Spark---RDD介绍
1.Spark核心编程
Spark为了能够进行高并发和高吞吐的数据处理,封装了三大数据结构,用于处理不同的应用场景。
RDD:弹性分布式数据集
累加器:分布式共享只写变量
广播变量:分布式共享只读变量
2.RDD介绍
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是 Spark 中最基本的数据处理模型。代码中是一个抽象类,它代表一个弹性的、不可变、可分区、里面的元素可并行计算的集合。简单的来说,RDD在程序中就是一个包含数据和逻辑的抽象类。RDD是一个最小计算单元。
2.1.RDD基本原理
IO原理:将数据读取成为字符

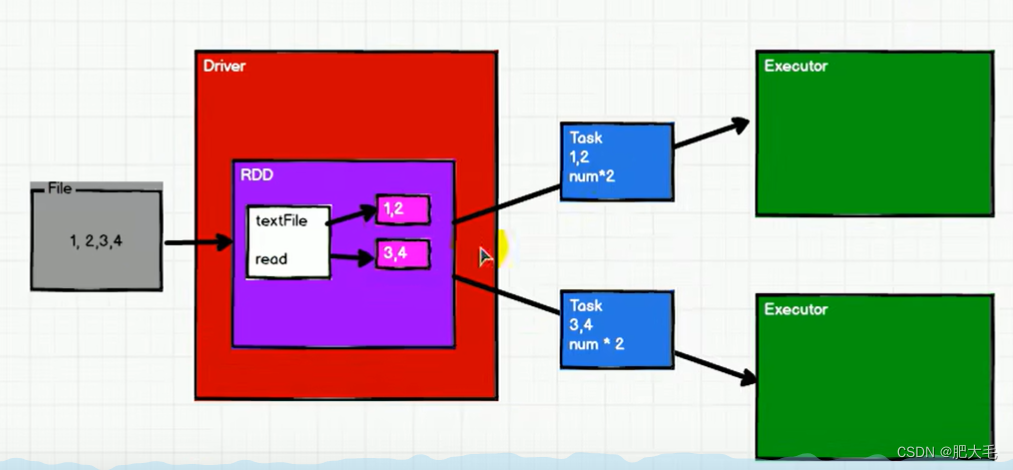
对WordCount案例进行分解,可以更好的帮助理解RDD。

RDD数据处理方式类似于IO流,也使用到了装饰者设计模式,它只有在执行了collect方法之后才会执行真正的业务逻辑操作,在之前全部都是对功能的扩展。
在IO中数据会被临时存储在缓冲区中,达到一定的阈值写出,但是在RDD中是不会临时存储数据的。
RDD的基本原理就是通过组合多个RDD来实现对功能的扩展。
注意;具体功能都是由RDD的子类来实现的
2.2 RDD特点
1.弹性

2.分布式 :数据存储在大数据集群的不同节点上
3.数据集 :RDD封装了计算逻辑,并不保存数据
4.数据抽象 :RDD是一个抽象类,具体实现由子类来实现
5. 不可变:RDD封装了计算的逻辑,是不可以随意改变的,如果想要改变,则需要产生新的RDD,在新的RDD里面封装计算逻辑
6. 可分区,并行计算:对读取进来的数据进行分区,之后将不同分区的数据发送给不同的Executor来处理。
2.3 RDD核心属性
2.3.1 分区列表
RDD 数据结构中存在分区列表,用于执行任务时并行计算,是实现分布式计算的重要属性。
2.3.2 分区计算函数
Spark 在计算时,是使用分区函数对每一个分区进行计算
2.3.3 RDD 之间的依赖关系
RDD 是计算模型的封装,当需求中需要将多个计算模型进行组合时,就需要将多个 RDD 建立依赖关系
2.3.4 分区器
当数据为 KV 类型数据时,可以通过设定分区器自定义数据的分区
2.3.5 首选位置
计算数据时,可以根据计算节点的状态选择不同的节点位置进行计算,即移动数据不如移动计算。
2.3 执行原理
Spark在数据处理的过程中需要计算资源,如内存、CPU和计算逻辑等。
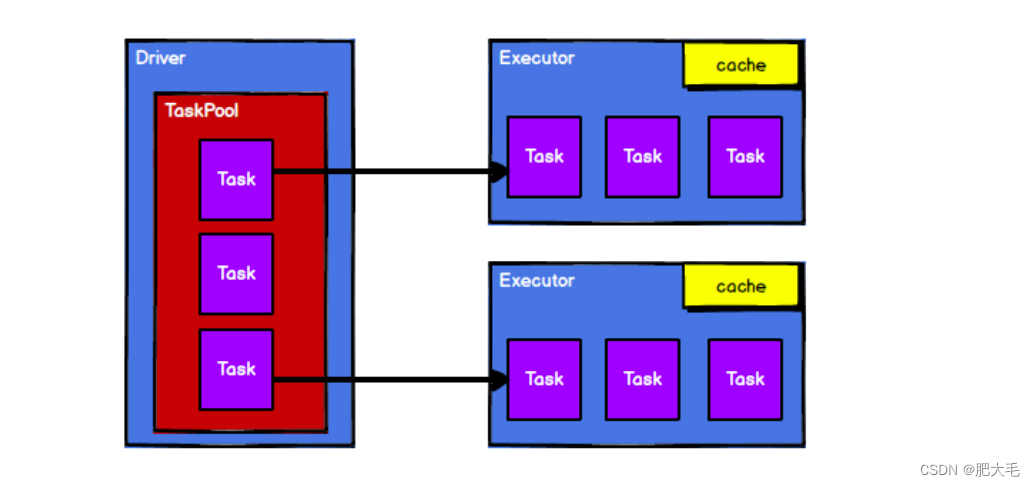
Spark 框架在执行时,先申请资源,然后将应用程序的数据处理逻辑分解成一个一个的计算任务。然后将任务发到已经分配资源的计算节点上, 按照指定的计算模型进行数据计算。最后得到计算结果。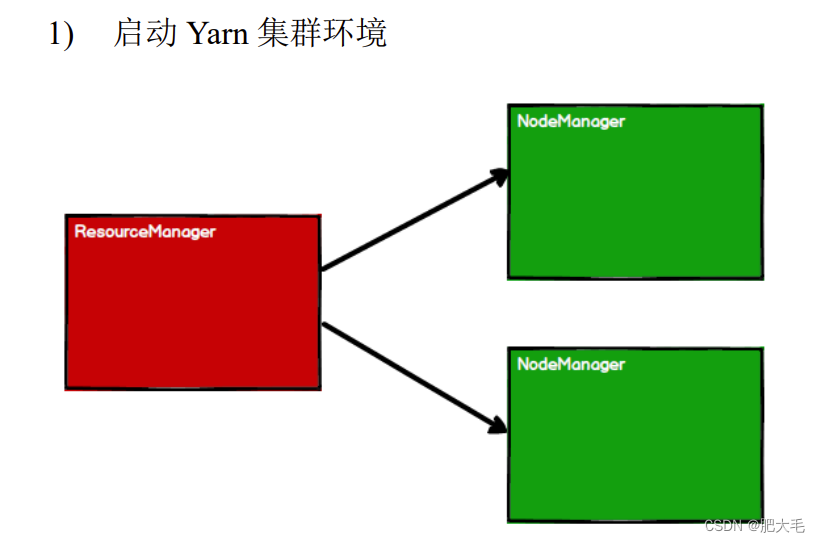
2.Spark 通过申请资源创建调度节点和计算节点
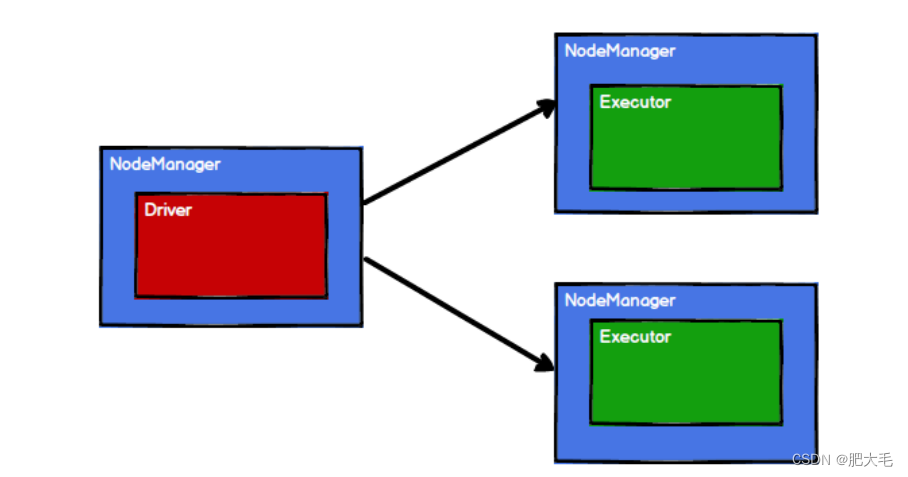
3.Spark 框架根据需求将计算逻辑根据分区划分成不同的任务
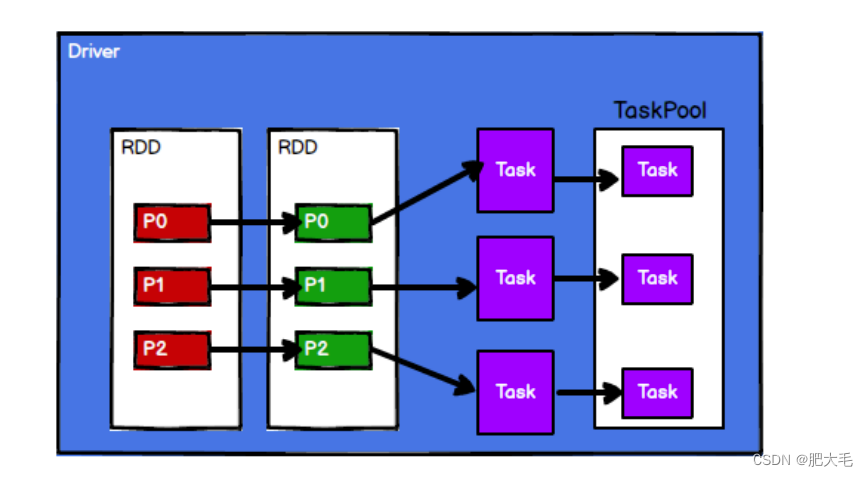
4.调度节点将任务根据计算节点状态发送到对应的计算节点进行计算
3.RDD基础编程
3.1 RDD创建
1.从集合(内存)中创建 RDD
val rdd1 = sparkContext.parallelize(
List(1,2,3,4)
)
val rdd2 = sparkContext.makeRDD(
List(1,2,3,4)
)
其中makeRDD方法的底层就是实现了paralleize方法
2.从外部存储(文件)创建 RDD
val fileRDD: RDD[String] = sparkContext.textFile("input")
3.2 RDD 并行度与分区
默认情况下,Spark 可以将一个作业切分多个任务后,发送给 Executor 节点并行计算,而能够并行计算的任务数量我们称之为并行度。(cpu核数就是并行度) 这个数量可以在构建 RDD 时指定。
sparkContext.makeRDD(
List(1,2,3,4),
4)//设置并行度为4
val fileRDD: RDD[String] =
sparkContext.textFile(
"input",
2)//设置并行度为2
读取内存数据时,数据可以按照并行度的设定进行数据的分区操作
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!