ML Kit 入门学习&介绍
ML Kit 入门学习&介绍
1. ML Kit
ML Kit 是 Google 提供的一款机器学习 SDK,它包含了一系列预训练模型,可以帮助开发者在 Android 和 iOS 应用中快速添加机器学习功能,是 Google 提供的一款开源 SDK,它可以免费使用。ML Kit 支持 Android 和 iOS 平台。
1.1 ML Kit 支持的功能包括:
- 图像识别:识别图像中的物体、场景和文本。
- 面部识别:检测和识别人脸。
- 物体检测:检测图像中的物体。
- 姿势估计:估计人体姿势。
- 语音识别:识别语音中的单词和短语。
- 语言识别:识别语音中的语言。
- 手势识别:识别手势。
- 行为识别:识别行为。
- 地理位置识别:识别地理位置。
- 翻译:翻译文本。
- 自然语言处理:处理自然语言。
- 推荐系统:为用户推荐内容。
1.2 ML Kit 使用的好处
- ML Kit 可以帮助开发者在应用中快速添加机器学习功能,而无需自己构建和训练模型。ML Kit 的使用非常简单,只需在应用中添加几行代码即可。ML Kit 还提供了丰富的 API 文档和示例代码,帮助开发者快速上手。
- ML Kit 是 Google 提供的一款开源 SDK,它可以免费使用。ML Kit 支持 Android 和 iOS 平台。
- ML Kit 是 Google 在机器学习领域的最新成果,它可以帮助开发者在应用中快速添加机器学习功能。
- ML Kit 的使用非常简单,只需在应用中添加几行代码即可。ML Kit 还提供了丰富的 API 文档和示例代码,帮助开发者快速上手
2. ML Kit 文字识别
? 机器学习套件文字识别 v2 API 可以识别任何中文、梵文、日语、韩语和拉丁语字符集中的文本。此 API 还可用于自动执行数据输入任务,例如处理信用卡、收据和名片
2.1主要功能
- 识别各种文字和语言的文本 支持识别中文、梵文、日语、韩语和拉丁字母的文字
- 分析文本结构支持检测符号、元素、行和段落
- 识别文本的语言 识别识别出的文本的语言
- 实时识别:可以在各种设备上实时识别文本
? 支持的语言查询地址:https://developers.google.com/ml-kit/vision/text-recognition/v2/languages?hl=zh-cn
2.3 准备工作
? 我们需要将ML Kit的Android 版机器学习套件库的依赖项添加到模块的应用级 Gradle 文件
dependencies {
// To recognize Latin script
implementation 'com.google.mlkit:text-recognition:16.0.0'
// To recognize Chinese script
implementation 'com.google.mlkit:text-recognition-chinese:16.0.0'
// To recognize Devanagari script
implementation 'com.google.mlkit:text-recognition-devanagari:16.0.0'
// To recognize Japanese script
implementation 'com.google.mlkit:text-recognition-japanese:16.0.0'
// To recognize Korean script
implementation 'com.google.mlkit:text-recognition-korean:16.0.0'
}
2.4 创建 TextRecognizer 实例
创建对应需要识别的语言
// When using Latin script library
val recognizer = TextRecognition.getClient(TextRecognizerOptions.DEFAULT_OPTIONS)
// When using Chinese script library
val recognizer = TextRecognition.getClient(ChineseTextRecognizerOptions.Builder().build())
// When using Devanagari script library
val recognizer = TextRecognition.getClient(DevanagariTextRecognizerOptions.Builder().build())
// When using Japanese script library
val recognizer = TextRecognition.getClient(JapaneseTextRecognizerOptions.Builder().build())
// When using Korean script library
val recognizer = TextRecognition.getClient(KoreanTextRecognizerOptions.Builder().build())
2.4 处理图片
将图片传递给 process 方法
val result = recognizer.process(image)
.addOnSuccessListener { visionText ->
// Task completed successfully
// ...
}
.addOnFailureListener { e ->
// Task failed with an exception
// ...
}
2.5 从识别出的文本块中提取文本
如果文本识别操作成功完成,系统会向成功监听器传递一个 Text 对象。Text 对象包含图片中识别到的完整文本以及零个或零个以上的 TextBlock 对象。
每个 TextBlock 表示一个矩形文本块,其中包含零个或零个以上的 Line 对象。每个 Line 对象代表一行文本,其中包含零个或零个以上的 Element 对象。每个 Element 对象代表一个字词或类似字词的实体,其中包含零个或零个以上的 Symbol 对象。每个 Symbol 对象代表一个字符、一个数字或类似字词的实体。
对于每个 TextBlock、Line、Element 和 Symbol 对象,您可以获取区域中识别出的文本、区域的边界坐标以及旋转信息、置信度分数等许多其他属性。
val resultText = result.text
for (block in result.textBlocks) {
val blockText = block.text
val blockCornerPoints = block.cornerPoints
val blockFrame = block.boundingBox
for (line in block.lines) {
val lineText = line.text
val lineCornerPoints = line.cornerPoints
val lineFrame = line.boundingBox
for (element in line.elements) {
val elementText = element.text
val elementCornerPoints = element.cornerPoints
val elementFrame = element.boundingBox
}
}
}
2.6 文字识别demo
创建识别中文的TextRecognizer 的实例
val recognizer = TextRecognition.getClient(ChineseTextRecognizerOptions.Builder().build())
输入需要识别的图片方法
private fun processImage(image: InputImage) {
recognizer.process(image)
.addOnSuccessListener { visionText ->
// Task completed successfully
var resultText = ""
Log.e("MainActivity", "识别的文字:${visionText.text}")
for (block in visionText.textBlocks) {
val blockText = block.text
val blockCornerPoints = block.cornerPoints
val blockFrame = block.boundingBox
for (line in block.lines) {
val lineText = line.text
val lineCornerPoints = line.cornerPoints
val lineFrame = line.boundingBox
for (element in line.elements) {
val elementText = element.text
val elementCornerPoints = element.cornerPoints
val elementFrame = element.boundingBox
resultText += "${elementText}==可信度判断:${element.confidence}\n"
Log.e(
"MainActivity",
"可信度判断:elementText:${elementText}==element:${element.confidence}"
)
}
}
Log.e(
"MainActivity",
"blockText:${blockText}==blockCornerPoints:${blockCornerPoints}==blockFrame:${blockFrame}"
)
}
textResult.value = resultText
}
.addOnFailureListener { e ->
Log.e("MainActivity", "addOnFailureListener:${e.printStackTrace()}")
}
}
界面布局
fun GreetingPreview() {
MyApplicationTheme {
Column(
modifier = Modifier.fillMaxSize(),
verticalArrangement = Arrangement.Top,
horizontalAlignment = Alignment.CenterHorizontally
) {
Image(
painter = painterResource(id = textImage.intValue),
contentDescription = "image",
modifier = Modifier.size(200.dp, 150.dp)
)
Button(onClick = {
val image = InputImage.fromBitmap(
resources.getDrawable(textImage.intValue).toBitmap(),
0
)
processImage(image)
}) {
Text1(text = "识别")
}
Button(onClick = {
index += 1
if (index == imageList.size) {
index = 0
}
textImage.intValue = imageList[index]
}) {
Text1(text = "切换图片")
}
Text1(
text = textResult.value,
fontSize = 20.sp, // 字体大小
color = colorResource(id = R.color.black), // 字体颜色
)
}
}
}
识别效果




通过上面4张图片的文字识别,第1张和第4张的文字识别可信度都在0.6以上,识别出来的文字也是100%正确的。 第2张和第3张的文字识别可信度在0.6以下出现了文字识别错误的情况。可见只要是书写字体端庄、工整、规范的中文基本上都可以100%的识别成功。
2.7 输入图片准则
-
为了使机器学习套件准确识别文本,输入图片必须包含由足够像素数据表示的文本。理想情况下,每个字符的大小至少应为 16x16 像素。字符像素大于 24x24 通常不会增加准确性。
例如,640x480 的图片可能非常适合用于扫描占据图片整个宽度的名片。如需扫描打印在信纸大小纸张上的文档,可能需要 720x1280 像素的图片。
-
图片聚焦不佳会影响文本识别的准确性。如果您未获得可接受的结果,请尝试让用户重新捕获图片。
-
如果您是在实时应用中识别文本,则应考虑输入图片的整体尺寸。图片越小,处理速度就越快。为了缩短延迟时间,请确保文本在图片中占据尽可能多的空间,并以较低的分辨率捕获图片(请牢记上述准确性要求)
3. 图像识别
图像识别是计算机视觉的一个重要领域,简单说就是帮你提取图片中的有效信息。 MLKit 提供了 ImageLabeling 功能,可以识别图像信息并进行分类标注。
比如输入一张包含猫的图片,ImageLabeling 能识别出图片中的猫元素,并给出一个猫的标注,除了最显眼的猫 ImageLabeling还能识别出花、草等图片中所有可识别的事物,并分别给出出现的概率和占比,识别的结果以 List<ImageLabel> 返回。 基于预置的默认模型,ImageLabeling可以对图像元素进行超过 400 种以上的标注分类,当然你可以使用自己训练的模型扩充更多分类。
3.1 主要功能
- 一个强大的通用基分类器,可以识别 400 多个描述照片中最常见对象的类别。
- 使用自定义模型,根据您的使用场景量身定制 使用 TensorFlow Hub 中的其他预训练模型,或使用通过 TensorFlow、AutoML Vision Edge 或 TensorFlow Lite Model Maker 训练的自定义模型。
- 易用的高级别 API 无需处理低级别模型输入/输出、图像预处理和后处理,也无需构建处理流水线。机器学习套件从 TensorFlow Lite 模型中提取标签,并以文本描述的形式提供这些标签。
支持标签查询地址:https://developers.google.com/ml-kit/vision/image-labeling/label-map?hl=zh-cn
3.2 准备工作
添加图像标签的依赖
dependencies {
// ...
// Use this dependency to bundle the model with your app
implementation 'com.google.mlkit:image-labeling:17.0.7'
}
3.3 创建一个ImageLabeling实例
val labeler = ImageLabeling.getClient(ImageLabelerOptions.DEFAULT_OPTIONS)
3.4 处理图片
将图片传递给 process 方法,成功和失败返回结果
labeler.process(image)
.addOnSuccessListener { labels ->
// Task completed successfully
// ...
}
.addOnFailureListener { e ->
// Task failed with an exception
// ...
}
3.5 图像识别demo
val labeler = ImageLabeling.getClient(ImageLabelerOptions.DEFAULT_OPTIONS)
private fun imageLabeling() {
val image = InputImage.fromBitmap(resources.getDrawable(textImage.intValue).toBitmap(), 0)
labeler.process(image).addOnSuccessListener { labels: List<ImageLabel> ->
// Task completed successfully
val imageLabel = labels.scan("") { acc, label ->
acc + "${label.text} : ${label.confidence}\n"
}.last()
textResult.value = imageLabel
}.addOnFailureListener {
// Task failed with an exception
}
}
识别效果


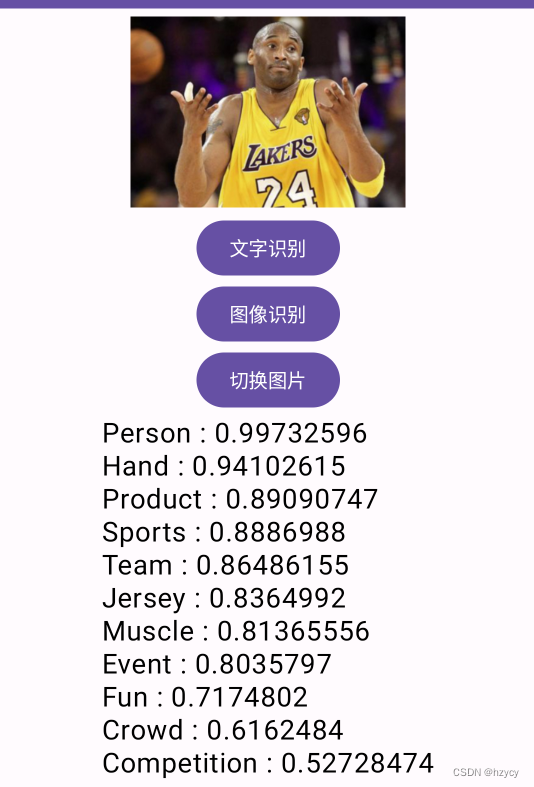
ImageLabeling可以识别图像中的事物分类,可信度从高到底排列,3张图片都精准的进行了识别。第三张图片不光是识别出了人,还有手、团队、运动、肌肉、体育等事件分类。
参考资料:https://developers.google.com/ml-kit/guides?hl=zh-cn
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- docker给容器分配固定ip
- Acrel-2000Z电力监控系统在重庆五桂堂历史文化商业街区的应用——安科瑞赵嘉敏
- office visio2016安装步骤
- 迅速理解什么是通信前置机
- c#入门
- JavaScript语法摘要
- SQL语句的执行顺序
- RISC-V Bytes: Caller and Callee Saved Registers
- 1864_什么是EMI
- 基于Java SSM框架实现雅博书城图书销售评价系统项目【项目源码+论文说明】