5.5 THREAD GRANULARITY
发布时间:2024年01月09日
性能调优中一个重要的算法决定是线程的粒度。有时,在每个线程中投入更多工作并使用更少的线程是有利的。当线程之间存在一些冗余工作时,就会产生这种优势。在当前一代设备中,每个SM的指令处理带宽有限。每个指令都消耗指令处理带宽,无论浮点计算指令、负载指令还是分支指令。消除冗余工作可以减轻指令处理带宽的压力,并提高内核的整体执行速度。
图5.17说明了矩阵乘法的这种机会。图5.6中的tile算法,使用一个线程来计算输出P矩阵的一个元素。这需要一行M和一列N之间的点积。
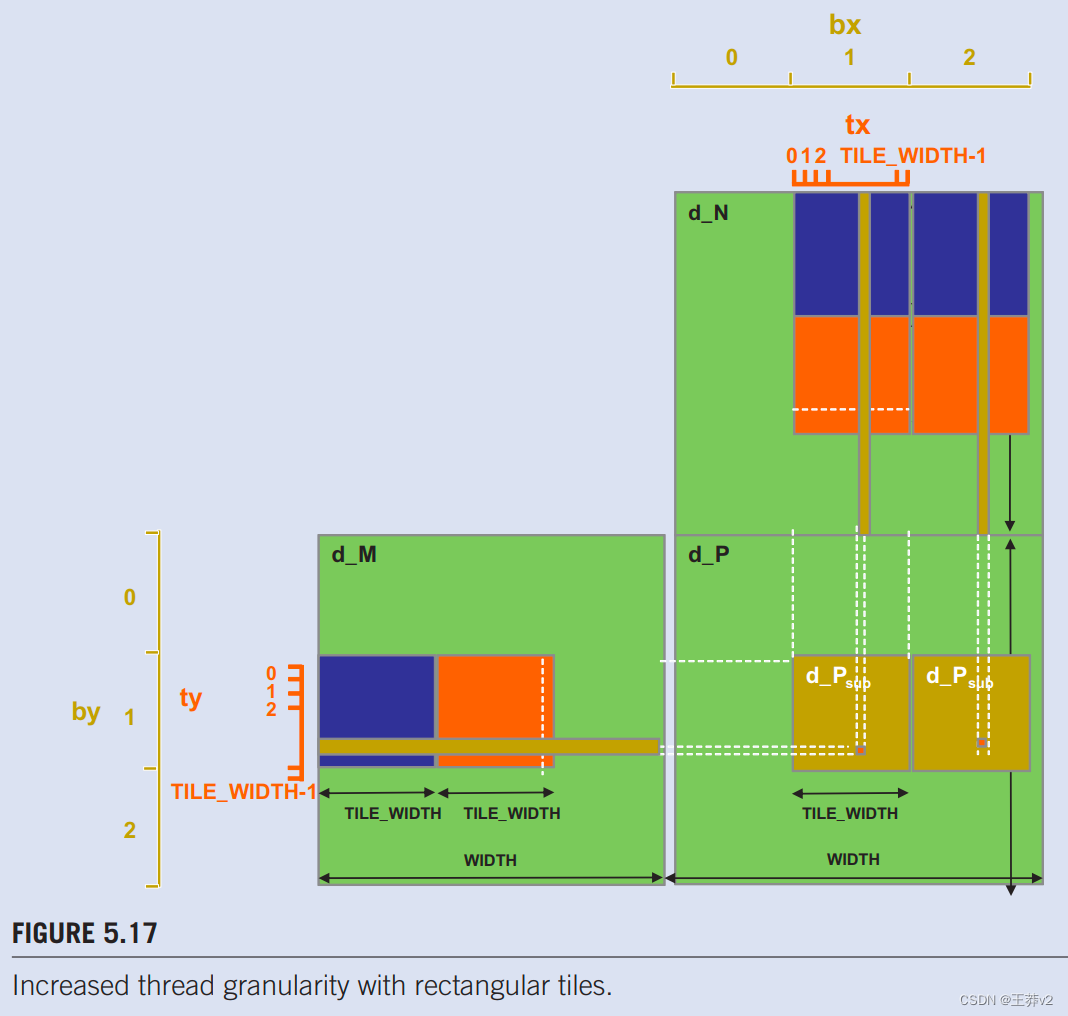
线程粒度调整的机会来自于多个块冗余加载每个M tile的事实。这也在图5.11.中得到了证明。如图5.17所示,相邻 tile 中两个P元素的计算使用相同的 M 行。使用原始的 tile 算法,相同的M行被分配给生成这两个P tile 的两个块冗余加载。人们可以通过将两个线程块合二为一来消除这种冗余。新线程块中的每个线程现在计算两个P元素。这是通过修改内核来完成的,这样两个点积由内核的最内层循环计算。两个点积都使用相同的Mds行,但不同的Nds列。这使全局内存访问减少了四分之一。鼓励读者将新内核作为练习。
潜在的缺点是**,新内核现在使用更多的寄存器和共享内存**。正如我们在上一节中讨论的,可以在每个SM上运行的块数量可能会减少。对于给定的矩阵大小,这也将线程块的总数减少了一半,这可能会导致较小尺寸的矩阵的并行性不足。在实践中,组合多达四个相邻的水平块来计算相邻的水平tile,显著提高了大型(2048x2048或更多)矩阵乘法的性能。
文章来源:https://blog.csdn.net/wangyifan123456zz/article/details/135478847
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- TensorRT优化部署实战项目:YOLOv5人员检测
- JAVA算法—排序
- 003-09-05【RDD-Transformation】南山街尽头大柳树旁人家闺女大红用GPT说明join, cogroup, cartesian 的作用
- Java I/O
- 如何进行实例监控
- 基于JavaWeb+SSM+Vue基于微信小程序生鲜云订单零售系统的设计和实现
- 元旦送好礼:华为 WATCH 4 系列,开启智慧健康的新一年
- 51.常用shell之 chown - 更改文件所有者和组 的用法及衍生用法
- 2-SAT问题相关理论和算法
- 【数据库】为什么PostgreSQL第一次查询结果很慢,第二次就变快了