Hudi 表类型和查询类型
发布时间:2023年12月20日
数据湖hudi的表类型定义了数据在DFS上如何组织布局,同时实现一些timeline等操作(表类型定定义数据是如何写入的);查询类型则是定义如何读取DFS上的数据。
| Table type | query type |
| Copy-On-Write | 快照查询; 增量查询; 增量CDC; 时间旅行; |
| Merge-On-Read | 快照查询; 增量查询; 读取优化查询; 时间旅行; |
表类型
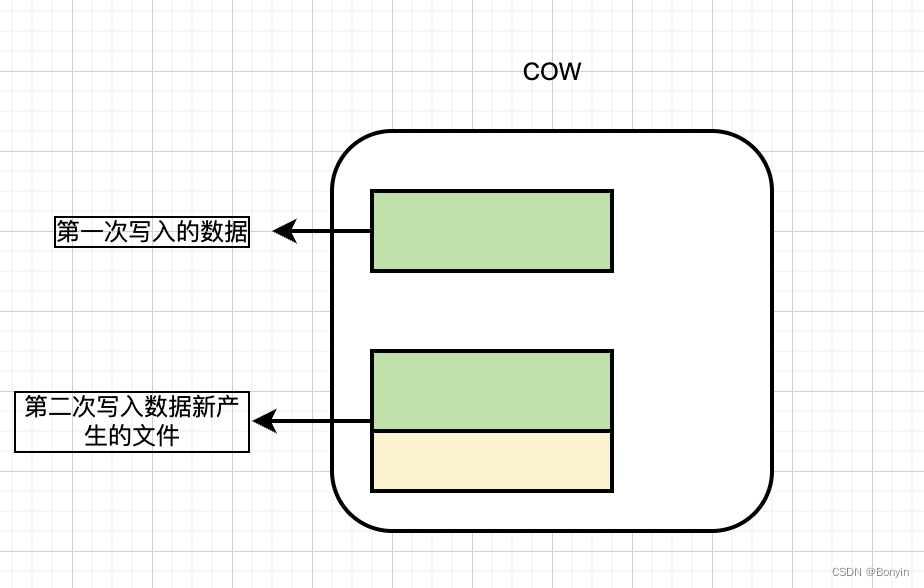
1.copy-on-write
使用列存储格式parquet组织数据,产生新版本的数据文件,是通过在写入期间执行同步合并重新产生新文件。?
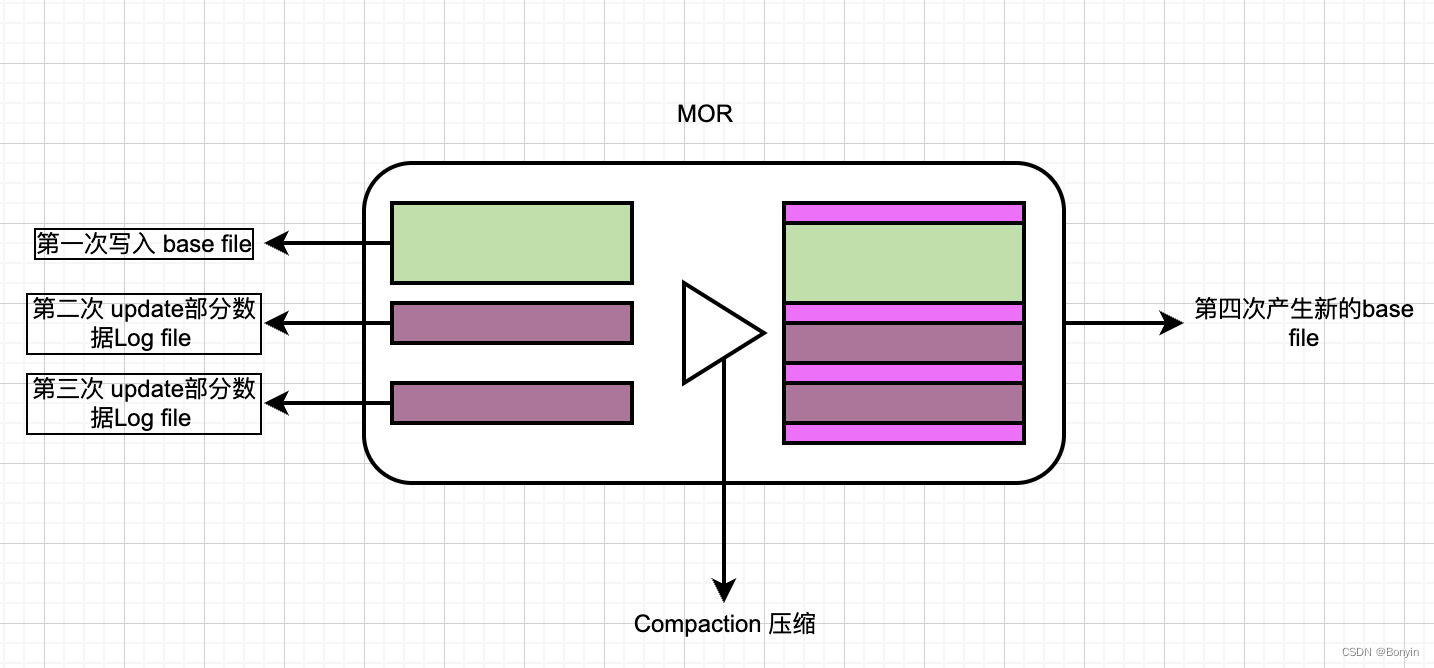
2.merge-On-Read
使用列加行的格式来组织数据,更新的数据写入到增量文件中,在将增量的数据压缩以同步或者异步的方式生成新的版本文件。
查询类型
Hudi支持以下查询:
快照查询:查询查看给定提交或压缩操作时表的最新快照。在读取表上合并的情况下,它通过合并公开近乎实时的数据(几分钟) 实时最新文件切片的基本文件和增量文件。对于写表复制,它提供了现有镶木地板表的直接替代品,同时提供更新插入/删除和其他写入端功能。
增量查询:查询仅查看自给定提交/压缩以来写入表的新数据。 这有效地提供了变更流以启用增量数据管道。默认情况下,这会生成最新的 自时间线中给定点以来的更改快照。
增量查询(CDC):这些是增量查询的子类型,其中查询会查看自此以来所有更改的数据 给定的提交/压缩,而不是更改数据的最新状态。这支持完整的 cdc 风格查询用例 允许查看更改前后的图像以及导致更改的操作。
读取优化查询:查询查看给定提交/压缩操作时表的最新快照。仅公开最新文件切片中的基础/列文件并保证 与非 hudi 列式表相比,列式查询性能相同。
时间旅行查询:查询截至时间轴中给定时间戳的表快照。
文章来源:https://blog.csdn.net/tryll/article/details/135048743
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【译】MongoDB 性能最佳实践指南
- linux系统中出现大量不可中断进程和僵尸进程怎么办?
- Java语言基础-总和
- WPF 使用矢量字体图标
- Meta与Ray-Ban合作推出了一款全新智能眼镜外观时尚,而且搭载了能够“看到“你所看到的一切的人工智能技术
- JavaScript-jQuery2-笔记
- 人工智能自然语言处理:语言之美,算法之智
- 将数组转换为树形结构
- 取消paypal免密支付绑定平台
- 学习在UE中通过Omniverse实现对USD文件的Live-Sync(实时同步编辑)