三维场景生成论文整理
一、分数蒸馏采样(score distillation sampling)
把分数蒸馏采样单独拿出来讲,实在是因为这个东西太重要了,是文生3D的核心。
在MVdream论文中,作者列出了两类基于Diffusion生成3D模型的思路
? Using the generated multi-view images as inputs for a few-shot 3D reconstruction method.
? Using the multi-view diffusion model as a prior for Score Distillation Sampling (SDS).
第一条非常直观,我用一个文生图模型生成多视图图像,然后进行三维重建,主要问题是文生图模型很难控制多视角图像的连贯性稳定性。
第二条比较难理解,我们来看Dreamfusion的pipeline
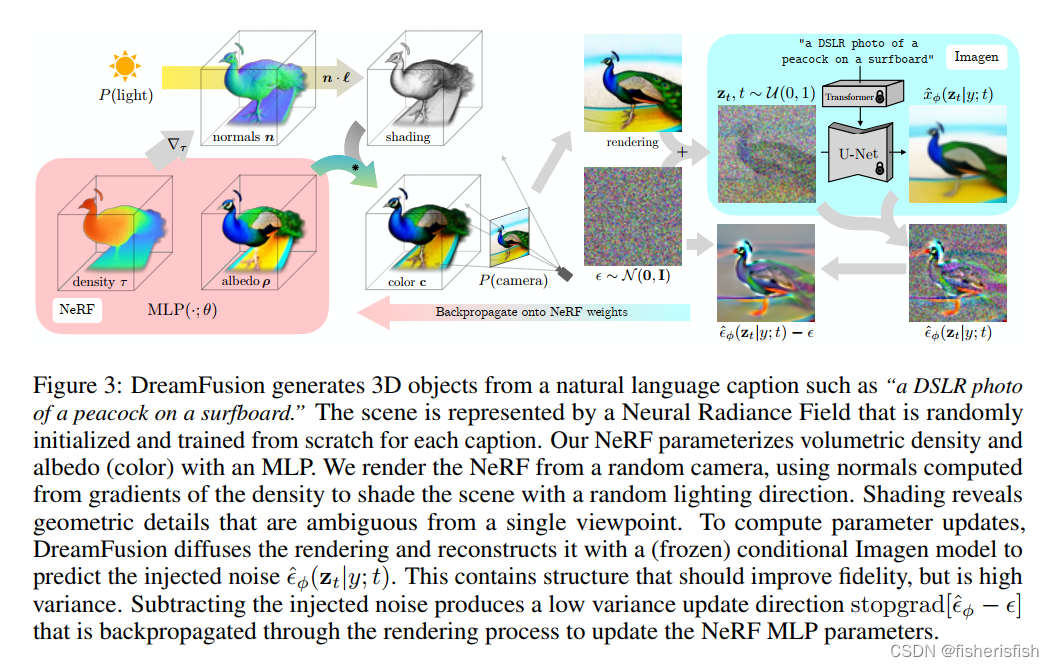
这个pipeline其实得从左往右看,首先使用随机初始化的NeRF,在球坐标中随机采样一个相机参数P并在相机周围采样点光源来渲染图像,然后渲染出得图像进入diffusion模型加噪,再用训练好的U-Net预测噪声,注意 文本信息是通过这一步加入到pipeline中的,这个时候假如NeRF渲染出来的图片接近真实的图片,那么我们用Diffusion模型预测的噪声就应该和加上的噪声接近。此时,我们就可以照搬Diffusion的损失函数??来度量噪声的接近程度:?
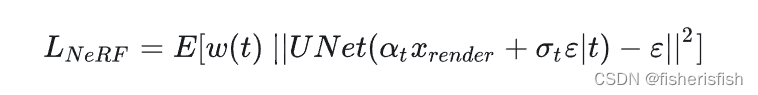
?这里我们再次回顾NeRF的输入,![]()
camera是相机参数信息,是采样点的(x,y,z,d),只不过在dreamfusion里,随机初始化NeRF场,然后在球坐标中随机采样一个相机参数P并在相机周围采样点光源,这时我们便可以在相机P下对NeRF场进行渲染(render),从而得到该相机参数P下对应的render图

清楚这一过程之后,我们可以来看这一段之中需要优化的步骤,首先就是NeRF的MLP,然后是diffusion的U-Net,我们写出损失函数
 ?
?
?简化成噪声损失梯度,U-Net优化梯度,和NeRF优化梯度,然后由于Unet的梯度难以计算,并且实践上看并不是那么重要,因此DreamFusion直接把这块最硬的骨头扔掉了,最终仍然可以获得比较好的结果。这个过程中我们就得到了Text-to-3D领域最重要的损失函数:SDS Loss。
1、随机采样一个相机和灯光
在每次迭代中,相机位置在球面坐标中被随机采样,仰角范围从-10°到90°,方位角从0°到360°,与原点的距离为1到1.5
同时还在原点周围取样一个看(look-at)的点和一个向上(up)的矢量,并将这些与摄像机的位置结合起来,创建一个摄像机的姿势矩阵。同时对焦距乘数服从U(0.7, 1.35)进行采样,点光位置是从以相机位置为中心的分布中采样的。
使用广泛的相机位置对合成连贯的三维场景至关重要,宽泛的相机距离也有助于提高学习场景的分辨率。
2、从该相机和灯光下渲染NeRF的图像
考虑到相机的姿势和光线的位置,以64×64的分辨率渲染阴影NeRF模型。在照明的彩色渲染、无纹理渲染和没有任何阴影的反照率渲染之间随机选择。
3、计算SDS损失相对于NeRF参数的梯度
通常情况下,文本prompt描述的都是一个物体的典型视图,在对不同的视图进行采样时,这些视图并不是最优描述。根据随机采样的相机的位置,在提供的输入文本中附加与视图有关的文本是有益的。
对于大于60°的高仰角,在文本中添加俯视(overhead view),对于不大于60°的仰角,使用文本embedding的加权组合来添加前视图、侧视图 或 后视图,具体取决于方位角的值。
4、使用优化器更新NeRF参数
3D场景在一台有4个芯片的TPUv4机器上进行了优化,每个芯片渲染一个单独的视图并评估扩散U-Net,每个设备的batch size为1。优化了15,000次迭代,大约需要1.5小时。
二、ProlificDreamer
把SDS更新方向的第二项由零均值的高斯换成了变分分布的Score。

?
 ?
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 性能测试工具Jmeter学习和使用
- 暗光增强——Zero-DCE网络推理测试
- C++类包含编译模型实战
- 智能高效|AIRIOT智慧货运管理解决方案
- 根据方程组解,生成n个n元一次方程组
- 【DFS】200.岛屿数量
- 基于spring boot的中小型仓库物流管理系统(Java毕业设计)
- unity学习笔记
- 三端负电源电压调节器79LXX,具有一系列固定电压输出,适用于小于100mA电源供给的场合
- Python 循环结构值while循环