transbigdata 笔记: 轨迹密集化/稀疏化 & 轨迹平滑
发布时间:2024年01月17日
1 密集化
transbigdata.traj_densify(
data,
col=['Vehicleid', 'Time', 'Lng', 'Lat'],
timegap=15)轨迹致密化,保证至多每隔timegap秒都有一个轨迹点
这边插补使用的是pandas的interpolate,method设置的是index
1.1 举例
transbigdata 笔记: 官方文档示例3:车辆轨迹数据处理-CSDN博客
2 稀疏化
transbigdata.traj_sparsify(
data,
col=['Vehicleid', 'Time', 'Lng', 'Lat'],
timegap=15,
method='subsample')扩展采样间隔并减少数据量
- method可以是interpolate/subsample
1.2 举例
transbigdata 笔记: 官方文档示例3:车辆轨迹数据处理-CSDN博客
3 轨迹平滑
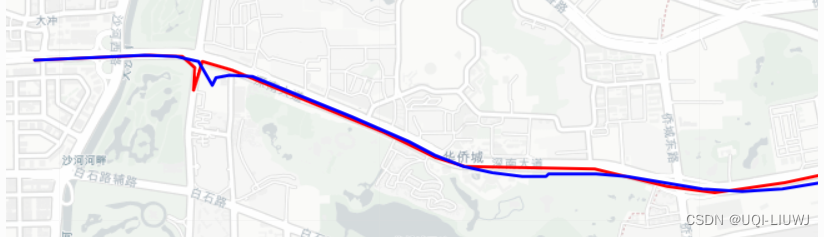
- 在处理车辆轨迹数据时,轨迹点表示对车辆实际“状态”的“观察”。由于误差,观察到的数据可能与车辆的实际状态有所不同。
- 那么,如何更准确地估计车辆的实际状态呢?
- 一种方式是,将轨迹点的位置与先前轨迹点的位置进行比较,以检查显著和不合理的跳跃
- 换言之,根据车辆先前的轨迹预测车辆未来可能的位置。如果下一个记录的轨迹点明显偏离预期位置,则可以确定轨迹异常。
- 这种方法与卡尔曼滤波的概念有相似之处
- 将先前位置推导的状态估计(当前轨迹点的预测位置)与当前观测数据(当前轨迹点的观测位置)相结合,以获得当前状态(实际位置)的最优估计
- 卡尔曼滤波器适用于轨迹数据中噪声相对稳定的情况,这意味着噪声方差保持不变。它在平滑由轨迹数据中的测量误差引起的小规模波动方面特别有效。
- 当轨迹中出现显著漂移时,卡尔曼滤波器的有效性是有限的。漂移点被视为观测值,对状态估计有重大影响,卡尔曼滤波器无法直接处理。
- ——>常见的方法是先去除漂移,然后进行平滑,最后进行路网匹配
3.1 方法介绍
transbigdata.traj_smooth(
data,
col=['id', 'time', 'lon', 'lat'],
proj=False,
process_noise_std=0.5,
measurement_noise_std=1)| data | ?轨迹数据 |
| proj? | 是否进行等距投影 |
| process_noise_std? | 过程噪声的标准偏差【上一时刻的状态预测当前时刻的状态,这个时刻产生的误差】 |
| measurement_noise_std | 测量噪声的标准偏差【观测位置的误差】 |
3.2 举例
文章来源:https://blog.csdn.net/qq_40206371/article/details/135634280
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 使用LVM的情况下扩展系统盘(其它情况也可以扩展)
- 数据库的连接池详解
- JavaScript中最重要的一环之一,ajax发送请求!!
- 微信原生小程序上传与识别以及监听多个checkbox事件打开pdf
- Sublime Text 4 for Mac/win: 提升前端开发效率的编辑神器
- ASP.NET Core列表增删改查
- 20、备忘录模式(Memento Pattern,不常用)
- 季节性ARIMA模型进行时间序列预测
- 聊一聊后端语言的差异和特性差异
- 0基础入门---第七章---卷积神经网络