Rust-泄漏
在C++中,如果引用计数智能指针出现了循环引用,就会导致内存泄漏。而Rust中也一样存在引用计数智能指针Rc,那么Rust中是否可能制造出内存泄漏呢?
内存泄漏
首先,我们设计一个Node类型,它里面包含一个指针,可以指向其他的Node实例:

接下来我们尝试一下创建两个实例,将它们首尾相连:

到这里写不下去了,Rust中要求,Box指针必须被合理初始化,而初始化Box的时候又必须先传入一个Node实例,这个Node的实例又要求创建一个Box指针。这成了“鸡生蛋蛋生鸡”的无限循环。
要打破这个循环,我们需要使用“可空的指针”。在初始化Node的时候,指针应该是“空”状态,后面再把它们连接起来。我们把代码改进,为了能修改node的值,还需要使用mut:

编译,发生错误:“error:use of moved value:node2”。
从编译信息中可以看到,在node1.next =Some(node2);这条语句中发生了move语义,从此句往后,node2变量的生命周期已经结束了。
因此后面一句中使用node2的时候发生了错误。
那我们需要继续改进,不使用node2,换而使用node1.next,代码改成下面这样:

编译又发生了错误,错误信息为:“error:use of partially moved value:node1”。
这是因为在match语句中,我们把node1.next的所有权转移到了局部变量n中,这个n实际上就是node2的实例,在执行赋值操作n.next =Some(node1)的过程中,编译器认为此时node1的一部分已经被转移出去了,它不能再被用于赋值号的右边。
看来,这是因为我们选择使用的指针类型不对,Box类型的指针对所管理的内存拥有所有权,只使用Box指针没有办法构造一个循环引用的结构出来。于是,我们想到使用Rc指针。同时,我们还用了Drop trait来验证这个对象是否真正被释放了:

编译依然没有通过,错误信息为:“error:partial reinitialization of uninitialized structure’node2`”,还是没有达到目的。继续改进,我们将原来“栈”上分配内存改为在“堆”上分配内存:

编译再次不通过,错误信息为:“error:cannot assign to immutable field”。
通过这个错误信息,我们现在应该能想到,Rc类型包含的数据是不可变的,通过Rc指针访问内部数据并做修改是不可行的,必须用RefCell把它们包裹起来才可以。
继续修改:

因为我们使用了RefCell,对Node内部数据的修改不再需要mut关键字。编译通过,执行,这一次屏幕上没有打印任何输出,说明了析构函数确实没有被调用。
至此,终于实现了使用Rc指针构造循环引用,制造了内存泄漏。
虽然构造循环引用非常复杂,但是可能性还是存在的,Rust无法从根本上避免内存泄漏。
通过循环引用构造内存泄漏,需要同时满足三个条件:
- 使用引用计数指针;
- 存在内部可变性;
- 指针所指向的内容本身不是’static的。
当然,这个示例也说明,通过构造循环引用来制造内存泄漏是比较复杂的,不是轻而易举就能做到的。
构造循环引用的复杂性可能也刚好符合我们的期望,毕竟从设计原则上来说:鼓励使用的功能应该设计得越易用越好;不鼓励使用的功能,应该设计得越难用越好。
Easy to Use,Easy to Abuse.
对于上面这个例子,要想避免内存泄漏,需要程序员手动把内部某个地方的Rc指针替换为std::rc::Weak弱引用来打破循环。这是编译器无法帮我们静态检查出来的。
内存泄漏属于内存安全
在编程语言设计这个层面,“内存泄漏”是一个基本上无法在编译阶段彻底解决的问题。在许多场景下,什么是“内存泄漏”、什么不是“内存泄漏”,本身就没有一个完全客观的评判标准。
它实质上跟程序员的“意图”有关。程序很难自动判定出哪些变量是以后还会继续用的,哪些是不再被使用的。
即便是在使用GC做内存管理的环境下,程序员也有可能不小心将不应该被使用的变量错误引用,造成无法自动回收的问题。
因为GC判定一个对象是否可回收的标准是,这个对象有没有被“根”对象直接或者间接引用。
假如一个对象本来是应该被释放的,可是因为逻辑问题,没有把指向它的有效引用全部释放,那么GC依旧把它判定为不可回收。
我们可能在不经意的情况下,造成了不再需要继续使用的对象被生命周期更长的对象所引用。
面对这样的情况,GC也会显得无能为力。比如,在android编程领域,我们可能会在注册回调函数的时候把一个较大的activity引用传递过去,结果activity应该被销毁的时候,由于还有其他变量继续持有指向它的引用,从而导致该activity变量无法正常被释放,这种现象被称为“Context泄漏”。
解决这个问题的办法只能是,在必要的地方使用“弱引用”(WeakReference),避免“强引用”对变量生命周期的影响。
解决引用计数的循环引用的办法与此类似,也是一样用“弱引用”来打破循环,避免“强引用”对生命周期的影响。
再比如在javascript中注册一个定时器,而定时器不小心引用了许多大对象,这些对象会随着闭包加入到主事件循环队列中,也会造成类似的结果。
在绝大部分情况下,GC给我们带来了方便。但是,程序员也千万不能因为有GC的辅助,而忽略对变量的生命周期的设计考量。
在C++和Rust中是一样的,如果出现了循环引用,那么只能通过手动打破循环的方式来解决内存泄漏的问题。编译器无法通过静态检查来保证你不会犯这个错误。
内存泄漏显然是一种bug。但它跟“内存不安全”这种bug的性质不一样。“内存泄漏”是对“正常数据”的“应该执行但是没有执行”的操作,“内存不安全”是对“不正常数据”的“不应该执行但是执行了”的操作。
“内存不安全”导致的后果比“内存泄漏”要严重得多。
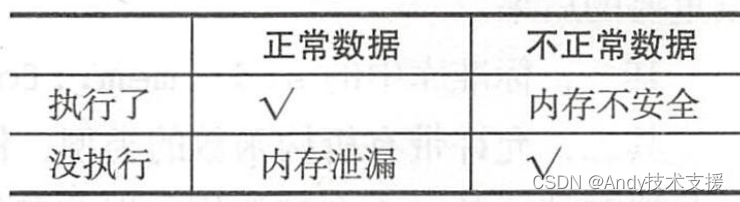
语言的设计者当然是希望能彻底解决内存泄,但是很可惜,这个问题恐怕不是在语言层面能彻底解决的问题。
所谓“彻底解决”的意思是,用户无论使用何种技巧,永远无法构造出内存泄漏的情况。
Rust语言无法给出这样的保证。
内存泄漏当然是不好的事情,作为开发者,我们应该尽可能避免内存泄漏现象的发生。
然而,需要强调的是,内存泄漏不属于内存安全的范畴,Rust也不会在语言设计层面给出一个“免除内存泄漏”的承诺。
析构函数泄漏
上面的例子展现了如何在Rust中不使用unsafe代码制造内存泄漏。在Rust中,在不经意间不小心制造内存泄漏的可能性是很低的。但是这个可能性还是存在的。
然而,内存泄漏并非最可怕的情况,因为内存泄漏只造成资源浪费,毕竟没有造成野指针等更为严重的内存安全问题。
上面的例子实际上还暗示了另外一种危险性,即析构函数泄漏。
在Rust中,RAⅡ手法用得非常普遍,它实际上要求程序的正确性依赖于析构函数的确定性调用。然而让我们担心的事情是,析构函数是有可能永远不会被调用的。
除了前面展示的通过循环引用导致的析构函数泄漏之外,还有许多种方式可以产生同样的效果。
比如,我们构造两个首尾相连的channel,发送端和接收端连到一起,那么在这两个channel里面传递的对象就进入了死循环,就永远不会被析构了。
析构函数泄漏是比内存泄漏更严重的情况。因为析构函数是可以“自定义”的,析构函数里面可能调用“任意的”代码。
我们一直在强调,Rust给了我们一个非常强的保证,即“内存安全”。这个保证是非常严肃认真的。
这个保证意味着,只要不使用unsafe,用户永远无法构造出“内存不安全”的情况。
然而,对于泄漏问题,Rust做不到像内存安全这种程度的保证。
所以,Rust设计者不得不痛苦地承认,析构函数并不能被保证调用。
大家不要误解了这段话,这并不是意味着Rust会轻轻松松、时时刻刻造成泄漏,它只是意味着,编译器没办法自动检查出所有可能的资源泄漏问题,并给出编译错误或警告。
承认析构函数可能不会被调用(即便在不使用unsafe代码情况下),并不会造成特别严重的问题——除非它违反了“内存安全”。
“内存安全”一直是Rust坚持的原则和底线,这条原则是永远不能被破坏的,否则Rust就失去了存在的意义。
这个结论直接导致了下面几个比较重要的后果。
其一,标准库中的std::mem::forget函数去掉了unsafe标记。
其二,允许带有析构函数的类型,作为static变量和const变量。全局变量的析构函数最后是泄漏掉了的,不会被调用。以前曾经规定带析构函数的类型不允许作为全局变量,后来放宽了规定,允许作为全局变量,但是析构函数无法调用。
其三,标准库中不安全代码需要依赖析构函数调用的逻辑得到修改,其中涉及Vec::drain_range和Thread::scoped等方法。
Rust标准库中有一个std::mem::forget函数,这个方法的签名是fn forget(t:T)。它接受的参数不是引用类型,而是将参数move进入函数体中,类似于std::mem::drop。
但它与drop最大的区别是,它会阻止编译器调用这个变量的析构函数,也不会释放它在堆上申请的内存。
它的作用就是制造泄漏。原来这个函数是unsafe的,但是,当设计者发现完全可以用安全代码写一个同样效果的forget函数,那么,它的unsafe标记也就没有什么意义了。
因此,大家决定,去掉forget函数前面的unsafe标记。这个函数不再被标记为unsafe,只是因为设计者意识到了泄漏并非内存安全问题,unsafe关键字只能用于标记跟内存安全相关的问题,并非意味着鼓励用户随意使用这个函数。那么它有什么用呢?我们可以举几个例子:
- 我们有一个未初始化的值,我们不希望它执行析构函数;
- 在用FFI跟外部函数打交道的时候。
即便析构函数泄漏,也不应造成内存不安全。这个结论,直接导致了thread::scoped函数从标准库中移除。
scoped函数是这样设计的:scoped函数可以创建一个线程,跟spawn函数不一样,它保证在当前函数退出以前,这个线程必定已经退出。
这样一来,我们就可以直接使用引用&来读父线程读局部变量,或者用&mut来写局部变量,避免了Arc的运行效率损失,是非常有用的scoped函数与spawn函数的区别就在于,它保证子线程一定会在当前函数退出之前退出,所以它的生命周期比当前函数的生命周期短。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!