浏览器渲染原理
目录
一、浏览器如何渲染页面?
当浏览器的网络线程收到 HTML 文档后,会产生一个渲染任务,并将其传递给渲染主线程的消息队列。
在事件循环机制的作用下,渲染主线程取出消息队列中的渲染任务,开启渲染流程。
渲染流程又细分为多个阶段:
- HTML 解析-----主线程
- 样式计算-----主线程
- 布局-----主线程
- 分层-----主线程
- 绘制-----主线程
- 分块----- 其它线程
- 光栅化-----其它线程
- 画----- 其它线程

1、解析HTML
完成后,会得到 DOM 树和 CSSOM 树。浏览器的默认样式、内部样式、外部样式、行内样式均会包含在 CSSOM 树中。
为了提高解析效率,浏览器在开始解析前,会启动一个预解析的线程,率先下载 HTML 中的外部 CSS 文件和 外部的 JS 文件。
?如果主线程解析到
link位置,此时外部的 CSS 文件还没有下载解析好,主线程不会等待,继续解析后续的 HTML。这是因为下载和解析 CSS 的工作是在预解析线程中进行的。这就是 CSS 不会阻塞 HTML 解析的根本原因。
如果主线程解析到
script位置,会停止解析 HTML,转而等待 JS 文件下载好,并将全局代码解析执行完成后,才能继续解析 HTML。这是因为 JS 代码的执行过程可能会修改当前的 DOM 树,所以 DOM 树的生成必须暂停。这就是 JS 会阻塞 HTML 解析的根本原因。


2、样式计算
主线程会遍历得到的 DOM 树,依次为树中的每个节点计算出它最终的样式,称之为 Computed Style。
在这一过程中,很多预设值会变成绝对值,比如
red会变成rgb(255,0,0);相对单位会变成绝对单位,比如em会变成px从而会得到一棵带有样式的 DOM 树。
?2.1、扩展
任何一个 HTML 元素,都有一套完整的 CSS 样式,只因没有书写样式,大概率可能会使用其默认值。
属性值的计算过程分为如下四个步骤:
确定声明值
层叠冲突
使用继承
使用默认值
(1)、确定声明值
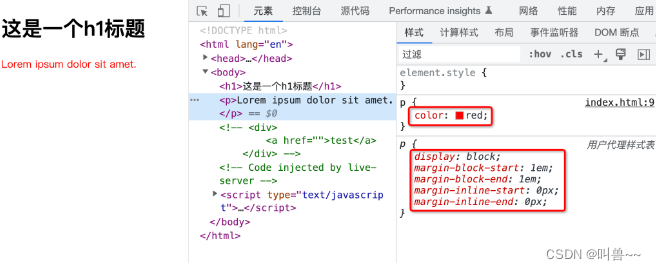
声明值就是作者自己所书写的 CSS 样式,例如下面的:
/* 这里我们声明了 p 元素为红色,那么就会应用此属性设置 */
p{
color : red;
}除了我们自己写的样式表,一般浏览器还会存在“用户代理样式表”,简单来讲就是浏览器内置了一套样式表。
(2)、层叠冲突
又细分为三个步骤:
比较源的重要性
比较优先级
比较次序
(2.1)、比较源的重要性
页面作者样式 > 用户样式 > 用户代理样式
-
浏览器会有一个基本的样式表来给任何网页设置默认样式。这些样式统称用户代理样式。
-
网页的作者可以定义文档的样式,这是最常见的样式表,称之为页面作者样式。
-
浏览器的用户,可以使用自定义样式表定制使用体验,称之为用户样式。
?更详细的来源重要性比较,可以参阅 *MDN*:*https://developer.mozilla.org/zh-CN/docs/Web/CSS/Cascade*
(2.2)、比较优先级
如果是在在同一个源中有样式声明冲突怎么办呢?此时就会进行样式声明的优先级比较。
例如:
<div class="test">
?<h1>test</h1>
</div>
.test h1{
?font-size: 50px;
}
?
h1 {
?font-size: 20px;
}在上面的代码中,同属于页面作者样式,源的重要性是相同的,此时会以选择器的权重来比较重要性。
很明显,上面的选择器的权重要大于下面的选择器,因此最终标题呈现为 50px。

可以看到,落败的作者样式在 Elements>Styles 中会被划掉。
有关选择器权重的计算方式,不清楚的同学,可以进入此传送门:Specificity - CSS: Cascading Style Sheets | MDN
(2.3)、比较次序
最后一种情况,那就是样式声明既是同源,权重也相同。
此时就会进入第三个步骤,比较样式声明的次序。
h1 {
font-size: 50px;
}
h1 {
font-size: 20px;
}在上面的代码中,同样都是页面作者样式,选择器的权重也相同,此时位于下面的样式声明会层叠掉上面的那一条样式声明,最终会应用 20px 这一条属性值。

(3)、使用继承
<div class="test">
<div>
<p>Lorem ipsum dolor sit amet.</p>
</div>
</div>
div {
color: red;
}
.test{
color: blue;
}?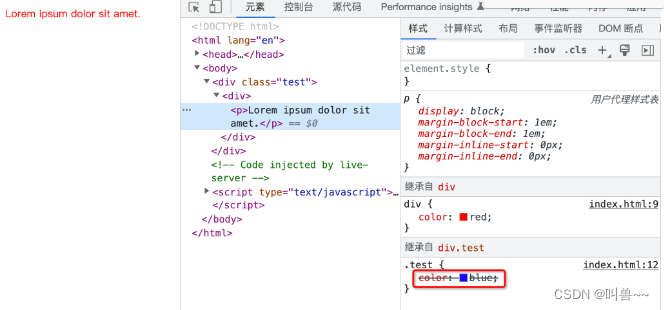
?因为这里并不涉及到选中 p 元素声明 color 值,不会去比较权重,而是从父元素上面继承到 color 对应的值,因此这里是谁近就听谁的。
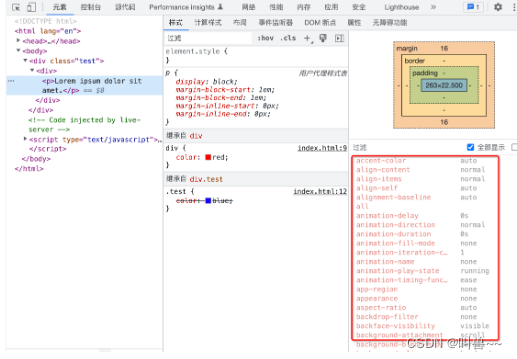
(4)、使用默认值
一个 HTML 元素要在浏览器中渲染出来,必须具备所有的 CSS 属性值,但是绝大部分我们是不会去设置的,用户代理样式表里面也不会去设置,也无法从继承拿到,因此最终都是用默认值
?
(5)、扩展-面试题?
下面的代码,最终渲染出来的效果,a 元素是什么颜色?p 元素又是什么颜色?
<div> <a href="">test</a> <p>test</p> </div> div { color: red; }解答:
因为 a 元素在用户代理样式表中已经设置了 color 属性对应的值,因此会应用此声明值。而在 p 元素中无论是作者样式表还是用户代理样式表,都没有对此属性进行声明,然而由于 color 属性是可以继承的,因此最终 p 元素的 color 属性值通过继承来自于父元素。

3、布局
布局完成后会得到布局树。
布局阶段会依次遍历 DOM 树的每一个节点,计算每个节点的几何信息。例如节点的宽高、相对包含块的位置。
大部分时候,DOM 树和布局树并非一一对应。
比如
display:none的节点没有几何信息,因此不会生成到布局树;又比如使用了伪元素选择器,虽然 DOM 树中不存在这些伪元素节点,但它们拥有几何信息,所以会生成到布局树中。还有匿名行盒、匿名块盒等等都会导致 DOM 树和布局树无法一一对应。
行内元素,块级元素? 是在HTML里面的说法
行盒与块盒,是在CSS里面的说法
内容必须在行盒里面,行盒与块盒不能相邻。

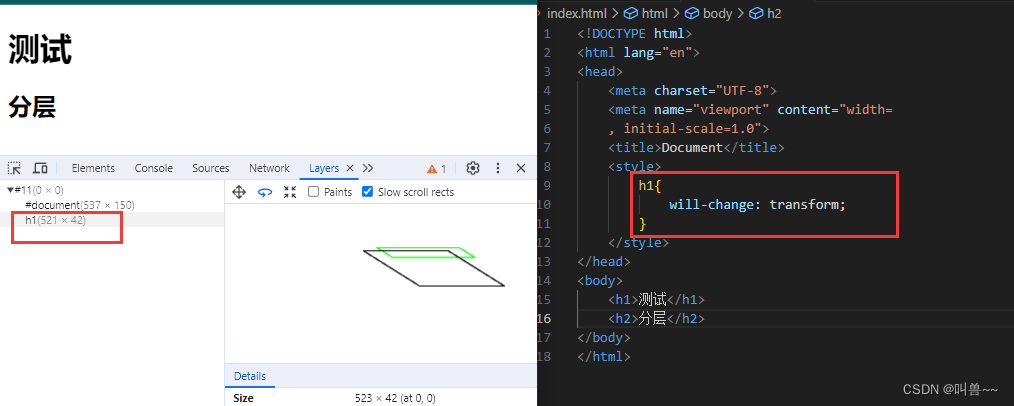
4、分层

滚动条、堆叠上下文、transform、opacity 等样式都会或多或少的影响分层结果,也可以通过
will-change属性更大程度的影响分层结果。如果在页面中我们有一个元素,要经常重排重绘,我们可以通过 【?will-change: transform;】告诉浏览器,将来元素会发生变化,让浏览器自行决策是否进行单独分层。
分层的好处在于,将来某一个层改变后,仅会对该层进行后续处理,从而提升效率。
5、绘制
主线程会为每个层单独产生绘制指令集,用于描述这一层的内容该如何画出来。
6、分块
启动合成线程,每个图层进行分块,将其划分为更多的小区域
它会从线程池中拿取多个线程来完成分块工作。
7、光栅化
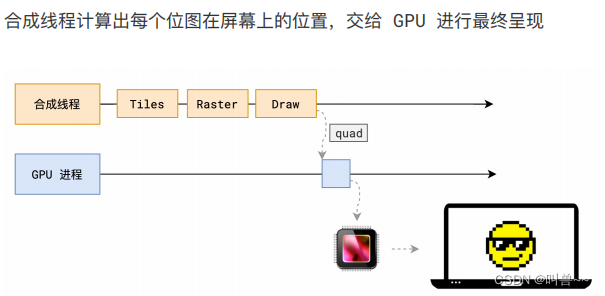
分块完成后 ,合成线程会将块信息交给 GPU 进程,以极高的速度完成光栅化,生成一块一块的位图 。并且优先处理靠近视口区域的块。

8、画
合成线程拿到每个层、每个块的位图后,生成一个个「指引(quad)」信息。
指引会标识出每个位图应该画到屏幕的哪个位置,以及会考虑到旋转、缩放等变形。
变形发生在合成线程,与渲染主线程无关,这就是
transform效率高的本质原因。合成线程会把 quad 提交给 GPU 进程,由 GPU 进程产生系统调用,提交给 GPU 硬件,完成最终的屏幕成像。
二、什么是reflow(重排)??
reflow 的本质就是重新计算 layout 树(布局树)。
当进行了会影响布局树的操作后,需要重新计算布局树,会引发 layout。
为了避免连续的多次操作导致布局树反复计算,浏览器会合并这些操作,当 JS 代码全部完成后再进行统一计算。所以,改动属性造成的 reflow 是异步完成的。
也同样因为如此,当 JS 获取布局属性时,就可能造成无法获取到最新的布局信息。
浏览器在反复权衡下,最终决定获取属性立即 reflow。
简述:当改变dom结构的时候,就会从dom树开始从新渲染页面,这过程叫重排
比如添加或者删除可见的DOM元素、元素尺寸改变、元素内容改变、
浏览器窗口尺寸改变等等
三、什么是repaint(重绘)??
repaint 的本质就是重新根据分层信息计算了绘制指令。
当改动了可见样式后,就需要重新计算,会引发 repaint。
由于元素的布局信息也属于可见样式,所以 reflow 一定会引起 repain
简述:当改变样式(不改变几何结构)的时候,它会从render树开始重新开始渲染页面,
这过程叫重绘,比如改变颜色,透明等
四、为什么 transform 的效率高?
因为 transform 既不会影响布局也不会影响绘制指令,它影响的只是渲染流程的最后一个「draw」阶段
由于 draw 阶段在合成线程中,所以 transform 的变化几乎不会影响渲染主线程。反之,渲染主线程无论如何忙碌,也不会影响 transform 的变化
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- PMP证书的PDU如何获得?
- Python从入门到精通秘籍七
- synchronized、volatile关键字
- MybatisPlus核心功能
- 优化改进YOLOv8算法之AKConv(可改变核卷积),即插即用的卷积,效果秒杀DSConv
- 多变量线性回归
- Hadoop/HDFS/MapReduce/Spark/HBase重要知识点整理
- 青龙面版 定时任务执行python文件
- 目前2024年阿里云服务器优惠购买入口链接汇总
- JavaScript堆内存耗尽