shell编程-6
发布时间:2024年01月22日
shell学习第6天
继续学习awk
systime()是awk内部得到当前时间的函数
strftime()是awk日期格式化输出的函数,按照指定的格式输出日期
编写一个脚本,发现新增了或者删除了用户,需要知道,还有修改了密码也要知道,密码为空的用户也要知道、如果有上面的行为就记录到日志里/var/log/user_pwd.log
#!/bin/bash
#定义日志文件
log_file="/var/log/user_pwd.log"
#备份 /etc/passwd 和 /etc/shadow
mkdir -p /backup_user
cd /backup_user
#手动去备份
#cp /etc/passwd passwd-$(date +%F)
#cp /etc/shadow shadow-$(date +%F)
#计算备份文件的md5sum
passwd_md5=$(md5sum /backup_user/passwd-$(date +%F) | awk '{print $1}')
shadow_md5=$(md5sum /backup_user/shadow-$(date +%F) | awk '{print $1}')
#计算最近的 /etc/passwd /etc/shadow 的md5值
c_passwd_md5=$(md5sum /etc/passwd | awk '{print $1}')
c_shadow_md5=$(md5sum /etc/shadow | awk '{print $1}')
#判断 passwd 文件的 md5 值是否有变化
if [[ $passwd_md5 != $c_passwd_md5 ]]; then
echo "用户信息被修改"
#使用 diff 去比较发现是增加或者减少了哪些用户
if diff -q /etc/passwd /backup_user/passwd-$(date +%F) > /dev/null; then
echo "用户信息没有详细变化"
else
diff /etc/passwd /backup_user/passwd-$(date +%F) | egrep "^<"|awk -F: '{print "用户新增了:"$1}' | tr -d "< " >>$log_file
i_name=$(diff /etc/passwd /backup_user/passwd-$(date +%F) | egrep "^<"|awk -F: '{print "用户新增了:"$1}' | tr -d "< ")
if [ $? -eq 0 ]; then
echo "用户新增了:$i_name"
fi
diff /etc/passwd /backup_user/passwd-$(date +%F) | egrep "^>"|awk -F: '{print "用户删除了:"$1}' | tr -d "> " >>$log_file
d_name=$(diff /etc/passwd /backup_user/passwd-$(date +%F) | egrep "^>"|awk -F: '{print "用户删除了:"$1}' | tr -d "> ")
if [ $? -eq 0 ]; then
echo "用户删除了:$d_name"
fi
fi
else
echo "用户信息没有被修改"
fi
#判断 shadow 文件的 md5 值是否有变化
if [[ $shadow_md5 != $c_shadow_md5 ]]; then
echo "用户密码文件被修改"
#使用 diff 去比较发现是 shadow 文件里的哪些行发生变化了
if diff -q /etc/shadow /backup_user/shadow-$(date +%F) > /dev/null; then
echo "用户密码文件没有详细变化"
else
diff /etc/shadow /backup_user/shadow-$(date +%F) | egrep "^<"|awk -F: '{print "用户新增了:"$1}' | tr -d "< " >>$log_file
i_name=$(diff /etc/shadow /backup_user/shadow-$(date +%F) | egrep "^<"|awk -F: '{print "用户新增了:"$1}' | tr -d "< ")
if [ $? -eq 0 ]; then
echo "用户新增了:$i_name"
fi
diff /etc/shadow /backup_user/shadow-$(date +%F) | egrep "^>"|awk -F: '{print "用户删除了:"$1}' | tr -d "> " >>$log_file
d_name=$(diff /etc/shadow /backup_user/shadow-$(date +%F) | egrep "^>"|awk -F: '{print "用户删除了:"$1}' | tr -d "> ")
if [ $? -eq 0 ]; then
echo "用户删除了:$d_name"
fi
fi
else
.
echo "用户密码文件没有修改"
fi
#判断没有设置密码或者密码为空的用户,记录到日志文件里
awk -F: 'length($2) == 1 || length($2) == 2 {print $1,"没有设置密码",strftime("%D",systime())}' /etc/shadow >>$log_file
awk -F: 'length($2) == 0 {print $1,"密码为空",strftime("%D",systime())}' /etc/shadow >>$log_file
if多分支

awk -F: 'length($2) == 1 || length($2) == 2 {print $1,"没有设置密码",strftime("%D",systime())}' /etc/shadow >>$log_file
awk -F: 'length($2) == 0 {print $1,"密码为空",strftime("%D",systime())}' /etc/shadow >>$log_file
'这两条可以整合起来:'
awk -F: '{if (length($2) == 1 || length($2) == 2) print $1,"没有设置密码",strftime("%D",systime())else if (length($2) ==0 ) print $1,"密码为空",strftime("%D",systime())}' /etc/shadow >>$log_file
小题目
在centos7的配置文件/etc/vimrc中有if v:lang s~ "utf8$'
这里的v:lang和=~分别是什么意思?
"utf8$"中的"$"的作用?
在
/etc/vimrc配置文件中的语句:if v:lang =~ "utf8$"这里的
v:lang是 Vim 中的一个特殊变量,表示当前的语言。而=~是 Vim 中的正则表达式匹配运算符。解释一下:
v:lang: 表示当前的语言。=~: 是 Vim 中的正则表达式匹配运算符,用于判断左侧的字符串是否匹配右侧的正则表达式。"utf8$": 是一个正则表达式,其中"utf8"表示匹配包含 “utf8” 的字符串,而$表示匹配字符串结尾。因此,整个正则表达式"utf8$"表示匹配以 “utf8” 结尾的字符串。因此,整个条件语句的意思是:如果当前语言是以 “utf8” 结尾的,那么就执行条件块中的内容。这可能用于在不同的语言环境下设置相关的 Vim 配置。
利用awk的system命令

[root@gh-shell 1-21] awk -F: '{system("mkdir -p /gao/hui/sc/"$1)}' /etc/passwd
0 directories, 0 files
[root@gh-shell 1-21] tree /gao
/gao
└── hui
└── sc
├── adm
├── bin
├── chrony
├── daemon
├── dbus
├── ftp
├── games
├── gaodingjiang
├── gaodingjiang1
├── gaodingjiang12
├── gaodingjiang123
├── gaofei12
├── gaofei123
├── gh123
├── halt
├── liu
├── liu1
├── liu2
├── liu3
├── lp
├── mail
├── nobody
├── operator
├── polkitd
├── postfix
├── root
├── root1
├── root2
├── sc1
├── sc10
├── sc11
├── sc12
├── sc13
├── sc14
├── sc15
├── sc16
├── sc17
├── sc18
├── sc19
├── sc20
├── sc5
├── sc6
├── sc7
├── sc8
├── sc9
├── shutdown
├── sshd
├── sync
├── systemd-network
└── tss
52 directories, 0 files
[root@gh-shell 1-21]#
求和

'简单的求和'
[root@gh-shell 1-21] cat grade.txt |awk 'NR>1{sum += $4}END{print sum}'
355
[root@gh-shell 1-21] cat grade.txt
name chinese math english
cali 80 91 82
tom 90 80 99
lucy 99 70 75
jack 60 89 99
[root@gh-shell 1-21]#
awk数组
array 数组 :一组数据

[root@gh-shell 1-21] cat a.txt
山东 aa 20
河南 bb 30
江西 cc 30
湖南 aa 40
山东 bb 10
江西 dd 60
河南 cc 30
湖南 cc 30
[root@gh-shell 1-21] cat a.txt|awk '{a[$1] += $3}END{for (i in a) print i,a[i]}'|sort -k 2 -n
山东 30
河南 60
湖南 70
江西 90
[root@gh-shell 1-21]#
这个数组很像python中的字典
key和value
[root@gh-shell 1-21] ./scdict.py
name gaohui
age 18
hobby read_book
skills Linux python
[root@gh-shell 1-21]# cat scdict.py
#!/usr/bin/python3
#定义一个字典
stu_info = {"name":"gaohui","age":18,"hobby":"read_book","skills":"Linux python"}
#打印所有的key和value
for key, value in stu_info.items():
print(key, value)
[root@gh-shell 1-21]#
小练习

[root@gh-shell 1-21] cat top_up.txt|awk 'NR>1{top_name[$1]+=$2}END{for (i in top_name) print i,top_name[i]}'|sort -k 2 -nr
fei 1329
gao 650
jiang 450
[root@gh-shell 1-21]#
[root@gh-shell 1-21] cat top_up.txt
username money
gao 100
gao 200
gao 350
fei 200
fei 239
fei 890
jiang 100
jiang 350
[root@gh-shell 1-21]#
练习2
已知一台服务器 nestat –an 输出,用IP简单的正则匹配上面出现的所有的IP
[root@gh-shell 1-21] netstat -antplu|egrep -o "([0-9]{1,3}\.){3}[0-9]{1,3}"|sort|uniq
0.0.0.0
127.0.0.1
192.168.153.1
192.168.153.165
[root@gh-shell 1-21] netstat -antplu|egrep "([0-9]{1,3}\.){3}[0-9]{1,3}"
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1109/sshd
tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN 1333/master
tcp 0 0 192.168.153.165:22 192.168.153.1:49935 ESTABLISHED 2133/sshd: root@pts
tcp 0 36 192.168.153.165:22 192.168.153.1:49930 ESTABLISHED 2109/sshd: root@pts
udp 0 0 127.0.0.1:323 0.0.0.0:* 745/chronyd
[root@gh-shell 1-21]#
split切割函数
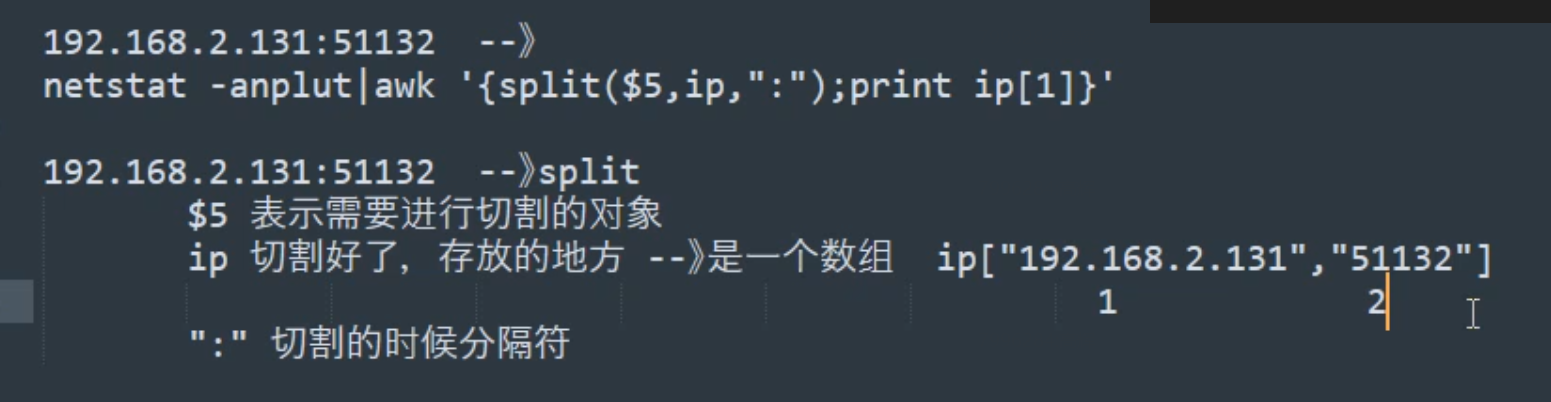

[root@gh-shell 1-21] netstat -antplu|awk 'NR>2 && /tcp/{s[$6] += 1}END{for (i in s) print i,s[i]}'
LISTEN 4
ESTABLISHED 2
[root@gh-shell 1-21]#
substr函数—>切片
从一段字符串里截取
[root@gh-shell 1-21] echo "fengdeyong|sanchaung|changsha"|awk -F"|" '{print substr($1,1,6)}'
fengde
[root@gh-shell 1-21]#
[root@gh-shell 1-21] echo "fengdeyong|sanchaung|changsha"|awk -F"|" '{print substr($1,5,10)}'
deyong
[root@gh-shell 1-21]#
substr($1,1,6)
1表示从第一个字符开始
6表示取6个字符
难题
以下是nginx日志的字段含义
$time_iso8601|$host|$http_cf_connecting_ip|$request|$status|$body_bytes_sent|$http_referer|$http_user_agent
-------------------------------------
2019-04-25T09:51:58+08:00|a.google.com|47.52.197.27|GET /v2/depth?symbol=aaa HTTP/1.1|200|24|-|apple
2019-04-25T09:52:58+08:00|b.google.com|47.75.159.123|GET /v2/depth?symbol=bbb HTTP/1.1|200|407|-|python-requests/2.20.0
2019-04-25T09:53:58+08:00|c.google.com|13.125.219.4|GET /v2/ticker?timestamp=1556157118&symbol=ccc HTTP/1.1|200|162|-|chrome
2019-04-25T09:54:58+08:00|d.shuzibi.co|-||HEAD /justfor.txt HTTP/1.0|200|0|-|-
2019-04-25T09:55:58+08:00|e.google.com|13.251.98.2|GET /v2/order_detail?apiKey=ddd HTTP/1.1|200|231|-|python-requests/2.18.4
2019-04-25T09:56:58+08:00|f.google.com|210.3.168.106|GET /v2/trade_detail?apiKey=eee HTTP/1.1|200|24|-|-
2019-04-25T09:57:58+08:00|g.google.com|47.75.115.217|GET /v2/depth?symbol=fff HTTP/1.1|200|397|-|python-requests/2.18.4
2019-04-25T09:58:58+08:00|h.google.com|47.75.58.56|GET /v2/depth?symbol=ggg HTTP/1.1|200|404|-|safari
2019-04-25T09:59:58+08:00|i.google.com|188.40.137.175|GET /v2/trade_detail?symbol=hhh HTTP/1.1|200|6644|-|-
2019-04-25T10:01:58+08:00|j.google.com|2600:3c01:0:0:f03c:91ff:fe60:49b8|GET /v2/myposition?apiKey=jjj HTTP/1.1|200|110|-|scan
1、 计算每分钟的带宽(body_bytes_sent)
[root@gh-shell 1-21] cat nginx.txt|awk -F"|" 'NR>1 {split($1,time,":|");print time[1]":"time[2],$(NF-2)}'
2019-04-25T09:51 24
2019-04-25T09:52 407
2019-04-25T09:53 162
2019-04-25T09:54 0
2019-04-25T09:55 231
2019-04-25T09:56 24
2019-04-25T09:57 397
2019-04-25T09:58 404
2019-04-25T09:59 6644
2019-04-25T10:01 110
[root@gh-shell 1-21]#
2、 统计每个URI(即不带问号?后面的内容)的每分钟的频率
[root@gh-shell 1-21] cat nginx.txt|awk -F"[|?]" 'NR>1{t[substr($1,1,16)$4]+=1}END{for (i in t) print i,t[i]}'|sort -k3 -nr
2019-04-25T10:01GET /v2/myposition 1
2019-04-25T09:59GET /v2/trade_detail 1
2019-04-25T09:58GET /v2/depth 1
2019-04-25T09:57GET /v2/depth 1
2019-04-25T09:56GET /v2/trade_detail 1
2019-04-25T09:55GET /v2/order_detail 1
2019-04-25T09:53GET /v2/ticker 1
2019-04-25T09:52GET /v2/depth 1
2019-04-25T09:51GET /v2/depth 1
2019-04-25T09:54 1
[root@gh-shell 1-21] cat nginx.txt |awk -F"[|?]" 'NR>1{t[substr($1,1,16)$4]+=1}END{for (i in t) print i,t[i]}'|sort -k3 -nr
2019-04-25T10:01GET /v2/myposition 1
2019-04-25T09:59GET /v2/trade_detail 1
2019-04-25T09:58GET /v2/depth 1
2019-04-25T09:57GET /v2/depth 1
2019-04-25T09:56GET /v2/trade_detail 1
2019-04-25T09:55GET /v2/order_detail 1
2019-04-25T09:53GET /v2/ticker 1
2019-04-25T09:52GET /v2/depth 1
2019-04-25T09:51GET /v2/depth 1
2019-04-25T09:54 1
[root@gh-shell 1-21]#
文章来源:https://blog.csdn.net/investor_/article/details/135744669
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- PHP+MySQL+Ajax实现注册功能
- WEB 3D技术 three.js 顶点交换
- 基于CNN的水果识别-含数据集训练模型
- 时序预测 | Matlab实现EEMD-SSA-BiLSTM、EEMD-BiLSTM、SSA-BiLSTM、BiLSTM时序预测对比
- jvm_下篇_补充_MAT从入门到精通
- RFID厂区产线智能管理系统
- 如何进行产品的人机交互设计?
- 腾讯云Elasticsearch Service产品体验
- Postman使用总结--参数化
- 美国电油加热器的UL认证安全标准UL574介绍