【深度学习-目标检测】02 - Fast R-CNN 论文学习与总结
发布时间:2023年12月25日
论文地址:Fast R-CNN
论文学习
1. 摘要(Abstract)
- Fast R-CNN方法的提出:
- 论文提出了一种快速区域卷积网络的办法,基于之前的R-CNN网络进行改进。
- 效率和准确性的提升:
- Fast R-CNN 在之前的工作基础上,通过几项创新提高了训练和测试的速度,同时也提高了检测的准确性(提高了训练和测试速度包括准确性)
- 性能比较:
- 相较于 R-CNN,以VGG-16为特征提取网络的基础下,训练速度快9倍,测试时速度快213倍,并且在PASCAL VOC 2012上实现了更高的平均精度。
- 相较于 SPPnet,以VGG-16为特征提取网络的基础下,训练速度快3倍,测试时速度快10倍,并且拥有更高的准确性。
2. 引言
目标检测的挑战 及 现有网络的局限性
- 目标检测的复杂性:
- 目标检测相较于图片分类更具有挑战性。
- 多阶段训练流程的低效率:
- 当前的方法(R-CNN、SPPnet等)通常采用多阶段的训练流程,这种流程不仅训练速度慢,而且效率低下。
- 对象定位的准确性问题:
- 目标检测需要准确定位对象,这带来了两个主要挑战:
- 需要处理大量的候选框(区域提议)。
- 这些候选框(区域提议)只提供大致的定位,需要进一步细化以实现更精确的定位。
- 目标检测需要准确定位对象,这带来了两个主要挑战:
- 现有解决方案的不足:
- 解决上述问题的方案通常在 速度、准确性、简洁性方面存在妥协。
- R-CNN 和 SPPnet 的局限性:
- R-CNN 存在 多阶段训练流程、训练空间和时间成本高、检测速度慢 的问题。
- SPPnet 在训练的时候无法更新卷积层,这限制了深度网络的准确性。
3. Fast R-CNN架构和训练
Fast R-CNN 架构
- Fast R-CNN网络以整个图像和一组对象提议(object proposals)作为输入。
- 网络首先通过多个卷积(conv)和最大池化(max pooling)层处理整个图像,产生卷积特征图(conv feature map)。(与R-CNN不同,一开始就将整幅图进行CNN卷积,提取出全图的特征图)
- 对于每个对象提议,区域兴趣(Region of Interest, RoI)池化层从特征图中提取固定长度的特征向量。(每个区域提议可能大小不一,形状不一,ROI池化层将它们进行处理,以保证每个区域提议获得的特征向量长度一致)
- 每个特征向量被送入一系列全连接层(fully connected layers),最终分叉为两个兄弟输出层:一个输出K个对象类别加上一个“背景”类别的softmax概率估计,另一个输出每个K类别的四个实值数,代表精细化的边界框位置。(与R-CNN的SVM分类器不同,采用了softmax进行分类)
ROI池化层
- RoI池化层使用最大池化将任何有效区域兴趣内的特征转换为具有固定空间范围(例如7x7)的小特征图。
- 每个RoI由一个四元组(r, c, h, w)定义,指定其在卷积特征图中的位置和大小。
从预训练网络初始化
- 实验使用了三个预训练的ImageNet网络,每个网络都有五个最大池化层和五到十三个卷积层。
- 预训练网络初始化Fast R-CNN网络时,会经历三个转换:
- 最后一个最大池化层被RoI池化层替换。
- 网络的最后一个全连接层和softmax被替换为两个新层。
- 网络被修改为接受两种数据输入:图像列表和这些图像中的RoI列表。
检测的微调训练
- Fast R-CNN通过反向传播训练所有网络权重,这是其重要能力之一。
- 训练使用分层采样的随机梯度下降(SGD),首先从N张图像中采样,然后从每张图像中采样R/N个RoI。
- Fast R-CNN使用一种简化的训练过程,使用一个微调阶段,联合优化softmax分类器和边界框回归器。
4. 尺度不变性
- “蛮力”学习(Brute Force Learning):
- 在这种方法中,每张图像在训练和测试期间都被处理为预定义的像素大小。
- 网络必须直接从训练数据中学习尺度不变的目标检测。
- 使用图像金字塔(Image Pyramids):
- 与“蛮力”方法相比,这种方法通过图像金字塔为网络提供近似的尺度不变性。
- 在测试时,使用图像金字塔来近似地对每个对象提议进行尺度标准化。
- 在多尺度训练期间,每次采样图像时随机选择一个金字塔尺度,作为数据增强的一种形式。
作者指出,由于GPU内存限制,他们仅对较小的网络进行了多尺度训练的实验。这部分内容强调了在目标检测任务中实现尺度不变性的重要性,并探讨了两种不同的方法来达到这一目标。尺度不变性对于提高目标检测系统在不同大小和尺度的对象上的性能至关重要。
补充学习
为了模型能够识别不同尺寸大小的同一物体,通常需要采用一定的方法,以下就是两种方法。
”蛮力”学习(Brute Force Learning)
通常来说,为了模型能够识别不同尺寸的同一个物体,我们会在图像输入的时候进行预处理,处理成某个固定的尺寸大小,这样我们训练模型只需要训练其对这个固定大小图片的识别能力即可。
但是”蛮力“学习,是指在训练的时候,就把同一物体的各种尺寸的图片交给模型训练,这样它就拥有识别各种尺寸图片能力,我们无需进行图片预处理,它拥有更强的识别能力,无需预处理简化任务。
图像金字塔(Image Pyramids)
图像金字塔(Image Pyramids)是一种在计算机视觉和图像处理中常用的技术,用于创建一系列具有不同分辨率的图像。这种方法可以帮助模型处理不同尺度的对象,从而实现尺度不变性。
从原始图像开始,通过逐步降低分辨率(例如,每次将宽度和高度减半)来创建一系列较小的图像。
这些较小的图像堆叠起来就像一个金字塔,顶部是最小的图像,底部是原始大小的图像。
这意味着模型可以在不同分辨率的图像上进行训练和测试,从而更好地适应和识别各种尺度的对象。
5. Fast R-CNN 检测
- 检测流程:
- 一旦Fast R-CNN网络被微调(fine-tuned),检测过程主要包括运行一个前向传播(forward pass)。
- 网络输入包括一张图像(或一个图像金字塔,编码为图像列表)和一组对象提议(object proposals)。
- 在测试时,通常会处理大约2000个对象提议,但也可能考虑更多(例如45000个)。
- 处理对象提议:
- 使用图像金字塔时,每个区域兴趣(RoI)被分配到最接近224x224像素面积的尺度。
- 对于每个测试RoI,前向传播输出一个类别后验概率分布和一组预测的边界框偏移量,每个K类别都有自己的细化边界框预测。
- 检测置信度和非极大值抑制:
- 对于每个对象类别k,根据估计的概率Pr(class=k|r)分配一个检测置信度给r。
- 然后,对每个类别独立进行非极大值抑制(non-maximum suppression),使用R-CNN中的算法和设置。
- 加速检测的技术:
- 对于整图分类,全连接层的计算时间相对于卷积层来说很小。但在检测中,需要处理的RoI数量很大,几乎一半的前向传播时间用于计算全连接层。
- 通过使用截断奇异值分解(truncated SVD)技术,可以加速大型全连接层的计算。
- 这种技术通过对权重矩阵进行SVD分解并保留前t个奇异值来减少参数数量,从而加速计算。
6. 主要结果
- 在VOC07、2010和2012数据集上的最先进表现:
- Fast R-CNN在这些数据集上实现了当时最先进的平均精度(mean Average Precision, mAP)。这表明Fast R-CNN在目标检测任务上的有效性和准确性。
- 与R-CNN和SPPnet相比的快速训练和测试:
- Fast R-CNN相比于之前的R-CNN和SPPnet,在训练和测试过程中展现了更快的速度。这是由于Fast R-CNN的架构优化和有效的计算流程,特别是通过整合RoI池化层和使用端到端训练策略实现的。
- 在VGG16中微调卷积层提高了mAP:
- 通过在VGG16网络中微调卷积层,Fast R-CNN能够提高模型的mAP。这表明对于非常深的网络,通过微调所有层(而不仅仅是顶层)可以获得更好的检测性能。
7. 总结
- Fast R-CNN的提出:
- 论文提出了Fast R-CNN,这是对之前的R-CNN和SPPnet方法的一个清晰且快速的更新。Fast R-CNN旨在提高目标检测的效率和准确性。
- 最先进的检测结果:
- 作者报告了使用Fast R-CNN在目标检测任务上达到的最先进结果,并通过详细的实验提供了新的见解。
- 稀疏对象提议的重要性:
- 特别值得注意的是,稀疏的对象提议似乎能够提高检测器的质量。在过去,探索这个问题的成本(时间上)太高,但在Fast R-CNN的框架下变得可行。
- 未来可能的发展方向:
- 作者指出,可能还存在未被发现的技术,这些技术能使密集的边界框(dense boxes)与稀疏提议(sparse proposals)一样表现良好。如果这样的方法被开发出来,它们可能会进一步加速目标检测的过程。
这篇论文《Fast R-CNN》的主要创新点和贡献可以总结如下:
- Fast R-CNN的创新:
- 论文提出了Fast R-CNN模型,这是一种改进的目标检测方法,它在速度、准确性和效率方面对之前的R-CNN和SPPnet模型进行了显著改进。
- 主要特点:
- Fast R-CNN通过整合RoI池化层和使用端到端的训练策略,显著提高了训练和测试的速度。
- 模型能够更新所有网络层,包括卷积层,这对于提高深度网络的性能至关重要。
- 与传统的R-CNN相比,Fast R-CNN不需要为每个对象提议单独提取特征,从而减少了存储需求和计算复杂性。
- 性能评估:
- 在PASCAL VOC数据集上的实验结果表明,Fast R-CNN在目标检测任务上达到了当时的最先进性能。
- 论文还展示了Fast R-CNN在训练和测试速度上相比于R-CNN和SPPnet的显著提升。
- 对未来研究的影响:
- Fast R-CNN的提出为目标检测领域的未来研究提供了新的方向,特别是在处理速度和深度网络训练策略方面。
- 它为后续的研究,如Faster R-CNN和其他基于深度学习的目标检测方法,奠定了基础。
Fast R-CNN
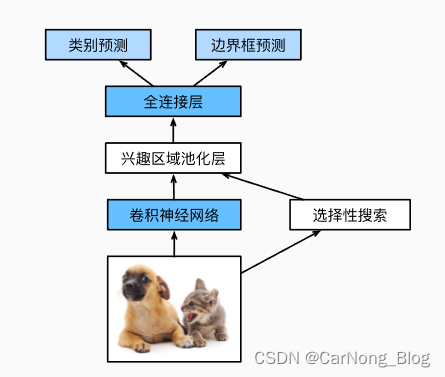
Fast R-CNN 整体工程流程详解:
- 输入:
- 输入包括一张图像和一组对象提议(object proposals)。对象提议通常是通过某种算法(如选择性搜索)从图像中预先计算得到的,表示可能包含目标对象的区域。
- 特征提取:
- 整张图像被送入一个卷积神经网络(CNN),通过多个卷积层和池化层来提取特征。这一步骤生成了一个卷积特征图(convolutional feature map)。
- 区域兴趣(RoI)池化:
- 对于每个对象提议,通过RoI池化层从卷积特征图中提取固定大小的特征向量。RoI池化层将每个提议映射到特征图上,并通过池化操作确保输出特征向量的尺寸是固定的。
- 分类和边界框回归:
- 提取的特征向量被送入一系列全连接层(fully connected layers)。
- 网络分叉为两个输出层:一个是softmax层,用于预测每个RoI属于各个类别的概率;另一个是边界框回归层,用于预测每个类别的精确边界框位置。
- 非极大值抑制(Non-Maximum Suppression, NMS):
- 对于每个类别,根据预测的概率和边界框,执行非极大值抑制来去除重叠的检测,保留最佳的检测结果。
- 输出:
- 最终输出包括每个对象提议的类别标签和精确的边界框位置。
对象提议(Object proposals)到 区域兴趣(ROI)过程
- 生成对象提议:
- 首先,使用某种对象提议算法(如选择性搜索)在输入图像中识别出潜在的对象位置。这些提议是图像中可能包含对象的区域。
- 提议预处理:
- 对象提议可能会经过一些预处理步骤,如去除过小或过大的提议,或者将提议的尺寸标准化。
- 提议到RoI的转换:
- 每个对象提议被转换为一个RoI。在Fast R-CNN中,RoI通常由一个四元组表示,指定了提议区域在原始图像中的位置和尺寸(即,矩形框的左上角坐标、宽度和高度)。
- RoI池化:
- 对于每个RoI,网络使用一个特殊的层——RoI池化层——来提取固定大小的特征向量。这个过程涉及将每个RoI映射到卷积特征图上,并从映射的区域中提取特征。
- RoI池化层通过将RoI区域划分为多个小格子,并在每个格子内进行最大池化操作,来确保输出特征向量的尺寸是固定的。
- 特征向量处理:
- 提取的特征向量随后被用于分类和边界框回归。这意味着网络将对每个RoI进行分类(判断是否包含对象以及对象的类别)并精确地定位对象的边界框。
以上内容旨在记录自己的学习过程以及复习,如有错误,欢迎批评指正,谢谢阅读。
文章来源:https://blog.csdn.net/qq_43513394/article/details/135196361
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Motionface VoiceFocus使用教程
- 协议基础笔记
- Redact Sensitive Info in PDF Files Crack
- 高校电力能耗监测精细化管理系统,提升能源利用效率的利器
- MySQL数据库技术实验报告(表数据插入、修改和删除)
- C手写字符串覆盖、追加、比较、查找函数
- 详解Java死锁-检测与解决
- 35岁程序员,坐标杭州,月薪3W,退休时能领多少钱?
- FTP和本地yum搭建
- 【卡梅德生物】单B细胞技术:牛单抗制备