python爬取网页图片并下载之多线程
python爬取网页图片并下载之多线程
前言
在上一篇爬虫案例中(python爬取网页图片)我们使用了最基础的文件读写来保存爬取的文件,但是其效率不尽人意,网速慢的时候可能得三四秒才能下载完一张图片,如果获取的图片总量以千以万计量那么这个速度是完全不可行的,因此接下来我们将引入python中的新机制-----多线程
多线程基础
在进行多线程之前,我们先来体验一下单线程
import time
def test():
time.sleep(20)
if __name__ == '__main__':
s = time.time()
test()
e = time.time()
print(e - s)
想都不用想,结果肯定是20啦

接下来正戏开始
首先导入thread包调用Thread模块
from threading import Thread
接着我们将休眠的20秒拆成10个2秒同时执行
按照我们平时的写法可能需要将time.sleep(2)循环遍历十次
但是利用Thread模块我们可以创建线程让程序同时执行任务
首先遍历十次循环
for i in range(10):
然后依次启动线程,括号内的参数target是你要执行的函数
for i in range(10):
t = Thread(target=test)# 注意test函数不要加括号!
然后启动线程
t.start()
完整代码:
import time
from threading import Thread
def test():
time.sleep(2)
if __name__ == '__main__':
threads = []
s = time.time()
for i in range(10):
t = Thread(target=test)
t.start()
threads.append(t)
# 等待所有线程完成
for t in threads:
t.join()
e = time.time()
print(e - s)

差距一下就显现了
线程池
了解完多线程的基本用法,接下来就引入了线程池的概念,线程池会预先创建线程集合然后从中选择一个空闲线程来处理任务,大白话就是你尽管写你的业务代码,线程的创建和销毁会由线程池帮你安排,从而大大提高线程的重用性和执行效率
想要使用线程池得先导入新的模块ThreadPoolExecutor
from concurrent.futures import ThreadPoolExecutor
代码书写的格式也比刚刚的更简单,只需要将你准备执行多线程运算的代码用 with ThreadPoolExecutor(num)as t:包起来,num是你要开启线程的数量,然后submit中第一个参数是你要执行的函数,后面的参数是你需要传入的元素
with ThreadPoolExecutor(10)as t:
for i in range(10):
t.submit(test, i)
推荐:开启的线程数量 = 自己电脑CPU的核心数
不知道自己CPU多少核的可以直接打开设备管理器查看
接着继续运行我们的代码
import time
from concurrent.futures import ThreadPoolExecutor
def test(i):
time.sleep(2)
print(f"线程{i}睡了两秒")
if __name__ == '__main__':
threads = []
s = time.time()
with ThreadPoolExecutor(10)as t:
for i in range(10):
t.submit(test, i)
e = time.time()
print(e - s)
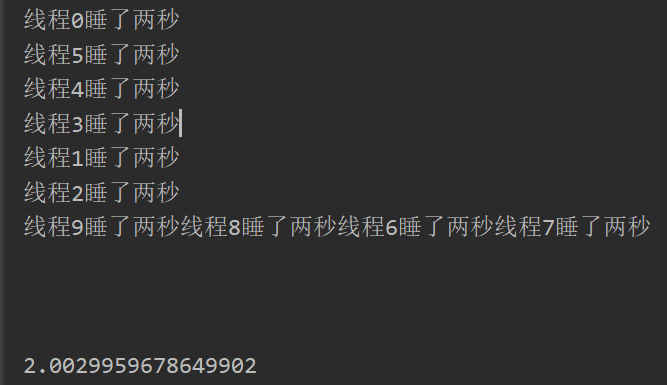
没有问题,继续下一个任务
实际应用
这里我们直接把上一篇爬虫爬取网站图片的代码搬过来
import requests
from lxml import etree
url = 'https://loryx.wiki/%E6%B5%8F%E8%A7%88/%E7%89%8C%E5%BA%93'
data = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36 Edg/120.0.0.0'
}
res = requests.get(url=url, data=data)
res.encoding = 'utf-8'
et = etree.HTML(res.text)
# print(res.text)
src = et.xpath("//td[@class='col15 leftalign']/a/@href")
name = et.xpath("//td[@class='col0 leftalign']/text()")
for i, index in enumerate(name):
name[i] = index.strip()
for i in range(len(src)):
with open(f"img/{name[i]}.png", 'wb') as f:
f.write(requests.get(src[i]).content)
如果你试着跑一下这个代码的话,你可能出去吃个饭回来发现程序还在运行中
现在开始对该代码进行改写
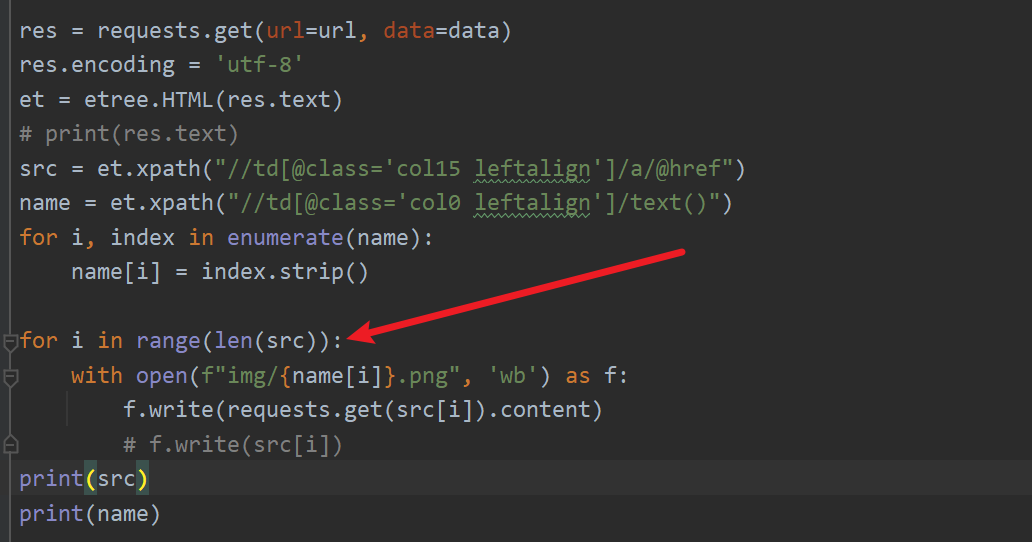
代码到这里我们已经获取了全部的src列表和name列表准备遍历了
所以先将该部分拆分到函数main内
def main():
res = requests.get(url=url)
res.encoding = 'utf-8'
et = etree.HTML(res.text)
src = et.xpath("//td[@class='col15 leftalign']/a/@href")
name = et.xpath("//td[@class='col0 leftalign']/text()")
for i, index in enumerate(name):
name[i] = index.strip()
for i in range(len(src)):
剩余的写入文件的代码也拆分到函数download内
这里文件名和传入数据我们也直接修改为形参
修改前:
def download():
with open(f"img/{name[i]}.png", 'wb') as f:
f.write(requests.get(src[i]).content)
修改后:
def download(name, src):
with open(name, 'wb') as f:
f.write(requests.get(src).content)
在main函数内导入ThreadPoolExecutor模块,并将准备遍历的部分进行包裹
with ThreadPoolExecutor(64) as t:
for i in range(len(src)):
接下来还需要两个步骤
- 准备download的参数
- 启动t线程
with ThreadPoolExecutor(64) as t:
for i in range(len(src)):
file_name = name[i]
t.submit(download, file_name, src[i])
代码到这里基本就完成了,直接启动main()函数
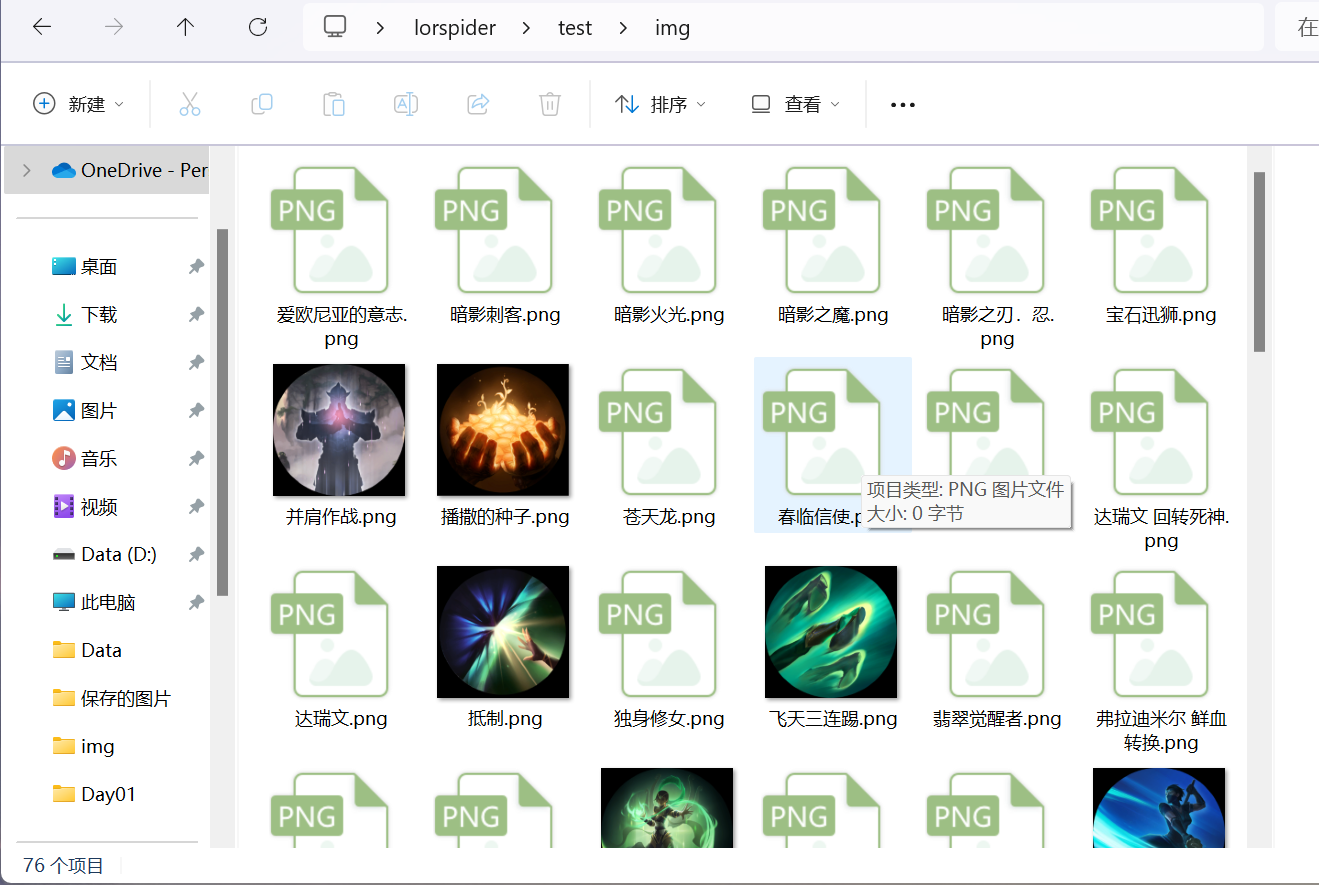
下载速度飞快,一瞬间60多张图片就下好了
总结
在python爬虫的学习中,即使是多线程也并不是我们最终的手段,在高级点的项目中,我们可能会用到其他的类似于Scrapy的爬虫框架
Scrapy使用Twisted框架作为其底层网络引擎,利用异步IO技术来实现高效的网络请求和数据处理,并且其内置了大量的组件和模块包,还支持数据库处理
这些在日后笔者也会慢慢更新。最后附上今天的完整代码:
from concurrent.futures import ThreadPoolExecutor
import requests
from lxml import etree
url = 'https://loryx.wiki/%E6%B5%8F%E8%A7%88/%E7%89%8C%E5%BA%93'
def download(name, src):
with open(name, 'wb') as f:
f.write(requests.get(src).content)
def main():
res = requests.get(url=url)
res.encoding = 'utf-8'
et = etree.HTML(res.text)
src = et.xpath("//td[@class='col15 leftalign']/a/@href")
name = et.xpath("//td[@class='col0 leftalign']/text()")
for i, index in enumerate(name):
name[i] = index.strip()
with ThreadPoolExecutor(64) as t:
for i in range(len(src)):
file_name = f"img/{name[i]}.png"
t.submit(download, file_name, src[i])
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Unblast:免费设计素材平台分享
- c#winform多线程死循环踩坑
- 【OCR项目】之用HALCON的深度学习工具进行文字识别,并导出到C++调用
- linux和windows对比
- TikTok真题第9天 | 163.缺失的区间、1861.旋转箱子、2217.找到指定长度的回文数
- Vue3使用 xx UI解决布局高度自适应
- 解决:PermissionError: [Errno 13] Permission denied: ‘xxx’
- Android 12.0 禁用adb install 安装app功能
- 最新AI创作系统ChatGPT系统源码+DALL-E3文生图+支持AI绘画+GPT语音对话功能
- SpringSecurity集成JWT实现后端认证授权保姆级教程-授权配置篇