RDD 缓存 和 Checkpoint
RDD 缓存 和 Checkpoint
RDD 缓存
-
RDD 缓存的意义
-
使用缓存的原因 - 多次使用 RDD
-
案例
-
数据集
access_log_sample.rar(深入了解 RDD数据集文件【同一份数据】)
-
需求:统计访问次数最多的IP,统计访问次数最少的IP
-
code
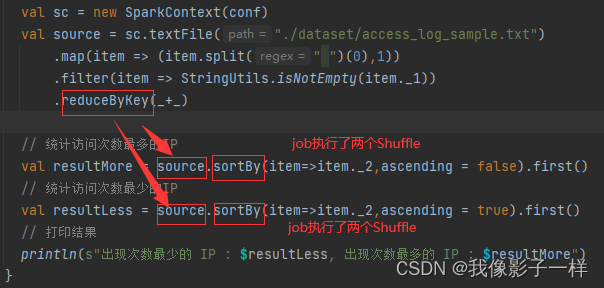
@Test def prepare(): Unit = { val conf = new SparkConf().setMaster("local[2]").setAppName("cache_prepare") val sc = new SparkContext(conf) val source = sc.textFile("./dataset/access_log_sample.txt") .map(item => (item.split(" ")(0),1)) .filter(item => StringUtils.isNotEmpty(item._1)) .reduceByKey(_+_) // 统计访问次数最多的IP val resultMore = source.sortBy(item=>item._2,ascending = false).first() // 统计访问次数最少的IP val resultLess = source.sortBy(item=>item._2,ascending = true).first() // 打印结果 println(s"出现次数最少的 IP : $resultLess, 出现次数最多的 IP : $resultMore") }
 转换算子的作用:生成RDD,以及RDD之问的依赖关系
转换算子的作用:生成RDD,以及RDD之问的依赖关系
Action算子的作用:生成Job,去执行Job
全局执行了四个shufflereduceByKey 是一个 Shuffle操作,Shuffle操作会在集群内进行数据拷贝 问题1:在上述代码中, 多次使用到了 source, 导致文件读取两次, 计算两次, 有没有什么办法增进上述代码的性能? (缓存) -
-
-
RDD 缓存的API
-
使用缓存的原因 - 容错

当在计算 RDD3 的时候如果出错了, 会怎么进行容错?
会再次计算 RDD1 和 RDD2 的整个链条, 假设 RDD1 和 RDD2 是通过比较昂贵的操作得来的, 有没有什么办法减少这种开销?
-
上述两个问题的解决方案其实都是 缓存, 除此之外, 使用缓存的理由还有很多, 但是总结一句, 就是缓存能够帮助开发者在进行一些昂贵操作后, 将其结果保存下来, 以便下次使用无需再次执行, 缓存能够显著的提升性能.
-
所以, 缓存适合在一个 RDD 需要重复多次利用, 并且还不是特别大的情况下使用, 例如迭代计算等场景.
-
code
@Test def cache(): Unit = { // 1. 创建 SC val conf = new SparkConf().setAppName("cache_prepare").setMaster("local[6]") val sc = new SparkContext(conf) // 2. 读取文件 val source = sc.textFile("dataset/access_log_sample.txt") // 3. 取出IP, 赋予初始频率 val countRDD = source.map( item => (item.split(" ")(0), 1) ) // 4. 数据清洗 val cleanRDD = countRDD.filter( item => StringUtils.isNotEmpty(item._1) ) // 5. 统计IP出现的次数(聚合) var aggRDD = cleanRDD.reduceByKey( (curr, agg) => curr + agg ) aggRDD=aggRDD.cache() //cache方法其实是persist方法的一个别名, //aggRDD=aggRDD.persist() // 也可以使用persist方法进行缓存 //action 操作之前进行缓存 !!! // 6. 统计出现次数最少的IP(得出结论) val lessIp = aggRDD.sortBy(item => item._2, ascending = true).first() // 7. 统计出现次数最多的IP(得出结论) val moreIp = aggRDD.sortBy(item => item._2, ascending = false).first() println((lessIp, moreIp)) }@Test def persist(): Unit = { // 1. 创建 SC val conf = new SparkConf().setAppName("cache_prepare").setMaster("local[6]") val sc = new SparkContext(conf) // 2. 读取文件 val source = sc.textFile("dataset/access_log_sample.txt") // 3. 取出IP, 赋予初始频率 val countRDD = source.map( item => (item.split(" ")(0), 1) ) // 4. 数据清洗 val cleanRDD = countRDD.filter( item => StringUtils.isNotEmpty(item._1) ) // 5. 统计IP出现的次数(聚合) var aggRDD = cleanRDD.reduceByKey( (curr, agg) => curr + agg ) aggRDD=aggRDD.persist(StorageLevel.MEMORY_ONLY) // MEMORY_ONLY是存储级别 //action之前进行缓存 // 6. 统计出现次数最少的IP(得出结论) val lessIp = aggRDD.sortBy(item => item._2, ascending = true).first() // 7. 统计出现次数最多的IP(得出结论) val moreIp = aggRDD.sortBy(item => item._2, ascending = false).first() println((lessIp, moreIp)) } -
注意:
persist方法其实有两种形式,persist()是persist(newLevel:StorageLevel)的个别名,persist(newLevel: StorageLevel)能够指定缓存的级别
-
-
缓存级别
其实如何缓存是一个技术活, 有很多细节需要思考, 如下
- 是否使用磁盘缓存?
- 是否使用内存缓存?
- 是否使用堆外内存?
- 缓存前是否先序列化?
- 是否需要有副本?
如果要回答这些信息的话, 可以先查看一下 RDD 的缓存级别对象
-
code
@Test def cacheOp(): Unit = { val conf = new SparkConf().setMaster("local[6]").setAppName("debug_string") val sc = new SparkContext(conf) val sourceRDD = sc.textFile("./dataset/access_log_sample.txt") .map(item => (item.split(" ")(0), 1)) .filter(item => StringUtils.isNotBlank(item._1)) .reduceByKey((curr, agg) => curr + agg) .persist() println(sourceRDD.getStorageLevel) sc.stop() }打印出来的对象是
StorageLevel, 其中有如下几个构造参数
根据这几个参数的不同,
StorageLevel有如下几个枚举对象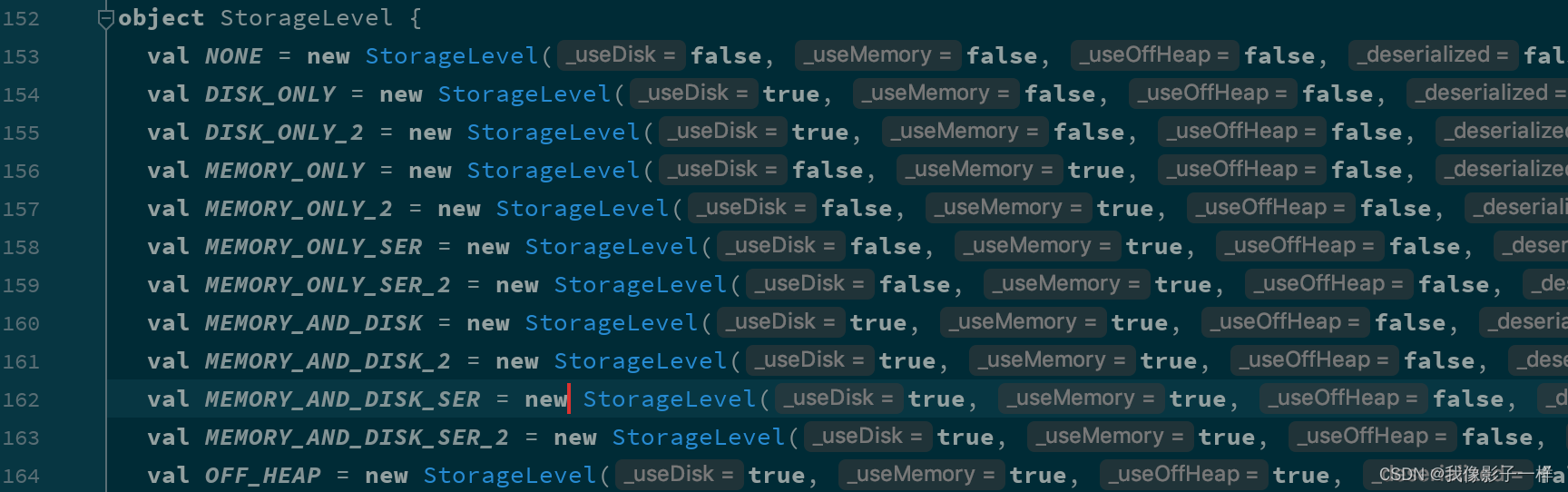
缓存级别 userDisk 是否使用磁盘 useMemory 是否使用内存 useOffHeap 是否使用堆外内存 deserialized 是否以反序列化形式存储 replication 副本数 NONE false false false false 1 DISK_ONLY true false false false 1 DISK_ONLY_2 true false false false 2 MEMORY_ONLY false true false true 1 MEMORY_ONLY_2 false true false true 2 MEMORY_ONLY_SER false true false false 1 MEMORY_ONLY_SER_2 false true false false 2 MEMORY_AND_DISK true true false true 1 MEMORY_AND_DISK true true false true 2 MEMORY_AND_DISK_SER true true false false 1 MEMORY_AND_DISK_SER_2 true true false false 2 OFF_HEAP true true true false 1 deserialized是否以反序列化形式存储:- 是否以反序列化形式存储,如果是,存的是对象, 如果不是, 则存储序列化过的值
- 如果true, 说明存放的是对象, 如果是false, 存放的就是二进制数据

-
如何选择分区级别:
Spark 的存储级别的选择,核心问题是在 memory 内存使用率和 CPU 效率之间进行权衡。建议按下面的过程进行存储级别的选择:
- 如果您的 RDD 适合于默认存储级别(MEMORY_ONLY),leave them that way。这是 CPU 效率最高的选项,允许 RDD 上的操作尽可能快地运行.
- 如果不是,试着使用 MEMORY_ONLY_SER 和 selecting a fast serialization library 以使 对象更加节省空间,但仍然能够快速访问。(Java和Scala)
- 不要溢出到磁盘,除非计算您的数据集的函数是昂贵的,或者它们过滤大量的数据。否则,重新计算分区可能与从磁盘读取分区一样快.
- 如果需要快速故障恢复,请使用复制的存储级别(例如,如果使用 Spark 来服务 来自网络应用程序的请求)。All 存储级别通过重新计算丢失的数据来提供完整的容错能力,但复制的数据可让您继续在 RDD 上运行任务,而无需等待重新计算一个丢失的分区.
Checkpoint
-
Checkpoint 的作用
- Checkpoint 的主要作用是斩断 RDD 的依赖链, 并且将数据存储在可靠的存储引擎中, 例如支持分布式存储和副本机制的 HDFS.
- Checkpoint 的方式
- 可靠的 将数据存储在可靠的存储引擎中, 例如 HDFS
- 本地的 将数据存储在本地

-
什么是斩断依赖链
斩断依赖链是一个非常重要的操作, 接下来以 HDFS 的 NameNode 的原理来举例说明
- HDFS 的 NameNode 中主要职责就是维护两个文件, 一个叫做
edits, 另外一个叫做fsimage.edits中主要存放EditLog,FsImage保存了当前系统中所有目录和文件的信息. 这个FsImage其实就是一个Checkpoint - HDFS 的 NameNode 维护这两个文件的主要过程是, 首先, 会由
fsimage文件记录当前系统某个时间点的完整数据, 自此之后的数据并不是时刻写入fsimage, 而是将操作记录存储在edits文件中. 其次, 在一定的触发条件下,edits会将自身合并进入fsimage. 最后生成新的fsimage文件,edits重置, 从新记录这次fsimage以后的操作日志. - 如果不合并
edits进入fsimage会怎样? 会导致edits中记录的日志过长, 容易出错. - 所以当 Spark 的一个 Job 执行流程过长的时候, 也需要这样的一个斩断依赖链的过程, 使得接下来的计算轻装上阵
- HDFS 的 NameNode 中主要职责就是维护两个文件, 一个叫做
-
Checkpoint 和 Cache 的区别
Cache 可以把 RDD 计算出来然后放在内存中, 但是 RDD 的依赖链(相当于 NameNode 中的 Edits 日志)是不能丢掉的, 因为这种缓存是不可靠的, 如果出现了一些错误(例如 Executor 宕机), 这个 RDD 的容错就只能通过回溯依赖链, 重放计算出来.
但是 Checkpoint 把结果保存在 HDFS 这类存储中, 就是可靠的了, 所以可以斩断依赖, 如果出错了, 则通过复制 HDFS 中的文件来实现容错.
所以他们的区别主要在以下两点
- Checkpoint 可以保存数据到 HDFS 这类可靠的存储上, Persist 和 Cache 只能保存在本地的磁盘和内存中
- Checkpoint 可以斩断 RDD 的依赖链, 而 Persist 和 Cache 不行
- 因为 Checkpoint RDD 没有向上的依赖链, 所以程序结束后依然存在, 不会被删除. 而 Cache 和 Persist 会在程序结束后立刻被清除.
-
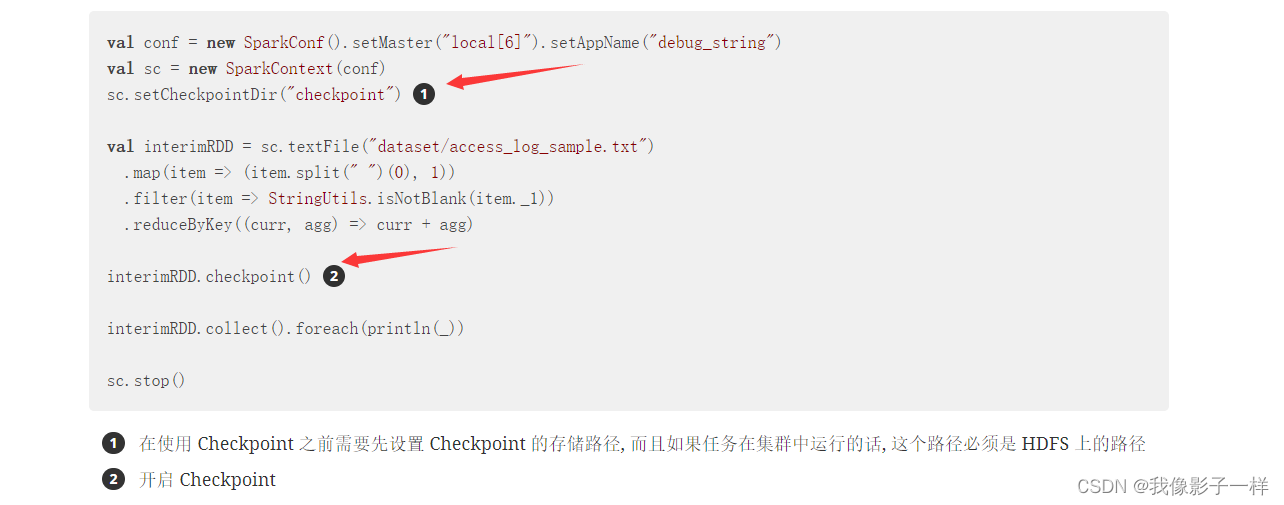
使用 Checkpoint
-
code
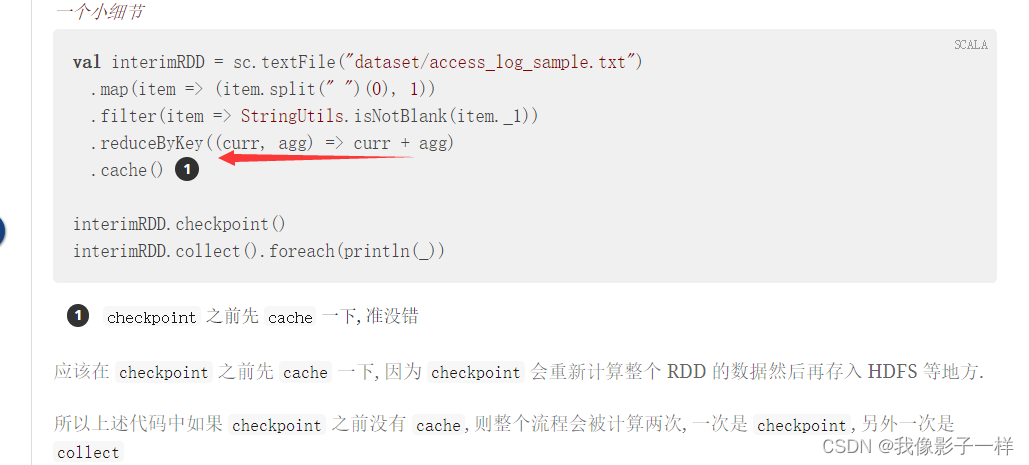
@Test def checkpoint(): Unit = { val conf = new SparkConf().setMaster("local[6]").setAppName("debug_string") val sc = new SparkContext(conf) // 设置保存 checkpoint 的目录, 也可以设置为 HDFS 上的目录 sc.setCheckpointDir("checkpoint") val source = sc.textFile("./dataset/access_log_sample.txt") val countRDD = source.map(item => (item.split("")(0), 1)) val cleanRDD = countRDD.filter(item => StringUtils.isNotEmpty(item._1)) var aggRDD = cleanRDD.reduceByKey((curr, agg) => curr + agg) // 不准确的说,Checkpoint 是一个Action操作,也就是说 // 如果调用 checkpoint ,则会重新计算一下RDD, 然后把结果存在HDFS或者本地目录中 //所以,应该在 Checkpoint 之前,进行一次 Cache aggRDD = aggRDD.cache() aggRDD.checkpoint() val lessIp = aggRDD.sortBy(item => item._2, ascending = true).first() val moreIp = aggRDD.sortBy(item => item._2, ascending = false).first() println(lessIp, moreIp) sc.stop() }
-
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 配置Nginx出现403 (Forbidden)静态文件加载不出来
- 苹果内购记录
- ES索引原理
- Ubuntu 18.04使用Qemu和GDB搭建运行内核的环境
- Hamcrest断言:自动化测试的利器
- jvm实战之-常用jvm命令的使用
- 【数据结构】线性表的知识点全面总结
- ReactNative 常见问题及处理办法(加固混淆)
- javascript读取RFID卡号源码
- 《BackTrader量化交易图解》第8章:plot 绘制金融图