Spark写入kafka(批数据和流式)
发布时间:2024年01月21日
Spark写入(批数据和流式处理)
Spark写入kafka批处理
写入kafka基础

# spark写入数据到kafka
from pyspark.sql import SparkSession,functions as F
ss = SparkSession.builder.getOrCreate()
# 创建df数据
df = ss.createDataFrame([[9, '王五', 21, '男'], [10, '大乔', 20, '女'], [11, '小乔', 22, '女']],
schema='id int,name string,age int,gender string')
df.show()
# todo 注意一:需要拼接一个value
# 在写入kafka时需要拼接一个value
df_kafka = df.select(F.concat_ws(',',df.id.cast('string'),df.name,df.age.cast('string'),df.gender).alias('value'))
df_kafka.show()
# 将df写入kafka
# todo 注意二:这个和读取kafka时的配置是一样,不过这里应该是没有读取起始量和读取结束量
options = {
# 指定kafka的连接的broker服务节点信息
'kafka.bootstrap.servers': 'node1:9092',
# 指定写入主题
'topic': 'user'
}
df_kafka.write.save(format='kafka', mode='append', **options)
kafka写入策略
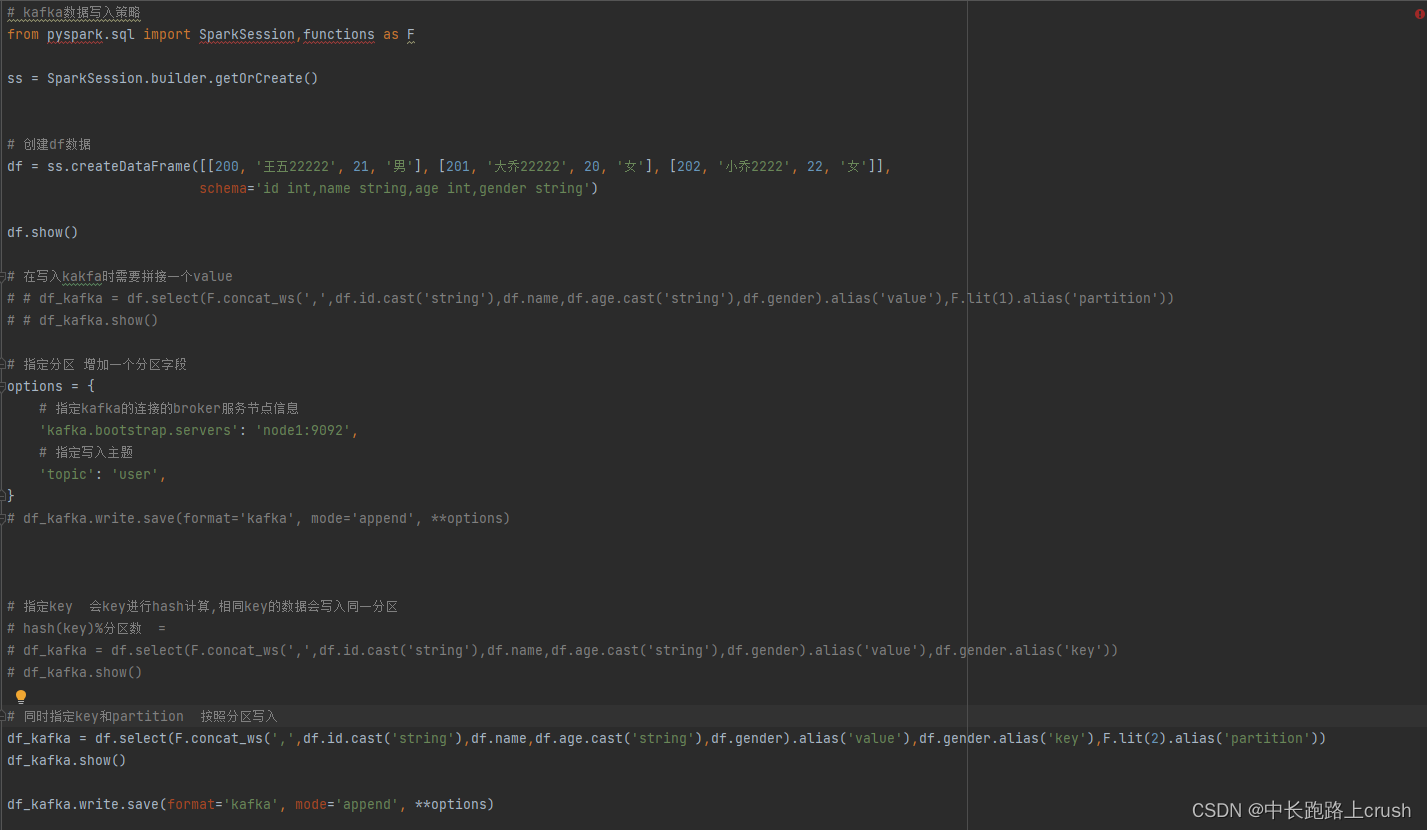
# kafka数据写入策略
from pyspark.sql import SparkSession,functions as F
ss = SparkSession.builder.getOrCreate()
# 创建df数据
df = ss.createDataFrame([[200, '王五22222', 21, '男'], [201, '大乔22222', 20, '女'], [202, '小乔2222', 22, '女']],
schema='id int,name string,age int,gender string')
df.show()
# 在写入kakfa时需要拼接一个value
# # df_kafka = df.select(F.concat_ws(',',df.id.cast('string'),df.name,df.age.cast('string'),df.gender).alias('value'),F.lit(1).alias('partition'))
# # df_kafka.show()
# 指定分区 增加一个分区字段
options = {
# 指定kafka的连接的broker服务节点信息
'kafka.bootstrap.servers': 'node1:9092',
# 指定写入主题
'topic': 'user',
}
# df_kafka.write.save(format='kafka', mode='append', **options)
# 指定key 会key进行hash计算,相同key的数据会写入同一分区
# hash(key)%分区数 =
# df_kafka = df.select(F.concat_ws(',',df.id.cast('string'),df.name,df.age.cast('string'),df.gender).alias('value'),df.gender.alias('key'))
# df_kafka.show()
# 同时指定key和partition 按照分区写入
df_kafka = df.select(F.concat_ws(',',df.id.cast('string'),df.name,df.age.cast('string'),df.gender).alias('value'),df.gender.alias('key'),F.lit(2).alias('partition'))
df_kafka.show()
df_kafka.write.save(format='kafka', mode='append', **options)
写入kafka应答响应级别
# spark写入数据到kafka
# 指定ack应答级别
from pyspark.sql import SparkSession, functions as F
ss = SparkSession.builder.getOrCreate()
# 创建df数据
df = ss.createDataFrame([[9, '王五', 21, '男'], [10, '大乔', 20, '女'], [11, '小乔', 22, '女']],
schema='id int,name string,age int,gender string')
df.show()
# 在写入kakfa时需要拼接一个value
df_kafka = df.select(F.concat_ws(',', df.id.cast('string'), df.name, df.age.cast('string'), df.gender).alias('value'))
df_kafka.show()
# 将df写入kafka
options = {
# 指定kafka的连接的broker服务节点信息
'kafka.bootstrap.servers': 'node1:9092',
# 指定写入主题
'topic': 'user',
# 指定级别
'acks':'all'
}
df_kafka.write.save(format='kafka', mode='append', **options)
Sprak写入kafka流式处理
文章来源:https://blog.csdn.net/weixin_58026490/article/details/135721129
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- IP 地址数据——IPv6 连接测试——你部署的网站安全吗。
- C语言与Java的区别
- 11-2 RHEL8配置YUM软件仓库及安装拼音输入法
- MySQL两个表的亲密接触-连接查询的原理
- 2020年财政收支
- 【C#】TimeSpan
- 邦芒攻略:快速拓展职场人脉的三种方法
- 要给客户圣诞发圣诞祝福了!
- 【小沐学GIS】基于OpenSceneGraph(OSG)绘制三维数字地球Earth
- 主流进销存系统有哪些?企业该如何选择进销存系统?