c++语言基础16-出现频率最高的字母
题目描述
给定一个只包含小写字母的字符串,统计字符串中每个字母出现的频率,并找出出现频率最高的字母,如果最高频率的字母有多个,输出字典序靠前的那个字母。
输入描述
包含多组测试数据,每组测试数据占一行。
输出描述
有多组输出,每组输出占一行。
输入示例
2
abcdeef
aabbccddeeff
输出示例
e
a
学了数组,字符串,链表。如果我们想要找到其中某个元素或者节点,需要从索引为0的位置或者表头开始,逐一进行比较,直到找到相等的位置或者末尾才会结束。那是否可以避免之前的比较,直接通过要查找的记录直接找到其存储位置呢?
是有的,可以通过“哈希表”来实现,哈希表是根据关键码key的值而直接进行访问的数据结构。
哈希表的作用是快速判断一个元素是否出现在集合里,它的核心思想是在关键码和存储位置之间建立一个确定的对应关系f, 使得每个关键字key对应一个存储位置,而这个对应关系,称之为散列函数(哈希函数)。
其实数组就是一张哈希表,哈希表中关键码就是数组的索引下标,然后通过下标直接访问数组中的元素。
哈希表来解决问题的时候,一般选择以下三种数据结构。
数组
set集合
map映射
哈希表
哈希表
首先什么是 哈希表,哈希表(英文名字为Hash table,国内也有一些算法书籍翻译为散列表,大家看到这两个名称知道都是指hash table就可以了)。
哈希表是根据关键码的值而直接进行访问的数据结构。
这么这官方的解释可能有点懵,其实直白来讲其实数组就是一张哈希表。
哈希表中关键码就是数组的索引下标,然后通过下标直接访问数组中的元素
那么哈希表能解决什么问题呢,一般哈希表都是用来快速判断一个元素是否出现集合里。
例如要查询一个名字是否在这所学校里。
要枚举的话时间复杂度是O(n),但如果使用哈希表的话, 只需要O(1)就可以做到。
我们只需要初始化把这所学校里学生的名字都存在哈希表里,在查询的时候通过索引直接就可以知道这位同学在不在这所学校里了。
将学生姓名映射到哈希表上就涉及到了hash function ,也就是哈希函数。
哈希表可以将其比喻为一个大抽屉,抽屉里面有很多小格子。每个格子可以用来存放一些东西。
抽屉编号: 抽屉有编号,这个编号就是数据的key,我们通过这个key来找到对应的抽屉。
散列函数: 哈希表使用一种特殊的函数(哈希函数),来决定数据应该放在哪个抽屉里。这个函数将数据的名字key转换成一个数字,然后根据这个数字来选择一个抽屉。
抽屉里的物品: 在每个抽屉里,可以放一些东西,这些东西就是我们要存储的数据。
解决冲突: 有时候不同的key经过散列函数后可能会得到相同的编号,这就是冲突。哈希表有方法来处理这些冲突。
快速查找: 当我们需要找到某个数据时,哈希表可以通过名字key快速地找到对应的抽屉,然后取出里面的数据,这个操作非常快速,就像从抽屉中拿出东西一样。
哈希函数
哈希函数,把学生的姓名直接映射为哈希表上的索引,然后就可以通过查询索引下标快速知道这位同学是否在这所学校里了。
哈希函数如下图所示,通过hashCode把名字转化为数值,一般hashcode是通过特定编码方式,可以将其他数据格式转化为不同的数值,这样就把学生名字映射为哈希表上的索引数字了。
如果hashCode得到的数值大于 哈希表的大小了,也就是大于tableSize了,怎么办呢?
此时为了保证映射出来的索引数值都落在哈希表上,我们会在再次对数值做一个取模的操作,这样我们就保证了学生姓名一定可以映射到哈希表上了。
此时问题又来了,哈希表我们刚刚说过,就是一个数组。
如果学生的数量大于哈希表的大小怎么办,此时就算哈希函数计算的再均匀,也避免不了会有几位学生的名字同时映射到哈希表 同一个索引下标的位置。
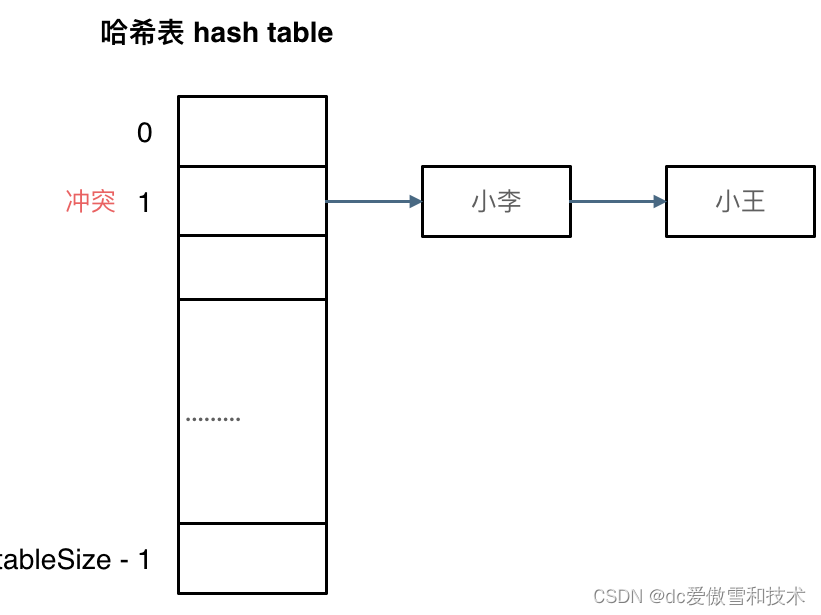
接下来哈希碰撞登场
哈希碰撞
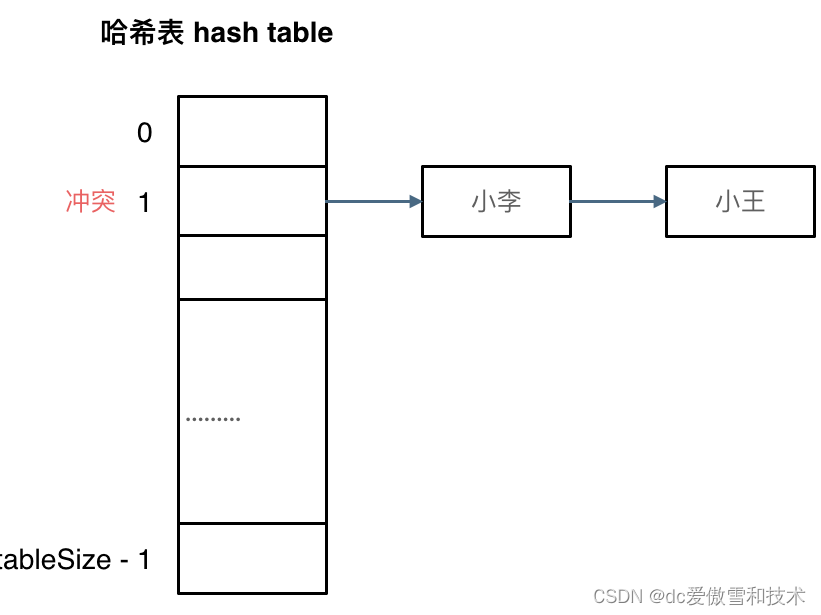
如图所示,小李和小王都映射到了索引下标 1 的位置,这一现象叫做哈希碰撞。
一般哈希碰撞有两种解决方法, 拉链法和线性探测法。
拉链法
刚刚小李和小王在索引1的位置发生了冲突,发生冲突的元素都被存储在链表中。 这样我们就可以通过索引找到小李和小王了
(数据规模是dataSize, 哈希表的大小为tableSize)
其实拉链法就是要选择适当的哈希表的大小,这样既不会因为数组空值而浪费大量内存,也不会因为链表太长而在查找上浪费太多时间
线性探测法
使用线性探测法,一定要保证tableSize大于dataSize。 我们需要依靠哈希表中的空位来解决碰撞问题。
例如冲突的位置,放了小李,那么就向下找一个空位放置小王的信息。所以要求tableSize一定要大于dataSize ,要不然哈希表上就没有空置的位置来存放 冲突的数据了。如图所示:
常见的三种哈希结构
当我们想使用哈希法来解决问题的时候,我们一般会选择如下三种数据结构。
数组
set (集合)
map(映射)
在C++中,set 和 map 分别提供以下三种数据结构,其底层实现以及优劣如下表所示:
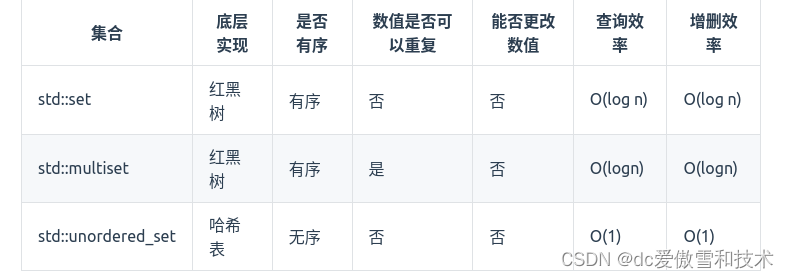
std::unordered_set底层实现为哈希表,std::set 和std::multiset 的底层实现是红黑树,红黑树是一种平衡二叉搜索树,所以key值是有序的,但key不可以修改,改动key值会导致整棵树的错乱,所以只能删除和增加。
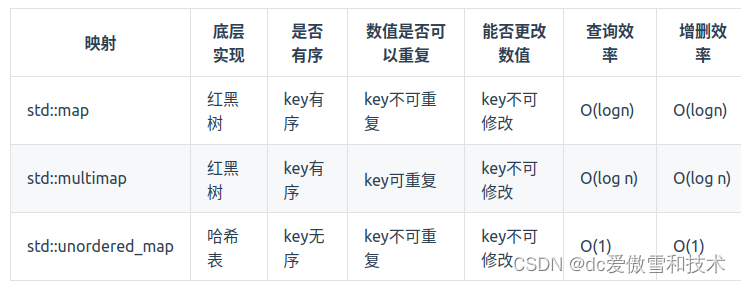
std::unordered_map 底层实现为哈希表,std::map 和std::multimap 的底层实现是红黑树。同理,std::map 和std::multimap 的key也是有序的(这个问题也经常作为面试题,考察对语言容器底层的理解)。
当我们要使用集合来解决哈希问题的时候,优先使用unordered_set,因为它的查询和增删效率是最优的,如果需要集合是有序的,那么就用set,如果要求不仅有序还要有重复数据的话,那么就用multiset。
那么再来看一下map ,在map 是一个key value 的数据结构,map中,对key是有限制,对value没有限制的,因为key的存储方式使用红黑树实现的。
其他语言例如:java里的HashMap ,TreeMap 都是一样的原理。可以灵活贯通。
虽然std::set、std::multiset 的底层实现是红黑树,不是哈希表,std::set、std::multiset 使用红黑树来索引和存储,不过给我们的使用方式,还是哈希法的使用方式,即key和value。所以使用这些数据结构来解决映射问题的方法,我们依然称之为哈希法。 map也是一样的道理。
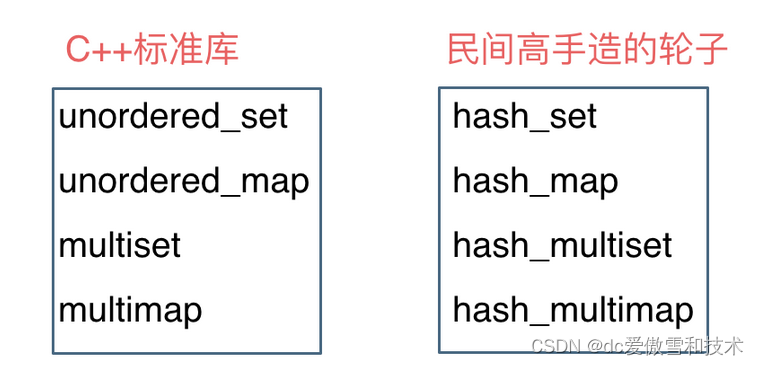
这里在说一下,一些C++的经典书籍上 例如STL源码剖析,说到了hash_set hash_map,这个与unordered_set,unordered_map又有什么关系呢?
实际上功能都是一样一样的, 但是unordered_set在C++11的时候被引入标准库了,而hash_set并没有,所以建议还是使用unordered_set比较好,这就好比一个是官方认证的,hash_set,hash_map 是C++11标准之前民间高手自发造的轮子。
总结
总结一下,当我们遇到了要快速判断一个元素是否出现集合里的时候,就要考虑哈希法。
但是哈希法也是牺牲了空间换取了时间,因为我们要使用额外的数组,set或者是map来存放数据,才能实现快速的查找。
如果在做面试题目的时候遇到需要判断一个元素是否出现过的场景也应该第一时间想到哈希法!
我遇到的问题
循环终止条件第一个循环是i < s.size(),第二个是i < 26,我开始都写为了26
题目分析
数组可以作为简单哈希表来使用,所以我们可以定义一个数组,来记录字符串s当中字符出现的次数。
由于输入的全都是小写字母,小写字母只有26个,那我们定义一个长度为26的数组即可,字符a到字符z的ASCII是26个连续的数值,所以字符a映射为下标0,相应的字符z映射为下标25。
在遍历 字符串s的时候,只需要将s[i] - 'a’所在的索引做+1 操作即可,并不需要记住字符a的ASCII,只要求出一个相对数值就可以了。 这样就将字符串s中字符出现的次数,统计出来了
经过一轮遍历之后已经完成统计,数组中各位的元素已经是a-z字母的频次了,如果想要找到最大值,还是需要重新遍历一遍,那我们如何记录这个最大值呢?
只需要先初始化最大值,然后逐一比对字符出现的频次和当前最大值的大小,如果当前字符出现的频次大于最大值,则更新最大值为当前字符出现的频次,这样完整遍历一遍后,就能找到出现频次最大的字符。
完整代码
#include <iostream>
#include <string>
int main() {
int n;
std::string s;
std::cin >> n;
while (n--) {
std::cin >> s;
int count[26] = {0};
for (int i = 0; i < s.size(); i++) {
count[s[i] - 'a'] += 1;
}
char result ;
int times = 0;
int index = 0;
for (int i = 0; i < 26; i++) {
if (count[i] > times) {
times = count[i];
index = i;
}
}
result = 'a' + index;
std::cout << result << std::endl;
}
return 0;
}
关于这个程序的时间复杂度,我们来分析一下:
读取 n 个字符串:这取决于每个字符串的长度。我们假设字符串的平均长度为 L。读取每个字符串的时间是 O(L),因此对于 n 个字符串,总的时间是 O(nL)。
对于每个字符串,程序遍历其长度来计算每个字符的频率。这也是每个字符串 O(L),所以对于所有字符串是 O(nL)。
然后,它遍历 26 个小写英文字母,以找出出现频率最高的字符。由于字母的数量(26)是固定的,所以每个字符串这部分是常数时间操作(O(1))。对于 n 个字符串,这部分是 O(n)。
字符串的平均长度为 L。读取每个字符串的时间是 O(L),因此对于 n 个字符串,总的时间是 O(nL)。
对于每个字符串,程序遍历其长度来计算每个字符的频率。这也是每个字符串 O(L),所以对于所有字符串是 O(nL)。
然后,它遍历 26 个小写英文字母,以找出出现频率最高的字符。由于字母的数量(26)是固定的,所以每个字符串这部分是常数时间操作(O(1))。对于 n 个字符串,这部分是 O(n)。
综合起来,这个程序的总体时间复杂度是 O(nL) + O(n),简化后是 O(nL),因为 O(nL) 主导了 O(n)。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 数据库读写分离设计方案
- 消息队列-RockMQ-定时延时发送消息
- 【uniapp app端下载文件到本地,支持doc、docx、txt、xlsx等类型的文件】
- Makefile(2)------Makefile的基本语法
- Zookeeper设计理念与源码剖析
- [Angular] 笔记 23:Renderer2 - ElementRef 的生产版本
- 如何利用SD-WAN优化企业访问Salesforce的体验?
- 论文翻译:Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
- 全国(山东、安徽)职业技能大赛--信息安全管理与评估大赛题目+答案讲解
- php大型酒店管理系统源码(多酒店版)带安装手册