【十四】【动态规划】1312. 让字符串成为回文串的最少插入次数、1143. 最长公共子序列、1035. 不相交的线,三道题目深度解析
动态规划
动态规划就像是解决问题的一种策略,它可以帮助我们更高效地找到问题的解决方案。这个策略的核心思想就是将问题分解为一系列的小问题,并将每个小问题的解保存起来。这样,当我们需要解决原始问题的时候,我们就可以直接利用已经计算好的小问题的解,而不需要重复计算。
动态规划与数学归纳法思想上十分相似。
数学归纳法:
-
基础步骤(base case):首先证明命题在最小的基础情况下成立。通常这是一个较简单的情况,可以直接验证命题是否成立。
-
归纳步骤(inductive step):假设命题在某个情况下成立,然后证明在下一个情况下也成立。这个证明可以通过推理推断出结论或使用一些已知的规律来得到。
通过反复迭代归纳步骤,我们可以推导出命题在所有情况下成立的结论。
动态规划:
-
状态表示:
-
状态转移方程:
-
初始化:
-
填表顺序:
-
返回值:
数学归纳法的基础步骤相当于动态规划中初始化步骤。
数学归纳法的归纳步骤相当于动态规划中推导状态转移方程。
动态规划的思想和数学归纳法思想类似。
在动态规划中,首先得到状态在最小的基础情况下的值,然后通过状态转移方程,得到下一个状态的值,反复迭代,最终得到我们期望的状态下的值。
接下来我们通过三道例题,深入理解动态规划思想,以及实现动态规划的具体步骤。
1312. 让字符串成为回文串的最少插入次数 - 力扣(LeetCode)

题目解析

状态表示
状态表示一般由经验+题目要求得到。
经验一般指以某个位置为结尾或者以某个位置为开始。
本题目为研究单个字符的回文子序列或者回文子串的问题,我们通常定义研究对象为(i,j)区域中内部情况。
我们可以很容易定义这样一个状态表示,定义dp[i][j]表示让s字符串中[i,j]这段子串变成回文串的最小插入次数。
状态转移方程
对于大多数问题的求解都是通过最后一个位置的状况进行分类讨论,尝试由其他状态推导出(i,j)位置的状态。

对(i,j)状态进行分析,尝试通过其他状态推导出(i,j)位置的状态值。
-
如果s[i]==s[j], 那么要使得[i,j]这段子串成为回文串,只需要使[i+1,j-1]这段子串成为回文串即可,此时使[i,j]这段子串成为回文串的最小插入次数,就等于使[i+1,j-1]这段子串成为回文串的最小插入次数,即dp[i][j]=dp[i+1][j-1]。(这种情况可以细分一下情况,因为需要考虑i+1,j-1与i,j的关系)
-
如果[i,j]这段子串只有一个元素,即i==j, 此时dp[i][j]=0,不需要额外插入字符,本身就是回文串。
-
如果[i,j]这段子串只有两个元素,即i+1==j, 此时dp[i][j]=0,不需要额外插入字符,本身就是回文串。
-
如果[i,j]这段子串有三个或者三个以上个元素,即i+1<j, 此时dp[i][j]=dp[i+1][j-1]。
-
-
如果s[i]!=s[j],

-
如果在i位置前添加一个j位置的字符, 我们可以在i位置前面添加一个j字符,此时s[i-1]==s[j],对于原子串[i,j]要成为回文串,只需要[i,j-1]子串成为回文串即可,此时使[i,j]这段子串成为回文串的最小插入次数,就等于使[i,j-1]这段子串成为回文串的最小插入次数+1,这个1就是我们插入蓝色字符的次数,即dp[i][j]=dp[i][j-1]+1。

-
如果在j位置后添加一个i位置的字符, 我们可以在j位置后面添加一个i字符,此时s[i]==s[j+1],对于原子串[i,j]要成为回文串,只需要[i+1,j]子串成为回文串即可,此时使[i,j]这段子串成为回文串的最小插入次数,就等于使[i+1,j]这段子串成为回文串的最小插入次数+1,这个1就是我们插入蓝色字符的次数,即dp[i][j]=dp[i+1][j]+1。
-
对上述情况进行合并和简化,得到状态转移方程,
如果s[i]==s[j],dp[i][j]=i+1<j?dp[i+1][j-1]:0;
如果s[i]!=s[j],dp[i][j]=min(dp[i][j-1]+1,dp[i+1][j]+1);
初始化
在初始化之前我们可以先判断填表顺序,
-
如果固定i改变j, 根据状态转移方程,我们知道在推导(i,j)位置的状态时可能需要用到(i+1,j-1),(i,j-1),(i+1,j)位置的状态。所以i的变化需要从大到小,由于还可能用到(i,j-1)的状态,所以j的变化需要从小到大。
-
如果固定j改变i, 根据状态转移方程,我们知道在推导(i,j)位置的状态时可能需要用到(i+1,j-1),(i,j-1),(i+1,j)位置的状态。所以j的变化需要从小到大,由于还可能用到(i+1,j)的状态,所以i的变化需要从大到小。
如果我们要填写每一个元素,可以得到这样的状态转移方程,
for (int i = n - 1; i >= 0; i--)
for (int j = i; j < n; j++)
if (s[i] == s[j])
dp[i][j] = i + 1 < j ? dp[i + 1][j - 1] : 0;
else
dp[i][j] = min(dp[i + 1][j], dp[i][j - 1]) + 1;此时满足前驱状态可以推导后续状态,我们现在只需要满足第一个状态可以正常得出即可,所以我们带入第一个状态,即i=n-1,j=i。此时可以得出dp[i][j]=0,所以我们不需要初始化,所有位置状态就可以正常得出。
填表顺序
-
如果固定i改变j, 根据状态转移方程,我们知道在推导(i,j)位置的状态时可能需要用到(i+1,j-1),(i,j-1),(i+1,j)位置的状态。所以i的变化需要从大到小,由于还可能用到(i,j-1)的状态,所以j的变化需要从小到大。
-
如果固定j改变i, 根据状态转移方程,我们知道在推导(i,j)位置的状态时可能需要用到(i+1,j-1),(i,j-1),(i+1,j)位置的状态。所以j的变化需要从小到大,由于还可能用到(i+1,j)的状态,所以i的变化需要从大到小。
返回值
dp[i][j]表示让s字符串中[i,j]这段子串变成回文串的最小插入次数。
结合题目意思,我们需要得到让s字符串中[0,n-1]这段子串变成回文串的最小插入次数。即返回dp[0][n-1]。
代码实现
class Solution {
public:
int minInsertions(string s) {
int n = s.size();
vector<vector<int>> dp(n, vector<int>(n)); // 创建 dp 表
for (int i = n - 1; i >= 0; i--)
for (int j = i; j < n; j++)
if (s[i] == s[j])
dp[i][j] = i + 1 < j ? dp[i + 1][j - 1] : 0;
else
dp[i][j] = min(dp[i + 1][j], dp[i][j - 1]) + 1;
return dp[0][n - 1];
}
};1143. 最长公共子序列 - 力扣(LeetCode)

题目解析

状态表示
对于子序列的问题研究,我们通常研究[0,i]这段区域中的子序列的情况,对于两段字符串,研究子序列问题,我们可以分别研究一个字符串中[0,i]的区域,和另一个字符串中[0,j]的区域中的子序列的情况。
结合题目意思,我们可以定义这样的状态表示,定义dp[i][j]表示text1中[0,i]区域,text2中[0,j]区域中所有子序列中,最长的公共子序列长度。
状态转移方程
对于状态转移方程的推导,通常都是通过最后一个位置的状况进行分类讨论。

对(i,j)状态进行分析,尝试通过其他状态推导出(i,j)位置的状态值。
-
如果[0,i][0,j]中最长公共子序列同时包括text1[i],text2[j],即text1[i]==text2[j], 此时最长公共子序列等于,[0,i-1],[0,j-1]中最长公共子序列后面添加i、j位置元素,此时[0,i][0,j]中最长公共子序列长度等于[0,i-1][0,j-1]中最长公共子序列长度+1,即 dp[i][j]=dp[i-1][j-1]+1。
-
如果[0,i][0,j]中最长公共子序列不同时包括text1[i],text2[j],即text1[i]!=text2[j],
-
如果[0,i][0,j]中最长公共子序列包括text1[i],不包括text2[j], 此时[0,i][0,j]中最长公共子序列长度等于[0,i][0,j-1]中最长公共子序列长度,即 dp[i][j]=dp[i][j-1]。
-
如果[0,i][0,j]中最长公共子序列不包括text1[i],包括text2[j], 此时[0,i][0,j]中最长公共子序列长度等于[0,i-1][0,j]中最长公共子序列长度,即 dp[i][j]=dp[i-1][j]。
-
对上述情况进行合并和简化,得到状态转移方程为,
if(text1[i]==text2[j]) dp[i][j]=dp[i-1][j-1]+1;
if(text1[i]!=text2[j]) dp[i][j]=max(dp[i][j-1],dp[i-1][j]);初始化

根据状态转移方程我们知道,在推导(i,j)位置的状态时,可能需要用到(i-1,j-1)(i,j-1)(i-1,j)位置的状态。

所以在推导绿色位置的状态时,会越界,所以我们应该初始化这些位置的元素。
而对这些位置进行初始化处理起来有些许麻烦,我们希望有一个更方便的办法解决初始化的问题。
因此我们可以多添加一行和一列,对这些位置进行初始化而代替原先需要初始化的位置。

添加虚拟节点后,有几点注意事项,
-
对虚拟节点初始化,需要保证使得推导绿色位置的状态的正确性。
-
要注意dp表示中下标的映射关系。
对虚拟节点进行初始化:
对虚拟节点进行初始化,一般是通过实际意义来初始化,我们先观察状态表示和状态转移方程,
dp[i][j]表示text1中[0,i]区域,text2中[0,j]区域中所有子序列中,最长的公共子序列长度。
if(text1[i]==text2[j]) dp[i][j]=dp[i-1][j-1]+1; if(text1[i]!=text2[j]) dp[i][j]=max(dp[i][j-1],dp[i-1][j]);
-
对绿色部分第一行进行分析, 绿色部分第一行表示,text1只有一个元素,text2至少有一个元素,然后找最长公共子序列的长度。
-
如果text1[i]==text2[j], 此时dp[i][j]=1,而if(text1[i]==text2[j]) dp[i][j]=dp[i-1][j-1]+1;,故dp[i-1][j-1]应该为0。
-
如果text1[i]!=text2[j], 此时dp[i][j]=dp[i][j-1],if(text1[i]!=text2[j]) dp[i][j]=max(dp[i][j-1],dp[i-1][j]);所以dp[i-1][j]应该不能取到,而dp[i][j-1]的值要么是1要么是0,为了统一上一种情况,故dp[i-1][j]应该为0。
-
综上所述,蓝色第一行应该初始化为0。
-
对绿色部分第一列进行分析, 绿色部分第一列表示,text1至少有一个元素,text2只有一个元素,然后找到最长公共子序列的长度。

-
如果text1[i]==text2[j], 此时dp[i][j]=1,而if(text1[i]==text2[j]) dp[i][j]=dp[i-1][j-1]+1;故dp[i-1][j-1]应该为0。
-
如果text1[i]!=text2[j], 此时dp[i][j]=dp[i-1][j],而if(text1[i]!=text2[j]) dp[i][j]=max(dp[i][j-1],dp[i-1][j]);所以dp[i][j-1]应该不能取到,而dp[i-1][j]的值要么是1要么是0,为了统一上一种情况,故dp[i][j-1]应该为0。
-
综上所述,蓝色第一列应该初始化为0。
所以对蓝色部分全部初始化为0即可。
下标映射关系:
dp[i][j]表示text1中[0,i]区域,text2中[0,j]区域中所有子序列中,最长的公共子序列长度。
因为多添加了一行和一列,所以实际上dp[i][j]表示text1中[0,i-1]区域,text2中[0,j-1]区域中所有子序列中,最长的公共子序列长度。
有两种解决办法。
-
从dp[i][j]找text中对应的位置需要下标减1。即用i-1,j-1找到text中的对应位置。
-
当然也可以在text前面添加一个字符作为平衡,这样dp[i][j]就可以直接与text1[i]、text2[j]元素进行对应。
实际上下标映射关系改变后,相应的状态表示,状态转移方程都需要改变,但我们只需要注意一下下标的映射关系含义即可。
填表顺序
-
如果固定i填写j, 根据状态转移方程我们知道,在推导(i,j)位置的状态时,可能需要用到(i-1,j-1)(i,j-1)(i-1,j)位置的状态,所以i的变化需要从小到大,由于还会用到(i,j-1)位置的状态,所以j的变化需要从小到大。
-
如果固定j填写i, 根据状态转移方程我们知道,在推导(i,j)位置的状态时,可能需要用到(i-1,j-1)(i,j-1)(i-1,j)位置的状态,所以j的变化需要从小到大,由于还会用到(i,j-1)位置的状态,所以i的变化需要从小到大。
返回值
dp[i][j]表示text1中[0,i]区域,text2中[0,j]区域中所有子序列中,最长的公共子序列长度。
结合题目意思,我们需要得到text1中[0,m-1]区域、text2中[0,n-1]区域中所有子序列中,最长的公共子序列长度,(n、m分别是text1,text2的长度)
又因为下标映射关系,所以我们需要返回dp[m][n]。
代码实现
class Solution {
public:
int longestCommonSubsequence(string s1, string s2) {
int m = s1.size(), n = s2.size();
s1 = " " + s1, s2 = " " + s2;
vector<vector<int>> dp(m + 1, vector<int>(n + 1));
for (int i = 1; i <= m; i++)
for (int j = 1; j <= n; j++)
if (s1[i] == s2[j])
dp[i][j] = dp[i - 1][j - 1] + 1;
else
dp[i][j] = max(dp[i - 1][j], dp[i][j - 1]);
return dp[m][n];
}
};1035. 不相交的线 - 力扣(LeetCode)
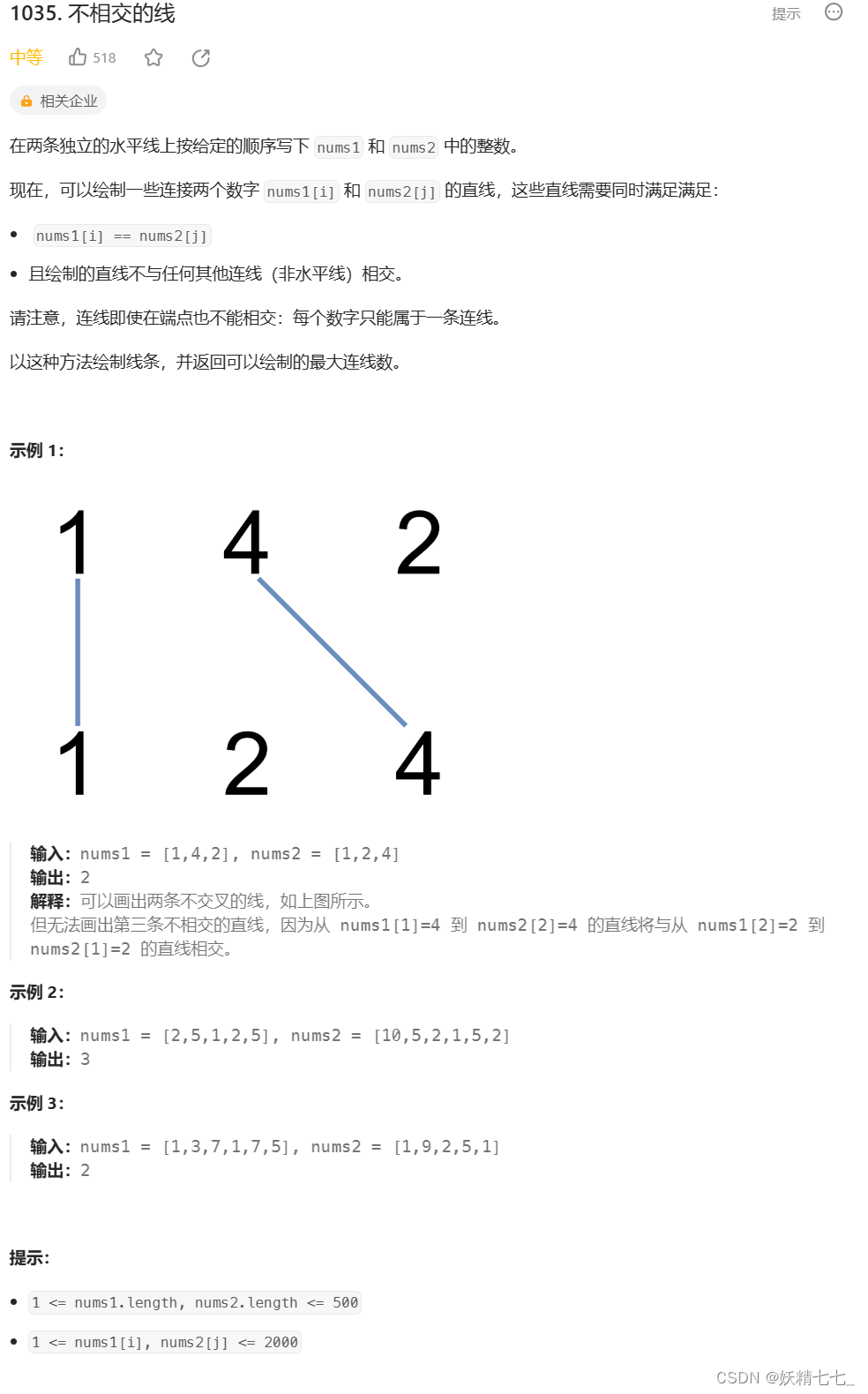
题目解析
状态表示
对于子序列的问题研究,我们通常研究[0,i]这段区域中的子序列的情况,对于两段字符串,研究子序列问题,我们可以分别研究一个字符串中[0,i]的区域,和另一个字符串中[0,j]的区域中的子序列的情况。
结合题目意思,我们可以定义这样的状态表示,定义dp[i][j]表示text1中[0,i]区域,text2中[0,j]区域中所有子序列中,最长的公共子序列长度。
状态转移方程
对于状态转移方程的推导,通常都是通过最后一个位置的状况进行分类讨论。

对(i,j)状态进行分析,尝试通过其他状态推导出(i,j)位置的状态值。
-
如果[0,i][0,j]中最长公共子序列同时包括text1[i],text2[j],即text1[i]==text2[j], 此时最长公共子序列等于,[0,i-1],[0,j-1]中最长公共子序列后面添加i、j位置元素,此时[0,i][0,j]中最长公共子序列长度等于[0,i-1][0,j-1]中最长公共子序列长度+1,即 dp[i][j]=dp[i-1][j-1]+1。
-
如果[0,i][0,j]中最长公共子序列不同时包括text1[i],text2[j],即text1[i]!=text2[j],
-
如果[0,i][0,j]中最长公共子序列包括text1[i],不包括text2[j], 此时[0,i][0,j]中最长公共子序列长度等于[0,i][0,j-1]中最长公共子序列长度,即 dp[i][j]=dp[i][j-1]。
-
如果[0,i][0,j]中最长公共子序列不包括text1[i],包括text2[j], 此时[0,i][0,j]中最长公共子序列长度等于[0,i-1][0,j]中最长公共子序列长度,即 dp[i][j]=dp[i-1][j]。
-
对上述情况进行合并和简化,得到状态转移方程为,
if(text1[i]==text2[j]) dp[i][j]=dp[i-1][j-1]+1;
if(text1[i]!=text2[j]) dp[i][j]=max(dp[i][j-1],dp[i-1][j]);初始化

根据状态转移方程我们知道,在推导(i,j)位置的状态时,可能需要用到(i-1,j-1)(i,j-1)(i-1,j)位置的状态。

所以在推导绿色位置的状态时,会越界,所以我们应该初始化这些位置的元素。
而对这些位置进行初始化处理起来有些许麻烦,我们希望有一个更方便的办法解决初始化的问题。
因此我们可以多添加一行和一列,对这些位置进行初始化而代替原先需要初始化的位置。

添加虚拟节点后,有几点注意事项,
-
对虚拟节点初始化,需要保证使得推导绿色位置的状态的正确性。
-
要注意dp表示中下标的映射关系。
对虚拟节点进行初始化:
对虚拟节点进行初始化,一般是通过实际意义来初始化,我们先观察状态表示和状态转移方程,
dp[i][j]表示text1中[0,i]区域,text2中[0,j]区域中所有子序列中,最长的公共子序列长度。
if(text1[i]==text2[j]) dp[i][j]=dp[i-1][j-1]+1; if(text1[i]!=text2[j]) dp[i][j]=max(dp[i][j-1],dp[i-1][j]);
-
对绿色部分第一行进行分析, 绿色部分第一行表示,text1只有一个元素,text2至少有一个元素,然后找最长公共子序列的长度。

-
如果text1[i]==text2[j], 此时dp[i][j]=1,而if(text1[i]==text2[j]) dp[i][j]=dp[i-1][j-1]+1;,故dp[i-1][j-1]应该为0。
-
如果text1[i]!=text2[j], 此时dp[i][j]=dp[i][j-1],if(text1[i]!=text2[j]) dp[i][j]=max(dp[i][j-1],dp[i-1][j]);所以dp[i-1][j]应该不能取到,而dp[i][j-1]的值要么是1要么是0,为了统一上一种情况,故dp[i-1][j]应该为0。
-
综上所述,蓝色第一行应该初始化为0。
-
对绿色部分第一列进行分析, 绿色部分第一列表示,text1至少有一个元素,text2只有一个元素,然后找到最长公共子序列的长度。

-
如果text1[i]==text2[j], 此时dp[i][j]=1,而if(text1[i]==text2[j]) dp[i][j]=dp[i-1][j-1]+1;故dp[i-1][j-1]应该为0。
-
如果text1[i]!=text2[j], 此时dp[i][j]=dp[i-1][j],而if(text1[i]!=text2[j]) dp[i][j]=max(dp[i][j-1],dp[i-1][j]);所以dp[i][j-1]应该不能取到,而dp[i-1][j]的值要么是1要么是0,为了统一上一种情况,故dp[i][j-1]应该为0。
-
综上所述,蓝色第一列应该初始化为0。
所以对蓝色部分全部初始化为0即可。
下标映射关系:
dp[i][j]表示text1中[0,i]区域,text2中[0,j]区域中所有子序列中,最长的公共子序列长度。
因为多添加了一行和一列,所以实际上dp[i][j]表示text1中[0,i-1]区域,text2中[0,j-1]区域中所有子序列中,最长的公共子序列长度。
有两种解决办法。
-
从dp[i][j]找text中对应的位置需要下标减1。即用i-1,j-1找到text中的对应位置。
-
当然也可以在text前面添加一个字符作为平衡,这样dp[i][j]就可以直接与text1[i]、text2[j]元素进行对应。
实际上下标映射关系改变后,相应的状态表示,状态转移方程都需要改变,但我们只需要注意一下下标的映射关系含义即可。
填表顺序
-
如果固定i填写j, 根据状态转移方程我们知道,在推导(i,j)位置的状态时,可能需要用到(i-1,j-1)(i,j-1)(i-1,j)位置的状态,所以i的变化需要从小到大,由于还会用到(i,j-1)位置的状态,所以j的变化需要从小到大。
-
如果固定j填写i, 根据状态转移方程我们知道,在推导(i,j)位置的状态时,可能需要用到(i-1,j-1)(i,j-1)(i-1,j)位置的状态,所以j的变化需要从小到大,由于还会用到(i,j-1)位置的状态,所以i的变化需要从小到大。
返回值
dp[i][j]表示text1中[0,i]区域,text2中[0,j]区域中所有子序列中,最长的公共子序列长度。
结合题目意思,我们需要得到text1中[0,m-1]区域、text2中[0,n-1]区域中所有子序列中,最长的公共子序列长度,(n、m分别是text1,text2的长度)
又因为下标映射关系,所以我们需要返回dp[m][n]。
代码实现
class Solution {
public:
int maxUncrossedLines(vector<int>& nums1, vector<int>& nums2) {
// 1. 创建 dp 表
// 2. 初始化
// 3. 填表
// 4. 返回值
int m = nums1.size(), n = nums2.size();
vector<vector<int>> dp(m + 1, vector<int>(n + 1));
for (int i = 1; i <= m; i++)
for (int j = 1; j <= n; j++)
if (nums1[i - 1] == nums2[j - 1])
dp[i][j] = dp[i - 1][j - 1] + 1;
else
dp[i][j] = max(dp[i - 1][j], dp[i][j - 1]);
return dp[m][n];
}
};结尾
今天我们学习了动态规划的思想,动态规划思想和数学归纳法思想有一些类似,动态规划在模拟数学归纳法的过程,已知一个最简单的基础解,通过得到前项与后项的推导关系,由这个最简单的基础解,我们可以一步一步推导出我们希望得到的那个解,把我们得到的解依次存放在dp数组中,dp数组中对应的状态,就像是数列里面的每一项。最后感谢您阅读我的文章,对于动态规划系列,我会一直更新,如果您觉得内容有帮助,可以点赞加关注,以快速阅读最新文章。
最后,感谢您阅读我的文章,希望这些内容能够对您有所启发和帮助。如果您有任何问题或想要分享您的观点,请随时在评论区留言。
同时,不要忘记订阅我的博客以获取更多有趣的内容。在未来的文章中,我将继续探讨这个话题的不同方面,为您呈现更多深度和见解。
谢谢您的支持,期待与您在下一篇文章中再次相遇!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 解决liquibase.exception.LockException: Could not acquire change log lock.
- Lazada发货越南用什么物流最好?物流费用是什么?-站斧浏览器
- 【Leetcode】 447. 回旋镖的数量
- 来自中国黑客发现的0Day漏洞;2023年恶意文件数量每日激增3%| 安全周报2352
- Prometheus实战篇:Prometheus监控docker
- 算法训练第四十八天|198. 打家劫舍、213. 打家劫舍 II、337. 打家劫舍 III
- Linux面试题
- 力扣labuladong一刷day53天LFU 算法
- Android画布Canvas drawPath绘制跟随手指移动的圆,Kotlin
- 使用 Kubernetes 部署机器学习模型的优势