大语言模型系列-word2vec
文章目录
前言
在前文大语言模型系列-总述已经提到传统NLP的一般流程:
创建语料库 => 数据预处理 => 分词向量化 => 特征选择 => 建模(RNN、LSTM等)
传统的分词向量化的手段是进行简单编码(如one-hot),存在如下缺点:
- 如果词库过大, one-hot编码生成的向量会造成维度灾难
- one-hot编码生成的向量是稀疏的,它们之间的距离相等,无法捕捉单词之间的语义关系。
- one-hot编码是固定的,无法在训练过程中进行调整。
因此,出现了词嵌入(word embedding)的概念,通过word embedding模型生成的向量是密集的,具有相似含义的单词在向量空间中距离较近,可以捕捉单词之间的语义关系。并且Word Embedding模型的权重可以在训练过程中进行调整,以便更好地捕捉词汇之间的语义关系。
word2vec就是一种经典的词嵌入(word embedding)模型,由Tomas Mikolov等人在2013年提出,它通过学习将单词映射到连续向量空间中的表示,以捕捉单词之间的语义关系。
提示:以下是本篇文章正文内容,下面内容可供参考
一、word2vec的网络结构和流程
Word2Vec是轻量级的神经网络,其模型仅仅包括输入层、隐藏层和输出层,根据学习思路的不同,分为两种训练方式:Skip-Gram和CBOW(Continuous Bag of Words)。其中,Skip-gram是已知当前词的情况下预测上下文的表示,CBOW则是在已知上下文的情况下预测当前词的表示。通过这种表示学习,学得映射矩阵,将原始离散数据空间映射到新的连续向量空间(实际上起到了降维的作用)。
- 将单词使用one-hot编码
- 输入网络进行训练,获得参数矩阵 W V × N W_{V×N} WV×N?
- 输入层的每个单词one-hot编码x(V-dim)与矩阵W相乘,即 x ? W V × N x \cdot W_{V×N} x?WV×N?,得到其word embedding(N-dim)
1.Skip-Gram模型
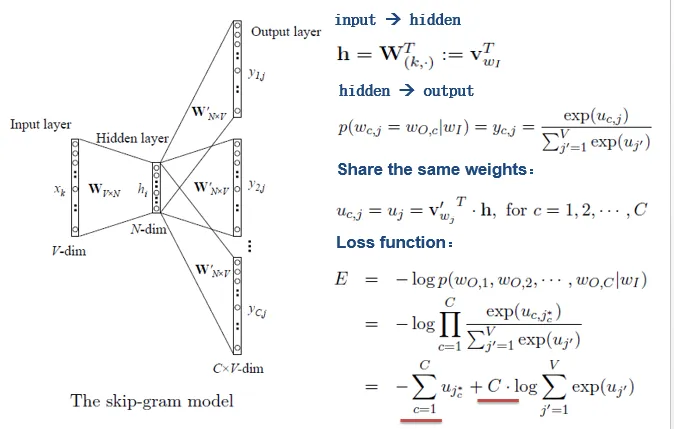
2.CBOW模型
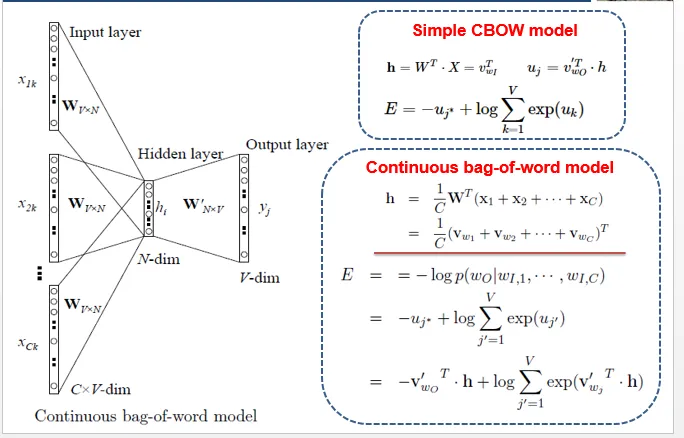
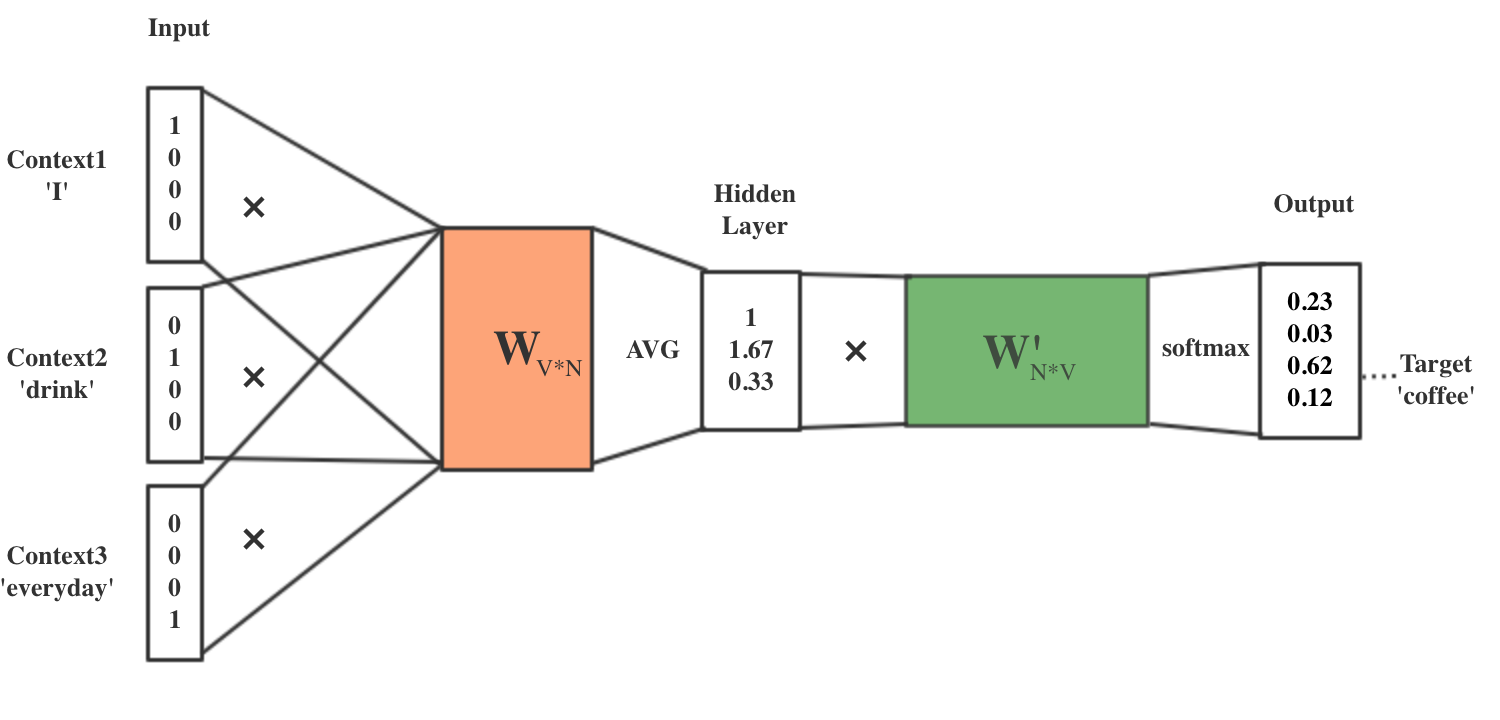
二、word2vec的训练机制
假设语料库中有V个不同的单词,hidden layer取128,则word2vec两个权值矩阵维度都是[V,128],我们使用的语料库往往十分庞大,这也会导致权值矩阵的庞大,即神经网络的参数规模的庞大,在使用SGD对庞大的神经网络进行学习时,将是十分缓慢的。
word2vec提出两种加快训练速度的方式,一种是Hierarchical softmax,另一种是Negative Sampling。
1. Hierarchical softmax
和传统的神经网络输出不同的是,word2vec的hierarchical softmax结构是把输出层改成了一颗哈夫曼树,其中图中白色的叶子节点表示词汇表中所有的V个词,黑色节点表示非叶子节点,每一个叶子节点也就是每一个单词,都对应唯一的一条从root节点出发的路径。我们的目的是使的 w = w 0 w=w_0 w=w0?这条路径的概率最大,即: P ( w = w 0 ∣ w I ) P(w=w_0|w_I) P(w=w0?∣wI?)最大,假设最后输出的条件概率是 P ( w = w 0 ∣ w 2 ) P(w=w_0|w_2) P(w=w0?∣w2?)最大,那么只需要去更新从根结点到 w 2 w_2 w2?这一个叶子结点的路径上面节点的向量即可,而不需要更新所有的词的出现概率,这样大大的缩小了模型训练更新的时间。
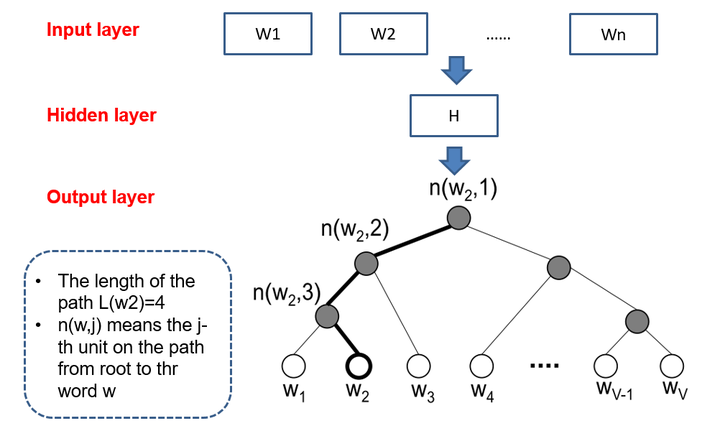
ps:
- 给定N个权值作为N个叶子结点,构造一棵二叉树,若该树的带权路径长度达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树(Huffman Tree)。哈夫曼树是带权路径长度最短的树,权值较大的结点离根较近。
- 我们知道在输入softmax之前,可以简单认为神经网络输出的大体含义为每个单词的频率,可以将其视为权值,然后通过哈夫曼树编码。这样在训练时,如果我们要计算Leaf2(观看)的概率,只需计算从Root到Leaf2路径上的节点的概率即可,而不需要考虑其他叶子节点,从而大大降低计算复杂度。
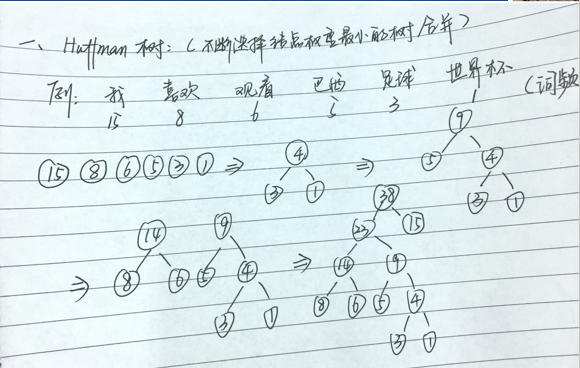

Hierarchical softmax的优点如下:
1)从利用softmax计算概率值改为利用Huffman树计算概率值,计算复杂度从O(V)变成了O(logV)
2)由于使用霍夫曼树是高频的词靠近树根,这样高频词需要更少的时间会被找到(贪心优化思想)
2. Negative Sampling
我们已经知道,对于每个训练样本,word2vec都需要计算并更新所有词汇表中的词的权重。这在大规模的词汇表上会变得非常昂贵,尤其是当词汇表非常大时。
Hierarchical softmax通过哈夫曼树,使得对于每个训练样本,只需要更新路径节点权重即可,大大减少了参数量和计算成本。Negative Sampling则通过只更新与当前训练样本相关的一小部分词的权重,以此来降低计算成本。具体步骤如下:
- 对于输入的中心词 w c w_c wc?,设置窗口大小m,该窗口大小内的词为正样本(即 w c ? m , . . . , w c + m w_{c-m},...,w_{c+m} wc?m?,...,wc+m?,不包括 w c w_c wc?)
- 按照一定的概率分布 P ( w ~ ) P(\tilde w) P(w~)从词典中抽取K个负样本 w ~ 1 , w ~ 2 , . . . , w ~ k \tilde w_1, \tilde w_2,..., \tilde w_k w~1?,w~2?,...,w~k?,那么{ w c , w ~ k w_c,\tilde w_k wc?,w~k?}为负样本,其中k=1,2,…,K
- 则给定中心词 w c w_c wc?,预测 w j w_j wj?( j ∈ [ c ? m , c + m ] j∈[c-m,c+m] j∈[c?m,c+m])由如下事件集构成: w c w_c wc?和 w j w_j wj?共同出现,以及 w c w_c wc?不和 w ~ k \tilde w_k w~k?共同出现
Negative Sampling的优点如下:
1)将多分类问题转换成K+1个二分类问题,从而减少计算量,计算复杂度由O(V)变成了O(K),加快了训练速度。
2)保证模型训练效果,因为目标词只跟相近的词有关,没有必要使用全部的单词作为负例来更新它们的权重。
总结
和之前的方法相比,word2vec能够考虑上下文并获得低维的词向量表示,但word2vec无法解决多义词问题,没有语境信息,原因是word embedding是静态的(词和向量是一对一的关系),并且词嵌入和实际任务模型分开,使得整个训练过程不是端到端的。

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!