[2023]Java后台开发工程师笔试题
这次试卷考察的都是偏基础的,而且没有编码题,很喜欢这家公司考察的方式,没有刻意求难,而是重基础,希望能达到这家公司的面试环节!如果能拿到offer那就大大的好!记录的主要是我不太会的
目录
单选题
线程的相关说法
如果线程的 run 方法执行结束或抛出一个不能捕获的例外,线程便进入死亡状态。
suspend() 和 resume() 两个方法配套使用,suspend()使得线程进入阻塞状态,并且不会自动恢复,必须其对应的 resume() 被调用,才能使得线程重新进入可执行状态。
考察了sql的程序语言
SQL程序语言有四种类型,对数据库的基本操作都属于这四类,它们分别为;数据定义语言(DDL)、数据查询语言(DQL)、数据操纵语言(DML)、数据控制语言(DCL)
我觉得这个知识点挺少的,就是要熟练掌握
- DDL(Data Definition Language):由
CREATE、ALTER、DROP和TRUNCATE四个语法组成- DML(Data Manipulation Language):由
insert、update、delete语法组成- DQL(Data Query Language):由
select组成- DCL(Data Control Language):授权
grant、取消授权revoke等等操作
考察了redis的持久化
可以看我这篇文章
关于容器类的说法,错误的是?
A java8的hashmap默认在桶节点数为8转换为红黑树
B hashtable线程安全,容许使用空值对
选b,hashtable确实是线程安全的,但是它不允许使用空值对,hashmap线程不安全,允许使用空值对
下列关于索引的描述不正确的是()
A 可通过索引快速查找数据,减少查询执行时间
B 数据库索引采用B+树是因为B+树在提高了磁盘IO性能的同时解决了元素遍历效率低下的问题
C 如果WHERE子句中使用了索引,那么ORDER BY子句中不会使用索引
D 索引提高了查询速度,也会提高更新表的速度
在这里只解释cd,c这种说法不完全,要得是where中使用的索引也是order by排列所需要的,如果不是那么order by就需要使用索引
d的话则是正确的,因为即使是更新也要先找到数据后再进行更新,而索引确实提高了这一速度
考察了java8内存划分
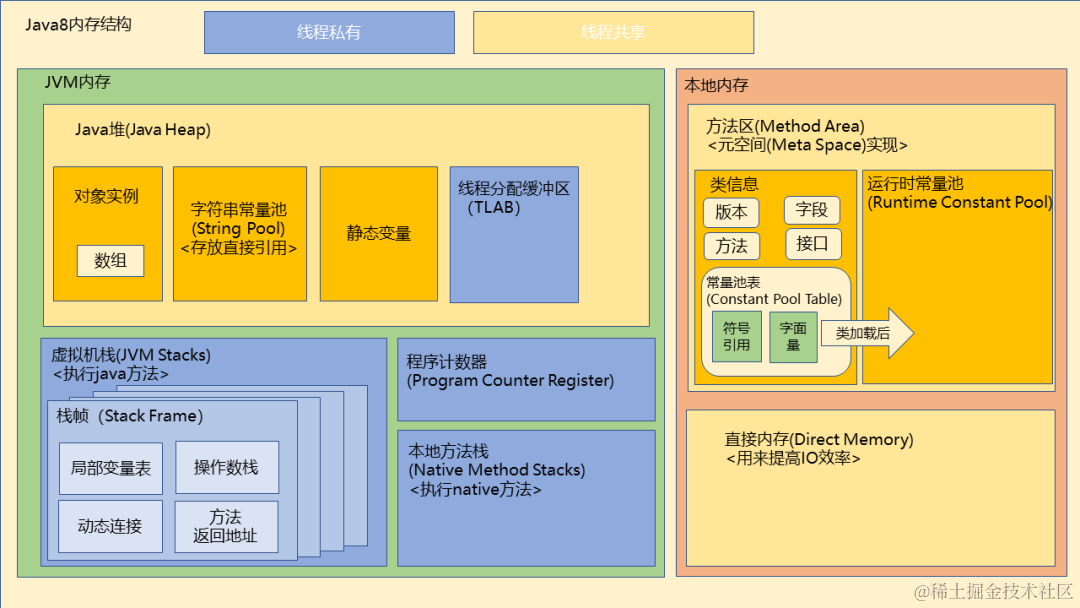
考察了反射
A 因为反射是在运行时而不是在编译时,所以不会利用到编译优化,同时因为是动态生成,因此,反射操作的效率要比那些非反射操作低得多
B 任何继承AccessibleObject的类的对象都可以使用该方法取消Java语言访问权限设置
C 每个class(代表普通类)类,无论创建多少个实例对象,在JVM中都对应同一个Class对象
D 通过Field可以访问给定对象的类变量,包括获取变量的类型,修饰符,注解,变量名,变量的值或者重新设置变量值,即使变量是private的
交给chatgpt回答
下列关于mybatis框架说法,正确的是?
A 如果使用在order by中就需要使用$
B ${}:仅仅为一个纯粹的String替换,在动态SQL解析阶段将会进行变量替换
C mybaits中的cdata标签指的是不应由XML解析器进行解析的文本数据,所以SQL语句中存在“<”,“&”一般都需要用CDATA标签包住
D 使用#可以很大程度上防止sql注入
交给chatgpt回答
下列关于spring说法,正确的是?
A Spring IOC主要是基于Java的反射机制去实现的
B 静态属性以及线程中的属性不能使用@Autowired直接注入
C AOP增强的方法A,被同一个类中的另一个方法B调用,如果外部调用B,A也会被增强
D @Transactional只能被应用到public方法上
交给chatgpt回答,但我选abd
下列哪些操作会使线程释放锁资源?
A sleep()
B join()
C yield()
D wait()
sleep():调用sleep会导致当前线程休眠。与wait方法不同之处,sleep方法不会释放当前占有的锁,会导致线程进入TIMED-WAITING状态;而wait方法会导致当前线程进入WAITING状态
yield():yield()暂停当前方法,释放自己拥有的CPU,线程进入就绪状态。它能让当前线程由“运行状态”进入到“就绪状态”,从而让其它具有相同优先级的等待线程获取执行权;但是,并不能保证在当前线程调用yield()之后,其它具有相同优先级的线程就一定能获得执行权;也有可能是当前线程又进入到“运行状态”继续运行!
join():加入线程(当前执行的线程是A线程,调用join()方法得是B线程)
wait():调用wait方法的线程会进入WAITING状态;只有等到其他线程之通知或被中断后才会返回。
下列关于IO的相关说法,正确的是?
A NIO和IO有相同的作用和目的,但实现方式不同,NIO主要用到的是块,所以NIO的效率要比IO高很多
B 如果你有少量的连接使用非常高的带宽,一次性发送大量的数据,用NIO服务器来处理比IO服务器来处理更有优势
C JAVA处理大文件,更快的方式是采用MappedByteBuffer
D NIO通讯是将整个任务切换成许多小任务,由一个线程负责处理所有IO事件,并负责分发
交给chatgpt回答
下列关于对象克隆说法,正确的是?
A 使用序列化能完成深克隆的功能
B Object的clone()方法是在java平台层实现的native方法,且被protected修饰
C 深克隆:即克隆基本类型变量,也克隆引用类型变量
D 深克隆的方法需要被public修饰
c是对的,chat
哪些情况会导致Mysql索引失效?
- 带有函数
- 带有运算
- 使用%XXX左模糊查询,因为mysql是最左原则
- 使用范围查询,not in,in,>,<
- 查询的字段不是索引的最左字段
- 字段类型不匹配
- or条件左右有一个不是索引字段
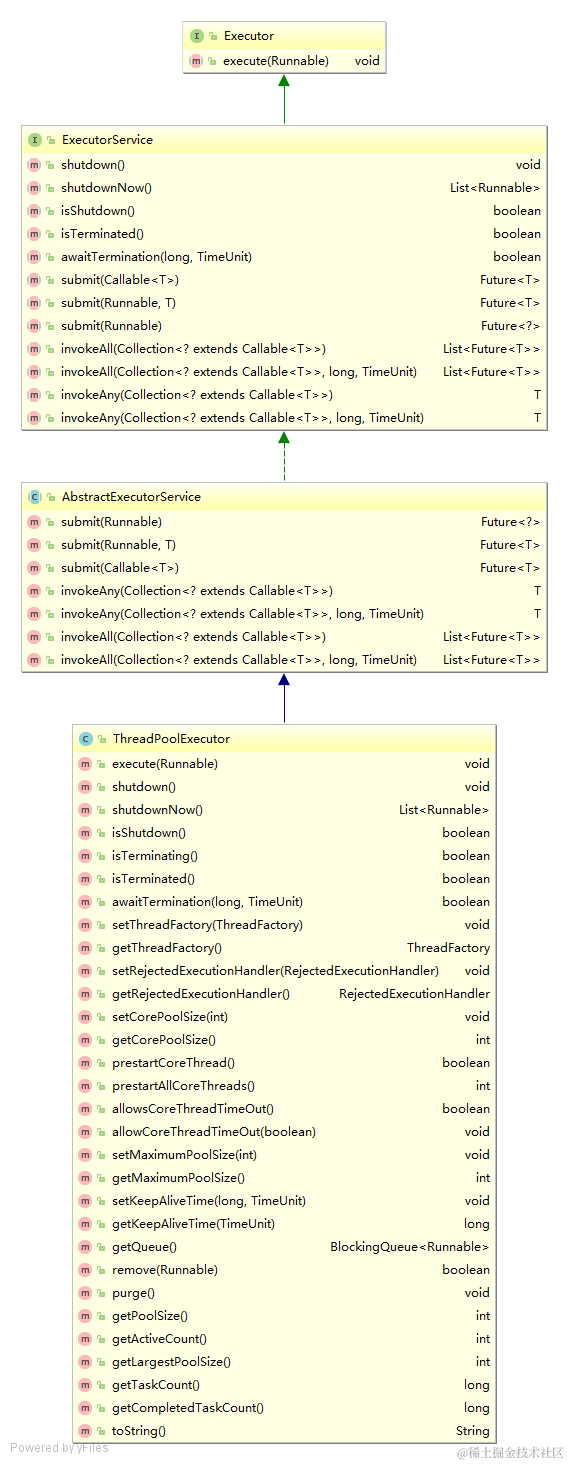
ThreadPoolExecutor有哪些常用的方法?
介绍几个方法shutdown()和shutdownNew(),前者是使当前未执行的线程继续执行,而不再添加新的任务task,方法不会阻塞。后者则是停止正在执行的,用一个list
<Runnable>队列来存储未运行的任务,并返回awaitTermination(long timeout, TimeUnit unit):查看在指定的时间内,池子是否已经终止工作,即最多等待多少时间后去判断池子已经终止工作。一般和shutdown()方法配合
setThreadFactory方法+UncaughtExceptionHandler处理异常:对线程池创建的线程进行属性定制化,当程序抛出异常时,可以自定义处理。
set/getRejectExecutionHandler():可以处理任务被拒绝执行时的行动
prestartCoreThread():每次调用一次就创建一个核心线程,返回的是boolean
prestartAllCoreThreads():启动全部核心线程,返回的是启动核心线程的数量
remove(Runnable):可以删除尚未被执行的Runnable任务
多个get方法:
- getActiveCount() : 取得多少个线程正在执行的任务
- getPoolSize() : 当前池中里面有多少个线程,包括正在执行任务的线程,也包括在休眠的线程
- getCompletedTaskCount() :取得已经执行完成的任务数
- getCorePoolSize() : 取的构造方法传入的corePoolSize参数值
- getMaximumPoolSize() : 取的构造方法中MaximumPoolSize的参数值
- getPoolSize() : 取的池中有多少个线程
- getTaskCount() : 取得有多少个任务发送给了线程池,运行的+ 排队的
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 大模型的算力网络技术原理和落地实践
- 中国电子学会2021年3 月份青少年软件编程Scratch图形化等级考试试卷一级真题(含答案见文章最下方)
- 租赁系统|租赁小程序开发|北京租赁系统提升行业发展
- 简述微信小程序原理
- Windows10安装Hadoop3.1.3环境
- 视频号下载保姆级攻略:五大神级下载方法揭秘!
- QT上位机开发(动态库dll的开发)
- 基于springboot+vue2的灾区物资管理系统(Java毕业设计)
- Python学习之路-单元测试
- Spring Security实现详解