Python实践——爬取百度图片
Python能做的事情很多,爬虫是一个常见需求,可以自动从互联网爬取想要的图片。这里我们从0开始实现一个百度图片的爬虫。
背景知识:
什么是网络爬虫?
网络爬虫又叫网络蜘蛛、网络机器人等,是一个能在互联网上自动提取网页信息并进行解析的程序。
简单就是两点:自动化地访问网站、获取所需信息。
网络爬虫实现方式主要有两种:(1)发送HTTP请求获取网页内容,(2)模拟浏览器行为来获取数据。
如何定位和获取页面元素?
Html网页中的各个元素都有自己的标签和属性。Xpath是XML路径语言,用于确定XML文档中的元素位置,通过元素路径对元素查找。
Html网页是XML的一种实现方式,使用Xpath实现对页面元素定位。
XPath可以通过标签名和属性名来定位和提取HTML或XML文档中的数据。可以用于获取Html元素的文本或者属性等,
比如标签div的文本,Xpath为://div/text()
比如标签img的图像链接,Xpath为://img/@srcXpath Helper是Chrome浏览器的扩展插件,是一款免费的XPath工具,可以快速获取Html元素的Xpath表达式。
如何下载想要的页面元素内容?
使用Python的requests库模拟人为浏览页面的操作,发送Http请求下载相应数据并保存。
下面根据背景知识逐步讲解操作步骤:
一、安装Xpath Helper插件
1、打开浏览器的扩展程序(这里以chrone为例)
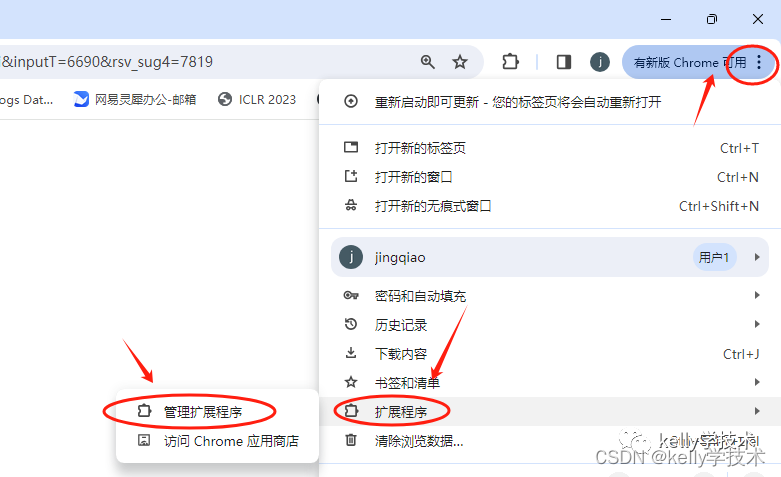
2、打开Chrone浏览器的应用商店

3、搜索Xpath Helper插件
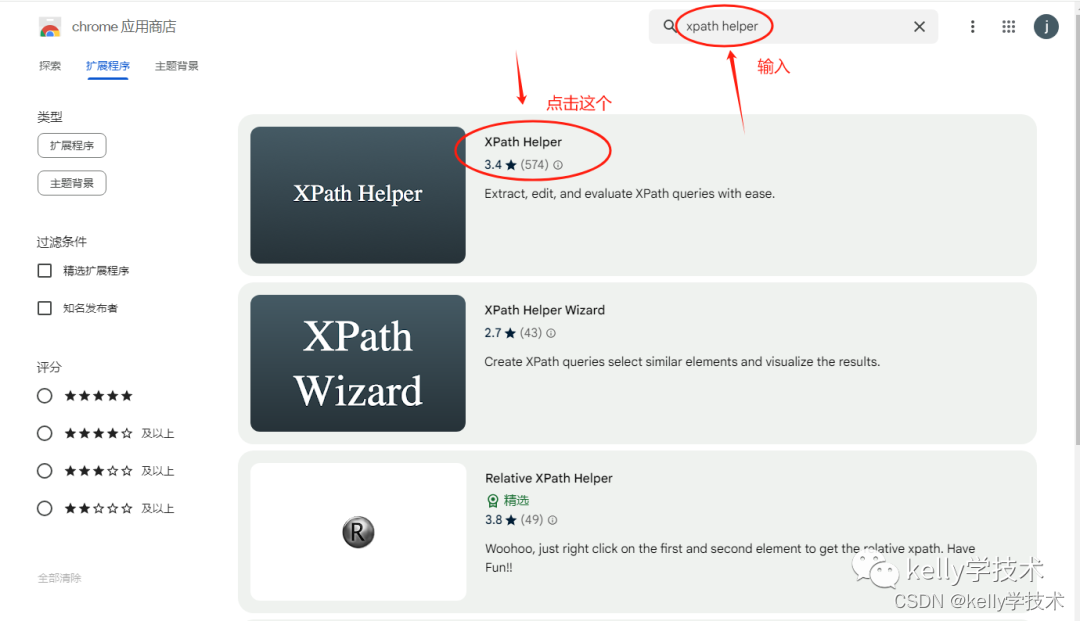
4、安装Xpath Helper插件


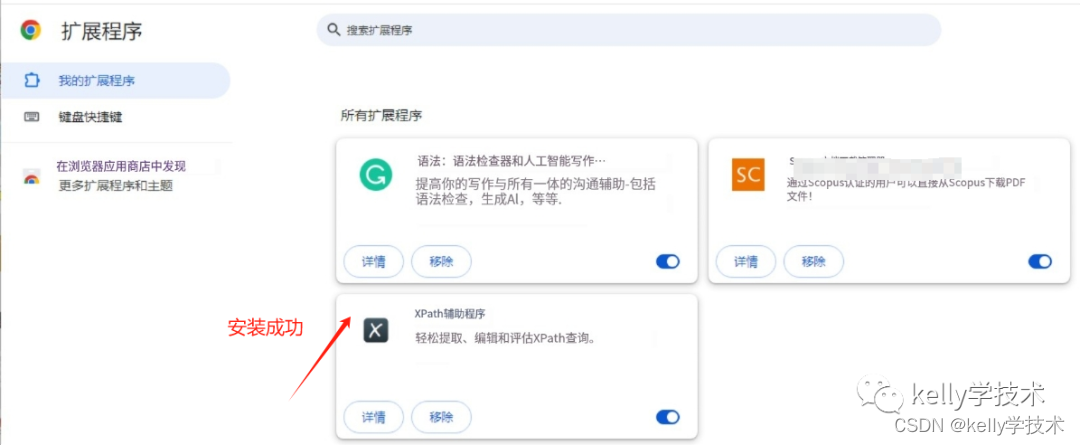
5、重启浏览器,激活Xpath Helper

6、将Xpath Helper插件固定到浏览器的工具栏:


二、在百度图片中搜索想要的图片,获取到待爬取的图片url,这里以“黄桥烧饼”为例。
1、打开百度图片,搜索“黄桥烧饼”

2、使用如下步骤打开“开发者工具”,或者直接按F12

3、按照图示查询网页的Html结构、图片的元素信息
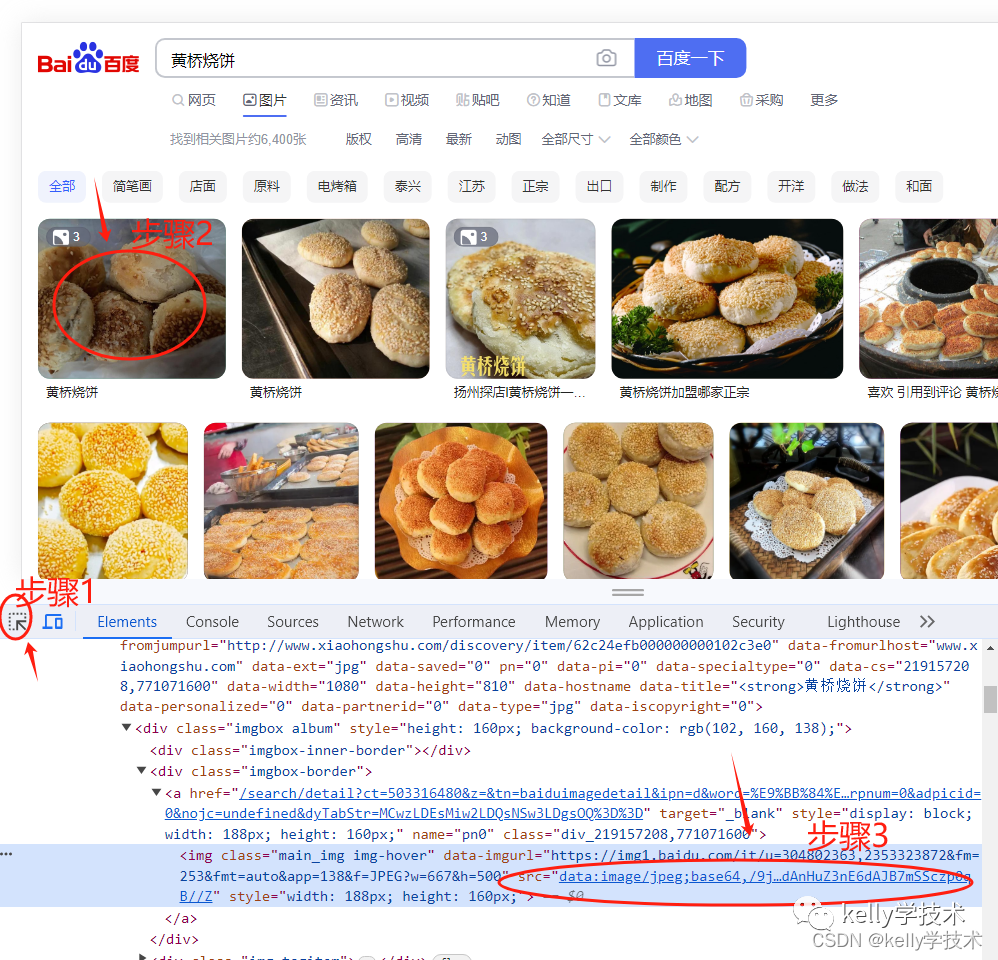
4、进一步查询图片的信息
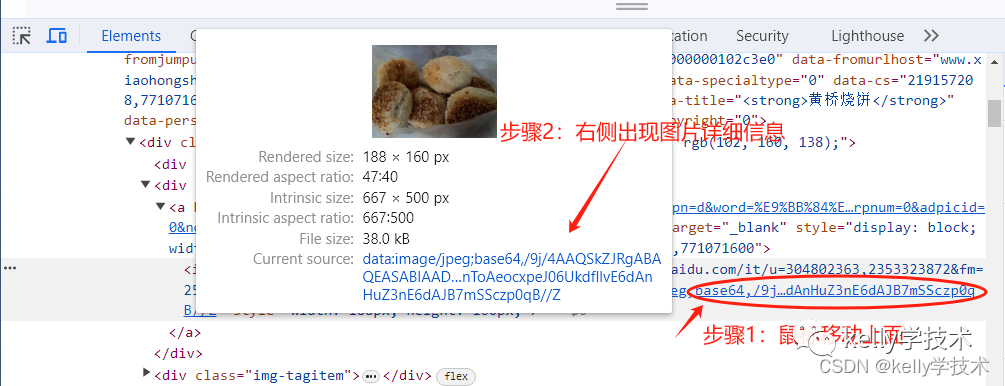
5、获取图片的Xpath路径,进而批量查询出图片的url地址

6、使用开发者工具直接查询图片标签的Xpath

7、将图片的Xpath黏贴到Xpath Helper插件的查询窗口

8、直接复制到Xpath绑定了特定图片,这里需要修改下得到更一般性的Xpath。
修改前://*[@id="imgid"]/div/ul/li[1]/div/div[2]/a/img
修改后://*[@id="imgid"]//a/img/@src9、将修改后的xpath复制到Xpath Helper的查询框中:

10、将Xpath Helper查询出的结果复制出来,单独放到一个txt文件中,作为爬虫的图片来源。
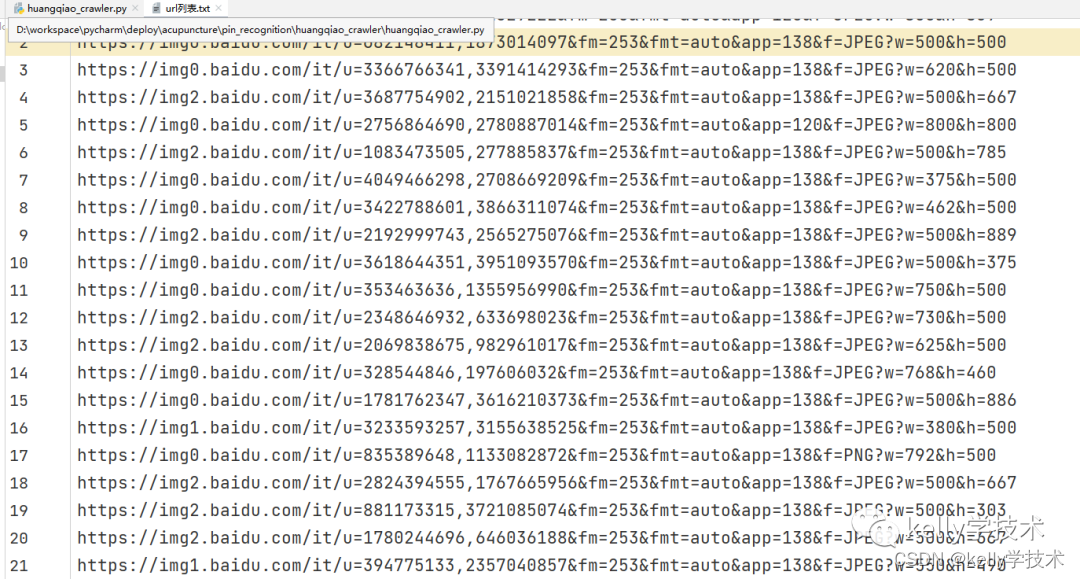
三、编写python爬虫
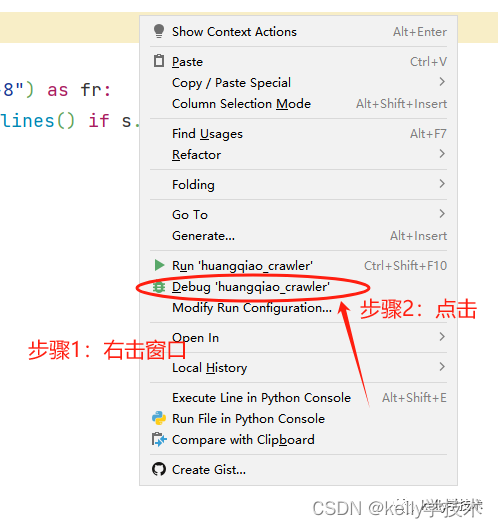
编写python爬虫



点击运行按钮,运行爬虫程序,根据前面的图片url集合,开始逐个爬取图片
最后爬取到的图片集合:

后记:
一般而言,爬虫会提升目标服务器负载,会影响到服务的正常运转。很多的目标网站/服务器会有多种反爬虫措施。比如:
图片伪装、自定义字体、验证码、
请求头验证、对特定IP地址的请求次数限制等
页面动态渲染(页面由客户端渲染,内容由JavaScript渲染而成,无法通过查看查看网页源代码得到有效数据)、
本文只是介绍爬虫的一个简单案例,想要得到一个功能强大的应用还需要掌握各种爬虫技术,后面会不断介绍。
本文原创,原始版本发表链接:
kelly会在公众号「kelly学技术」不定期更新文章,感兴趣的朋友可以关注一下,期待与您交流。
--over--
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 接口与继承
- 每日一题:Leetcode974.和可被k整除的子数组
- codeforces 1909B
- 软件测试用例经典方法 | 单元测试法案例
- 猜数字游戏
- 使用Go发送HTTP POST请求
- 【漏洞复现】Hikvision综合安防管理平台config信息泄露漏洞
- 算法随想录第四十二天打卡|01背包问题,你该了解这些!,01背包问题,你该了解这些! 滚动数组, 416. 分割等和子集
- 如何在苹果手机上进行文件管理
- ubuntu编译FFmpeg并使用编译好的so使用c++进行编码和解码