【大数据OLAP引擎】StarRocks为什么快?
StarRocks的优势
StarRocks最初主要的优势是性能,当时在单表查询方面与性能标杆ClickHouse不相上下,而join优化特性使其在多表关联查询场景下的性能表现要远远优于ClickHouse,替换ClickHouse自然也就成了StarRocks的第一个目标。
而StarRocks的野心不止于此,后来又进一步发展了联邦查询功能,成为Presto的性能升级替代方案。与此同时,StarRocks优良的预计算特性让其成为Druid的一种替代选择。
为什么单表性能可以跟ClickHouse不相上下?
先看下测试数据
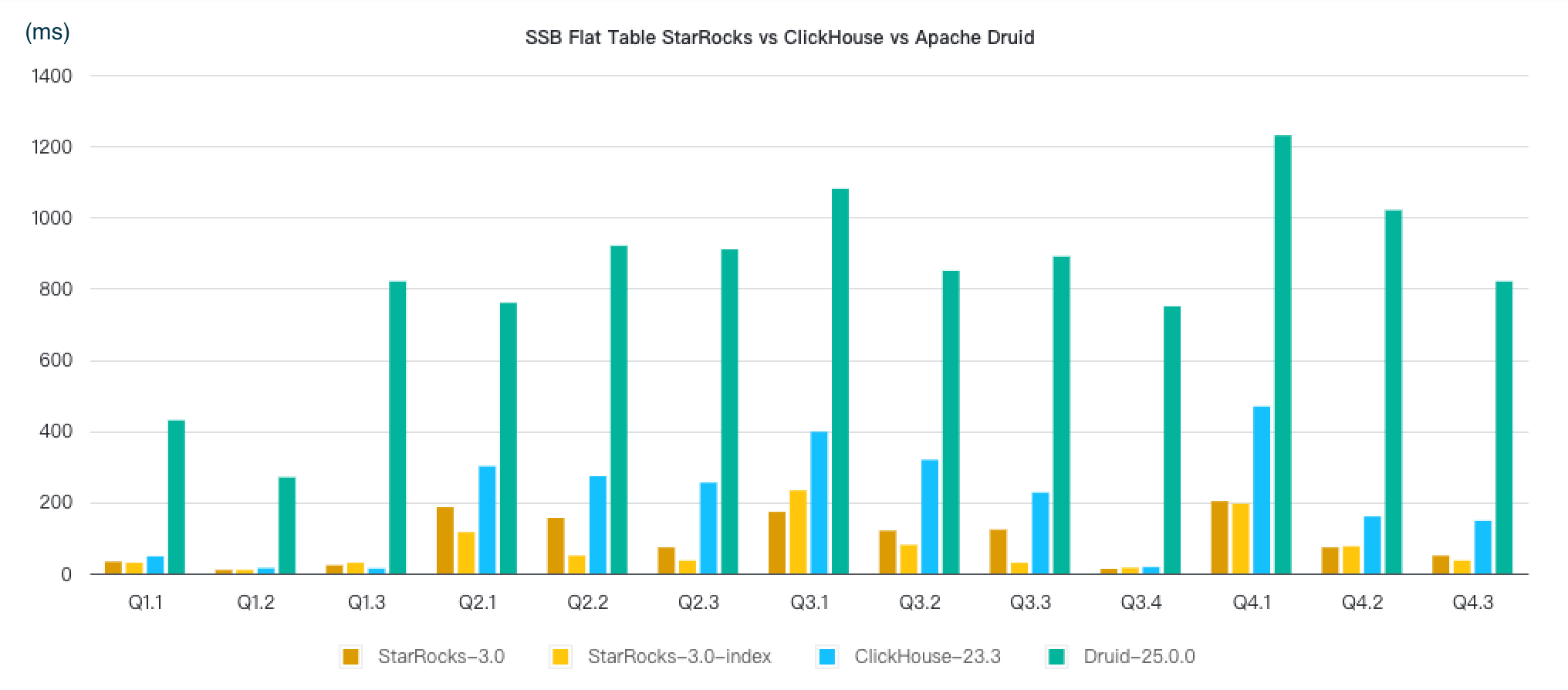
SSB Flat Table 性能测试
Star Schema Benchmark(以下简称 SSB)是学术界和工业界广泛使用的一个星型模型测试集(来源论文),通过这个测试集合可以方便的对比各种 OLAP 产品的基础性能指标。ClickHouse 通过改写 SSB,将星型模型打平转化成宽表 (flat table),改造成了一个单表测试 benchmark(参考链接)。本报告记录了 StarRocks、ClickHouse 和 Apache Druid 在 SSB 单表数据集上的性能对比结果,测试结论如下:
- 在标准测试数据集的 13 个查询上,StarRocks 整体查询性能是 ClickHouse 的 2.1 倍,Apache Druid 的 8.7 倍。
- StarRocks 启用 Bitmap Index 后整体查询性能是未启用的 1.3 倍,此时整体查询性能是 ClickHouse 的 2.8 倍,Apache Druid 的 11.4 倍。
Clickhouse原理
ClickHouse 是一个真正的列式数据库管理系统(DBMS)。
在 ClickHouse 中,数据始终是按列存储的,包括矢量(向量或列块)执行的过程。只要有可能,操作都是基于矢量进行分派的,而不是单个的值,这被称为?矢量化查询执行?(SIMD),它有利于降低实际的数据处理开销。
这个想法并不新鲜,其可以追溯到 APL 编程语言及其后代:A +、J、K 和 Q。矢量编程被大量用于科学数据处理中。即使在关系性数据库中,这个想法也不是什么新的东西:比如,矢量编程也被大量用于 Vectorwise 系统中。
通常有两种不同的加速查询处理的方法:矢量化查询执行和运行时代码生成。在后者中,动态地为每一类查询生成代码,消除了间接分派和动态分派。这两种方法中,并没有哪一种严格地比另一种好。运行时代码生成可以更好地将多个操作融合在一起,从而充分利用 CPU 执行单元和流水线。矢量化查询执行不是特别实用,因为它涉及必须写到缓存并读回的临时向量。如果 L2 缓存容纳不下临时数据,那么这将成为一个问题。但矢量化查询执行更容易利用 CPU 的 SIMD 功能。研究表明,将两种方法结合起来是更好的选择。ClickHouse 使用了矢量化查询执行,同时初步提供了有限的运行时动态代码生成。
StarRocks原理
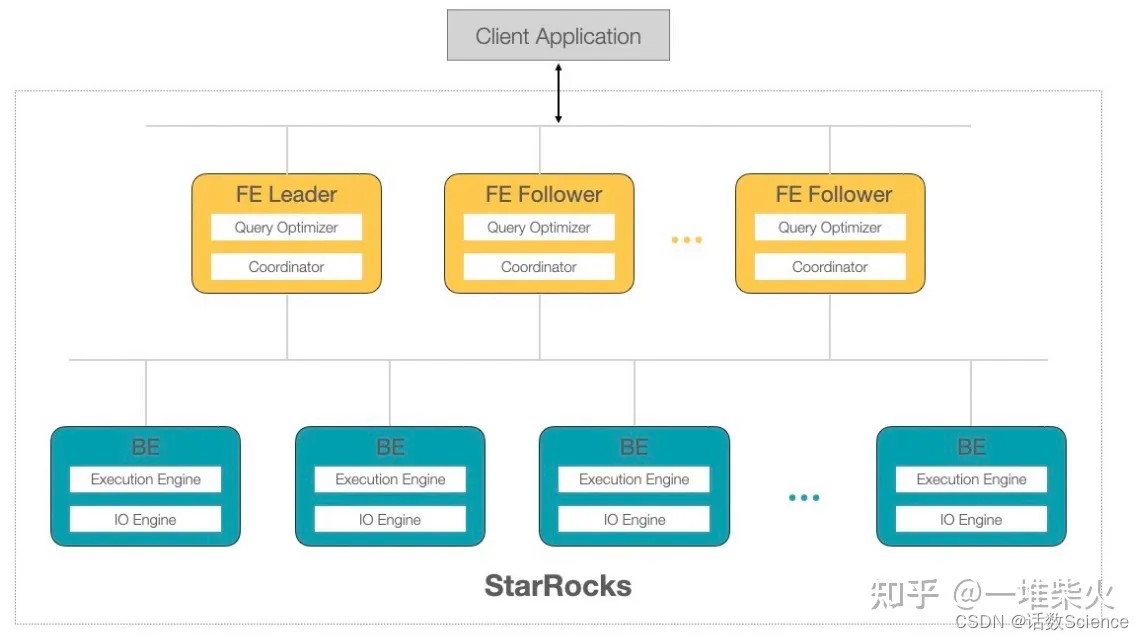
StarRocks 整体上架构?较简单,有两层结构,黄?的是 FrontEnd 节点,蓝?的是 BackEnd 节点:
? FrontEnd 节点主要负责元数据的管理和客户端链接的管理,并且根据元数据信息进? 查询的规划和查询的调度。从 MySQL 客户端发起的请求通过 FrontEnd 节点转化成分 布式的 AST,也就是我们所说的执?计划树,推送给对应的 BackEnd 节点。每?个 FrontEnd 节点都存储全量的元数据,通过类 Paxos 协议进?数据同步,这种多数派的 数据同步协议也保证了我们可以线上?平阔所容 FrontEnd 节点。
? BackEnd 节点主要负责数据存储及 SQL 的计算?作。FrontEnd 节点按照?定的策略 将数据分配给对应的 BackEnd 节点。在执? SQL 计算时,?条 SQL 语句?先会按照 具体的语义规划成逻辑执?单元,然后再按照数据的分布情况拆分成具体的物理执? 单元在 BackEnd 中进?计算。BackEnd 节点是完全对等的,数据通过 Qurom 协议进 ?同步。BackEnd 节点同样也?持在线?平阔缩容。
StarRocks 是通过 MPP 多机并行机制来充分利用多机的资源,通过 Pipeline 并行机制来充分利用单机上多核的资源,通过向量化执行来充分利用单核的资源,进而达到极致的查询性能。
向量化引擎
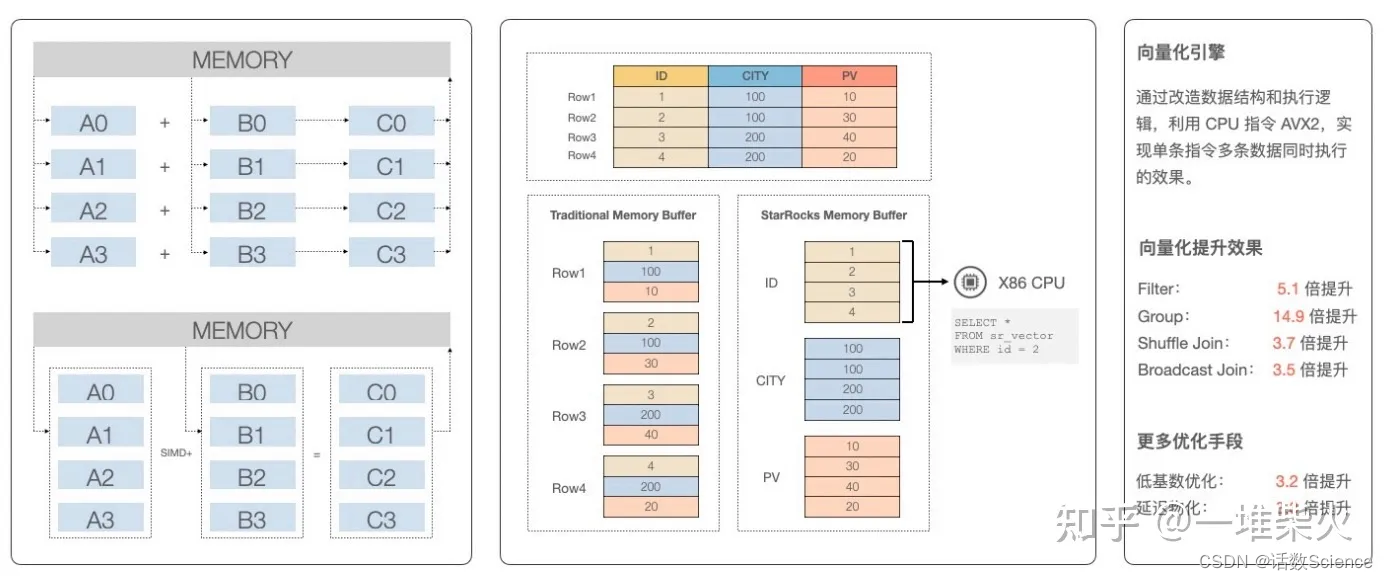
StarRocks 执?器的?个重?的特性就是向量化引擎。通过向量化引擎,可以极?程度的提?查询性能。
作为?个列存数据库,StarRocks 的数据在 BackEnd 存储层是以列的形式组织的。 在没有做向量化引擎之前,数据以列的形式存储,但以?的形式被加载到内存中。?如说我 们要计算 A 列与 B 列的和,会以?的维度不停的调? CPU 的加指令,循环迭代 A0 + B0, A1 + B1,A2 + B2。
有了向量化引擎之后,StarRocks 在将数据加载到内存中时,也是按照列的形式进?布局。 通过调? CPU 的 SIMD 指令集,计算 A 列与 B 列相加,减少了连续的虚函数调?,避免 CPU 流?线被打断。
通过向量化引擎的加速,过滤操作?概有 5 倍左右的性能提升,聚合操作有 15 倍的性能提升,关联操作有?概 3-4 倍的性能提升。
向量化执行

随着数据库执行的瓶颈逐渐从 IO 转移到 CPU,为了充分发挥 CPU 的执行性能,StarRocks 基于向量化技术重新实现了整个执行引擎,向量化执行引擎是为了充分利用单核 CPU 的能力。
向量化在实现上主要是算子和表达式的向量化,上图左边是算子向量化的示例,上图右边是表达式向量化的示例,算子和表达式向量化执行的核心是批量按列执行。相比于单行执行,批量执行可以有更少的虚函数调用,更少的分支判断;相比于按行执行,按列执行对 CPU Cache 更友好,更易于 SIMD 优化。
向量化执行不仅仅是数据库所有算子的向量化和表达式的向量化,而是一项巨大和复杂的性能优化工程,包括数据在磁盘、内存、网络中的按列组织,数据结构和算法的重新设计,内存管理的重新设计,SIMD 指令优化,CPU Cache 优化,C++ Level 优化等。经过努力,StarRocks 向量化执行引擎相比之前的按行执行,取得了整体 5 到 10 倍的性能提升。
一条SQL到执行经过了一系列的优化:
- 通过高效强大的 CBO 优化器生成最佳的分布式物理执行计划;
- 通过查询调度器选择合适的数据副本,并将分布式物理执行计划调度到合适的计算节点进行计算;
- 通过 MPP 分布式执行框架充分利用多机的资源,做到查询性能可以随着机器数量近似线性扩展;
- 通过 Pipeline 并行执行框架充分利用多核资源,做到查询性能可以随着机器核数近似线性扩展;
- 通过向量化执行引擎充分利用 CPU 单核资源,将单核执行性能做到极致。
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 大数据系列 | CDH6.3.2(Cloudera Distribution Hadoop)部署、原理和使用介绍
- Jmeter接口测试+压力测试
- 2023 年终总结
- 【QT】QGraphicsView和QGraphicsItem坐标转换
- Kafka安全认证机制详解之SASL_PLAIN
- Golang 协程配合管道
- 矩阵式键盘按键音
- 柱面,盘片,盘面,扇面,磁头,磁道,扇区,CHS地址,LAB地址
- Docker网络+资源控制
- NFC刷卡soc芯片SI3262集成刷卡+触摸+ACD超低功耗一体