Python爬虫|使用urllib获取百度首页源码
发布时间:2024年01月14日
在这个博客中,我们将一起探索百度首页的源码,深入了解从URL请求到页面呈现的全过程。我们将使用Python的urllib.request库来模拟浏览器发送请求,并解码响应中的页面源码。通过分析源码,我们将揭示网页的结构、内容和背后的工作原理。
在这个过程中,您将学习到如何使用Python进行网络请求、如何解码响应数据,以及如何解析HTML代码。此外,您还将了解到网页的基本构成和常见的网页开发技术。
先来看源码:
# 使用urllib获取百度首页源码
'''
导入
'''
import urllib.request
'''
定义一个url
baidu.com
'''
url = 'http://www.baidu.com'
'''
模拟浏览器向服务器发送请求
用代码模拟浏览器向服务器要数据
并用一个变量接收
'''
response = urllib.request.urlopen(url)
'''
获取响应中的页面的原码
read()返回的是字节形式的二进制数据
将二进制数据转换成字符串---解码---编码格式
'''
content = response.read().decode('utf-8')
'''
打印数据
'''
print(content)
再来看讲解:
首先,我们需要导入 urllib.request 模块,它是Python的内置库,用于处理URL请求。
import urllib.request
接下来,我们需要定义一个URL,这里我们选择的是百度首页的URL。
url = 'http://www.baidu.com'
然后,我们使用 urlopen 函数模拟浏览器向服务器发送请求,并将响应对象赋值给 response 变量。
response = urllib.request.urlopen(url)
接着,我们使用 read 方法获取响应中的页面的原始代码,并将其解码为字符串。这里我们选择的是 utf-8 编码格式。
content = response.read().decode('utf-8')
最后,我们打印出获取到的数据。
print(content)
通过以上代码,我们可以获取到百度首页的源码,并将其打印出来。这可以帮助我们了解网页的结构和内容。
运行之后,获得以下内容,如图:
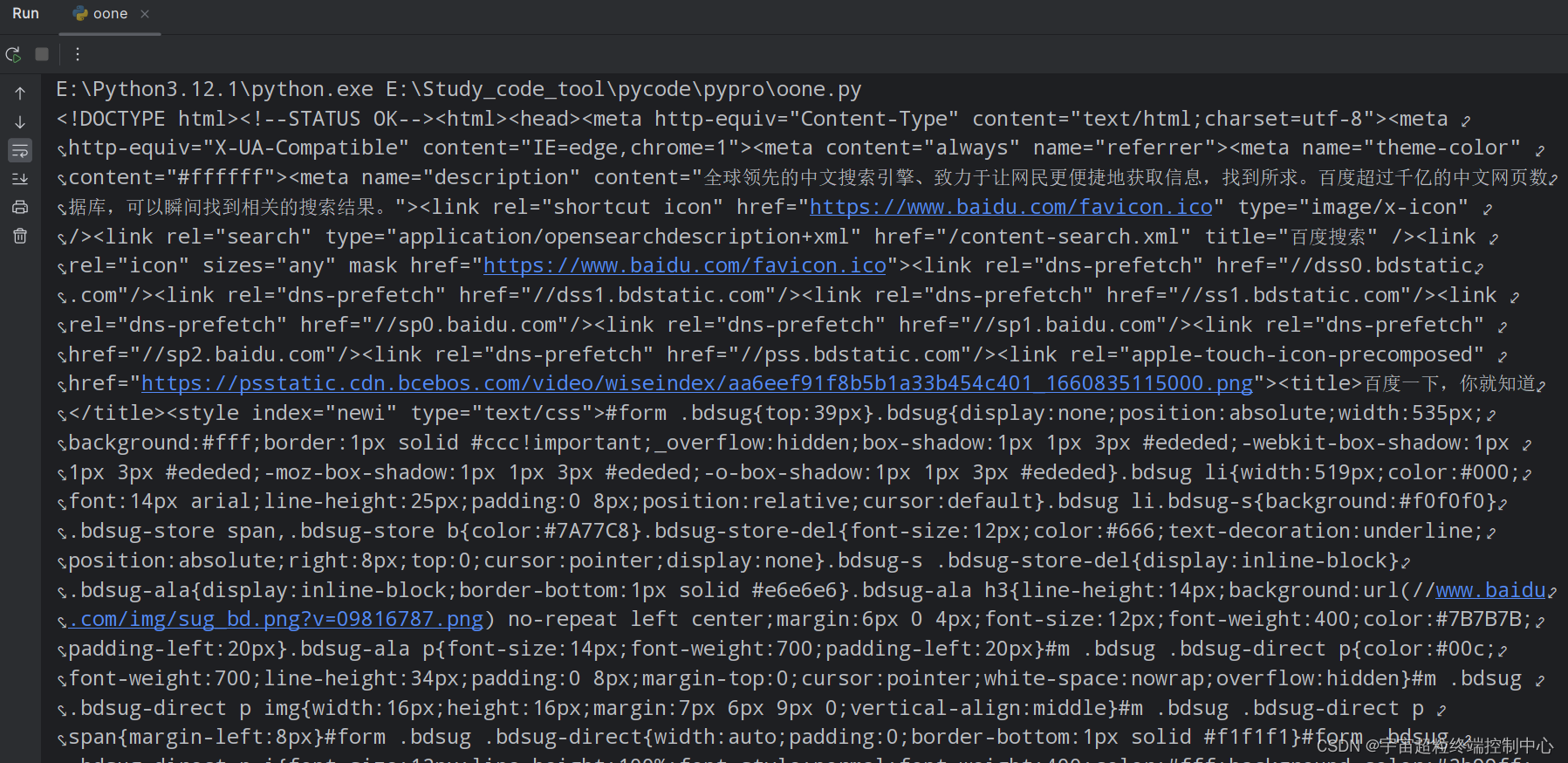
为了方便观看代码,可以将代码复制到html文件中进行格式化,查看:
在这里插入图片描述
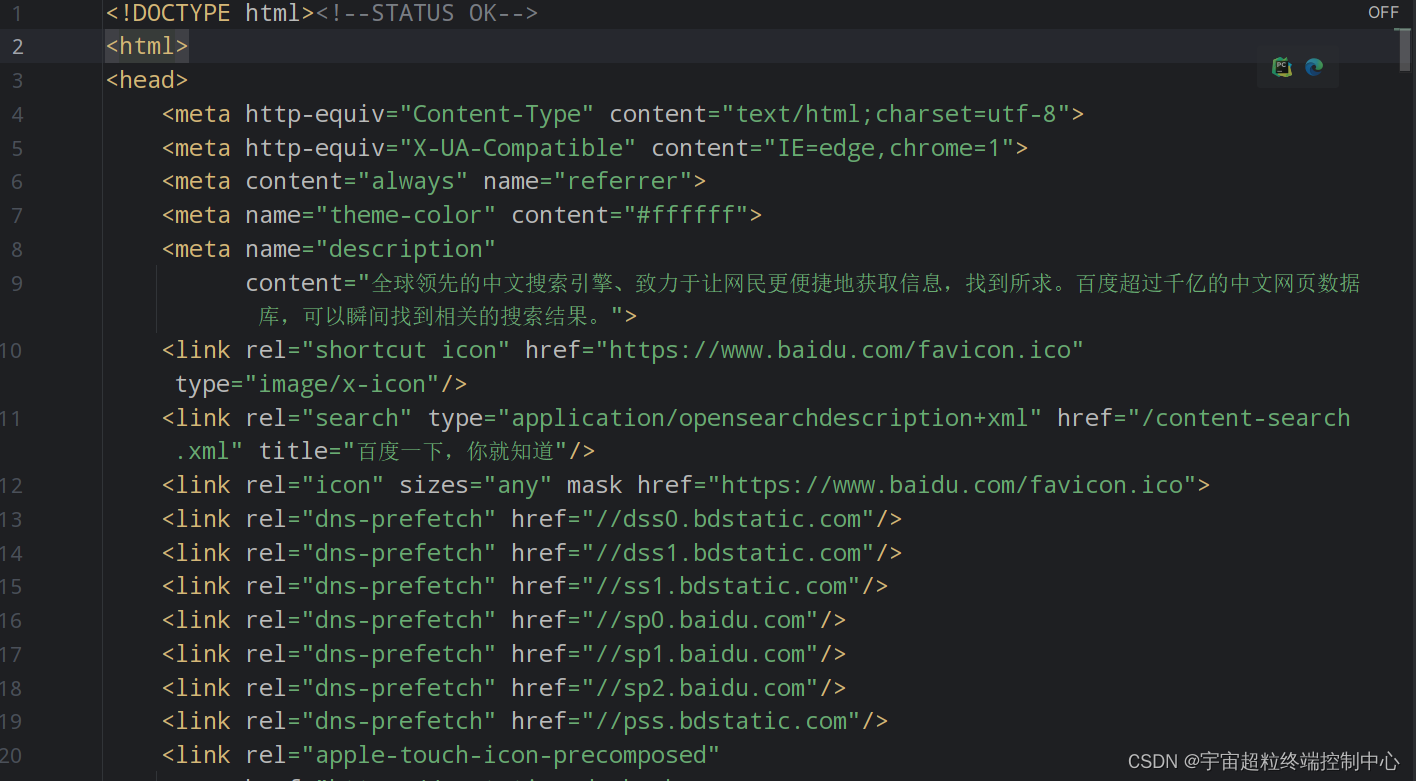
运行这个HTML页面即可打开百度首页
文章来源:https://blog.csdn.net/2301_82018821/article/details/135587229
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!