编程领域新巨头:Phind-CodeLlama-34B-v2的技术优势揭秘
前言
在当前快速发展的人工智能领域,特别是在大型语言模型(LLM)的赛道上,新的竞争者Phind-CodeLlama-34B-v2已经引起了业界的广泛关注。作为一款专注于代码生成的模型,它不仅在标准基准测试HumanEval上取得了73.8%的pass@1成绩,还在多语言编程方面展现出了卓越的能力。
-
Huggingface模型下载:https://huggingface.co/Phind/Phind-CodeLlama-34B-v2
-
AI快站模型免费加速下载:https://aifasthub.com/models/Phind

Phind-CodeLlama-34B-v2核心优势
-
高效的Fine-Tuning
Phind-CodeLlama-34B-v2模型是在Phind-CodeLlama-34B-v1的基础上,通过对1.5亿个高质量编程相关的Token进行额外的Fine-Tuning而来。这不仅提升了模型的性能,还使其在开源模型中处于领先地位。
-
多语言编程能力
该模型精通Python、C/C++、TypeScript、Java等多种编程语言,使其成为多语言编程领域的强大工具。这一点对于全球范围内的开发者来说尤为重要,因为它能够满足不同编程环境下的需求。
-
指令调优和易用性
Phind-CodeLlama-34B-v2在Alpaca/Vicuna格式上进行了指令调优,使得模型更易于控制和使用。这对于开发者来说是一个巨大的优势,因为它可以根据特定的需求和场景灵活地调整模型的行为。

技术细节
-
数据集和训练过程
Phind-CodeLlama-34B-v2使用了一个包含1.5亿Token的高质量私有数据集进行Fine-Tuning。这个数据集由编程问题和解决方案组成,采用了指令-答案的格式,与常规的代码完成示例不同。
-
训练技术
在训练过程中,模型利用了DeepSpeed ZeRO 3和Flash Attention 2等先进技术,使得训练更加高效。在32个A100-80GB GPU上,仅用了15小时就完成了训练,显示了其在训练速度上的优势。
-
性能优化
为了进一步提升性能,Phind-CodeLlama-34B-v2运行在NVIDIA的H100 GPU上,并利用TensorRT-LLM库,实现了每秒处理100个Token的速度。
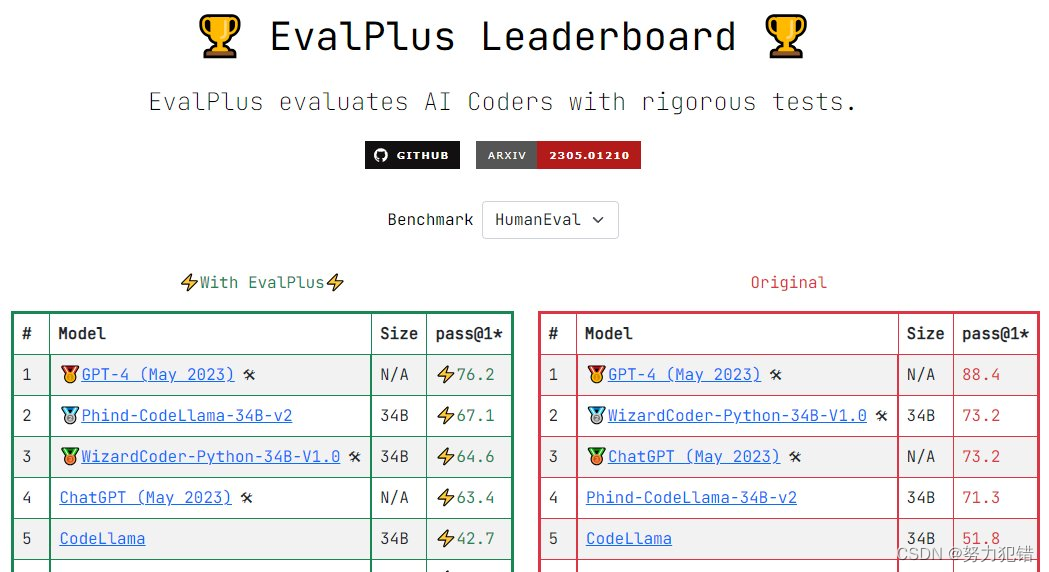
Phind与ChatGPT的比较
Phind-CodeLlama-34B-v2在多个方面与OpenAI的ChatGPT-4形成了竞争。虽然在某些方面ChatGPT-4仍然占有一定优势,但Phind在以下几个关键方面表现更为突出:
-
更大的上下文窗口,Phind拥有16,000个Token的大上下文窗口(12,000用于输入,4,000用于网页结果),相比之下,ChatGPT-4的上下文窗口为8,000个Token。
-
速度优势,在速度上,Phind的运行速度是GPT-4的五倍,与ChatGPT 3.5相当。
展望未来
考虑到机器学习模型的快速发展,我们有理由相信,Phind-CodeLlama-34B-v2在不久的将来,将会出现更多令人瞩目的突破。大型语言模型在编程能力方面的发展已经成为一个游戏规则改变者,对初学者和资深开发人员都提供了重要的帮助。
总的来说,Phind-CodeLlama-34B-v2作为编程领域的新巨头,其在代码生成、多语言处理和训练效率上的突出表现,无疑将推动整个AI编程领域的发展和创新。
模型下载
Huggingface模型下载
https://huggingface.co/Phind/Phind-CodeLlama-34B-v2
AI快站模型免费加速下载
https://aifasthub.com/models/Phind
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- C++ 中 static 应用
- react craco配置响应式postcss-px-to-viewport
- kafka中消息key作用与分区规则关系
- PPP算法
- 【Spring】10 BeanFactoryAware 接口
- 【编译原理】期末预习PPT后三章笔记+LL(1) II
- 【Pytorch】Pytorch或者CUDA版本不符合问题解决与分析
- vue3学习-生命周期函数
- POWERBUILDER如何解析xml
- cfa一级考生复习经验分享系列(十一)