基于SQL的可观测性现状观察

本文字数:8975;估计阅读时间:23?分钟
作者:Ryadh Dahimene
审校:庄晓东(魏庄)
本文在公众号【ClickHouseInc】首发
1375年的加泰罗尼亚地图所展示的地中海地区。通商媒介语(Lingua Franca )是地中海贸易者在8个多世纪中所使用的中世纪语言。
“未来已经到来,只是分布的不均。”《经济学家》,2003年 - 威廉·吉布森
工程学和计算机科学中许多成功的范式 paradigm 都是两种不同方法碰撞的结果,碰撞导致了更广泛、更强大的应用。
以AI为例,自动驾驶汽车的平民化直接得益于:深度学习与计算机视觉的进步。类似地,强化学习和机器人技术的结合也促使了:机器人的自治控制系统的进步。最近的另一个例子是:机器学习和自然语言处理的结合,这导致了能够以更自然和类似人类的方式,理解和回应人类用户查询的对话式聊天机器人的出现。
在接下来的博文中,我们将看到两个已建立的范式的平行背景:SQL和可观测性。我们将解释它们是如何相互碰撞的,并共同在可观测性领域里创造新的机会。最后,我们给读者提供了回答一个问题的必要元素:基于SQL的可观测性是否适用于我的场景?
如果您没有时间阅读整篇文章(约10分钟),您将在摘要部分找到主要观点。
通商媒介语 -Lingua Franca
明年将是SQL(结构化查询语言)的50周年纪念。如果您的工作或爱好与技术、数据或软件相关,那么您曾经接触过SQL的可能性会很大。2023年StackOverflow开发者调查将SQL排名为最受欢迎编程语言的第3位,被超过6.7万名专业开发者中的一半以上人使用(有人可能会说这不是一种真正的编程语言,或者它就是?)
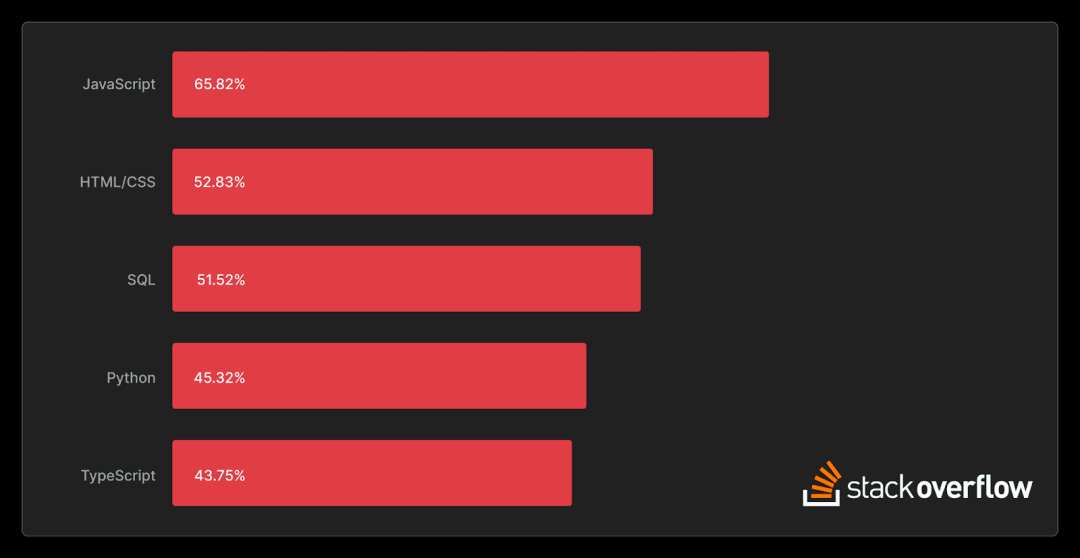
在这个快节奏的数字时代,SQL的长盛不衰和流行程度是一个例外,也证明了其简洁优雅和适应性。
关于上述排名前5的编程语言的另一个有趣之处是,除了SQL,其他所有被引用的语言都是:在1990年代或之后创建的,平均年龄约为25年。在这个快节奏的数字时代,SQL的长盛不衰和流行是一个例外,也证明了其简洁优雅和适应性。
然而,在过去的半个世纪里,它也并不都是一帆风顺,因为这么多年以来也出现了许多其他语言,并声称在处理数据时具有优越性。许多人还记得NoSQL时代,其中廉价的计算和存储资源使NoSQL运动,甚至能够颠覆SQL的长期统治。然而,十多年后,数据格局又大致回归到了SQL,这也是对其持久优势的另一种承认。
OLAP的民主化和实时分析的出现
多年来,SQL已经为不同的应用程序建模和调整,大致可分为两类:OLTP和OLAP(在线事务处理和在线分析处理)。OLTP数据库几乎从一开始就受到了广泛采用,其中的产品包括IBM DB2和Oracle等专有系统,然后是MySQL和Postgres等开源数据库系统。这是因为这些系统在几乎任何应用程序中都起着后端和事实来源的关键作用。
有趣的是,OLAP术语是由E. F. Codd在大约30年前首次引入的(即使在此之前也存在类似OLAP的系统)。OLAP得到采用的故事与OLTP不同,因为分析系统并不总是被视为“必需品”,根据数据集的大小和业务需求的性质,某些适度的分析需求可以通过OLTP系统来满足。这意味着:OLAP系统最初仅由能够为专有解决方案(如Essbase或Microsoft SSAS最初,或最近的SAP Hana和Vertica)进行投资的,并能够证明其合理性的大型组织所采用。
在过去的十多年里,OLAP得到了广泛采用的一个重要推动因素是:由Snowflake、Google BigQuery和Amazon Redshift等云数据仓库引起的。在开源领域,随着Apache Druid(2011年)、Apache Pinot(2013年)和ClickHouse(2009年开始,2016年开源)的出现,大量替代方案开始出现。开源OLAP数据库的出现有效的降低了准入门槛,提供了经济实惠的替代方案,并允许组织根据其围绕实时分析的特定需求定制解决方案。在先前的文章中,我们详细介绍了如何用开源OLAP系统有效地实现实时数据仓库。
由于可观测性是一项以实时为分析导向的任务,在本博文中,我们将使用缩写词SQL来互换地指代查询语言本身,以及其在OLAP用例中的应用。
从动态系统到syslog再到... Twitter
令人惊讶的是,可观测性的起源甚至比SQL还要古老。工程师Rudolf E. Kálmán在20世纪60年代首次使用这个术语,用于度量从系统的外部输出知识推断出其内部状态的能力。随后,计算机和IT系统的出现导致了监视和记录方法的激增。我认为另一个重要的里程碑发生在1980年代,随着"syslog"的出现,它是Eric Allman作为Sendmail项目的一部分开发的。1998年,Joshua Weinberg描述了:如何使用syslog来集中来自异构系统的日志,以帮助系统管理员完成日常任务,需要借助几个Perl脚本的帮助。因此,集中式日志记录的概念诞生了,这后来成为可观测性的第一个支柱。值得注意的是,这种最初的方法更侧重于在IT网络中发送日志的机制,并没有解决存储的问题,只将日志视为普通文件。

快进到2013年,伴随Twitter迅猛成长,带来了前所未有的可扩展性挑战,这迫使其工程团队迅速采取行动,从单体架构转向大规模分布式系统,同时保持服务的正常运行。当时,Twitter在具有影响力的博文《Twitter的可观测性》中总结了他们的方案:
“可观测性团队的任务是:使用统一平台来收集、存储和展示指标等问题...随着Twitter的不断发展,它变得更加复杂,服务变得更加庞大。存在着数以千计的服务实例,和数百万的数据点,都需要高性能的可视化和自动化,以智能地呈现有趣或异常的信号给用户”。
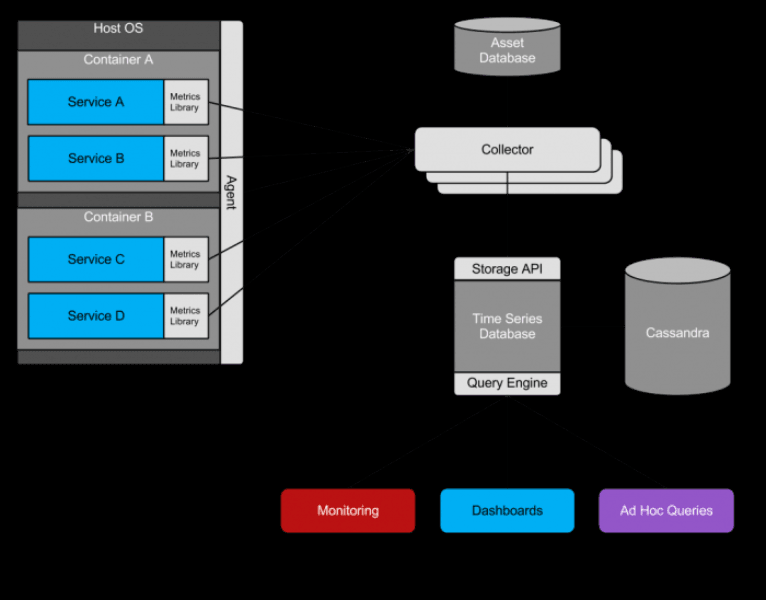
原文链接:https://blog.twitter.com/engineering/en_us/a/2013/observability-at-twitter
作为一家技术为主的公司,并且因为当时没有现成的可观测性解决方案,Twitter的工程师们自行构建了大部分组件,以满足这些需求,包括在Apache Cassandra之上构建的定制化时间序列数据库,这是一种领先的NoSQL存储。与此同时,在无数其他组织中,人们还注意到全文搜索引擎(如Elasticsearch)也可以用于存储日志和遥测数据。这种方法,得益于ELK堆栈的出现,或者像Splunk这样的专有解决方案,推动了其他NoSQL存储作为事实上的可观测性存储。
从那时起,世界已经迎头赶上,每个组织都比以往更加注重技术。因此,自然而然地,在可观测性领域涌现了许多工具和供应商,提供开箱即用、本地或SaaS解决方案,以便任何一家公司不必像Twitter在2013年那样自行构建方案。由此产生的可观测性生态系统:包括一系列NoSQL存储和即插即用的SaaS解决方案,这些解决方案通常使用NoSQL存储作为后端。这也导致了可观测性术语定义的"延伸",以一套完整的工具和实践,使组织能够有效地监控和操作其IT资产。
碰撞的路径:可观测性只是另一个数据问题
2013年的Twitter博文(如上所述)已经设定了标准的可观测性流水线,包括收集、存储、可视化和警报(请注意,Twitter将警报称为"监控")。

那么,在过去10年里发生了什么变化?
这个流水线的结构基本上仍然是一样的;许多可观测性供应商提供了端到端体验的所有组件,从收集代理、数据聚合器到存储层和图形界面呈现。然而,在可观测性流水线的每个步骤中,新的想法和项目不断地涌现出来,提供了大量可替代解决方案,有效地将SQL重新引入可观测性领域。因此,让我们深入研究每个步骤。
在可观测性流水线的每个步骤中,新的想法和项目不断地涌现出来,提供了大量可替代解决方案,有效地将SQL重新引入可观测性领域。
收集
在数据收集这个步骤中,开源发挥了魔力,社区创建了OpenTelemetry(简称OTel)等项目,专门解决可观测性数据的收集问题。OpenTelemetry是一个CNCF孵化项目,提供了一组面向供应商中立的API、SDK和工具,用于对应用进行埋点、生成、收集和导出Trace、指标和日志等遥测数据。重要的是,OTel正在逐渐确立自己作为一种行业标准。这种标准化使其更容易与不同的存储层和前端集成,并摆脱了锁定环境的限制。
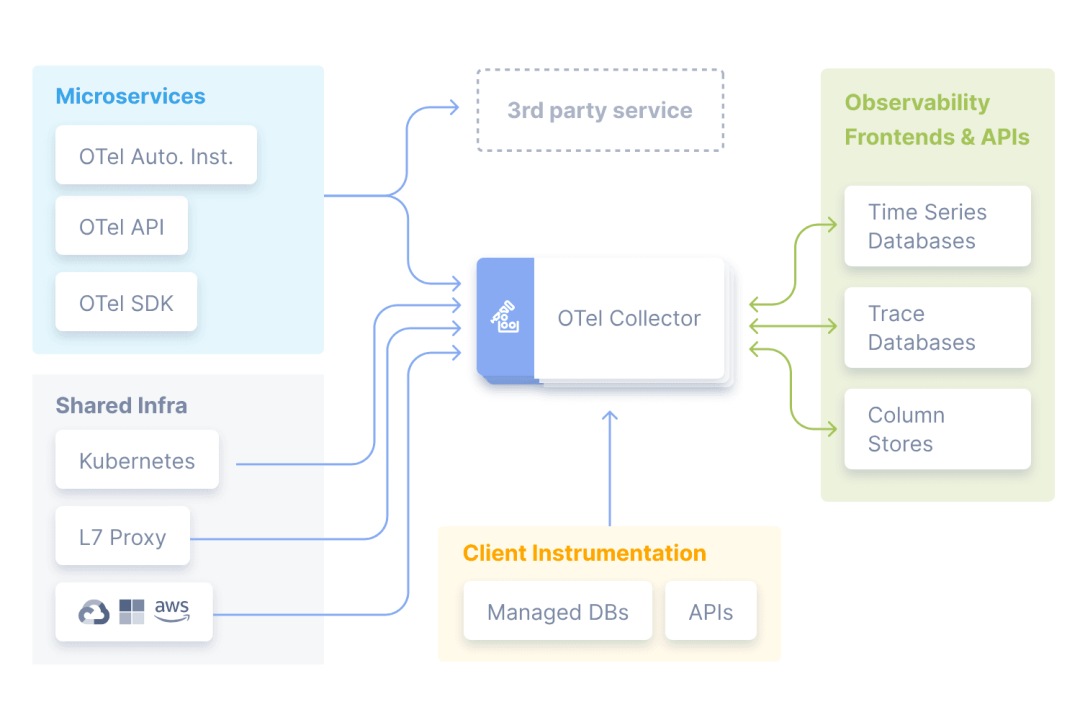
存储
存储层是可观测性堆栈的引擎,需要能够实时摄取和暴露不断增长的数据量的系统。作为OLAP列存储,ClickHouse适用于几乎任何规模的数据量,并具有使其特别适用于可观测性数据的特性。
“实时”的速度
ClickHouse的操作在毫秒级别,利用所有可用的系统资源,充分发挥它们的潜力,以尽可能快的速度处理每个分析查询。这也适配于各种摄取速度,在这里每秒达到数百万行,也并不罕见。这得益于磁盘上数据的列存储结构和对实现最快的OLAP数据库需求的底层实现(例如矢量化查询引擎)的投入。
压缩
在列中,对类似的数据进行分组不仅有益于分析查询,还允许最大化同质列文件的压缩比,从而受益于排序的局部性效应。相比之下,基于NoSQL索引的存储的一个主要挑战是:数据在磁盘上空间的膨胀。
ClickHouse附带了能够在摄取和查询时,即时处理数据的压缩算法。这对于可观测性数据尤其重要,因为预计到会存在相当多的冗余。例如,在最近的一项研究中,我们发现ClickHouse管理的日志数据达到了14倍的压缩比,仍然使我们能够在最小的硬件占用下实现出色的性能。
无底(Bottomless)存储
ClickHouse可以部署在无共享体系结构上(每个节点管理自己的存储和计算)。这对许多用例都适用,但缺点是:引入了一种刚性的可扩展性模型和一些脆弱性,因为磁盘往往昂贵且不可靠。
另一种数据存储的转变发生在“存储和计算分离”的概念中。与其使用磁盘,通过采用“共享存储”方法支持的ClickHouse节点,将其支持为对象存储而不是磁盘,则通常更有吸引力。ClickHouse Cloud更进一步,在“共享一切”体系结构中实现了存储和计算的完全分离。基于S3的架构还简化了数据管理:不需要提前调整集群/存储大小,甚至不需要分片数据。
但是,这会牺牲了一部分查询性能,以换取降低运营复杂性的好处(例如,如果将SSD NVMe与基于S3的系统进行比较)。然而,我们在Clickhouse Cloud规模上的测试表明,好处远远超过了劣势,这使其对具有不断增长的数据量的可观测性工作负载具有吸引力。
互操作性
目前支持99种数据格式、20多种内置集成引擎,以及数百种作为更广泛、充满活力的开源集成生态系统的第三方集成,互操作性不是事后思考的问题,而是ClickHouse的主要特征。这使其能够轻松集成到几乎任何现有堆栈中,并降低了复杂性和部署时间。这也意味着数据永远不会被锁定在平台上,可以轻松地通过不同的手段复制、移动或简单地在原地查询。
例如,您可以决定使用S3表函数,将大量遥测数据以Parquet格式存储在远程对象存储桶中,以实现归档目的,从而有效地扩展持久保留能力,例如遵守合规性,同时仍然能够远程查询数据。
无与伦比的表达能力
ClickHouse SQL支持1474多个聚合和分析函数,使实时数据探索变得简单而强大。像Materialized Views这样的功能,通常用于在插入时转换数据,支持常见任务,如从非结构化日志中提取结构,结合了分区、TTL管理、动态列选择、物化列等功能。由像dbt(Data Build Tool)这样的工具支持的服务器端数据转换,还使ClickHouse成为简化和组织数据转换工作流的强大数据存储。
此外,用于分位数、uniq、抽样、LTTB等的高效近似值查询是大范围数据上进行超快速查询的改变者。
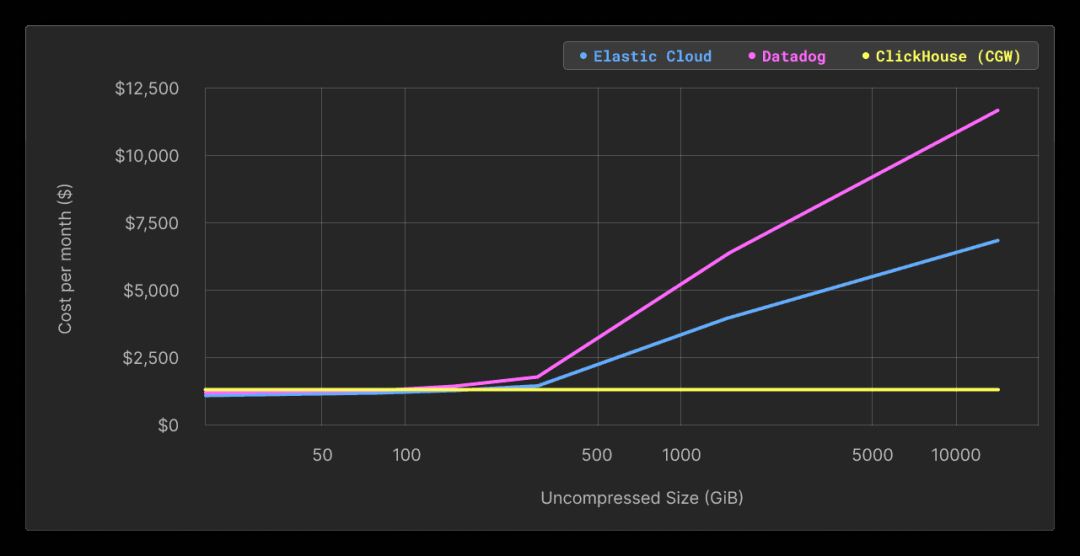
TCO(总体拥有成本)
上述因素的综合效应导致:基于ClickHouse的平台的总体TCO较低,同时释放了数据的全部潜力。最近,在一个最小的ClickHouse Cloud设置上进行了一项实验,结果表明您可以在每月仅300美元的费用获得高达14TB的日志的出色性能。随着添加的数据量越来越多,这种比较变得更加有趣,清楚地显示出成本和数据量在不同平台上以不同的速度增长。
可视化和更改
数据的呈现层可以采取各种形式。在这个领域,ClickHouse受益于一个充满活力的集成生态系统。
Grafana Labs作为一个可观测性可视化能力的领先提供商,我们与Grafana Labs密切合作,致力于clickhouse-datasource,以确保用户体验流畅并充分利用所有相关的ClickHouse功能。Grafana还提供了内置的告警功能,和一个广泛的连接器目录,以在同一仪表板中组合各种数据源。
我们的一些用户还发现:在日志记录方面,利用了Metabase等替代开源可视化和BI工具也取得了成功,而其他用户则构建了自定义工具。这表明开放的生态系统可以促使创新应用蓬勃发展。
在像ClickHouse这样的SQL数据库中,公开可观测性数据的另一个重要方面是,几乎任何支持SQL的客户端都可以通过支持的接口(Native、HTTP、ODBC、JDBC、MySQL)与其交互。从SQL客户端到数据可视化和BI工具以及语言客户端。这扩展了在现有IT环境中实施自定义替代方案的可能性。
最后,即使学习SQL的曲线通常很短,但面向代码生成的生成AI的民主化使得:从自然语言输入中生成SQL查询会变得比以往更加容易,而不是编写查询。这使得SQL学习曲线相关的论点变得不太重要。ClickHouse Cloud的用户已经可以将查询编写为自然语言问题,并让控制台根据可用表的上下文将这些问题转换为SQL查询。这种方法也用于自动修复用户查询。
基于SQL的可观测性管道
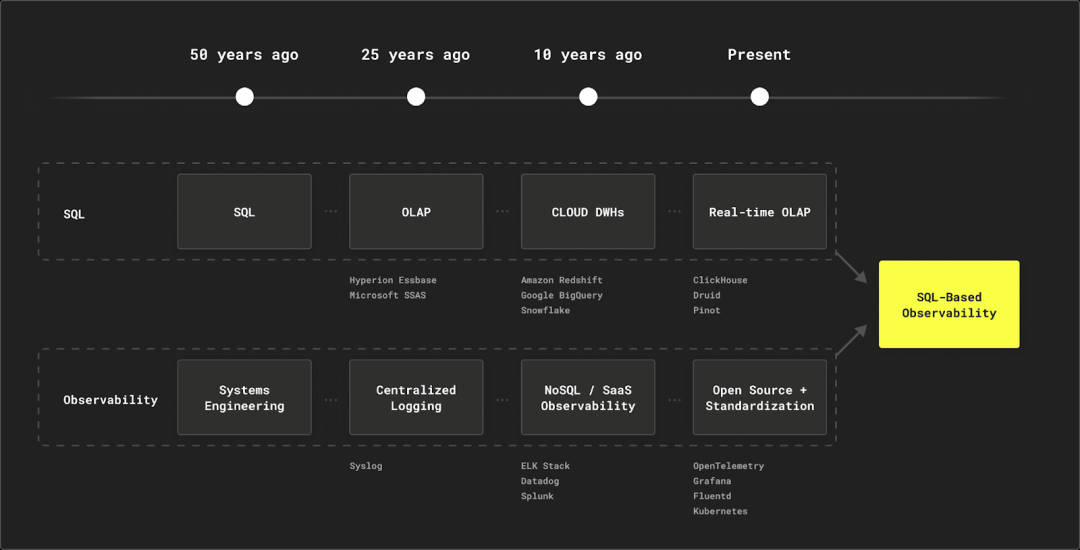
我们之前讨论的SQL和可观测性平行时间线表明,在技术方面,从起源到全球应用,再到全民化的道路可以采取各种形式。
我们认为,目前,高效实时OLAP存储的可访问性,加上开源可观测性标准的成熟性,使得可以将经过验证,和经过时间测试的SQL原则,应用于可观测性用例。此外,将可观测性视为另一种数据用例导致了它的普及化,并加速了其全球应用。
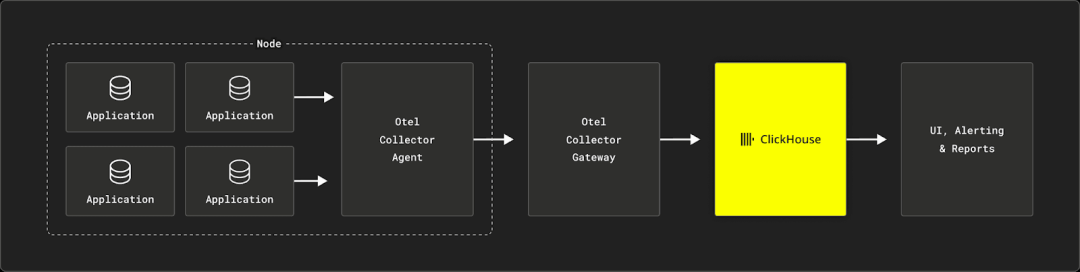
由此产生的基于SQL的可观测性堆栈既简单,而又没有偏见,为用户提供了在现有IT环境中:可定制化、调整和集成的多种选择。例如,一些体系结构将利用消息队列(如Apache Kafka)来帮助收集和缓冲数据,然后将其导入ClickHouse(我们在最近的WarpStream示例中展示了这样的体系结构)。其他示例可能部署多个可视化工具,以提供自助可视化功能,而不仅仅是经典的仪表板。
我们最近估算了LogHouse与一家领先的商业SaaS可观测性提供商的成本节约比,结果是300倍的节省
我们在ClickHouse中部署了上述堆栈,作为ClickHouse Cloud代码代号为“LogHouse”的集中式日志平台。这是一个利用OpenTelemetry Kubernetes集成进行收集,利用ClickHouse Cloud进行存储,并利用Grafana进行仪表板和日志探索的多区域ClickHouse Cloud部署。它目前管理着超过10PB的遥测数据,压缩到Clickhouse中仅为600TB(x16的压缩比!),并成功地为管理的所有服务的日志需求提供服务。我们最近估算了LogHouse与一家领先的商业SaaS可观测性提供商的成本节约比,结果是300倍的节省。
同样,许多运行大规模用例的用户已经成功地实施了基于SQL的可观测性管道。示例包括:
-
在eBay,使用ClickHouse在Kubernetes上进行监控的OLAP(https://innovation.ebayinc.com/tech/engineering/ou-online-analytical-processing/)
-
在Cloudflare,使用ClickHouse对每秒600万请求进行HTTP分析(https://blog.cloudflare.com/http-analytics-for-6m-requests-per-second-using-clickhouse/?utm_source=linkedin&utm_medium=social&utm_campaign=blog)
-
在Zomato,使用Clickhouse构建的成本效益日志平台,规模达到PB级(https://blog.zomato.com/building-a-cost-effective-logging-platform-using-clickhouse-for-petabyte-scale)
-
在Uber快速可靠的无模式日志分析平台(https://www.uber.com/en-ES/blog/logging/)
-
在Gitlab的可观测性使用了ClickHouse(https://handbook.gitlab.com/handbook/engineering/development/ops/monitor/observability/#clickhouse-datastore)
-
Helicone的LLM监控(https://clickhouse.com/blog/helicones-migration-from-postgres-to-clickhouse-for-advanced-llm-monitoring)
-
在Resmo,使用ClickHouse进行OpenTelemetry 追踪(https://clickhouse.com/blog/how-we-used-clickhouse-to-store-opentelemetry-traces)
ClickHouse还被用作一些最受欢迎的可观测性SaaS提供商的后端,包括:
-
Signoz.io(https://clickhouse.com/blog/signoz-observability-solution-with-clickhouse-and-open-telemetry)
-
Highlight.io(https://clickhouse.com/blog/overview-of-highlightio)
-
Qryn(https://qryn.metrico.in/#/)
-
BetterStack(https://betterstack.com/)
好了,现在有什么注意事项?
尽管在前一节详细列出了优势,但着手进行基于SQL的可观测性之旅的用户,还必须注意到当前的这些限制,以做出明智的决定(截至2023年12月)。
传统上,可观测性分为三个支柱:日志、指标和追踪。根据我们自己和客户大规模运行ClickHouse进行可观测性的经验,我们认为:在当前生态系统成熟度的水平下,日志和追踪是最容易解决的两个支柱。我们在两篇先前的帖子中详细记录了这些用例:logs和traces。
另一方面,指标用例目前由Prometheus主导,它是一个具有维度的数据模型和查询语言的工具。虽然我们看到了有许多使用ClickHouse成功进行指标管理的用例,但我们认为,为了实现PromQL支持,一个一揽子的指标体验将受益于ClickHouse的用户。因此,我们已决定在这个领域进行投入。
最后,考虑到应用的问题,考虑到基于SQL的可观测性的用户,还需要考虑到内部团队/用户的技能和偏好。即使SQL是数据操作的通用语言,可以在AI的帮助下轻松生成,可观测性用户可能来自不同的背景(SRE、分析师、DevOps或管理员),并且根据您的希望为,为他们创建的体验类型(即自助服务与预先准备的仪表板和警报之间的区别),SQL的学习曲线可能有或没有,都还必须进行评估。
基于SQL的可观测性是否适用于我的场景?
以下总结了一个列表,如果您想考虑将基于SQL的可观测性用于您的用例,这是您需要了解的内容(我保证这不是通过ChatGPT总结出来的):
下面是可能适用的假设情况:
-
您或您的团队熟悉SQL(或想要学习它)。
-
您更喜欢遵循诸如OpenTelemetry之类的开放标准,以避免锁定并实现可扩展性。
-
您愿意运行一个从收集到存储和可视化都由开源创新推动的生态系统。
-
您预计将承载中等或大量的可观测性数据(甚至是非常大量)。
-
您希望控制TCO(总体拥有成本)并避免不断增长的可观测性成本。
-
您不能或不想受制于管理成本,而被困在较短的可观测性数据保留期内。
下面是可能不适用的假设情况:
-
学习(或生成!)SQL对您或您的团队没有吸引力。
-
您正在寻找一种打包的、端到端的可观测性体验。
-
您的可观测性数据量太小,以至于不会体现出任何显着差异(例如,<150 GiB)并且没有可预测到的增长。
-
您的用例以指标为重,需要PromQL。在这种情况下,您仍然可以使用ClickHouse来处理日志和跟踪,而将Prometheus用于指标,在Grafana的呈现层将其统一起来。
-
您更喜欢等待生态系统更加成熟和基于SQL的可观测性更加成熟。
总结和展望
通过这篇文章,我们尽力提出了对基于SQL的可观测性的现状,以及诚实评估结果。这是基于我们对这个用例的了解,我们每天在实地看到的趋势,以及我们运行可观测性管道的经验。我们希望这些元素能帮助您自行做出决策,并对采用基于SQL的可观测性是否适合于您,而做出明智的决定。
此外,这代表了撰写时(2023年12月)该领域的状态。这个领域正在以很高的速度不断前进和扩展,挑战着我们上面所讨论的一些核心需求。例如,在日志探索和搜索中,ClickHouse最近对倒排索引的支持则更为相关。语言支持也在迅速发展,最近添加了Kusto查询语言(KQL)到ClickHouse,这是一种以管道为导向的查询语言,特别适用于遥测数据的分析,并且在安全分析社区中很受欢迎。最后,正如上面所讨论的,应用于代码生成的生成式AI的飞跃,它使得通过使用纯英语(或您喜欢的语言)与可观测性数据进行交互变得越来越容易了。
希望这些增强功能,以及开源堆栈的成熟性将汇聚在一起,加速可观测性的普及化,都将有助于在组织中更广泛地采用,并使几乎每个人都受益于更可靠的终端解决方案。

??联系我们
手机号:13910395701
邮箱:Tracy.Wang@clickhouse.com
满足您所有的在线分析列式数据库管理需求
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Linux awk命令全解析,实战指南带你轻松处理文本数据!
- SecureCRT & SecureFX 9.5 for macOS, Linux, Windows 下载 - 跨平台的多协议终端仿真和文件传输
- 存储底层SPDK与io_uring IO机制对比
- OpenCV中的格式转换
- 无心剑七绝《忆彭德怀》
- CleanMyMac X 4 for Mac(Mac优化清理工具)v4.14.6中文破解版
- 电动汽车转子油冷电机
- Nodejs 第二十五章(http)
- VCG 基于CMake构建VCG项目
- Postgresql源码(119)PL/pgSQL中ExprContext的生命周期