生产经验——分区的分配以及再平衡
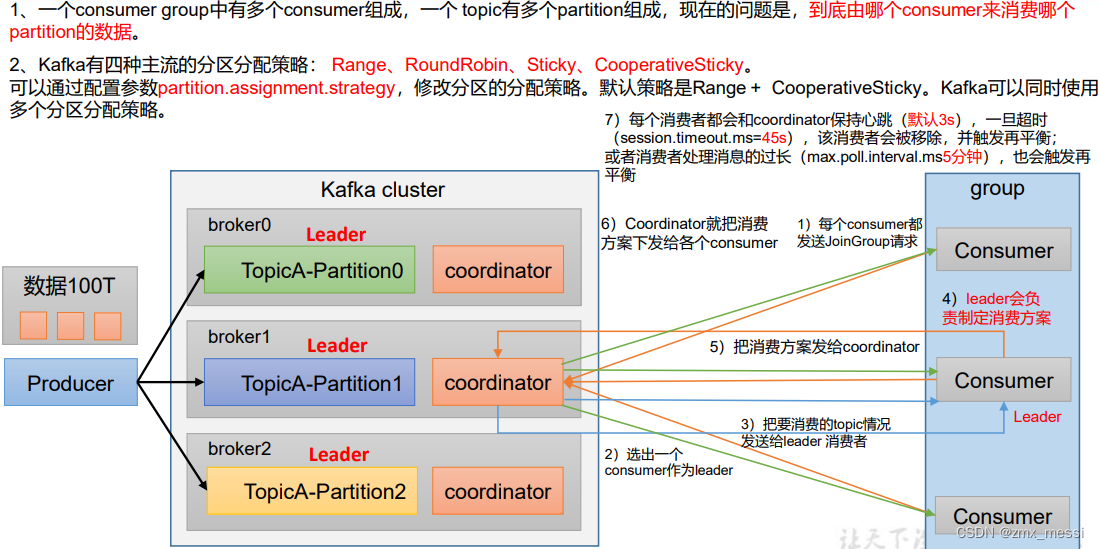
Range 以及再平衡

实操:
(1)修改主题 first 为 7 个分区。
bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --alter --topic first --partitions 7
?????????复制 CustomConsumer 类,创建 CustomConsumer2。这样可以由三个消费者 CustomConsumer、CustomConsumer1、CustomConsumer2 组成消费者组,组名都为“test”, 同时启动 3 个消费者,他们都在一个组别中。
启动 CustomProducer 生产者,发送 500 条消息,随机发送到不同的分区:
消费者1:消费 0,1,2分区的数据:
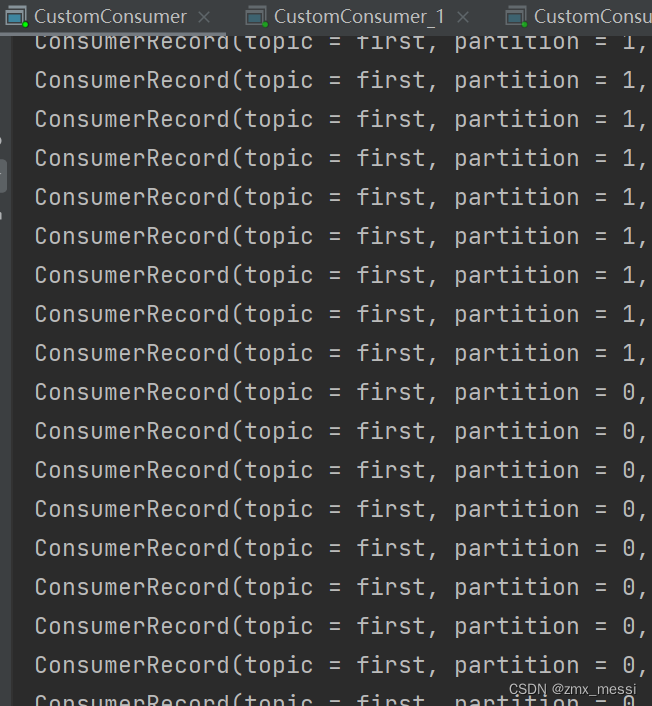
消费者2:消费3,4分区的数据:
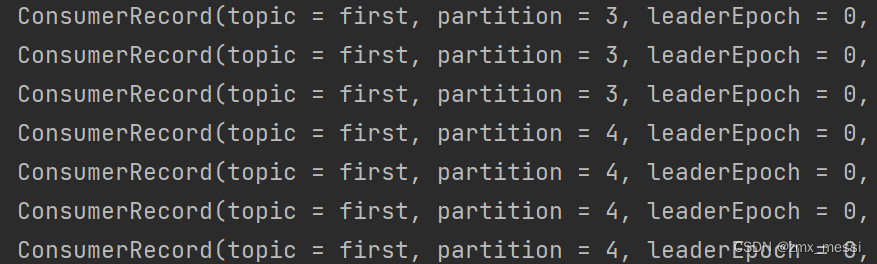
消费者3:消费5,6分区的数据:

? ? ? ? 此时做一个破坏性实验,把消费者1干掉,我们发现,前45s,?消费者2和消费者3正常接收数据,而45s后,认为消费者1退出消费者组,因此消费者1的数据会给整体给别人接受。
? ? ? ? 如果此时再发送一波数据,那么消费者2消费0,1,2,3分区的数据,消费者3消费4,5,6分区的数据。
RoundRobin 以及再平衡
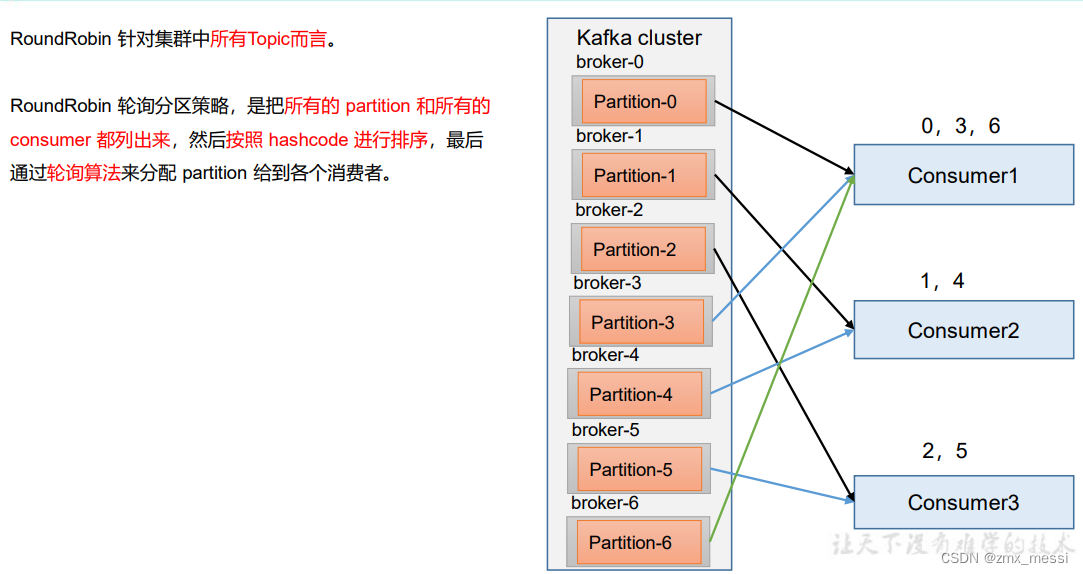
????????依次在 CustomConsumer、CustomConsumer1、CustomConsumer2 三个消费者代 码中修改分区分配策略为 RoundRobin。
//设置分区分配策略
properties.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG,"org.apache.kafka.clients.consumer.RoundRobinAssignor");消费者2:消费 1,4分区的数据:?
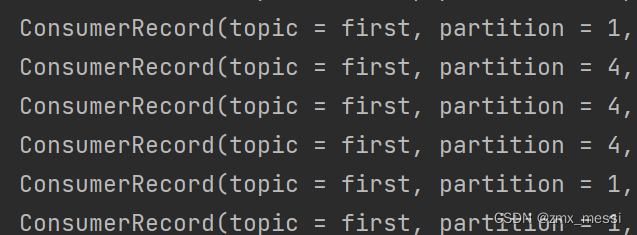
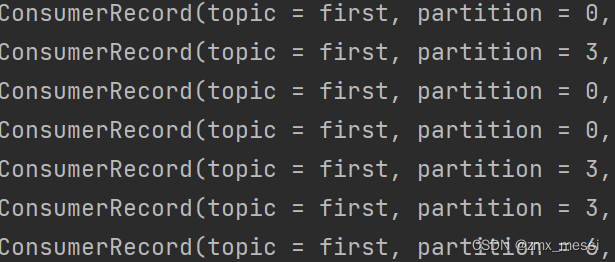
?消费者0:消费0,3,6分区的数据:
?消费者1:消费2,5分区的数据: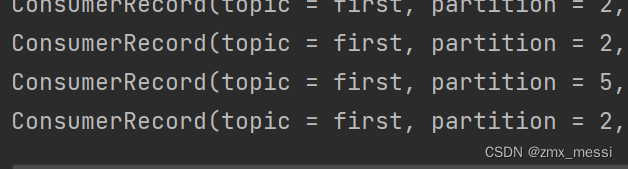
????????此时做一个破坏性实验:将消费者0干掉,0 号消费者的任务会按照 RoundRobin 的方式,把数据轮询分成 0 、6 和 3 号分区数据, 分别由 1 号消费者或者 2 号消费者消费。
????????说明:0 号消费者挂掉后,消费者组需要按照超时时间 45s 来判断它是否退出,所以需要等待,时间到了 45s 后,判断它真的退出就会把任务分配给其他 broker 执行。发现1处理:2,5,3发现2处理:1,4,0,6
????????(2)再次重新发送消息观看结果(45s 以后)。 1 号消费者:消费到 0、2、4、6 号分区数据 2 号消费者:消费到 1、3、5 号分区数据 说明:消费者 0 已经被踢出消费者组,所以重新按照 RoundRobin 方式分配。
Sticky 以及再平衡
????????可以理解为分配的结果带有“粘性的”。即在执行一次新的分配之前, 考虑上一次分配的结果,尽量少的调整分配的变动,可以节省大量的开销。
// 修改分区分配策略
properties.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG,
"org.apache.kafka.clients.consumer.StickyAssignor");
?三个消费者正常工作时,可以看到会尽量保持分区的个数近似划分分区。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 一个个人博客应该怎么学?
- 计算机毕业设计 基于SpringBoot的高校宣讲会管理系统的设计与实现 Java实战项目 附源码+文档+视频讲解
- ROS-安装xacro
- day07_方法_数组
- 【信息安全原理】——入侵检测与网络欺骗(学习笔记)
- 考研英语高频打卡
- Centos安装Docker及使用
- 互联网上门洗衣洗鞋小程序功能模块介绍;
- 开发日记(数据库类型、数据库时间戳、java exception)
- [亲测有效]CentOS7下安装mysql5.7