NLP论文阅读记录 - 2021 | WOS 利用 ParsBERT 和预训练 mT5 进行波斯语抽象文本摘要
文章目录
前言

Leveraging ParsBERT and Pretrained mT5 for Persian Abstractive Text Summarization(21)
0、论文摘要
文本摘要是最关键的自然语言处理(NLP)任务之一。每天都有越来越多的研究在这一领域进行。基于 Transformer 的预训练编码器解码器模型已开始在这些任务中受到欢迎。本文提出了两种方法来解决此任务,并引入了一个名为 pnsummary 的新颖数据集,用于波斯语抽象文本摘要。本文使用的模型是 mT5 和 ParsBERT 模型的编码器-解码器版本(即波斯语的单语言 BERT 模型)。这些模型在 pn-summary 数据集上进行了微调。目前的工作是此类工作中的首例,通过取得有希望的成果,可以作为任何未来工作的基线。
一、Introduction
1.1目标问题
随着数字时代的出现,大量的文本信息已经可以通过数字方式获得。不同的自然语言处理 (NLP) 任务侧重于该信息的不同方面。自动文本摘要是这些任务之一,关注将文本压缩为较短的格式,以便保留内容中最重要的信息[1]、[2]。这在许多应用中至关重要,因为由人类生成摘要,无论多么精确,都可能变得相当耗时且麻烦。此类应用包括搜索引擎中使用的文本检索系统,用于显示搜索结果的摘要版本[3]。文本摘要可以从不同的角度来看待,包括单文档[4]与多文档[5]、[6]以及单语言与多语言[7]。然而,这项任务的一个重要方面是方法,它要么是提取的,要么是抽象的。在提取式摘要中,从上下文中选择几个句子来代表整个文本。这些句子是根据它们的分数(或排名)来选择的。这些分数是通过计算某些特征来确定的,例如句子之间的顺序位置、句子的长度、名词的比例等。对句子进行排序后,选择前 n 个句子来代表整个文本 [8] 。抽象摘要技术通过使用原始文本中不一定存在的单词生成新句子来创建原始文本的简短版本。与提取性摘要相比,抽象技术更令人畏惧,但也更有吸引力和灵活。因此,不同语言的抽象技术越来越受到关注。然而,据我们所知,专门研究波斯语文本摘要的著作太少,几乎所有著作都是摘录的。部分原因是缺乏可用于此任务的适当的波斯语文本数据集。这是当前工作背后的主要动机:为波斯语创建一个抽象文本摘要框架,并为此任务编写一个新的格式正确的数据集。
1.2相关的尝试
抽象文本摘要有不同的方法,特别是对于英语,其中许多方法基于序列到序列(Seq2Seq)结构,因为文本摘要可以被视为 Seq2Seq 任务。
在[9]中提出了一种Seq2Seq编码器-解码器模型,其中使用深度循环生成解码器来提高摘要质量。 [10]中提出的模型是一种用于抽象文本摘要的注意力编码器-解码器递归神经网络(RNN)。在[11]中,引入了一种新的训练方法,将强化学习与监督词预测相结合。 [12] 中提出了 Seq2Seq 模型的增强版本。类似地,[13]中提出了编码器-解码器架构的扩展版本,该架构受益于用于抽象概括的信息选择层。
上面提到的许多工作都受益于预训练的语言模型,因为这些模型已经开始在过去几年中获得了巨大的人气。这是因为他们利用迁移学习的优势,将每个 NLP 任务简化为轻量级微调阶段。因此,预训练用于文本摘要的 Seq2Seq 结构的方法可能非常有前途。BERT [14] 和 T5 [15] 是广泛使用的预训练语言建模技术。 BERT 使用掩码语言模型 (MLM) 和编码器-解码器堆栈对左右上下文执行联合调节。另一方面,T5 是一个统一的 Seq2Seq 框架,采用 Text-to-Text 格式来解决基于 NLP 文本的问题。
T5 模型的多语言变体称为 mT5 [16],涵盖 101 种不同的语言,并在基于 Common Crawl 的数据集上进行训练。由于其多语言特性,mT5 模型是英语以外语言的合适选择。 BERT模型还有多语言版本。然而,该模型 [17]、[18] 有许多单语言版本,它们在各种 NLP 任务上表现优于多语言版本。对于波斯语,ParsBERT 模型 [19] 在命名实体识别 (NER) 和情感分析等许多波斯语 NLP 任务上表现出了最先进的水平。
尽管预训练语言模型在自然语言理解(NLU)任务方面非常成功,但它们在 Seq2Seq 任务方面表现出较低的效率。因此,在本文中,我们试图通过做出以下贡献来解决波斯语在文本摘要方面的上述缺点:
1.3本文贡献
总之,我们的贡献如下:
? 为波斯语文本摘要任务引入一个新颖的数据集。该数据集是公开可用的1,任何希望将其用于未来工作的人都可以使用。
? 研究波斯语文本抽象文本摘要的两种不同方法。一种是在 Seq2Seq 结构中使用 ParsBERT 模型,如 [20] 中所示。另一种是使用mT5模型。这两个模型都在建议的数据集上进行了微调。
本文的其余部分结构如下。第二节概述了 ParsBERT Seq2Seq 编码器-解码器模型以及 mT5。在第三节中,概述了两种方法的微调和文本生成配置。第四节介绍了数据集的组成及其统计特征。本节还概述了用于衡量模型性能的指标。第五节介绍了对早期模型中提到的数据集进行微调所获得的结果。最后,第六节总结了本文。
二.前提
三.本文方法
本节概述了序列到序列 ParsBERT 和 mT5 架构。
A. 序列到序列 ParsBERT
ParsBERT [19] 是波斯语 BERT 语言模型 [14] 的单语版本,采用 BERT 模型的基本配置(即 12 个隐藏层,隐藏大小为 768,有 12 个注意力头)。 BERT 是一种基于 Transformer 的 [21] 语言模型,具有如图 1 所示的仅编码器架构。在该架构中,输入序列 {x1, x2, …, xn} 映射到上下文化编码序列 { x′ 1, x′ 2, …, x′ n } 通过一系列双向自注意力块,每个块中有两个前馈层。然后可以通过将分类层添加到最后一个隐藏层来将输出序列映射到特定于任务的输出类。
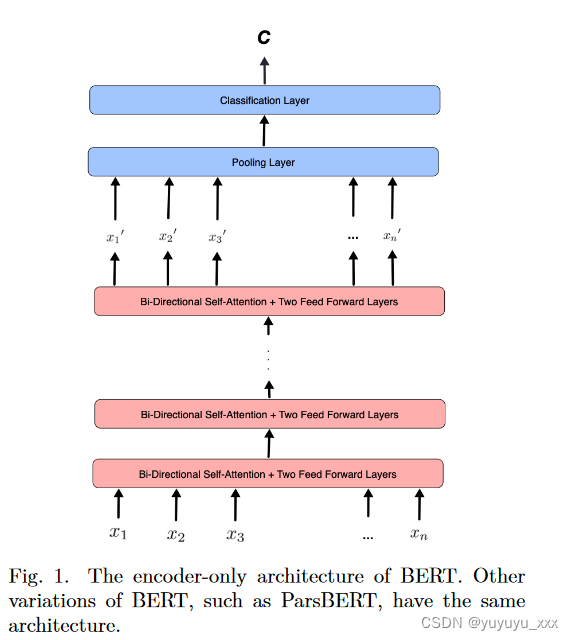
BERT 模型通过将输入序列映射到具有先验已知输出长度的输出序列,在 NLU 任务上实现了最先进的性能。然而,由于输出序列维度不依赖于输入,因此使用 BERT 进行文本生成(摘要)是不切实际的。换句话说,任何基于 BERT 的模型都只对应于基于 Transformer 的编码器-解码器模型的编码器部分的架构,这些模型主要用于文本生成。
另一方面,诸如 GPT-2 [22] 之类的仅解码器模型可以用作文本生成的手段。然而,事实证明,编码器-解码器结构可以更好地完成此类任务[23]。
因此,我们使用 ParsBERT 来热启动如[20]中提到的,从仅编码器检查点中训练编码器和解码器,以实现预训练的编码器解码器模型(BERT2BERT或B2B),该模型可以使用第四节中介绍的数据集进行微调以进行文本摘要。
在此架构中,编码器层与 ParsBERT 转换器层相同。解码器层也与 ParsBERT 相同,但有一些变化。首先,在自注意力层和前馈层之间添加交叉注意力层,以便根据上下文编码序列(例如 ParsBERT 模型的输出)调节解码器。其次,将双向自注意力层更改为单向层以与自回归生成兼容。总而言之,在热启动解码器时,只有交叉注意力层权重被随机初始化,所有其他权重都是 ParsBERT 的预训练权重。图 2 说明了与 ParsBERT 模型一起热启动的所提出的 BERT2BERT 模型的构建块,以及示例文本及其由所提出的模型生成的摘要版本。

在此图中,输入文本首先被馈送到特殊的标记编码器,该编码器处理半空格字符 (U+200C Unicode) 并删除不需要的标记。半空格字符在波斯语中广泛用于各种情况(例如形成复数名词)。在图 2 所示的示例文本中,单词“???????”实际上由三个标记组成:“????”(名词)+ [unused0] +“??”(复数标记),其中 [unused0] 标记代表半-将名词连接到复数标记的空格标记。之后,文本被馈送到编码器块,编码器块的结果被馈送到解码器块,解码器块又生成输出摘要。然后将半字符标记转换为实际的半字符特定的令牌解码器块。
B、mT5
mT5 代表多语言文本到文本传输转换器(多语言 T5),是 T5 模型的多语言版本。 T5 是一种编码器-解码器 Transformer 架构,它密切反映了原始 Transformer 模型 [24] 的主要构建块,并涵盖以下目标:
? 预测下一个单词的语言建模。 ? 反洗牌以重新定义原始文本。 ? 破坏跨度来预测屏蔽词。
T5网络架构继承了之前下游NLP任务的统一框架,并将其转变为文本到文本的格式[23]。换句话说,T5 架构允许采用编码器-解码器过程将每个可能的 NLP 任务聚合到一个网络中。因此,每个任务都使用相同的超参数和损失函数。如图 3 所示。
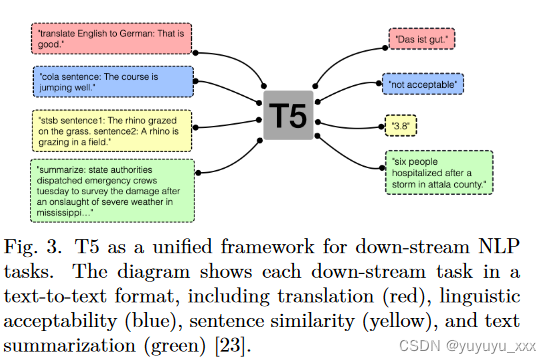
mT5继承了T5型号的所有功能。 mT5 在 C4 数据集的扩展版本上进行了训练,该数据集包含 101 种语言(包括波斯语)的 10,000 多个网页内容,迄今为止超过 71 个月的抓取。
与其他多语言模型(如多语言 BERT [14]、XLM-R [25] 和多语言 BERT(不支持波斯语)[26])相比,mT5 在所有任务上都达到了最先进的水平 [15], [16],特别是在总结任务上。
四 实验效果
4.1数据集
4.2 对比模型
4.3实施细节
为了在第 IV 节中介绍的 pn-summery 数据集上微调第 II 节中介绍的两个模型,我们使用了具有 1000 个预热步骤的 Adam 优化器,批量大小为 4 和 5 个训练周期。 Seq2Seq ParsBERT 和 mT5 的学习率分别为 5e ? 5 和 1e ? 4。
文本生成过程是指微调模型后自回归语言生成的解码策略。本质上,自回归生成围绕这样的假设:任何单词序列的概率分布都可以分解为条件下一个单词分布的乘积,如方程(1)所示,其中 W0 是初始上下文单词,T 是单词序列的长度。
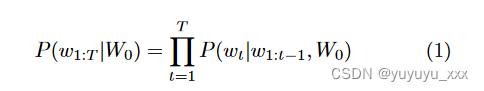
这里的目标是通过选择最佳标记(单词)来最大化序列概率。一种方法是贪婪搜索,其中选择的下一个单词只是概率最高的单词。然而,如果高概率的单词隐藏在一些低概率的单词后面,则该方法会忽略它们。为了解决这个问题,我们使用波束搜索方法,在每个时间步保留 nbeams 个最可能的序列(即波束),并最终选择总体概率最高的一个。与贪婪搜索相比,集束搜索生成更高概率的序列。
一个缺点是集束搜索??往往会生成一些重复单词的序列。为了克服这个问题,我们利用 n-grams 惩罚 [11]、[27]。这样,如果下一个单词导致生成已经见过的 n-gram,则该单词的概率将设置为0 手动,从而防止 n-gram 重复。波束搜索中使用的另一个参数是早期停止,它可以是活动的也可以是非活动的。如果处于活动状态,则当所有波束假设到达 EOS 代币时,文本生成将停止。表 I 列出了当前工作中用于 BERT2BERT 和 mT5 模型的波束数量、n 元惩罚大小、长度惩罚和早期停止值。

4.4评估指标
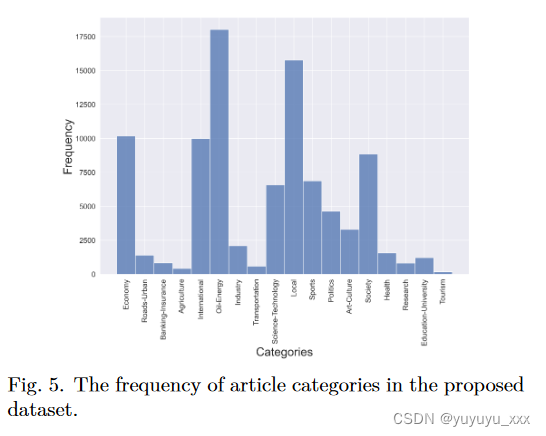
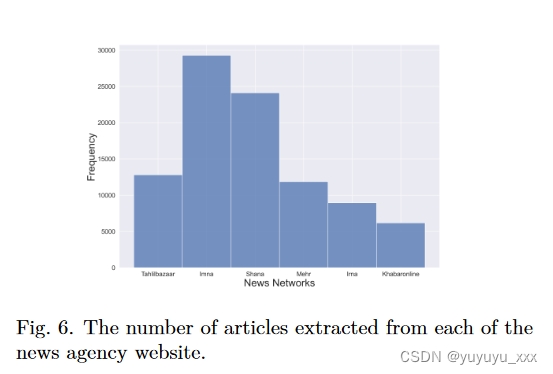
为了评估本文介绍的两种架构的性能,我们通过从 6 个不同的新闻机构网站抓取大量文章及其摘要来构建一个新的数据集,以下表示为 pn-summary。两个模型都在此数据集上进行了微调。因此,这是第一次建议将该数据集用作波斯语抽象摘要的基准。该数据集共包含 93,207 篇文档,涵盖从经济到旅游的一系列类别。文章类别的频度分布和各通讯社的文章数量分别如图5和图6所示。
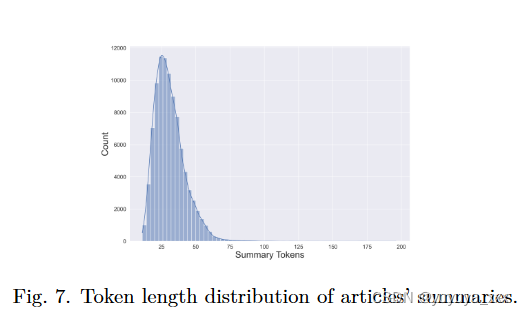
应该注意的是,文章摘要中的标记数量各不相同。如图7所示。从图中可以看出,大多数文章的摘要长度都在30个token左右。
为了确定模型的性能,我们使用面向回忆的基础评估(ROUGE)度量包[28]。该软件包广泛用于自动摘要和机器翻译评估。此包中包含的指标将自动摘要与每个文档的参考摘要进行比较。该包中包含五种不同的指标。我们计算其中三个指标的 F-1 分数,以显示两个模型在建议数据集上的整体性能: ? ROUGE-1(一元语法)评分,用于计算生成的摘要和参考摘要之间一元语法的重叠。 ? ROUGE-2(二元组)评分,计算生成摘要和参考摘要之间二元组的重叠。 ? ROUGE-L 评分,其中分数是在句子级别计算的。在此度量中,新行将被忽略,并计算两个文本片段之间的最长公共子序列(LCS)。
4.5 实验结果
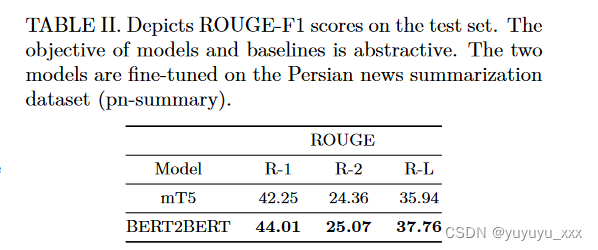
本节介绍了在所提出的 pn-summary 数据集上通过微调 mT5 和基于 ParsBERT 的 BERT2BERT 结构获得的结果。表 II 报告了第 IV 节中讨论的三种不同 ROUGE 指标的 F1 分数。可以看出,与 mT5 模型相比,ParsBERT B2B 结构获得了更高的分数。这可能是因为该架构中的编码器解码器权重(即 ParsBERT 权重)是在大量波斯语语料库上进行具体调整的,这使其成为适合仅限波斯语任务的架构。
由于尚未针对波斯语提出其他预训练的抽象摘要方法,并且这是第一次引入和发布 pn-summary 数据集,因此不可能将当前工作的结果与任何其他基线进行比较。因此,这项工作中提出的结果可以作为任何未来波斯语抽象方法的基线,这些方法试图在当前工作中提出和发布的拟议 pn-summary 数据集上训练他们的模型。为了进一步说明这两个模型的性能,我们在表 III 中包含了数据集中的两个示例。正文、实际摘要以及 mT5 和 BERT2BERT 模型生成的摘要如下表所示。根据该表,两个示例中 BERT2BERT 模型给出的摘要无论是含义还是词汇选择都比较接近实际摘要。
4.6 细粒度分析
五 总结
波斯语文本摘要的工作有限,其中没有一个是基于预先训练的模型进行抽象的。在本文中,我们提出了两种预训练方法,旨在通过抽象方法解决波斯语文本摘要问题:一种基于多语言 T5 模型,另一种是从 ParsBERT 语言模型热启动的 BERT2BERT。我们还编写并发布了一个名为 pn-summary 的新数据集,用于文本摘要,因为波斯语明显缺乏此类数据集。在上述数据集上微调所提出的方法的结果是有希望的。由于该领域缺乏工作,我们的工作无法与任何早期的工作进行比较,现在可以作为该领域任何未来工作的基线。
思考
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Text-to-SQL小白入门(十一)DAIL-SQL教你刷Spider榜单第一
- 3.1 内容管理模块 - 工程搭建、课程查询、配置Swagger、数据字典
- Python库中关于时间的常见操作
- 2020年认证杯SPSSPRO杯数学建模A题(第一阶段)听音辨位全过程文档及程序
- [论文笔记] 大模型gpu机器推理测速踩坑 (llama/gpt类)
- Oracle12c创建表空间及用户
- QPushButton样式设置
- CMake入门教程【高级篇】编译选项target_compile_options
- ubuntu20.04里面安装目标检测数据标注软件labelImg的详细过程
- 对有状态组件和无状态组件的理解及使用场景