条件,我们更希望让 LLM 帮我们自动过滤掉不符合条件的文档。LangChain 提供了一个自查询(Self-querying)的检索器,可以帮助我们自动过滤元数据的信息。可以看看官方的介绍:
顾名思义,自查询检索器是一种能够查询自身的检索器。具体而言,给定任何自然语言查询,检索器使用查询构造 LLM 链来编写结构化查询,然后将该结构化查询应用于其底层 VectorStore。这允许检索器不仅使用用户输入查询与存储的文档的内容进行语义相似性比较,而且还从用户查询中提取对存储文档的元数据过滤器,并执行这些过滤器。
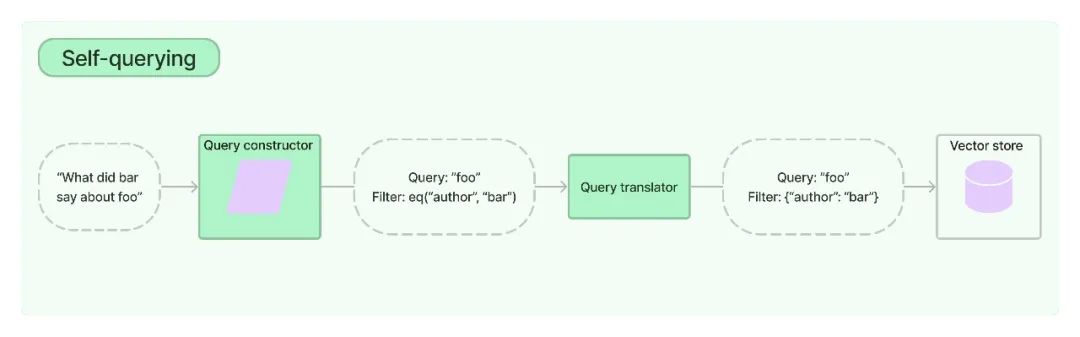
下面我们用自查询过滤器来改进上面的例子。
from langchain.llms import OpenAI
from langchain.retrievers.self_query.base import SelfQueryRetriever
from langchain.chains.query_constructor.base import AttributeInfo
metadata_field_info=[
AttributeInfo(
name="genre",
description="电影的类型",
type="string",
),
AttributeInfo(
name="year",
description="电影发布的时间",
type="integer",
),
AttributeInfo(
name="director",
description="导演的名字",
type="string",
),
AttributeInfo(
name="rating",
description="电影评分,1-10分",
type="float"
),
AttributeInfo(
name="name",
description="电影的名字",
type="string"
),
]
document_content_description = "电影的简短描述"
llm = OpenAI(temperature=0)
retriever = SelfQueryRetriever.from_llm(
llm,
vectordb,
document_content_description,
metadata_field_info,
verbose=True
)
question = "请帮我推荐一些剧情类电影"
docs = retriever.get_relevant_documents(question)
# 输出
"""
query='剧情' filter=Comparison(comparator=<Comparator.EQ: 'eq'>, attribute='genre', value='剧情') limit=None
[Document(page_content="描述了在戏曲舞台上与幕后生活中,程蝶衣、段小楼两位'京剧人'半个世纪的悲欢离合,是一部跨越五十年的人性史诗。", metadata={'year': 1993, 'director': '陈凯歌', 'rating': 9.5, 'genre': '剧情', 'name': '霸王别姬'}),
Document(page_content='通过九儿与余占鳌的爱情故事,描述了1930年代中国北方农村的生活景象,展示了人性的激情与冷酷。', metadata={'year': 1987, 'rating': 8.2, 'genre': '剧情', 'director': '张艺谋', 'name': '红高粱'}),
Document(page_content='描绘了一段充满讽刺和黑色幽默的中国西南地区的权力斗争,全片充满了荒诞和激进的政治讽刺。', metadata={'year': 2010, 'director': '姜文', 'rating': 8.5, 'genre': '剧情', 'name': '让子弹飞'})]
"""
在上面的示例代码中,我们首先定义了电影元数据中每个属性的信息,包括属性的名字,属性的描述(描述非常重要,尽量详细,这是 LLM 解读的关键),还有属性的类型(有些 VectorStore 不支持高级的属性类型,比如 Chroma 不支持 list 类型)。
然后我们使用SelfQueryRetriever.from_llm方法来创建一个自查询检索器,这个方法需要传入一个 LLM 模型,一个 VectorStore,一个文档内容的描述,还有上面定义的元数据信息。在from_llm的参数中我们还可以指定verbose=True,这样就可以看到检索器内部的运行过程,方便我们调试。
最后我们就可以使用get_relevant_documents方法来检索文档了。检索出来的结果第一行是检索器的调试信息,可以看到检索器使用EQ(相等)操作符来匹配电影类型,剩下的结果与元数据过滤方案的结果相同。
我们再查询一下评分大于 8 分的电影,从结果上看到检索器使用了GTE(大于等于)操作符来匹配评分。
question = "请帮我推荐评分8分以上的电影"
docs = retriever.get_relevant_documents(question)
# 输出
"""
query=' ' filter=Comparison(comparator=<Comparator.GTE: 'gte'>, attribute='rating', value=8) limit=None
[Document(page_content='描绘了一段充满讽刺和黑色幽默的中国西南地区的权力斗争,全片充满了荒诞和激进的政治讽刺。', metadata={'year': 2010, 'director': '姜文', 'rating': 8.5, 'genre': '剧情', 'name': '让子弹飞'}),
Document(page_content='一个关于复仇,爱情,自我牺牲和道德责任的故事,融合了武侠动作和浪漫剧情元素,被誉为是现代武侠电影的杰出代表。', metadata={'year': 2000, 'director': '李安', 'rating': 8.8, 'genre': '动作', 'name': '卧虎藏龙'}),
Document(page_content='根据真实事件改编,中国特警队在湄公河流域的金三角地带进行卧底行动,破获一个特大毒品案件,表现了中国警察的决心和勇气。', metadata={'year': 2016, 'rating': 8.0, 'director': '林超贤', 'genre': '动作', 'name': '湄公河行动'}),
Document(page_content="描述了在戏曲舞台上与幕后生活中,程蝶衣、段小楼两位'京剧人'半个世纪的悲欢离合,是一部跨越五十年的人性史诗。", metadata={'year': 1993, 'director': '陈凯歌', 'rating': 9.5, 'genre': '剧情', 'name': '霸王别姬'})]
"""
我们再查询一下八零年代的电影,从结果上看到检索器使用了GTE(大于等于)和LTE(小于等于)操作符来匹配年份。
question = "请帮我推荐一些八零年代的电影"
docs = retriever.get_relevant_documents(question)
# 输出
"""
query=' ' filter=Operation(operator=<Operator.AND: 'and'>, arguments=[Comparison(comparator=<Comparator.GTE: 'gte'>, attribute='year', value=1980), Comparison(comparator=<Comparator.LTE: 'lte'>, attribute='year', value=1989)]) limit=None
[Document(page_content='通过九儿与余占鳌的爱情故事,描述了1930年代中国北方农村的生活景象,展示了人性的激情与冷酷。', metadata={'year': 1987, 'rating': 8.2, 'genre': '剧情', 'director': '张艺谋', 'name': '红高粱'})]
"""
总结
本文介绍了 LangChain 打造知识库过程中遇到的文档检索问题以及解决方案,这也是在 Deeplearning 推出的关于 LangChain 最新短课程——《LangChain: Chat with Your Data》[2]中学到的,里面还讲解了更多关于知识库文档方面的实用技术,感兴趣的同学可以去 Deeplearning 官网了解一下。
关注我,一起学习各种人工智能和 AIGC 新技术,欢迎交流,如果你有什么想问想说的,欢迎在评论区留言。
参考:
[1]Chroma: https://www.trychroma.com/
[2]《LangChain: Chat with Your Data》: https://learn.deeplearning.ai/langchain-chat-with-your-data/lesson/1/introduction
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 如何使用TrafficWatch根据PCAP文件监控和分析网络流量
- 【Kafka每日一问】Kafka重平衡逻辑是什么样的?
- ASAP是什么?它如何助力提升客户服务质量?
- Spark---RDD算子(单值类型Value)
- SpringMVC简介
- 幻兽帕鲁4核16G配置推荐价格表阿里云和腾讯云
- 计算机网络应用层(期末、考研)
- c# 文件检索
- 【动态规划】【离线查询】【前缀和】689. 三个无重叠子数组的最大和
- 华为OD机试真题-分配土地-Python-OD统一考试(C卷)