【AI】YOLO学习笔记
作为经典的图像识别网络模型,学习YOLO的过程也是了解图像识别的发展过程,对于初学者来说,也可以了解所采用算法的来龙去脉,构建解决问题的思路。
1.YOLO V1
论文地址:https://arxiv.org/abs/1506.02640
YOLO(You Only Look Once)是一种基于深度神经网络的对象识别和定位算法,其最大的特点是运行速度很快,可以用于实时系统。YOLO V1不同于之前模型的特点是:创造性的将候选区和对象识别这两个阶段合二为一,所以速度是它优于其他模型的点。
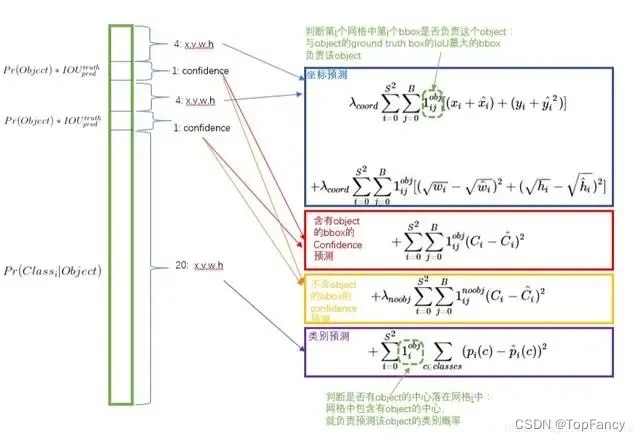
YOLO 网络模型

YOLO并没有真正去掉候选区,而是采用了预定义的预测区。也就是将图片划分为 7*7=49 个网格(grid),每个网格允许预测出2个边框(bounding box,包含某个对象的矩形框)。
模型的输入为448*448*3的图像,最后输出的是7*7*30的tensor,7*7是网格的大小,后面的30则是有两部分组成,前10位是描述的两个bounding box,分别是x,y,h,w,c,xy是中心点的位置,wh是预选框的宽度和高度,c是预选框的置信度;后20位是代表方框所属类别的概率。为了达成这种30位的输出层效果,我们需要通过损失函数来对模型进行限制。
NMS 非极大值抑制
简单来说,每个物体只保留最准确(置信度最高)的一个矩形框,其余的全删除。
YOLO采用重叠度的方式来进行筛选:
将候选框按照置信度排序,依次计算两个候选框的重叠度,当重叠度大于我们设定的阈值时,则丢弃置信度较小的候选框,从而达到减少候选框的目的。
IoU= 并集面积/交集面积? = union_area/intersection_area
2.YOLO V2
YOLO V2的改进:
-
Batch Normalization
V2版本舍弃Dropout,卷积后全部加入Batch Normalization,
网络的每一层的输入都做了归一化,收敛相对更容易 -
更大的分辨率
V1训练时用的是224*224,测试时使用448*448,
V2训练时额外又进行了10次448*448 的微调 -
网络结构
采用Darknet网络模型;去掉了FC层,全部采用卷积层;经过5次降采样,最后的输出为13*13的网格,5次降采样每次降为原来的一半,所以最出的输入是416*416,即便需要自己修改输入数据的大小,也要确保是32的倍数。
采用1*1的卷积,减少计算量; -
聚类提取先验框
k-means聚类中采用的距离为1-IOU; -
Anchor Box
通过引入anchor boxes,使得预测的box数量更多(13*13*n) -
Directed Location Prediction
V2中并没有直接使用偏移量,而是选择相对grid cell的偏移量 -
感受野
采用多层卷积,感受野更大
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 建立人才信息化管理体系,提高企业核心竞争力
- C++ -- 入门(引用&&)
- AlignBench:量身打造的中文大语言模型对齐评测
- 强迫症福音 格式化代码后的sql语句 CASE WHEN THEN ELSE END 语句如何转为一行显示
- Nginx基本配置内容
- 最短路搜索算法
- HarmonyOS应用开发学习笔记 UI布局学习 栅格布局(GridRow/GridCol)
- LRU算法(面试遇到两次)
- FPGA——spi代码篇
- 2024年【安全生产监管人员】考试及安全生产监管人员模拟考试题库