机器学习基本概念及模型简单代码(自用)
监督学习
监督学习是机器学习的一种方法,其中我们教导模型如何做出预测或决策,通过使用包含输入和对应输出的已标注数据集进行训练。这种方法的关键特点是利用这些标注数据**(即带有正确答案的数据)**来指导模型的学习过程。
一言以蔽之,数据带有X和结果Y,(X->Y)
基本概念
- 训练数据:这些是用于训练模型的数据点,每个数据点都包括特征(输入变量)和标签(输出变量,即预测目标)。
- 模型:在监督学习中,模型是一个数学结构,它试图根据输入特征来预测标签。
- 学习算法:算法通过最小化预测和实际结果之间的差异(通常是通过损失函数)来调整模型的参数。
监督学习的类型
- 分类(Classification):输出变量是离散的标签。例如,判断电子邮件是否为垃圾邮件。
- 回归(Regression):输出变量是连续的值。例如,预测房屋价格。
过程
- 准备数据:收集并处理数据,确保每个数据点都有特征和相应的标签。
- 选择模型:基于问题的性质(如分类或回归)选择一个适当的模型。
- 训练模型:使用训练数据来训练模型。这通常涉及到调整模型的参数,以最小化预测误差。
- 评估模型:使用独立的测试数据集评估模型的性能。
- 参数调优:根据模型的性能,调整学习算法的参数。
- 部署模型:一旦模型被训练并验证,它就可以被用来对新的数据点做出预测。
优点
- 高准确性:在有足够质量的训练数据情况下,监督学习模型通常能达到高准确性。
- 易于理解和实现:监督学习的流程直接且易于实现。
缺点
- 需要大量标注数据:有效的监督学习需要大量的标注数据,而这些数据的收集和标注可能既费时又昂贵。
- 泛化问题:如果训练数据不能代表真实世界的数据分布,模型可能在实际应用中表现不佳。
总的来说,监督学习是一种强大的方法,适用于许多实际问题,尤其是在有充足且高质量的训练数据时。
非监督学习是机器学习的一种方法,它与监督学习不同,因为它不使用预先标注的数据。在非监督学习中,算法被提供了输入数据,但没有对应的输出标签。目标是探索数据的结构,找出隐藏的模式或数据的内在特性。
一言以蔽之,数据X,不带有结果Y
关键特点
- 无标签数据:非监督学习不依赖于标注的输出数据,而是直接从输入数据中学习。
- 探索性分析:它通常用于对数据进行探索性分析,发现数据中的模式和关系。
常见的非监督学习类型
- 聚类:将数据划分为几个组或“簇”,使得同一簇内的数据点彼此相似,而不同簇的数据点不同。例如,客户细分,浏览器使用聚类算法针对多个关键词寻找文章。
- 降维:减少数据中的特征数量,以便更容易地进行可视化或进一步分析。例如,主成分分析(PCA)。
- 关联规则学习:在大型数据库中寻找项目之间的有趣关系,例如市场篮子分析。
- 异常检测:识别数据集中的异常或罕见事件。例如,用于欺诈检测。
非监督学习的应用
- 数据探索:理解数据的结构和分布。
- 自然语言处理:比如主题建模和词嵌入。
- 推荐系统:发现用户可能感兴趣的新产品或服务。
- 图像处理:如图像分割和对象识别。
方法和技术
- K-均值聚类:一种流行的聚类算法,用于将数据分为K个簇。
- 层次聚类:创建数据的树形结构分割。
- DBSCAN:基于密度的聚类方法,适合于寻找任意形状的簇。
- 主成分分析(PCA):一种常用的降维技术。
优点
- 灵活性:由于不需要标注数据,非监督学习在实际应用中非常灵活。
- 发现隐藏模式:可以发现数据中未知的模式。
缺点
- 结果解释性:非监督学习的结果可能不如监督学习那样直观和容易解释。
- 目标不明确:由于缺乏明确的输出变量,确定学习的目标和评价模型的效果可能更加困难。
非监督学习是一种强大的工具,适用于那些我们不了解数据结构或没有明确目标的场景。尽管其结果的解释性可能不如监督学习,但它在探索性数据分析和模式识别方面非常有效。
**
线性回归模型
**
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
# 设置 Matplotlib 字体
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei'] # 用于正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用于正常显示负号
# 检查是否有可用的 CUDA 支持的 GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")
# 数据生成
x = torch.unsqueeze(torch.linspace(-1, 1, 100), dim=1).to(device) # 将数据移至 GPU
y = (2 * x + torch.randn(x.size()).to(device) * 0.2).to(device) # 生成噪声并将其移至 GPU
# 定义模型
class LinearRegressionModel(nn.Module):
def __init__(self):
super(LinearRegressionModel, self).__init__()
self.linear = nn.Linear(1, 1)
def forward(self, x):
return self.linear(x)
model = LinearRegressionModel().to(device) # 将模型移至 GPU
# 损失函数和优化器
criterion = nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# 训练循环
num_epochs = 100
for epoch in range(num_epochs):
pred_y = model(x) # 前向传播
loss = criterion(pred_y, y) # 计算损失
optimizer.zero_grad()
loss.backward() # 反向传播
optimizer.step() # 更新权重
if (epoch+1) % 10 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')
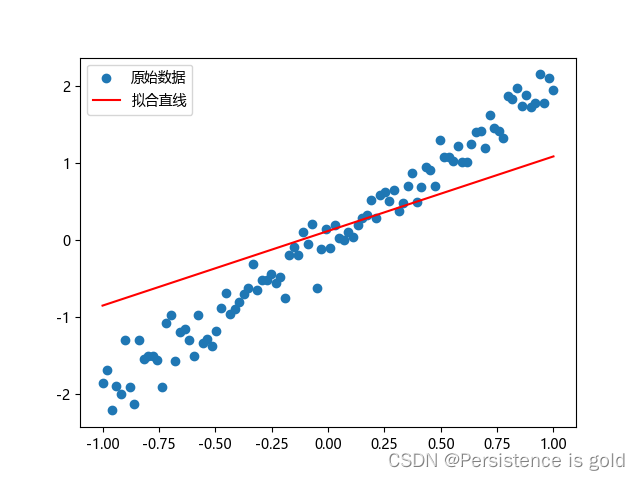
# 绘制结果(需要将数据移回 CPU)
predicted = model(x).detach().cpu().numpy()
plt.scatter(x.cpu().numpy(), y.cpu().numpy(), label='原始数据')
plt.plot(x.cpu().numpy(), predicted, label='拟合直线', color='r')
plt.legend()
plt.show()
线性模型相对简单和易用,易于我们了解并掌握更复杂的非线性模型。
成本函数
成本函数(Cost Function),在机器学习和统计学中,是一个用来衡量模型预测值与实际值之间差异的函数。它是一个关键的概念,因为在训练机器学习模型时,目标通常是最小化这个成本函数。换句话说,成本函数帮助我们了解我们的模型做得有多好(或多差)。
成本函数有几种不同的类型,取决于具体的任务和使用的算法。例如:
-
均方误差(Mean Squared Error, MSE):这是回归任务中常用的成本函数。它计算模型预测值与实际值之间差异的平方的平均值。
-
交叉熵损失(Cross-Entropy Loss):这在分类任务中非常常见。对于二分类问题,这通常被称为二元交叉熵损失;对于多类分类问题,它被称为多类别交叉熵损失。
-
逻辑回归损失(Logistic Regression Loss):在逻辑回归中使用,这也是一种交叉熵损失函数的形式。
-
Hinge损失(Hinge Loss):这主要用于支持向量机(SVM)中的分类任务。
成本函数的选择取决于具体的应用场景和要解决的问题类型。在机器学习的训练过程中,通过调整模型参数来最小化成本函数,从而提高模型的预测准确性。
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
import numpy as np
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
# 创建一个简单的数据集
# 假设这些是预测值和实际值
predicted = torch.randn(10)
actual = torch.randn(10)
# 使用均方误差作为成本函数
mse_loss = nn.MSELoss()
loss = mse_loss(predicted, actual)
# 用于绘图的数据
points = torch.linspace(-3, 3, 100)
losses = [(mse_loss(p * torch.ones_like(predicted), actual)).item() for p in points]
# 绘制图形
plt.plot(points.numpy(), losses, label='MSE Loss')
plt.scatter(predicted.numpy(), [mse_loss(p, actual).item() for p in predicted], color='red')
plt.xlabel('Predicted Values')
plt.ylabel('Loss')
plt.title('MSE Loss with Varying Predictions')
plt.legend()
plt.show()

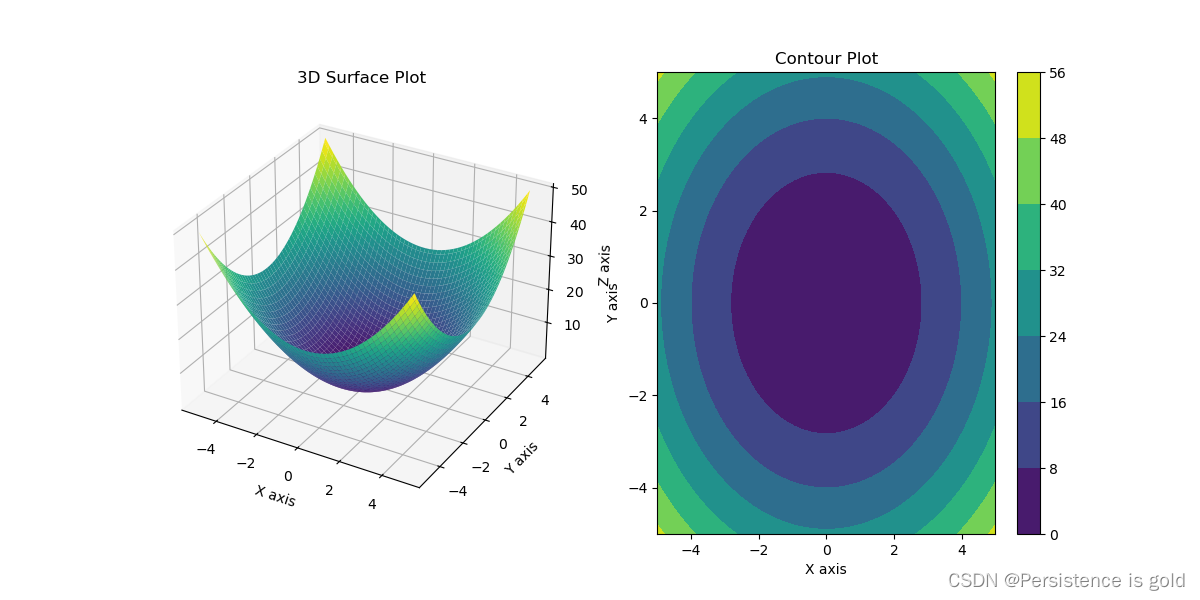
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
# 定义一个简单的二元函数,例如二次函数
def func(x, y):
return x**2 + y**2
# 生成x和y的数据
x = np.linspace(-5, 5, 100)
y = np.linspace(-5, 5, 100)
x, y = np.meshgrid(x, y)
z = func(x, y)
# 创建3D图
fig = plt.figure(figsize=(12, 6))
# 创建一个3D轴
ax1 = fig.add_subplot(121, projection='3d')
ax1.plot_surface(x, y, z, cmap='viridis')
ax1.set_xlabel('X axis')
ax1.set_ylabel('Y axis')
ax1.set_zlabel('Z axis')
ax1.set_title('3D Surface Plot')
# 创建等高线图
ax2 = fig.add_subplot(122)
contour = ax2.contourf(x, y, z, cmap='viridis')
fig.colorbar(contour)
ax2.set_xlabel('X axis')
ax2.set_ylabel('Y axis')
ax2.set_title('Contour Plot')
# 展示图像
plt.show()
jupyter代码
%matplotlib notebook
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
# 定义一个简单的二元函数
def func(x, y):
return x**2 + y**2
# 生成x和y的数据
x = np.linspace(-5, 5, 100)
y = np.linspace(-5, 5, 100)
x, y = np.meshgrid(x, y)
z = func(x, y)
# 创建3D图
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
ax.plot_surface(x, y, z, cmap='viridis')
# 设置坐标轴标签
ax.set_xlabel('X axis')
ax.set_ylabel('Y axis')
ax.set_zlabel('Z axis')
# 展示图像
plt.show()
梯度下降
梯度下降是一种优化算法,常用于机器学习和人工智能领域,用于最小化一个函数。简而言之,它的目的是找到函数的最小值或最低点。这个算法的工作原理是迭代地调整参数,以减少函数的值。
梯度下降的关键概念是梯度(函数在某一点的斜率或方向),它指示了函数值增加的方向。梯度下降算法沿着梯度的相反方向(即下降的方向)进行参数的调整,以期达到函数的最小值。
梯度下降通常分为三种类型:
- 批量梯度下降(Batch Gradient Descent):在每一步中使用所有数据来计算梯度。
- 随机梯度下降(Stochastic Gradient Descent,SGD):在每一步中随机选择一个数据点来计算梯度。
- 小批量梯度下降(Mini-batch Gradient Descent):在每一步中使用数据的一个子集(称为“小批量”)来计算梯度。
在机器学习中,梯度下降通常用于训练模型,例如线性回归、逻辑回归和神经网络。通过最小化损失函数(一种衡量模型预测和实际值差异的函数),梯度下降帮助确定模型参数,使模型的预测尽可能接近真实数据。
“怎样最快的下山?”–>梯度下降
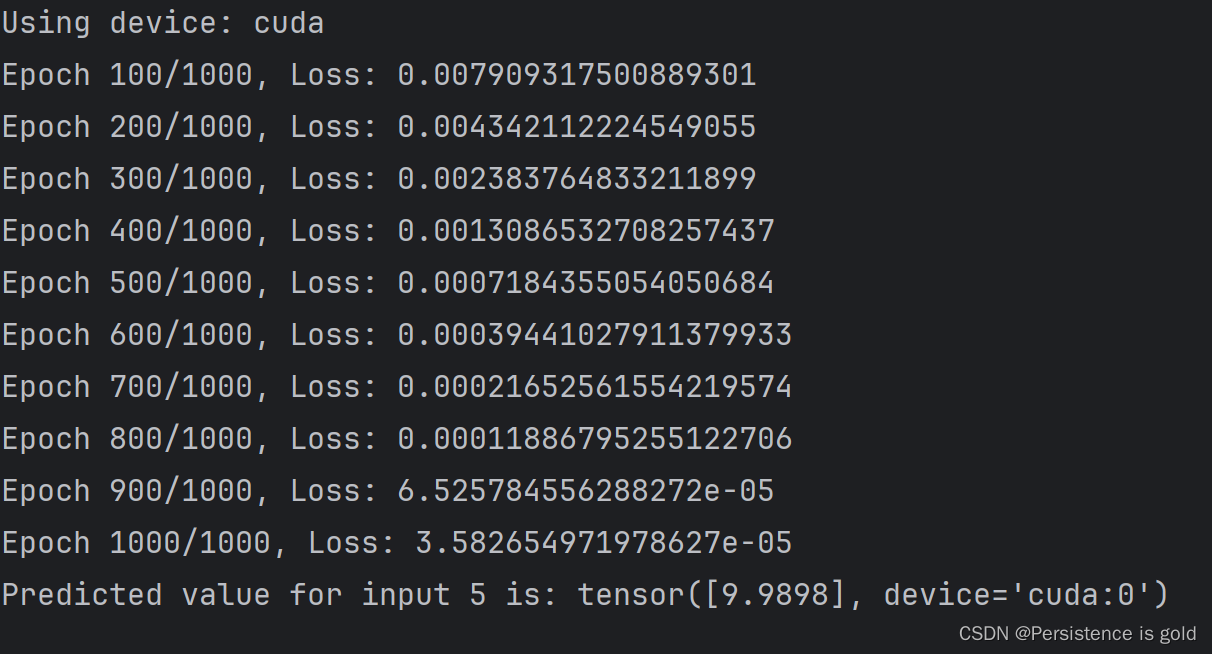
import torch
import torch.nn as nn
import torch.optim as optim
# 检查CUDA是否可用,并据此设置device变量
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print("Using device:", device)
# 假设数据
X = torch.tensor([[1.0], [2.0], [3.0], [4.0]], device=device)
Y = torch.tensor([[2.0], [4.0], [6.0], [8.0]], device=device)
# 创建线性模型,并将其移动到设定的device
model = nn.Linear(1, 1).to(device)
# 定义损失函数
criterion = nn.MSELoss()
# 选择优化器
optimizer = optim.SGD(model.parameters(), lr=0.01)
# 训练循环
epochs = 1000
for epoch in range(epochs):
# 前向传播
y_pred = model(X)
# 计算损失
loss = criterion(y_pred, Y)
# 反向传播
optimizer.zero_grad()
loss.backward()
# 更新参数
optimizer.step()
if (epoch+1) % 100 == 0:
print(f'Epoch {epoch+1}/{epochs}, Loss: {loss.item()}')
# 测试模型
test_x = torch.tensor([[5.0]], device=device)
predicted = model(test_x).data[0]
print(f'Predicted value for input 5 is: {predicted}')
运行结果
多元线性回归和矢量化
多元线性回归和矢量化是两个重要的概念,在数据分析和机器学习领域中非常常见。
多元线性回归
多元线性回归是线性回归的一种扩展,它用于描述两个或多个自变量(输入变量)与一个因变量(输出变量)之间的线性关系。多元线性回归的基本形式如下:
[ y = \beta_0 + \beta_1 x_1 + \beta_2 x_2 + \cdots + \beta_n x_n + \epsilon ]
其中:
- ( y ) 是因变量。
- ( x_1, x_2, \ldots, x_n ) 是自变量。
- ( \beta_0, \beta_1, \ldots, \beta_n ) 是模型参数,包括截距项 ( \beta_0 ) 和各自变量的系数。
- ( \epsilon ) 是误差项,代表模型未能解释的部分。
在多元线性回归中,我们的目标是根据已有数据估计这些参数(系数),以便我们可以使用这个模型来预测或理解自变量和因变量之间的关系。
矢量化
矢量化是一种编程技术,尤其在科学计算中非常重要,它通过操作整个数组而不是数组中的单个元素来提高代码的效率。这种方法可以大幅减少显式的循环和迭代,利用现代处理器的矢量运算能力,从而加快计算速度。
在多元线性回归的上下文中,矢量化使我们能够更高效地计算预测值、损失函数和梯度。例如,多元线性回归的矢量化形式可以表示为:
[ \mathbf{y} = \mathbf{X}\beta + \epsilon ]
其中:
- ( \mathbf{y} ) 是因变量的向量。
- ( \mathbf{X} ) 是一个矩阵,每一行代表一个数据点,每一列代表一个自变量。
- ( \beta ) 是包含所有模型参数的向量。
- ( \epsilon ) 是误差向量。
使用矢量化,我们可以用一行代码计算整个数据集的预测值,而无需显式编写循环。这不仅使代码更简洁,而且通常更高效,因为现代数值计算库(如NumPy)和硬件都是为矢量和矩阵运算优化的。
总结
- 多元线性回归:一种统计技术,用于建模多个自变量和一个因变量之间的线性关系。
- 矢量化:一种编程技术,通过操作整个数组而不是单个元素,提高计算效率,特别适用于数据分析和机器学习中的大规模计算。
Numpy库
NumPy(Numerical Python的缩写)是Python编程语言的一个非常流行的库,专门用于大规模数值计算。它提供了一个高性能的多维数组对象和用于操作这些数组的工具,成为科学计算和数据分析中不可或缺的工具之一。
关键特性
-
多维数组对象:NumPy的核心功能是其
ndarray对象,这是一个多维数组,允许你进行高效的向量化计算。它比Python内置的列表更高效,尤其是在处理大型数据集时。 -
广播功能:NumPy支持广播(broadcasting),这是一种强大的机制,允许不同大小的数组进行算术运算。
-
数学函数:提供了大量的数学函数来操作这些数组,包括统计、线性代数运算、傅里叶变换等。
-
集成:可以轻松地与其他Python库集成,如Pandas(数据分析)、Matplotlib(绘图)、SciPy(科学计算)等。
-
内存效率:NumPy的数组更加内存效率,支持更复杂的数学运算。
-
平台无关性:NumPy的数组表示是平台无关的,这使得NumPy数组适合于实现跨平台的数据交换。
应用领域
- 科学计算:NumPy被广泛用于科学计算领域,如物理学、化学、天文学等。
- 数据分析:作为Pandas等数据处理工具的基础,NumPy在数据分析和预处理中非常重要。
- 机器学习:在机器学习和深度学习领域,NumPy用于数据的处理和转换。
- 图像处理:在图像处理领域,NumPy的数组可以用来表示和操作图像。
示例代码
以下是一个简单的NumPy使用示例:
import numpy as np
# 创建一个NumPy数组
a = np.array([1, 2, 3, 4, 5])
# 进行一些数组操作
print("数组的形状:", a.shape)
print("数组的总和:", np.sum(a))
print("数组的平均值:", np.mean(a))
安装
如果你的Python环境中还没有安装NumPy,你可以通过Python的包管理器pip来安装它:
pip install numpy
总之,NumPy是Python科学计算的基石,其强大的数组操作和数学工具使其成为进行高效数据分析和数值计算的首选库。
import numpy as np
import time
# 创建更大的数组
size = 1000000
a = np.random.rand(size)
b = np.random.rand(size)
list_a = list(a)
list_b = list(b)
# 使用NumPy进行点乘
start_time = time.time()
dot_product_numpy = a * b
end_time = time.time()
numpy_time = end_time - start_time
# 使用Python列表进行相同的计算
start_time = time.time()
dot_product_list = [list_a[i] * list_b[i] for i in range(len(list_a))]
end_time = time.time()
list_time = end_time - start_time
# 打印结果和耗时
print("NumPy版本耗时:", numpy_time)
print("Python列表版本耗时:", list_time)
print("NumPy比Python列表快了多少倍:", list_time / numpy_time)
运行结果

可以清楚看到使用numpy进行向量点乘的效率比for循环快了多少!
使用 NumPy 的 dot 函数可以进行数组或矩阵的点乘(内积)。点乘不同于元素间乘法,点乘涉及将两个数组的对应元素相乘后求和(对于一维数组),或者是矩阵乘法(对于二维数组)。以下是一个使用 dot 函数的示例,演示了如何使用它来计算一维数组和二维数组的点乘,并与传统 Python 循环方法进行性能比较:
import numpy as np
import time
# 创建一维数组
size = 1000000
a = np.random.rand(size)
b = np.random.rand(size)
# 使用 NumPy 进行点乘
start_time = time.time()
dot_product_numpy = np.dot(a, b)
end_time = time.time()
numpy_time = end_time - start_time
# 使用 Python 列表和循环进行相同的计算
list_a = list(a)
list_b = list(b)
start_time = time.time()
dot_product_list = sum([list_a[i] * list_b[i] for i in range(size)])
end_time = time.time()
list_time = end_time - start_time
# 打印结果和耗时
print("NumPy dot 产品:", dot_product_numpy)
print("Python 列表点乘产品:", dot_product_list)
print("NumPy 版本耗时:", numpy_time)
print("Python 列表版本耗时:", list_time)
print("NumPy 比 Python 列表快:", list_time / numpy_time, "倍")
# 创建二维数组(矩阵)
N = 300
M = 400
K = 500
matrix_a = np.random.rand(N, M)
matrix_b = np.random.rand(M, K)
# 使用 NumPy 对矩阵进行点乘
start_time = time.time()
matrix_product_numpy = np.dot(matrix_a, matrix_b)
end_time = time.time()
print("NumPy 矩阵点乘耗时:", end_time - start_time)
在这个示例中,我们首先对一维数组进行了点乘,然后对二维数组(矩阵)进行了点乘。对于一维数组,点乘是向量内积;对于二维数组,点乘是矩阵乘法。NumPy 的 dot 函数会自动根据输入数组的维度执行正确的操作。由于 NumPy 的底层实现是高度优化的,因此在处理大型数组时,其性能远超纯 Python 实现。
多元线性回归梯度下降
要实现多元线性回归模型,并使用梯度下降算法来训练它,可以使用PyTorch这个强大的深度学习库。下面是一个简单的多元线性回归示例,其中包括创建模型、定义损失函数和优化器,以及训练循环。
在这个例子中,假设我们有一些多维输入数据和对应的目标输出,我们的目标是训练一个线性模型来拟合这些数据。
import torch
import torch.nn as nn
import torch.optim as optim
# 生成一些随机数据作为示例
# 假设有3个特征和100个数据点
n_features = 3
n_samples = 100
X = torch.randn(n_samples, n_features)
Y = torch.randn(n_samples, 1)
# 创建线性回归模型
model = nn.Linear(n_features, 1)
# 定义损失函数 - 均方误差
criterion = nn.MSELoss()
# 选择优化器 - 随机梯度下降
optimizer = optim.SGD(model.parameters(), lr=0.01)
# 训练模型
epochs = 1000
for epoch in range(epochs):
# 前向传播: 计算预测值
y_pred = model(X)
# 计算和打印损失
loss = criterion(y_pred, Y)
# 后向传播: 计算损失相对于模型参数的梯度
optimizer.zero_grad() # 清空过去的梯度
loss.backward() # 计算梯度
# 更新参数
optimizer.step()
if (epoch+1) % 100 == 0:
print(f'Epoch [{epoch+1}/{epochs}], Loss: {loss.item()}')
# 模型评估(这里简单地用训练数据进行评估)
with torch.no_grad():
y_predicted = model(X)
mse = criterion(y_predicted, Y)
print(f'Model test MSE: {mse.item()}')
这段代码做了以下几件事情:
- 数据准备:生成了一些随机的输入数据
X和目标数据Y。 - 模型定义:创建了一个线性模型,它可以从输入特征到输出值进行映射。
- 损失函数:使用均方误差损失函数来衡量预测值和实际值之间的差异。
- 优化器:使用随机梯度下降(SGD)作为优化器来更新模型的权重。
- 训练循环:在每个epoch中,计算前向传播的损失,执行后向传播来获取梯度,并更新模型的权重。
请注意,这是一个简化的示例,仅用于演示目的。在实际应用中,你需要使用实际的数据集,并可能需要进行数据预处理、模型验证和超参数调整等步骤。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【Java 集合】LinkedBlockingDeque
- 年度回顾:2023年技术领域那些“最佳”、“最糟”和“最丑恶”的事件
- FAST-LIO2:论文和算法解析
- 数据结构:图文详解 队列 | 循环队列 的各种操作(出队,入队,获取队列元素,判断队列状态)
- 【linux】远程桌面连接到Debian
- 多级缓存架构(二)Caffeine进程缓存
- 【DB】DML DDL DCL TCL分别指的哪些
- 使用教程之【SkyWant.[2304]】路由器操作系统,破解移动【Netkeeper】校园网【小白篇】
- android自定义时间选择
- 4S店汽车行业万能通用小程序源码系统:功能强大,集合汽车在线展示+在线预约+贷款计算器......附带完整的搭建教程