机器学习中的监督学习基本算法-逻辑回归简单介绍
逻辑回归
逻辑回归(Logistic Regression)是一种用于解决二分类问题的统计学习方法,尽管名字中带有"回归"一词,但实际上它是一种分类算法。逻辑回归的主要目标是通过学习从输入特征到一个离散的输出(通常是0或1)的映射。
模型表达式:
逻辑回归模型使用逻辑函数(也称为sigmoid函数)将线性组合的输入特征映射到[0, 1]之间的概率值。模型的数学表达式如下:

其中:
P(Y=1)P(Y=1) 是观测到类别1的概率;
e 是自然对数的底;
β0,β1,…,βn是模型的参数;
X1,X2,…,Xn是输入特征。
逻辑回归的训练目标是通过最大化似然函数或最小化交叉熵损失函数来学习模型的参数。常用的优化算法包括梯度下降法。通过不断调整参数,使得模型对训练数据中的样本分类的概率更接近实际标签。
逻辑回归的优点:
简单而有效: 逻辑回归是一种简单的模型,易于理解和实现。
概率输出: 输出为概率值,便于理解样本属于某个类别的可能性。
抗噪声能力: 对于一些噪声数据的影响相对较小。
适用性广泛: 逻辑回归适用于各种领域,包括医学、金融、社会科学等。
逻辑回归的应用场景:
二分类问题: 逻辑回归最常见的应用是解决二分类问题,如判断邮件是垃圾邮件还是正常邮件。
概率预测: 可以用于预测一个事件发生的概率,例如客户购买产品的概率。
风险建模: 在金融领域中,逻辑回归可以用于评估客户违约的概率。
疾病诊断: 在医学领域,逻辑回归可以用于疾病的早期诊断。
逻辑回归的反向传播公式推导
逻辑回归模型在训练过程中通常使用梯度下降等优化算法来最小化损失函数,其中反向传播(Backpropagation)是一个关键的步骤。下面是逻辑回归的反向传播公式推导过程:
- 定义损失函数:
逻辑回归的损失函数通常采用交叉熵损失函数,用于度量模型输出的概率分布与实际标签之间的差异。对于二分类问题,损失函数可以定义为:
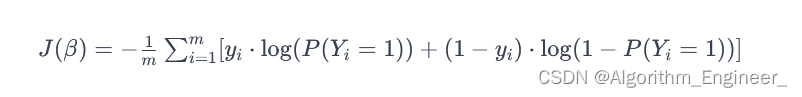
其中 m 是样本数量,yi是第 i 个样本的实际标签。
- 计算梯度:
梯度表示损失函数相对于模型参数的变化率。我们需要计算损失函数对每个参数的偏导数。以 j 号参数 βj 为例:
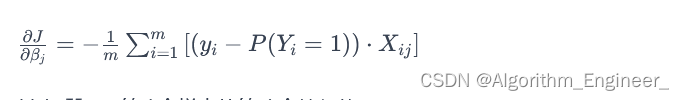
其中 Xij 是第 i 个样本的第 j 个特征值。
- 更新参数:
通过梯度下降等优化算法,更新模型参数:
 其中 α 是学习率,用于控制参数更新的步长。
其中 α 是学习率,用于控制参数更新的步长。
- 反向传播:
反向传播是在整个神经网络中进行的,涉及从输出层到输入层的梯度计算和参数更新。在逻辑回归中,由于只有一个输出层,反向传播主要集中在计算输出层的梯度,然后通过链式法则逐层向后传播。
总结:
逻辑回归的反向传播公式推导主要涉及计算损失函数对模型参数的偏导数,然后通过梯度下降等优化算法更新参数。这个过程可以扩展到更复杂的神经网络中,但基本的思想是一致的。在实际应用中,通常会使用深度学习框架(如TensorFlow、PyTorch)来自动进行反向传播。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- re:从0开始的HTML学习之路 13. 表单(完结撒花)
- 408数据结构常考算法基础训练
- Text to image论文精读 TISE (Text-to-Image Synthesis Evaluation):用于文本到图像合成的评估度量工具包
- PyTorch中的 Dataset、DataLoader 和 enumerate()
- vulnhub靶机odin
- [ABAP] 修改SAP网页端登录界面
- int char[] String 转换
- 关于文件上传功能的安全方面的考量
- Python生成圣诞节词云-代码案例剖析【第17篇—python圣诞节系列】
- three.js实现扩散光圈效果