Dynamic Coarse-to-Fine Learning for Oriented Tiny Object Detection(CVPR2023)

文章目录
hh
源代码
-
该论文作者此前提出了RFLA,一种基于高斯接受场的标签分配策略
动态先验:简单来说就是:初始化先验位置,通过前向传播获取每个先验位置对应的偏移量集合?o,模型据此动态调整先验位置。
Abstract & Conclusion
现存问题
检测任意方向的微小物体给现有的检测器带来了巨大的挑战,特别是在标签分配方面。尽管近年来在定向目标检测器中对自适应标签分配进行了探索,但定向微小目标的极端几何形状和有限特征仍然会导致严重的不匹配和不平衡问题。具体而言,位置先验、正样本特征和实例不匹配,并且由于缺乏适当的特征监督,极端形状对象的学习存在偏差和不平衡。即特征先验不匹配和正样本不平衡是阻碍定向微小目标标签分配的两个障碍。
解决方法
为了解决这些问题,作者提出了一个动态先验和由粗到精的分配器DCFL。
一方面,以动态方式对先验、标签分配和对象表示进行建模,以减轻不匹配问题。另一方面,利用粗糙的先验匹配和更精细的后验约束来动态地标记标签,为不同的实例提供适当和相对平衡的监督。
即作者提出了一个动态先验来缓解不匹配问题,并提出了一个粗到细的分配器来缓解不平衡问题,其中先验、标签分配和gt表示都以动态的方式重新制定。
结论
在六个数据集上进行的大量实验表明,基线有了实质性的改进。值得注意的是,在单尺度训练和测试下,作者在DOTA-v1.5、DOTA-v2.0和DIOR- R数据集上获得了一阶段检测器的最先进性能
-
详
问题
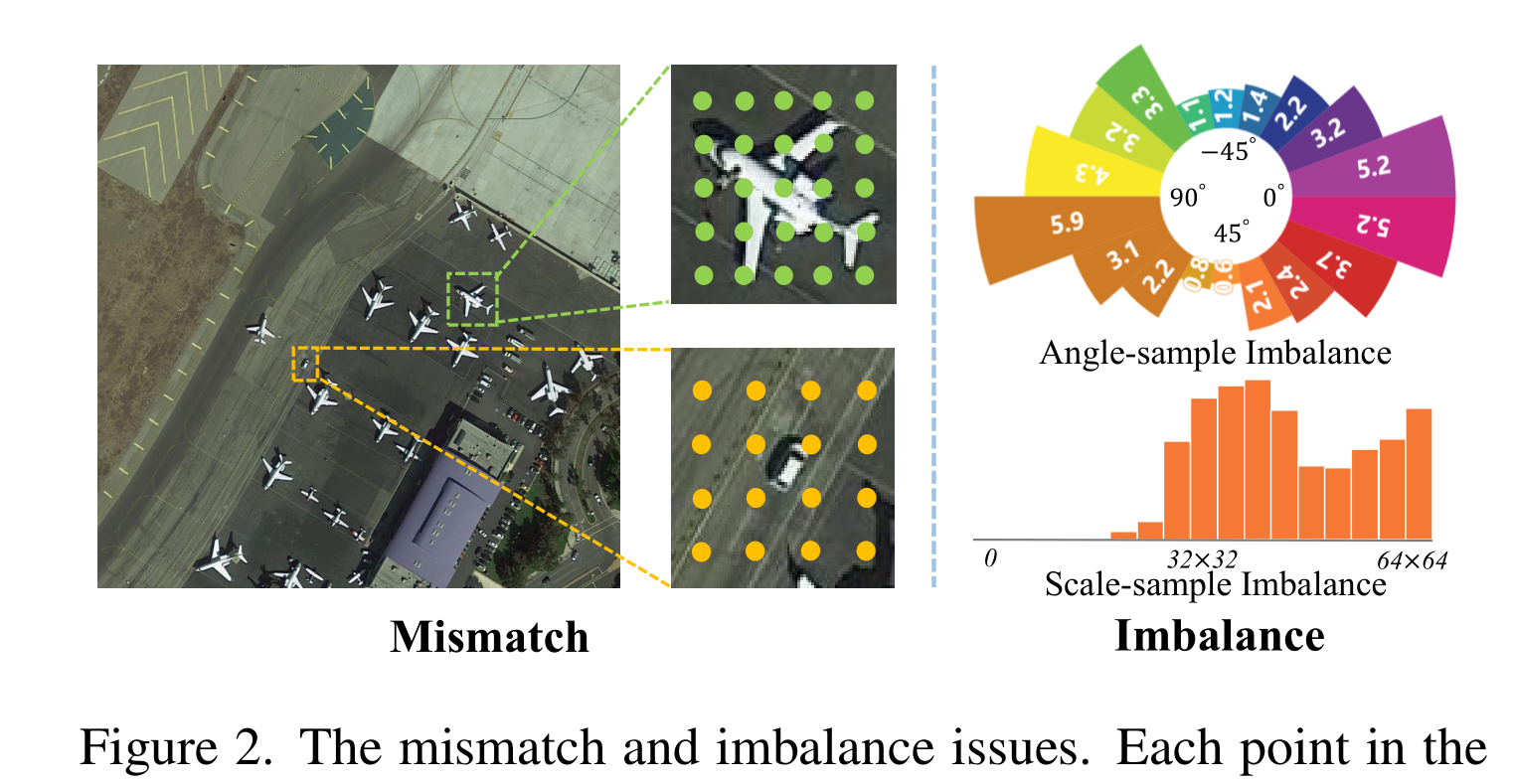
不匹配和不平衡问题非常明显。首先,在位置先验、特征和实例之间存在相互不匹配的问题。尽管一些自适应标签分配方案可能会探索更好的先验框或点的正负划分,但先验后面的采样特征位置仍然是固定的,派生的先验仍然是静态和均匀定位的,大多数先验偏离了微小物体的主体。无论我们如何划分正负样本,先验和特征本身都不能很好地匹配定向微小物体的极端形状。其次,现有的检测器对于定向和微小的物体容易产生偏差和不平衡。更准确地说,对于基于锚的检测器,形状与锚盒不同的gt将产生低IoU,导致缺乏阳性样本。
方法
上述问题促使作者设计一个更加动态和平衡的学习管道,用于定向微小目标检测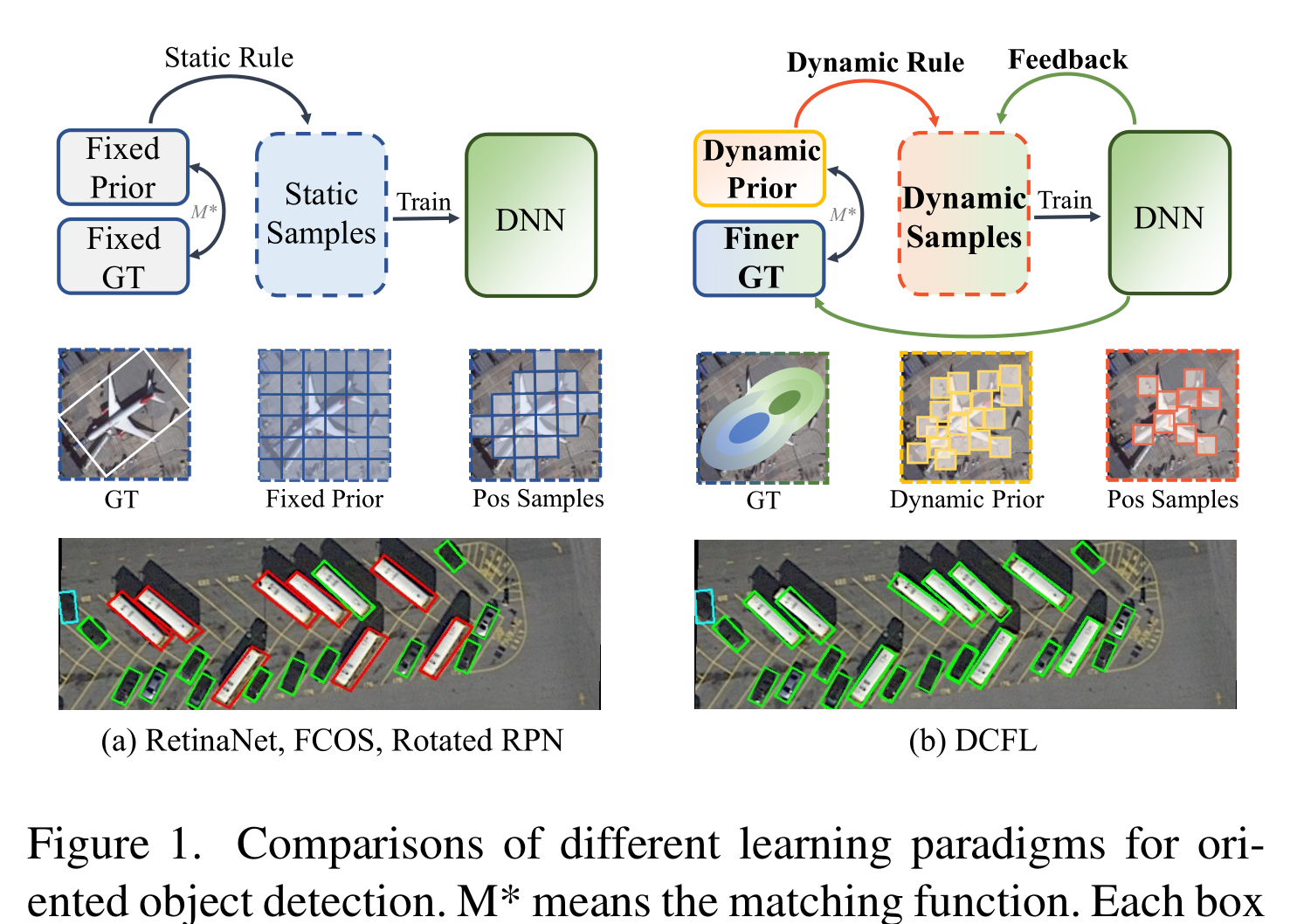
作者通过以动态方式重新制定先验、标签分配和gt表示来缓解不匹配问题,这些都可以由深度神经网络(DNN)更新。
同时,作者以从粗到精的方式动态渐进地分配标签,以寻求对各种实例的平衡监督,即缓解不平衡问题。
具体来说,作者引入了动态先验捕获块(PCB)学习先验,在保留先验物理意义的同时自适应调整先验位置。PCB(的设计灵感来源于DETR 和 Sparse R-CNN [48] 这两种检测框架的可学习提案(learnable proposals)范式。这种范式在目标检测中摒弃了预定义先验与特征之间的匹配问题。(ps:DETR(Detection Transformer)和Sparse R-CNN是两种基于Transformer或者采用Transformer部分结构的目标检测方法,它们放弃了传统的锚框(Anchor-based)机制,转而采用动态生成、可学习的区域提议方式来定位和分类目标。这种方式避免了因预先设定不同尺寸和比例锚框与实际目标可能不匹配而导致的问题,提高了模型在处理各种复杂场景下的性能和效率。)
基于动态先验,作者进一步选择跨FPN层的粗略正样本(CPS, Cross-FPN-layer Coarse Positive Sample)作为候选对象进行标签分配。实现这一CPS选择的方法是通过计算真值gt与动态先验之间的广义 Jensen-Shannon 散度。
广义Jensen-Shannon散度(GJSD)在本场景中的应用能够扩大粗略正样本(CPS)的搜索范围,不仅包括目标物体的邻近空间位置,还涵盖了相邻的不同特征金字塔网络(FPN)层级。这种扩展有助于为形状极端的目标物体提供更多的候选框,从而提高检测的召回率。
在确定了CPS候选集合之后,作者利用模型预测结果(后验概率)对这些候选框进行重新排序,并采用更精细的动态高斯混合模型(Dynamic Gaussian Mixture Model, DGMM)来表示真值(ground truth)。通过DGMM,我们可以过滤掉质量较低的样本,确保仅保留高质量的候选框用于训练和优化。
简而言之:作者提出使用GJSD构造粗阳性样本(CPS),并用更精细的动态高斯混合模型(DGMM)表示对象,获得粗到细的标签分配。
Overview
给定一组密集先验P∈R W×H×C (W ×H为特征图大小,C为形状信息个数,为简单起见,每个特征点有一个先验),目标检测器通过深度神经网络(Deep Neural Network, DNN)将集合P重新映射为最终检测结果D,可以简化为:

显然DNNh为检测头,检测结果D包含两部分,分类分数D cls∈R W×H×A (A为分类号),框位置D reg∈R W×H×B (B为框参数号)。
为了训练DNN h,我们需要在先验集P和gt集gt之间找到合适的匹配,并为P分配pos/ negative标签来监督网络的学习。
对于静态分配器(如RetinaNet[30]),可以通过手工匹配函数M s获得pos标签集G: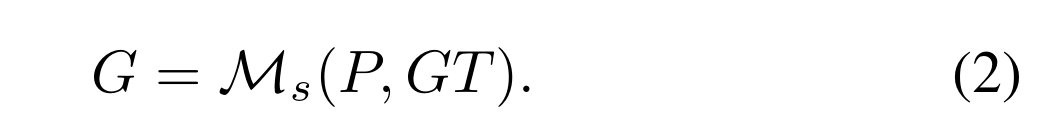
对于动态分配器[14,24,38],他们倾向于同时利用先验信息P和后验信息(预测)D,然后应用预测感知映射M d来得到集合G:
pos/neg标签分离后,损失函数可归纳为两部分:
aha,our work
我们以动态的方式对先验、标签分配和gt表示进行建模,以减轻不匹配问题。
ps:~表示动态项
和之前的公式没区别,就是变成动态的了
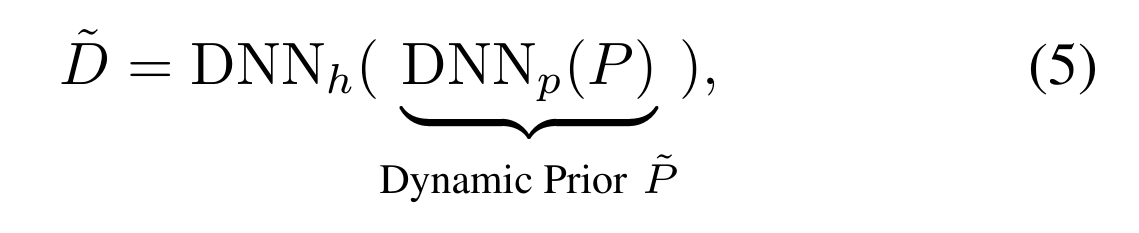
P~ = DNNp(P),D~ = DNNh(P~)。DNNp是一个可学习的块,包含在检测头中以更新先验。
将匹配函数重新表述为从粗到精的范式:
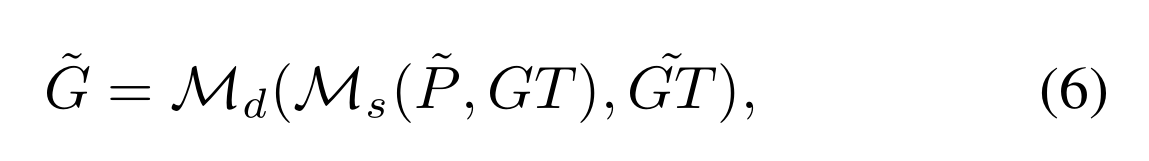
~GT(Ground Truth)通过动态高斯混合模型(Dynamic Gaussian Mixture Model, DGMM)得到了更为精细的表示
首先使用了一个经过调整的静态分配器M s 来处理带有动态元素的先验信息 ? P 和不变的真值GT,得到初步的标签分配结果。然后,再将这一初步分配结果作为输入,与另一个动态更新的真值 ~GT 一起送入动态分配器M d 进行进一步优化处理
简而言之,最终损失模型为:
Dynamic Prior
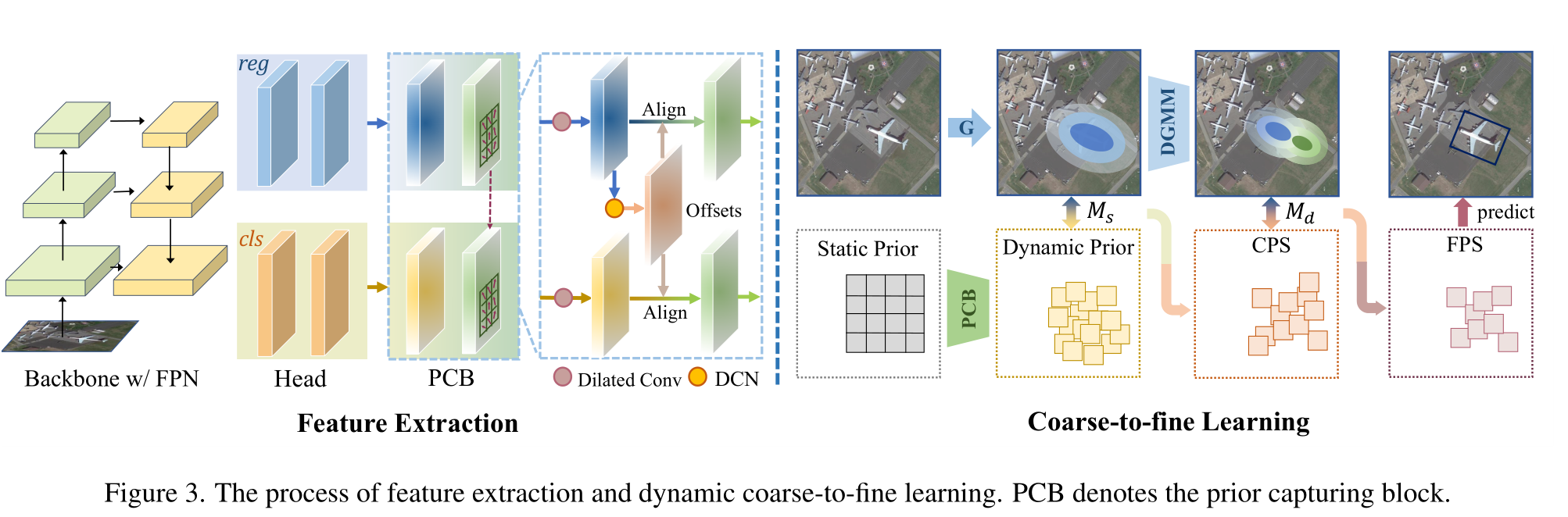
受DETR和Sparse R-CNN[48]中提议更新的纯可学习范式的启发,我们建议在先验中引入更多的灵活性来缓解不匹配问题。此外,我们保留了先验的物理意义,其中每个先验代表一个特征点,继承了密集检测器的快速收敛能力。所提出的先验捕获块(PCB)的结构如图所示,其中部署扩展卷积来考虑周围信息,然后利用可变形卷积网络(Deformable convolution Network, DCN)[9]来捕获动态先验。此外,我们利用从回归分支中学习到的偏移量来指导分类分支的特征提取,从而使两个任务更好地对齐。
简单注释:
-
Backbone with FPN: 主要负责获取不同层次的特征表示,FPN能够有效地合并来自不同层级的特征以获得更好的语义理解能力。
-
Head: 根据之前得到的特征映射生成候选区域(RoIs),然后进一步细化这些区域以便准确地标记物体位置及类型。
-
PCB: 动态先验捕获块,它的主要作用是在不同的特征级别之间建立联系,从而更好地捕获场景中的上下文信息。具体来说,它包含了一系列的卷积层、池化层以及其他一些变换函数,如align operation,旨在优化特征表达的质量。
-
Dynamic Coarse-to-Fine Learning: 这一部分涉及到两种类型的prior - 静态 prior 和 动态 prior。静态 prior 在训练开始时就已知或者固定不变;而动态 prior 则随着训练进程不断更新变化。此外,CPS(Coarse Prior Selection)和FPS(Fine Prior Selection)用来决定哪些prior应该被用作指导后续的特征选择和整合工作。
动态先验捕获的过程如下:
首先,我们对每个先验位置p(x, y)进行初始化,其值基于特征点的空间位置s设定。这里的特征点位置s经过重新映射至原始图像坐标系。
然后,在每一次迭代过程中,我们将网络前向传播以获取每个先验位置对应的偏移量集合?o。这意味着网络会学习到每个初始先验框相对于真实目标位置的调整信息,这些偏移量用于更新每个先验框的位置,使其更加接近于实际物体边界。
通过这种方式,模型可以动态地根据输入数据自适应地调整先验框的位置,而不是依赖固定的预定义锚框或先验分布,从而更有效地定位和检测具有各种形状和大小的目标物体。这一机制有助于解决传统方法中由于预设先验与目标物体实际位置不匹配而导致的问题,提高检测性能和准确性。
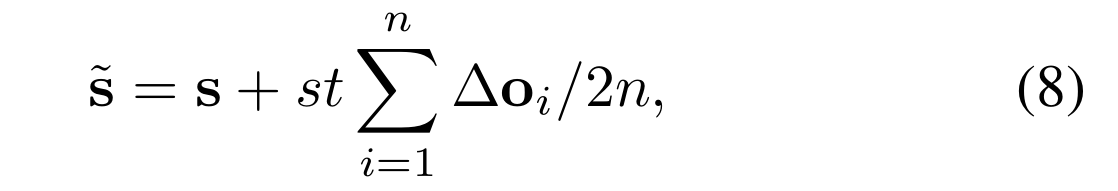
“st” 代表特征图的步长(stride),它决定了特征图相对于原始图像空间分辨率的下采样程度。而 "n"则表示每个先验位置所对应的偏移量集合中偏移的数量
最后,我们利用二维高斯分布N p(μp,Σ p),它被证明有利于小物体[58,61]和定向物体[61,63]来确定首选位置。具体地说,动态的~ s作为高斯的平均向量μp。我们在每个特征点上预设一个与RetinaNet[30]中一样的方形先验(w,h,θ),然后通过[64]计算协方差矩阵Σ p: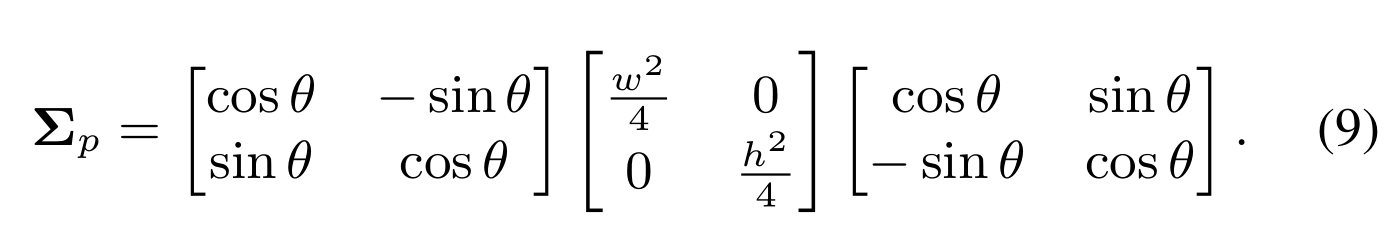
Coarse Prior Matching
给定一组先验框,在目标检测任务中,一种基本的标签分配规则是为特定的真值gt指定一个候选真实预测样本的范围。一些自适应策略将给定真实标注gt的候选框限制在单个特征金字塔网络(FPN)层内[14,23,68],而另一些方法则允许所有层级作为候选[67, 71]。
然而,对于定向微小物体而言,前者的严格启发式规则可能会导致最优层级选择的不足,因为微小物体的特征可能在不同层级上表达不充分;而后者的宽松策略虽然扩大了搜索范围,但可能导致模型收敛速度变慢的问题[32]。这是因为过多且跨层级的候选框会增加计算负担和噪声干扰,影响训练效率和最终检测性能。因此,对于定向微小物体的检测,需要寻找一种既能充分利用多层特征信息又不会显著降低训练效率的优化策略来进行标签分配。
因此,作者提出了一种跨FPN层的粗略正样本(Cross-FPN-layer Coarse Positive Sample, CPS)候选方案。相比于全FPN层的方式,CPS候选集缩小了样本范围,同时摒弃了单一层级的启发式方法。
在CPS策略中,我们对候选范围进行了适度扩展,不仅包含目标物体本身的精确空间位置,还延伸到了其邻近的空间位置以及相邻的FPN层。这样的设计保证了与单一层次启发式方法相比,能够获取到相对多样且充足的候选样本,从而缓解了样本数量不平衡的问题,并有助于提高检测器对定向微小目标的识别和定位能力。通过这种方式,在保持搜索范围合理的同时,优化了模型对于不同大小、形状及方向的目标检测性能。
具体来说,在构建CPS时,作者采用Jensen-Shannon散度(JSD)[13]来实现相似性度量。JSD继承了Kullback-Leibler散度(KLD)[63]的尺度不变特性,能够有效衡量目标真实框(ground truth, gt)与其邻近非重叠先验框之间的相似度[58, 63]。更重要的是,JSD克服了KLD不对称性的缺点。
然而,对于高斯分布之间的Jensen-Shannon散度不存在封闭形式解[39]。因此,我们采用了Generalized Jensen-Shannon Divergence(广义Jensen-Shannon散度,GJSD)[39]作为替代方案,它为高斯分布提供了一个封闭形式的解决方案。这样,我们可以通过计算GJSD来精确地量化候选样本与gt之间的相似度,并在此基础上筛选出合适的正样本,从而优化检测模型的学习和性能表现。
例如,两个高斯分布N p(μp,Σ p)和N g(μg,Σ g)之间的GJSD定义为:
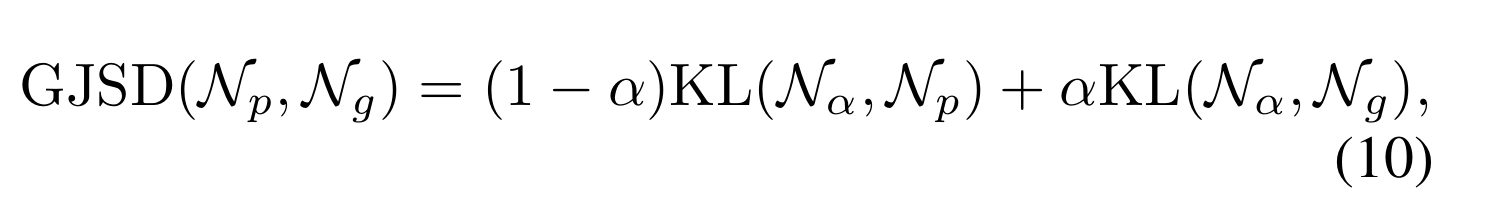
KL指的是Kullback-Leibler散度(KLD), N α (μ α ,Σ α ) 由下式给出:
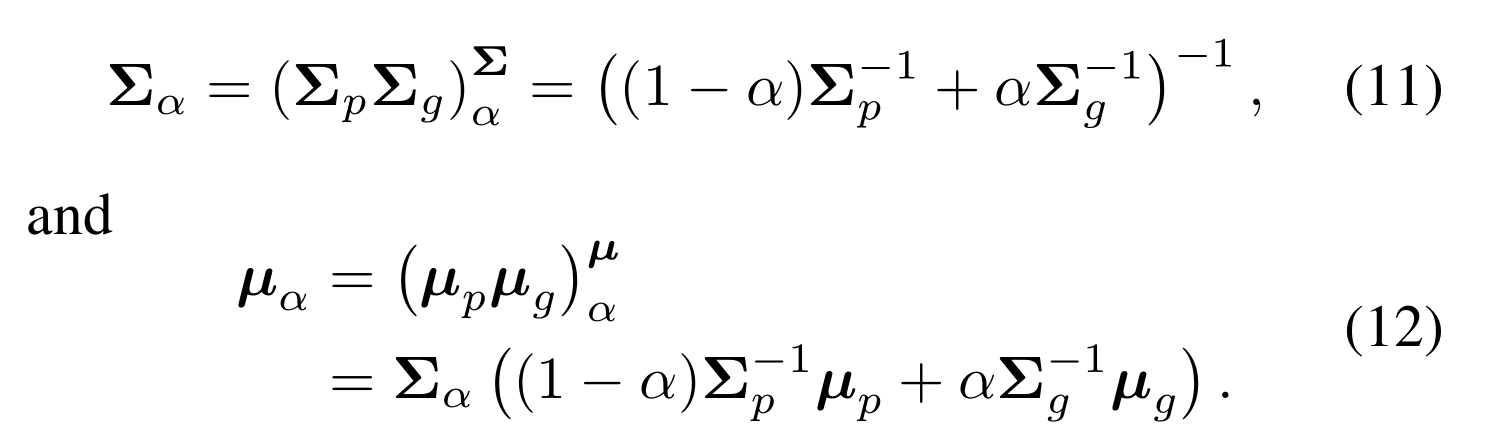
在相似性度量中,α是控制两个分布权重的参数
最后,对于每一个目标真实框(gt),我们选择与其具有前K个最高广义Jensen-Shannon散度(GJSD)得分的先验框作为粗略正样本集(Coarse Positive Samples, CPS)。而剩余的先验框则被视作负样本。这种基于排序的方式与GJSD测量法相结合,用于构建跨FPN层的CPS。这样的粗匹配策略在公式6中的M_s中起到关键作用,它旨在解决MaxIoU匹配方法在处理异常角度和尺度时可能引发的类别不平衡问题。通过这种方式筛选CPS,可以更好地涵盖不同尺度和方向的目标,并有助于训练过程中正负样本的均衡分布,从而提升检测模型在各种复杂情况下的性能和鲁棒性。
Finer Dynamic Posterior Matching
基于粗略正样本(Coarse Positive Sample, CPS)候选集,我们设计了一种动态后验(预测)匹配规则M_d,用于过滤掉质量较低的样本。这个M_d包含两个关键组成部分:一是后验重排序策略,二是动态高斯混合模型(Dynamic Gaussian Mixture Model, DGMM)约束。
-
后验重排序策略:
在初步筛选出CPS之后,利用网络当前的预测结果(即后验概率分布)对这些粗略正样本进行重新排序。这一步骤可以依据预测置信度、类别得分或其他相关指标来调整每个候选框的重要性,并进一步优化标签分配的准确性。 -
动态高斯混合模型(DGMM)约束:
使用DGMM对真实标注(ground truth)进行精细化建模,以更精确地模拟目标物体的空间分布和形状变化。在匹配过程中,将DGMM与候选框的预测信息相结合,通过比较候选框与DGMM表示的真实标注之间的相似性,可以有效地剔除那些与真实目标不匹配或者质量低下的样本。
通过这样的设计,M_d能够根据模型的实时预测性能和GT的精细表示对CPS进行动态筛选和优化,从而提高目标检测算法对于各类目标,特别是微小或定向目标的识别能力和鲁棒性。
在CPS中,我们根据候选样本的预测得分进行重新排序。换句话说,我们通过进一步细化样本成为真实预测的可能性(Possibility of becoming True predictions, PT)来优化正样本的选择。PT是一个线性组合,结合了样本的预测分类得分和与真实标注(ground truth, gt)的位置匹配得分
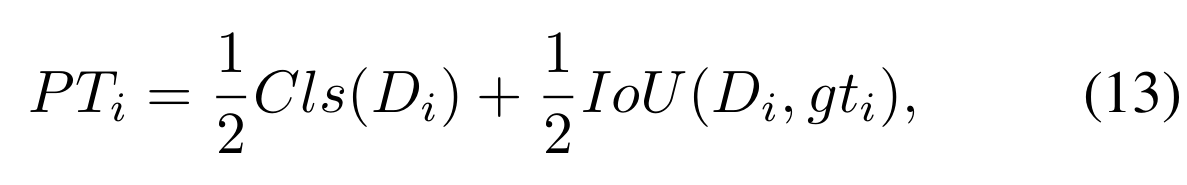
Cls为预测的分类置信度,IoU为预测位置与其对应的gt位置之间的旋转IoU。我们选择Q最高PT的候选者作为中等阳性样本(MPS)候选者。
在上述基于粗略正样本(CPS)的筛选之后,为了进一步获取更为精确的正样本集合(Finer Positive Samples, FPS),我们采用了一种更精细的目标实例表示方法进行过滤。不同于以往研究中使用的中心概率图[53]或单高斯模型[23,64],我们使用了更为精细的动态高斯混合模型(DGMM)来描述目标实例。
具体来说,对于每一个特定的目标实例gt_i,其几何中心(cx_i, cy_i)被用作第一个高斯分布的均值向量μ_i,1;而语义中心(sx_i, sy_i)则是通过对MPS(可能是之前提到的、经过初步筛选后的高质量样本集)中样本位置的平均计算得出,作为第二个高斯分布的均值向量μ_i,2。
即我们通过以下方式参数化目标实例:
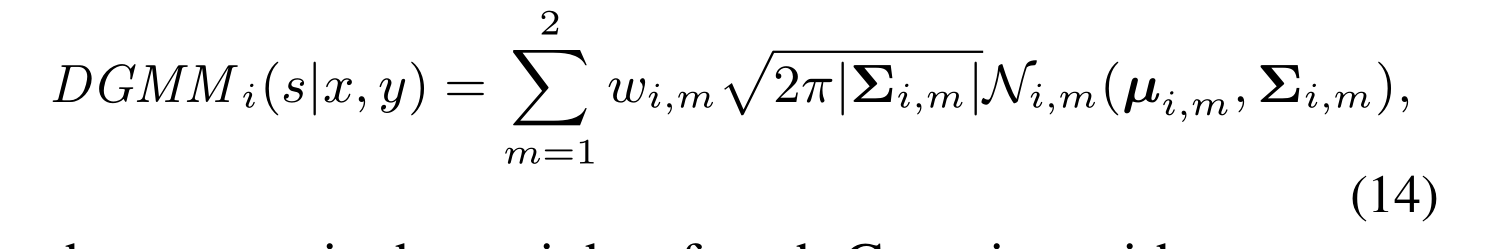
其中,w_i,m 是每个高斯分布的权重,并且所有权重之和为1;Σ_i,m 等于gt的协方差矩阵Σ_g。
MPS中的每个样本都有一个对应的DGMM得分DGMM(s|MPS),我们将那些对任意gt具有DGMM(s|MPS) < e^(-g)的样本设置为负样本,这里的g是一个可调整的阈值。这样,我们就能够有效地剔除与真实目标匹配度较低的样本,从而确保FPS集中包含的是更有可能是真实目标的高质量候选框。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 尚硅谷大数据项目《在线教育之实时数仓》笔记010
- 选择排序
- 使用java模拟兰顿蚂蚁
- 15软件2班Web开发课学期总结
- 基础算法(6):前缀和
- HTML+JS + layer.js +qrcode.min.js 实现二维码弹窗
- spring国际化 - i18n
- 系列十四、理解MySQL varchar(50)
- 基于SpringBoot实现的医院预约挂号系统
- concrt140.dll丢失修复方法分享,concrt140.dll下载方法修复教程