【C语言】大小端字节序详解
前言
提示:这里可以添加本文要记录的大概内容:
前言:
计算机系统中的字节序是一个关键概念,影响着数据在内存中的存储方式。其中,C语言的大小端字节序是一个备受关注的话题。了解字节序对于编写可移植性强、跨平台的程序至关重要。在这篇博客中,我们将深入探讨C语言中大小端字节序的概念、影响以及如何处理不同字节序带来的挑战。
提示:以下是本篇文章正文内容,下面案例可供参考
引入大小端字节序
先来看一个程序
#include <stdio.h>
int main()
{
int a = 0x11223344;
return 0;
}
当我们调试这段程序,观察变量a的内存中所存储的内容时,可以发现
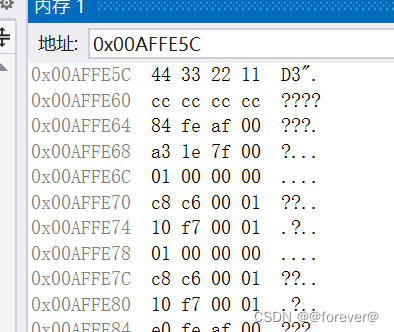
a变量在内存中存储的顺序是44332211,那么原因是什么呢?由此,大小端字节序便产生了!
大小端字节序的定义
在计算机科学中,大小端字节序是指在多字节数据类型存储时,最低有效字节(Least Significant Byte,简称LSB)和最高有效字节(Most Significant Byte,简称MSB)的存放顺序。这影响了数据在内存中的存储方式。
-
大端字节序(Big-Endian): 数据的高位字节存储在低地址内存单元,低位字节存储在高地址内存单元。即,MSB 存在于最低的地址位置。
-
小端字节序(Little-Endian): 数据的低位字节存储在低地址内存单元,高位字节存储在高地址内存单元。即,LSB 存在于最低的地址位置。
考虑一个4字节整数 0x12345678,在大端字节序中存储为 12 34 56 78,而在小端字节序中存储为 78 56 34 12。
这种字节序的差异对于底层数据表示和网络通信至关重要,因此在编程和系统级别的开发中,理解和正确处理大小端字节序是不可或缺的技能。
为什么会出现大小端之分
计算机体系结构的设计中,大小端字节序的差异源于对多字节数据存储方式的不同选择。这种分歧主要受到以下两个因素的影响:
-
硬件设计:
-
Big-Endian: 一些体系结构,如 Motorola 68000 和 IBM System/360,选择将最重要的字节存储在最低的内存地址中。这样的设计在处理大端字节序时,可以更方便地从内存中读取高位字节。
-
Little-Endian: 另一些体系结构,如 Intel x86 架构,选择将最不重要的字节存储在最低的内存地址中。这样的设计在处理小端字节序时,同样可以更方便地从内存中读取低位字节。
-
-
数据存储的方式:
-
Big-Endian: 大端字节序在人类读写的方式上更自然,因为我们习惯从左到右,从高位到低位阅读数字。然而,这种方式可能导致内存中的数据在传输时需要进行字节交换,增加了一些处理的复杂性。
-
Little-Endian: 小端字节序在存储时将最低有效字节放在最低地址,这使得直接从内存中读取多字节数据更加高效,因为可以直接使用内存中的字节流。
-
总结:
大小端字节序的分歧是由底层硬件体系结构的设计选择引起的。虽然这种差异在不同体系结构之间存在,但它对于计算机系统的整体性能和数据交换都具有深远的影响。因此,在编程和系统级开发中,理解并正确处理大小端字节序是至关重要的。
示例:设计一个小程序来判断当前机器的字节序
#include <stdio.h>
int check_sys(int a)
{
return *(char*)&a;
}
int main()
{
int a = 1;
if (check_sys(a)==1)
{
printf("小端\n");
}
else
{
printf("大端\n");
}
return 0;
}
运行结果
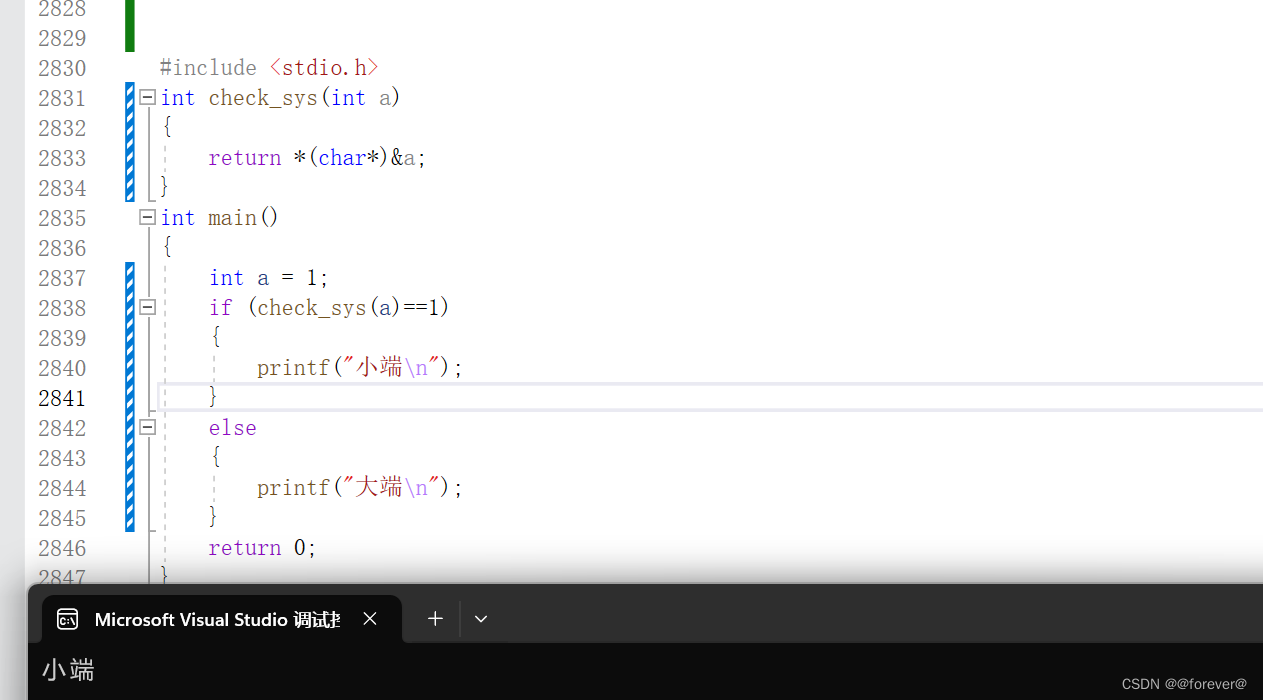
从结果可以看出,该机器是小端存储
改进写法(利用联合体成员共用同一块内存空间的特点)
#include <stdio.h>
union U
{
int a;
char c;
};
int main()
{
union U u = {1};
if (u.c==1)
{
printf("小端\n");
}
else
{
printf("大端\n");
}
return 0;
}
运行结果
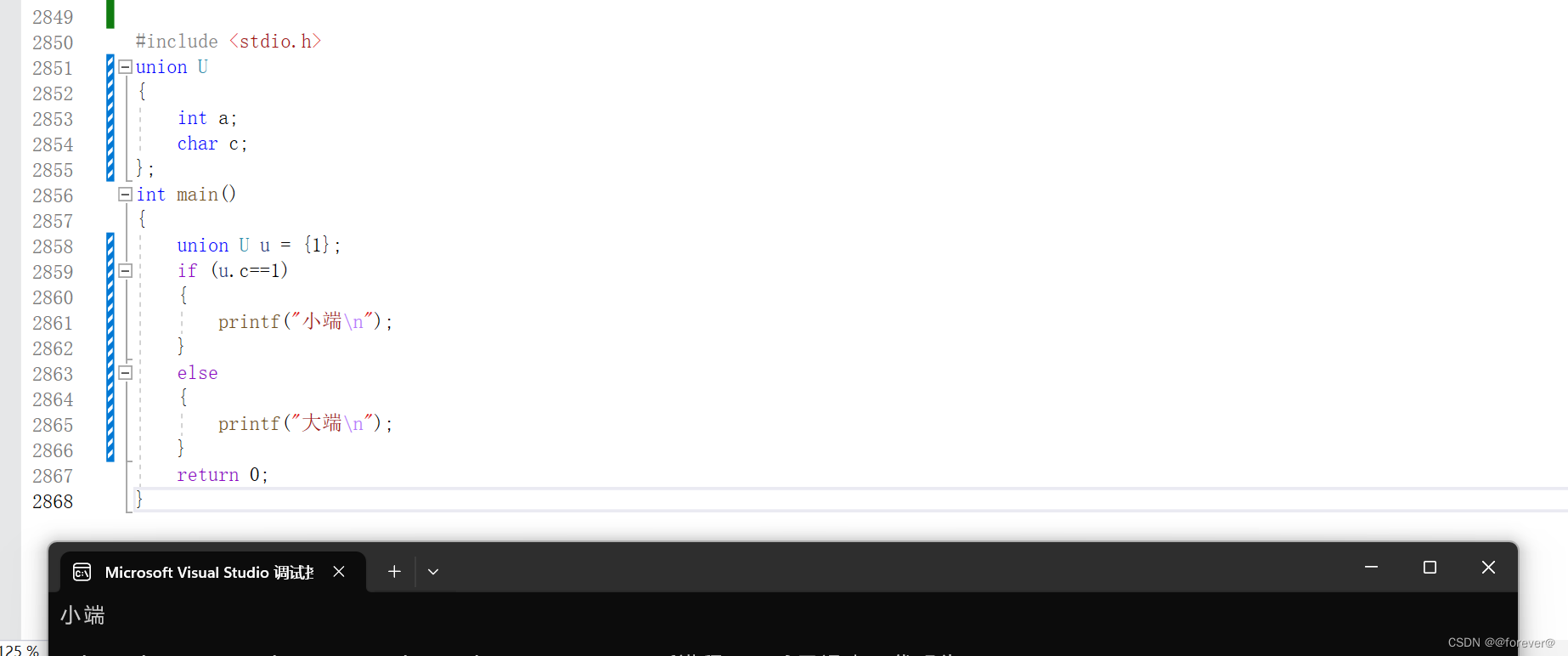
从结果可以看出当前机器是小端存储
总结
通过本文的介绍,我们深入了解了C语言中的大小端字节序。无论是在网络通信、文件存储还是跨平台开发中,理解字节序的差异都是至关重要的。在编写程序时,采用适当的字节序处理机制,可以确保程序在不同平台上的稳定运行。字节序的理解不仅是程序员的基本技能,更是编写高质量、可维护代码的重要一环。希望通过本文的分享,读者对C语言中的字节序问题有了更清晰的认识。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 无线路由器DHCP导致网络故障一例
- 探索Vue.js的Composition API:构建更清晰、可维护的组件
- 有了 Prisma,就别用 TypeORM 了
- 02.部署LVS-DR群集
- 设计模式除盲
- L1-071 前世档案(Java)
- WEB前端IDE的使用以及CSS的应用
- 群晖启动SSH功能【无法执行此操作,可能是因为网络连接不稳定或系统正忙】的解决方案
- eNSP实现默认路由、静态路由、浮动路由、等价路由、单臂路由
- 结合教学经验谈计量经济学与Stata软件的学习