java基础知识②:多线程编程、IO流和网络编程、泛型、集合框架
目录
具体如下👀:
一、多线程编程
1、什么是线程?什么是进程?区别又是什么?
👌在Java中,进程是操作系统分配资源的最小单位,指一个正在运行的应用程序实例,每个进程都有自己独立的内存空间和系统资源。Java中可以使用`ProcessBuilder`类或`Runtime`类创建和管理进程。通过调用操作系统命令或执行外部程序,可以创建新的进程并与其进行通信。
而线程是进程内的执行单元,一个进程可以包含多个线程,每个线程都可以独立执行代码。Java中的线程由`java.lang.Thread`类表示。可以通过继承`Thread`类或实现`Runnable`接口来创建线程。 线程之间共享进程的内存空间,可以访问相同的变量和对象。线程可以并发执行,通过调度器分配CPU时间片来实现多线程的并发执行。即进程是线程的容器,Java中的线程是指程序执行的最小单位,它允许程序同时执行多个任务。
进程和线程的区别如下:
- 地址空间:同一进程的线程共享本进程的地址空间,而进程之间则是独立的地址空间。
- 资源拥有:同一进程内的线程共享本进程的资源,但是进程之间的资源是独立的。
线程可以分为两种类型:用户线程和守护线程。用户线程在程序运行过程中创建并执行,而守护线程是一种特殊的线程,它会在所有用户线程结束后自动退出。
多线程是指在一个程序中同时运行多个线程。
多线程编程是通过创建并运行多个线程,使得程序可以同时执行多个任务。多线程编程可以提高程序的性能和响应能力。通过将任务分配给不同的线程并同时执行,可以充分利用多核处理器的能力。
在Java中,实现多线程编程有两种方式:继承Thread类和实现Runnable接口。继承Thread类的方式需要重写run()方法,将要执行的代码写在run()方法中。实现Runnable接口的方式需要实现run()方法,同样将要执行的代码写在run()方法中。两种方式的差别在于,使用Runnable接口可以避免单继承的限制,使得代码更加灵活。
创建线程的两种方式示例代码如下:
- 继承Thread类方式:
public class MyThread extends Thread {
@Override
public void run() {
// 线程执行的代码
}
}- 实现Runnable接口方式:
public class MyRunnable implements Runnable {
@Override
public void run() {
// 线程执行的代码
}
}- 创建并启动线程的代码示例:
public class Main {
public static void main(String[] args) {
// 继承Thread类方式创建并启动线程
MyThread myThread = new MyThread();
myThread.start();
// 实现Runnable接口方式创建并启动线程
MyRunnable myRunnable = new MyRunnable();
Thread thread = new Thread(myRunnable);
thread.start();
}
}在多线程编程中,线程之间可能存在竞态条件和资源共享的问题。线程之间可以通过共享内存进行通信,但需要注意线程安全性和同步的问题,以避免出现竞态条件和数据不一致的情况。竞态条件是指多个线程同时访问某个共享资源,由于执行顺序不确定性,导致结果的不确定性。为了避免竞态条件,可以使用互斥锁、同步块等机制保证线程的同步执行。资源共享问题是指多个线程同时访问某个共享资源,由于资源的读写操作不一致性,导致结果的不一致性。为了解决资源共享问题,可以使用信号量、互斥锁等机制保证资源的正确读写。
Java提供了一些同步机制来解决多线程编程中的竞态条件和资源共享问题。其中最常用的同步机制是synchronized关键字和Lock接口。synchronized关键字可以用来修饰方法和代码块,它能够保证同一时刻只有一个线程访问被修饰的代码。Lock接口提供了更灵活的方式来进行同步操作,它允许多个线程同时访问被修饰的代码,但在访问之前需要先获取锁,并且在访问结束后释放锁。
下面是使用synchronized关键字和Lock接口进行同步的示例代码:
- 使用synchronized关键字同步:
public class Counter {
private int count = 0;
public synchronized void increment() {
count++;
}
public synchronized int getCount() {
return count;
}
}- 使用Lock接口同步:
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
public class Counter {
private int count = 0;
private Lock lock = new ReentrantLock();
public void increment() {
lock.lock();
try {
count++;
} finally {
lock.unlock();
}
}
public int getCount() {
lock.lock();
try {
return count;
} finally {
lock.unlock();
}
}
}多线程编程还可以利用线程池来管理和调度线程。线程池是一种预先创建一组线程并维护它们的执行队列的技术,它可以重复使用已经创建的线程,避免了线程的创建和销毁开销。Java提供了Executors类和ThreadPoolExecutor类来创建和管理线程池。Executors类提供了一些静态方法用于创建不同类型的线程池,而ThreadPoolExecutor类则提供了更灵活的方式进行线程池的定制。
使用线程池可以提高多线程编程的效率和可维护性,特别是在需要大量执行任务并且任务之间存在耗时操作时,线程池可以有效地控制并发线程的数量,避免资源的过度占用和线程的过度竞争。
下面是使用线程池的示例代码:
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class Main {
public static void main(String[] args) {
ExecutorService executor = Executors.newFixedThreadPool(10);
for (int i = 0; i < 100; i++) {
executor.execute(new MyRunnable());
}
executor.shutdown();
}
}- 线程生命周期:
线程具有不同的生命周期,包括新建(New)、就绪(Runnable)、运行(Running)、阻塞(Blocked)和终止(Terminated)等状态。
线程可以通过调用`start()`方法启动,进入就绪状态,等待调度器分配CPU时间片来执行。
在运行状态时,线程执行其`run()`方法中的代码。
阻塞状态表示线程暂时无法执行,可能是因为等待某个条件满足或等待某个资源释放。
终止状态表示线程执行完毕或出现异常而终止。
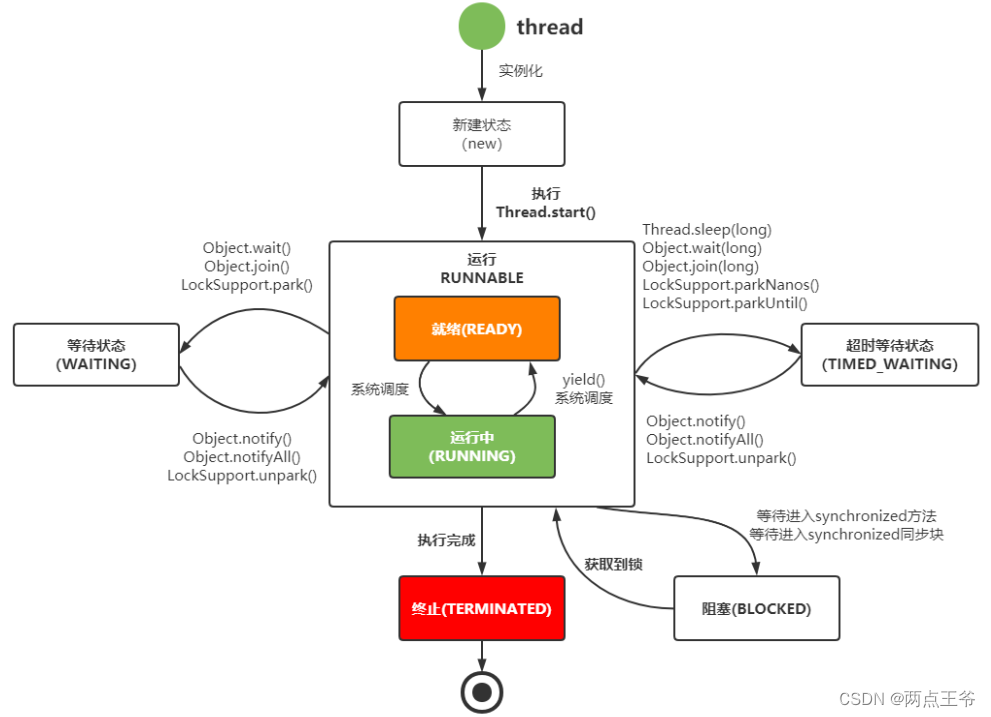
以上就是对Java中线程、多线程和多线程编程的详细讲解。通过了解线程的创建、同步和调度机制,我们可以更好地理解多线程编程的原理和应用。在实际开发中,合理地使用多线程可以提高程序的性能和响应速度,但同时也需要注意线程安全和资源共享的问题,避免出现竞态条件和数据不一致的情况。
二、IO流
Java中的IO (Input/Output) 是对输入和输出进行操作的一组类和接口。IO流是指Java程序通过流的方式读取或写入数据。它将数据从一个地方传输到另一个地方。
Java的IO功能非常强大且灵活,可以用于读取和写入各种类型的数据,包括文件、网络连接、内存数据等。
Java IO包括以下几个关键组件:
- 输入流(InputStream):用于从数据源(如文件、网络等)读取数据。
- 输出流(OutputStream):用于向目标(如文件、网络等)写入数据。
- 读取器(Reader):用于从字符数据源中读取数据。
- 写入器(Writer):用于向字符目标写入数据。
Java IO流分为字节流和字符流:
- 字节流(Byte Stream):以字节为单位读取和写入数据,适用于处理二进制数据或字节流数据。字节流包括InputStream和OutputStream。
- 字符流(Character Stream):以字符为单位读取和写入数据,适用于处理文本文件。字符流包括Reader和Writer。
Java中的IO流有以下几个常用的类和接口:
-
InputStream:抽象类,实现了字节输入流的基本功能。
- FileInputStream:用于从文件中读取字节。
- ByteArrayInputStream:用于从内存中的字节数组中读取字节。
-
OutputStream:抽象类,实现了字节输出流的基本功能。
- FileOutputStream:用于向文件写入字节。
- ByteArrayOutputStream:用于向内存的字节数组中写入字节。
-
Reader:抽象类,实现了字符输入流的基本功能。
- FileReader:用于从文件中读取字符。
- CharArrayReader:用于从内存的字符数组中读取字符。
-
Writer:抽象类,实现了字符输出流的基本功能。
- FileWriter:用于向文件写入字符。
- CharArrayWriter:用于向内存的字符数组中写入字符。
以上是Java IO的基本结构,接下来详细介绍各个组件的使用方法和常见功能。
- InputStream和OutputStream:
InputStream和OutputStream是Java IO中最基本的两个类,用于进行字节流的读取和写入操作。常用的子类有FileInputStream、FileOutputStream、ByteArrayInputStream和ByteArrayOutputStream等。
使用InputStream读取数据的基本步骤:
- 创建一个InputStream对象,选择合适的子类。
- 调用read()方法读取字节,并将其赋值给一个整型变量。
- 判断读取的返回值,如果是-1表示已经到达文件末尾,否则将读取的字节转换成字符或其他需要的类型。
示例代码如下:
try (InputStream inputStream = new FileInputStream("input.txt")) {
int data;
while ((data = inputStream.read()) != -1) {
char c = (char) data;
System.out.print(c);
}
} catch (IOException e) {
e.printStackTrace();
}使用OutputStream写入数据的基本步骤:
- 创建一个OutputStream对象,选择合适的子类。
- 调用write()方法将字节写入流中。
- 最后要调用close()方法关闭流。
示例代码如下:
try (OutputStream outputStream = new FileOutputStream("output.txt")) {
String data = "Hello, World!";
byte[] bytes = data.getBytes();
outputStream.write(bytes);
} catch (IOException e) {
e.printStackTrace();
}- Reader和Writer:
Reader和Writer是字符流的基本操作类,用于读取和写入字符数据。常用的子类有FileReader、FileWriter、CharArrayReader和CharArrayWriter等。
使用Reader读取字符的基本步骤:
- 创建一个Reader对象,选择合适的子类。
- 调用read()方法读取字符,并将其赋值给一个整型变量。
- 判断读取的返回值,如果是-1表示已经到达文件末尾,否则将读取的字符转换成字符串或其他需要的类型。
示例代码如下:
try (Reader reader = new FileReader("input.txt")) {
int data;
while ((data = reader.read()) != -1) {
char c = (char) data;
System.out.print(c);
}
} catch (IOException e) {
e.printStackTrace();
}使用Writer写入字符的基本步骤:
- 创建一个Writer对象,选择合适的子类。
- 调用write()方法将字符写入流中。
- 最后要调用close()方法关闭流。
示例代码如下:
try (Writer writer = new FileWriter("output.txt")) {
String data = "Hello, World!";
writer.write(data);
} catch (IOException e) {
e.printStackTrace();
}此外还有缓存流、对象流。
- 缓冲流(Buffered Stream):
缓冲流是对基本的IO流进行了包装,提供了缓冲写入和读取的功能,能够提高读写的效率。常用的缓冲流有BufferedInputStream、BufferedOutputStream、BufferedReader和BufferedWriter等。
使用缓冲流的基本步骤:
- 创建一个基本的IO流对象。
- 将基本的IO流对象作为参数传递给缓冲流的构造方法,创建一个缓冲流对象。
- 使用缓冲流进行读写操作。
- 最后要调用close()方法关闭流。
示例代码如下:
try (BufferedReader reader = new BufferedReader(new FileReader("input.txt"));
BufferedWriter writer = new BufferedWriter(new FileWriter("output.txt"))) {
String line;
while ((line = reader.readLine()) != null) {
writer.write(line);
writer.newLine();
}
} catch (IOException e) {
e.printStackTrace();
}- 对象流(Object Stream):
对象流用于对Java对象进行读写操作,可以将Java对象序列化为字节流,或从字节流反序列化为Java对象。常用的对象流有ObjectInputStream和ObjectOutputStream。
将对象写入流的基本步骤:
- 创建一个输出流对象,用于写入字节流。
- 创建一个对象流对象,将输出流对象作为参数传递给构造方法,用于写入对象。
- 调用对象流的writeObject()方法将Java对象写入流中。
- 最后要调用close()方法关闭流。
示例代码如下:
try (ObjectOutputStream outputStream = new ObjectOutputStream(new FileOutputStream("object.txt"))) {
Student student = new Student("Tom", 20);
outputStream.writeObject(student);
} catch (IOException e) {
e.printStackTrace();
}从流中读取对象的基本步骤:
- 创建一个输入流对象,用于读取字节流。
- 创建一个对象流对象,将输入流对象作为参数传递给构造方法,用于读取对象。
- 调用对象流的readObject()方法从流中读取Java对象。
- 最后要调用close()方法关闭流。
示例代码如下:
try (ObjectInputStream inputStream = new ObjectInputStream(new FileInputStream("object.txt"))) {
Student student = (Student) inputStream.readObject();
System.out.println(student);
} catch (IOException | ClassNotFoundException e) {
e.printStackTrace();
}
以上是Java中IO和IO流相关的基本知识和常见操作。通过对这些知识点的掌握,可以实现对文件、网络和其他数据源的读取和写入操作,方便地处理各种数据。
三、网络编程
网络编程是指利用计算机网络进行数据传输和通信的编程技术,Java语言提供了丰富的类库和API来支持网络编程。在Java中进行网络编程主要涉及以下几个方面的知识:网络通信模型、Socket编程、URL编程、HTTP编程和Web服务。
-
网络通信模型 网络通信模型包括C/S模型(Client/Server)和P2P模型(Peer-to-Peer)两种模式。C/S模型是指客户端和服务器之间的通信模式,客户端发送请求,服务器进行响应;P2P模型是指对等节点之间进行直接通信,没有固定的服务器。
-
Socket编程 Socket是网络编程中最基础的类,它是实现网络通信的一种机制。Java提供了Socket类和ServerSocket类来支持Socket编程。Socket类用于客户端,它提供了与服务器建立连接、发送请求和接收响应的方法;ServerSocket类用于服务器端,用于监听客户端的请求并进行响应。
-
URL编程 URL(Uniform Resource Locator)是用于定位互联网上资源的地址。Java提供了URL类来进行URL编程,通过URL类可以获取资源的各种信息,如主机名、端口号、路径、查询参数等。
-
HTTP编程 HTTP(Hypertext Transfer Protocol)是用于在Web中传输超文本的协议。Java提供了URLConnection类和HttpURLConnection类来进行HTTP编程,可以通过这些类来发送HTTP请求和接收HTTP响应,进行与Web服务器的交互。
-
Web服务 Web服务是指通过Web进行数据交互的一种服务。Java提供了JAX-WS和JAX-RS两个API来支持Web服务的开发。JAX-WS是用于开发SOAP协议的Web服务的API,它使用XML格式进行数据交互;JAX-RS是用于开发RESTful风格的Web服务的API,它使用简单的HTTP方法进行数据交互。
在进行Java网络编程时,需要注意以下几个方面的问题:
- 异常处理:网络通信中可能出现各种异常,如连接异常、传输异常等,需要合理处理这些异常,确保程序的稳定性。
- 线程安全:网络通信通常涉及到多线程的使用,需要注意线程安全的问题,避免出现数据竞争和并发访问的问题。
- 性能优化:网络通信涉及到数据传输和响应的时间,需要进行性能优化,如使用缓冲区、合理设置超时时间等。
- 安全性:网络通信中可能涉及到数据的传输和交换,需要保证数据的安全性,如使用加密算法进行数据加密、使用数字签名进行数据验证等。
四、泛型
泛型是一种参数化类型的机制,它使我们能够在编译时期指定代码中的某些数据类型。泛型是Java的一个重要特性,它提供了一种在代码中定义、使用和操作参数化类型的机制。泛型的引入使得我们能够在编译时检查和确保类型的安全性,我们可以创建更通用的数据结构和算法,使其能够处理各种类型的数据,并且减少了类型转换的需要。泛型的主要目的是提高代码的重用性和类型安全性。泛型还可以在编译时期捕获类型错误,并减少运行时错误的发生。
-
泛型类和泛型方法:
- 泛型类是指具有一个或多个类型参数的类。通过在类名后面的尖括号中定义类型参数,可以在类的任何位置使用这些参数。例如,
List<T>中的T就是一个类型参数。 - 泛型方法是指具有一个或多个类型参数的方法。类型参数可以在方法的返回类型之前定义,并在方法体内使用。例如,
<T> T getElement(List<T> list)是一个泛型方法,它返回一个与传入列表类型相同的元素。
- 泛型类是指具有一个或多个类型参数的类。通过在类名后面的尖括号中定义类型参数,可以在类的任何位置使用这些参数。例如,
-
泛型类型限定和通配符:
- 通配符
?表示未知类型,可以用来指定泛型类型的上限或下限。 - 上限通配符
<? extends T>用来限定泛型类型的上界,表示类型参数必须是T或T的子类。例如,List<? extends Number>表示一个列表,其中的元素类型是Number或其子类。 - 下限通配符
<? super T>用来限定泛型类型的下界,表示类型参数必须是T或T的父类。例如,List<? super Integer>表示一个列表,其中的元素类型是Integer或其父类。 - 例如,我们可以使用
List<? extends Number>来表示一个只包含Number及其子类的列表,并使用List<? super Integer>来表示一个只能接受Integer及其父类的列表。
- 通配符
-
类型擦除和类型转换:
- 泛型只存在于编译时期,在运行时会被擦除为原始类型。这是为了保持与之前的Java版本的兼容性。
- 类型擦除意味着在运行时无法访问参数化类型的具体信息,只能访问原始类型。例如,
List<Integer>在运行时会被擦除为List。 - 对于泛型类型的转换,可以使用强制类型转换或
instanceof关键字来判断具体类型,并进行相应的转换和操作。
-
泛型的类型推断和类型通配符限制:
- Java 7引入了“菱形操作符”
<>,可以通过编译器的类型推断来省略泛型参数的具体类型。 - 当使用泛型类型进行操作时,编译器会根据上下文推断出具体的类型参数。
- 类型通配符可以限制泛型类型的范围,从而增加类型安全性。通配符限制了方法可以接受的具体类型,但不会使方法参数具体化。
- Java 7引入了“菱形操作符”
总体而言,泛型提供了一种强类型的编程方式,增加了代码的可读性、可维护性和可扩展性。通过使用泛型,可以有效地减少代码中的类型转换,并提供编译时的类型检查,减少了运行时的错误。在实际开发中,合理使用泛型可以提高代码的质量和效率。
五、集合框架
Java集合是Java中用于存储数据的一种数据结构。它可以存储不同类型的对象,并提供了一套丰富的操作方法。Java集合框架提供了一系列的接口和类,用于操作集合。在Java集合框架中,集合被分为四个基本接口,即List、Set、Queue和Map。本文将从全面整体的角度详细讲解Java中集合的相关知识点。

1、集合框架的基本接口 Java集合框架中的四个基本接口是List、Set、Queue和Map。
List(列表):
- 特点:有序、可重复的集合,元素按照插入顺序排序。
- 常用实现类:ArrayList、LinkedList、Vector。
- ArrayList是一个动态数组,它可以根据需要自动扩展容量。LinkedList是一个双向链表,它可以在任意位置插入或删除元素。Vector是一个线程安全的动态数组,它的使用比较少。
- 示例代码:
List<String> list = new ArrayList<>();
list.add("Apple");
list.add("Orange");
list.add("Banana");
System.out.println(list);List接口提供了一系列常用的方法,如add()、get()、set()、remove()等。可以使用下标来访问List中的元素,下标从0开始。
Set(集):
- 特点:无序、不可重复的集合,不允许存储重复元素。
- 常用实现类:HashSet、LinkedHashSet、TreeSet。
- HashSet是一种基于哈希表的实现,它对元素进行散列,不保证元素的顺序。LinkedHashSet是一种基于哈希表和链表的实现,它保持元素的插入顺序。TreeSet是一种基于红黑树的实现,它对元素进行排序。
- 示例代码:
Set<String> set = new HashSet<>();
set.add("Apple");
set.add("Orange");
set.add("Banana");
System.out.println(set);Set接口提供了一系列常用的方法,如add()、contains()、remove()等。可以使用迭代器或增强for循环来遍历Set中的元素。
Queue(队列):
- 特点:先进先出(FIFO)的集合,可以用于实现任务调度、消息传递等场景。
- 常用实现类:LinkedList、ArrayDeque、PriorityQueue。
- LinkedList可以用作队列或栈,它实现了Queue和Deque接口。PriorityQueue是一种基于优先级堆的实现,它可以根据元素的排序顺序进行访问。
- 示例代码:
Queue<String> queue = new LinkedList<>();
queue.add("Apple");
queue.add("Orange");
queue.add("Banana");
System.out.println(queue);Queue接口提供了一系列常用的方法,如add()、offer()、remove()、poll()等。可以使用迭代器或增强for循环来遍历Queue中的元素。
集合的遍历方式:Iterator(迭代器)、for-each 循环、Java 8 的 Stream
Iterator(迭代器):
- 特点:用于遍历集合中的元素,提供了 hasNext() 和 next() 方法。
List<String> list = new ArrayList<>();
list.add("Apple");
list.add("Orange");
list.add("Banana");
Iterator<String> iterator = list.iterator();
while (iterator.hasNext()) {
String item = iterator.next();
System.out.println(item);
}集合的遍历方式:
-
for-each 循环:
List<String> list = new ArrayList<>();
list.add("Apple");
list.add("Orange");
list.add("Banana");
for (String item : list) {
System.out.println(item);
}迭代器:
List<String> list = new ArrayList<>();
list.add("Apple");
list.add("Orange");
list.add("Banana");
Iterator<String> iterator = list.iterator();
while (iterator.hasNext()) {
String item = iterator.next();
System.out.println(item);
}Java 8 的 Stream:
List<String> list = new ArrayList<>();
list.add("Apple");
list.add("Orange");
list.add("Banana");
list.stream().forEach(System.out::println);Map(接口):
它实现了键值对的存储方式。它是一个无序的集合,不能包含重复的键,但是可以包含重复的值。Map提供了常用的方法,用于添加、删除、查询和更新键值对。
- 常用的Map接口的实现类有HashMap、LinkedHashMap、TreeMap和Hashtable。
- HashMap是最常用的Map实现类,它根据键的hashCode值存储数据,具有很快的访问速度。它不保证键的顺序,允许使用null作为键或值。
- Map接口 Map是一种键值对的映射表。Map接口中的常用实现类有HashMap、LinkedHashMap和TreeMap。HashMap是一种基于哈希表的实现,它对键进行散列,不保证键的顺序。LinkedHashMap是一种基于哈希表和链表的实现,它保持键的插入顺序。TreeMap是一种基于红黑树的实现,它根据键的排序顺序进行访问。
Map<String, Integer> map = new HashMap<>();
map.put("apple", 1);
map.put("banana", 2);
map.put("orange", 3);
System.out.println(map.get("apple")); // 输出1
System.out.println(map.containsKey("banana")); // 输出true
System.out.println(map.containsValue(3)); // 输出true
map.remove("orange");
System.out.println(map.size()); // 输出2- LinkedHashMap继承自HashMap,它保证了元素的顺序按照插入的顺序或者访问的顺序进行迭代。
Map<String, Integer> map = new LinkedHashMap<>();
map.put("apple", 1);
map.put("banana", 2);
map.put("orange", 3);
for (Map.Entry<String, Integer> entry : map.entrySet()) {
System.out.println(entry.getKey() + ": " + entry.getValue());
}输出的顺序为插入的顺序:apple: 1 banana: 2 orange: 3
- TreeMap是一个有序的Map实现类,它根据键的自然顺序或者自定义的排序规则进行排序。
Map<String, Integer> map = new TreeMap<>();
map.put("apple", 1);
map.put("banana", 2);
map.put("orange", 3);
for (Map.Entry<String, Integer> entry : map.entrySet()) {
System.out.println(entry.getKey() + ": " + entry.getValue());
}输出的顺序为插入的顺序:apple: 1 banana: 2 orange: 3
- Hashtable是一个线程安全的Map实现类,它的方法都是同步的,但是性能比HashMap要差。它不允许使用null作为键或值。
Map<String, Integer> map = new Hashtable<>();
map.put("apple", 1);
map.put("banana", 2);
map.put("orange", 3);
System.out.println(map.get("apple")); // 输出1
System.out.println(map.containsKey("banana")); // 输出true
System.out.println(map.containsValue(3)); // 输出true
map.remove("orange");
System.out.println(map.size()); // 输出2Map接口提供了一系列常用的方法,如put()、get()、remove()等。可以通过键来访问Map中的值。
2、集合框架的常用类 除了基本接口外,Java集合框架还提供了一些常用的类,如Collections、Arrays和Iterator。
-
Collections类 Collections是一个包含一系列静态方法的实用类,用于操作集合。例如,可以使用Collections.sort()对List进行排序,使用Collections.shuffle()随机打乱List中的元素,使用Collections.reverse()反转List中的元素等。
-
Arrays类 Arrays是一个包含一系列静态方法的实用类,用于操作数组。例如,可以使用Arrays.sort()对数组进行排序,使用Arrays.binarySearch()在有序数组中搜索指定元素,使用Arrays.copyOf()复制数组等。
-
Iterator接口 Iterator是一个用于遍历集合的接口,它提供了一系列用于访问集合元素的方法。可以使用Iterator来遍历List、Set和Queue中的元素,但不能用于Map。Iterator接口中的常用方法有hasNext()、next()和remove()。
3、集合框架的性能比较 在选择集合实现类时,需要考虑其性能特点。下面是几种常用集合类的性能比较:
-
ArrayList vs LinkedList ArrayList在随机访问元素时性能更好,因为它可以通过下标直接访问元素。而LinkedList在插入或删除元素时性能更好,因为它只需要修改相邻节点的指针。
-
HashSet vs TreeSet HashSet在插入和查询元素时性能更好,因为它使用散列表实现。而TreeSet在有序访问元素时性能更好,因为它使用红黑树实现。
-
HashMap vs TreeMap HashMap在插入和查询元素时性能更好,因为它使用散列表实现。而TreeMap在有序访问元素时性能更好,因为它使用红黑树实现。
4、集合框架的线程安全性 在多线程环境下,集合的线程安全性是一个重要的考虑因素。
-
ArrayList vs Vector ArrayList是非线程安全的,而Vector是线程安全的。如果需要在多线程环境下使用ArrayList,可以使用Collections.synchronizedList()方法将其转换为线程安全的。
-
HashSet vs ConcurrentHashMap HashSet是非线程安全的,而ConcurrentHashMap是线程安全的。如果需要在多线程环境下使用HashSet,可以使用Collections.synchronizedSet()方法将其转换为线程安全的。
-
HashMap vs ConcurrentHashMap HashMap是非线程安全的,而ConcurrentHashMap是线程安全的。如果需要在多线程环境下使用HashMap,可以使用Collections.synchronizedMap()方法将其转换为线程安全的。
5、集合框架的常用操作方法 Java集合框架提供了一系列常用的操作方法,如增加、修改、删除、查找、排序等。
-
增加元素 可以使用add()方法向集合中添加元素。例如,list.add(element)。
-
修改元素 可以使用set()方法修改集合中的元素。例如,list.set(index, element)。
-
删除元素 可以使用remove()方法从集合中删除元素。例如,list.remove(element)。
-
查找元素 可以使用contains()方法查找集合中是否包含指定元素。例如,list.contains(element)。
-
排序元素 可以使用sort()方法对集合中的元素进行排序。例如,Collections.sort(list)。
6、集合框架的应用场景 Java集合框架在实际开发中有广泛的应用场景。
-
在数据存储和处理方面,可以使用集合框架来存储和操作大量数据。
-
在算法和数据结构方面,可以使用集合框架来实现各种算法和数据结构,如图、树、堆等。
-
在并发编程方面,可以使用集合框架来处理多线程环境下的数据共享和同步。
-
在网络编程方面,可以使用集合框架来处理网络请求和响应的数据。
7、总结 :Java集合框架是Java中用于存储数据的一种数据结构。它提供了一系列的接口和类,用于操作集合。集合框架中的四个基本接口是Collection(List、Set、Queue)和Map,它们分别用于存储有序集合、无序集合、先进先出队列和键值对映射。集合框架还提供了一些常用的类和接口,如Collections、Arrays和Iterator,用于操作集合和数组。在使用集合框架时,需要考虑其性能特点和线程安全性。集合框架在实际开发中有广泛的应用场景,在数据存储和处理、算法和数据结构、并发编程以及网络编程等方面都可以发挥重要作用。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- vscode自定义插件核心代码
- 解决el-tree中default-expand-all动态加载全部不生效问题
- spark-sql字段血缘实现
- Python算法例24 落单的数Ⅱ
- 全网最全Stable Diffusion原理说明!!简单明了 容易理解!!!
- vue3 系列:Vue3 官方文档速通
- GD32E230C8T6《调试篇》之 FMC(闪存)的读写 + USART打印
- 单机多卡训练报错NCCL版本有问题
- Ansys Lumerical | 带2D输出耦合器的出瞳扩展器的优化
- vitepress项目使用github的action自动部署到github-pages中,理论上可以通用所有