NBA得分数据可视化
简介
这是上学期的一些课外活动内容,将 NBA 得分数据进行可视化,并进行后续的探索性分析和建模(本文未介绍)。主要研究动机来源于这篇论文:

该论文使用二元的伽马过程来刻画 NBA 主客场得分数据,并且考虑了两者之间的相关性。该模型可以预测最终得分和两支队伍的总得分。并将预测结果应用到了下注市场(赌球?)。
小编有话说:这是一篇将随机过程(可靠性中的退化过程)应用到了其他领域(体育,篮球)的典型代表。并且发到了管理学不错的期刊(ABS 4星),这种思路非常值得学习!
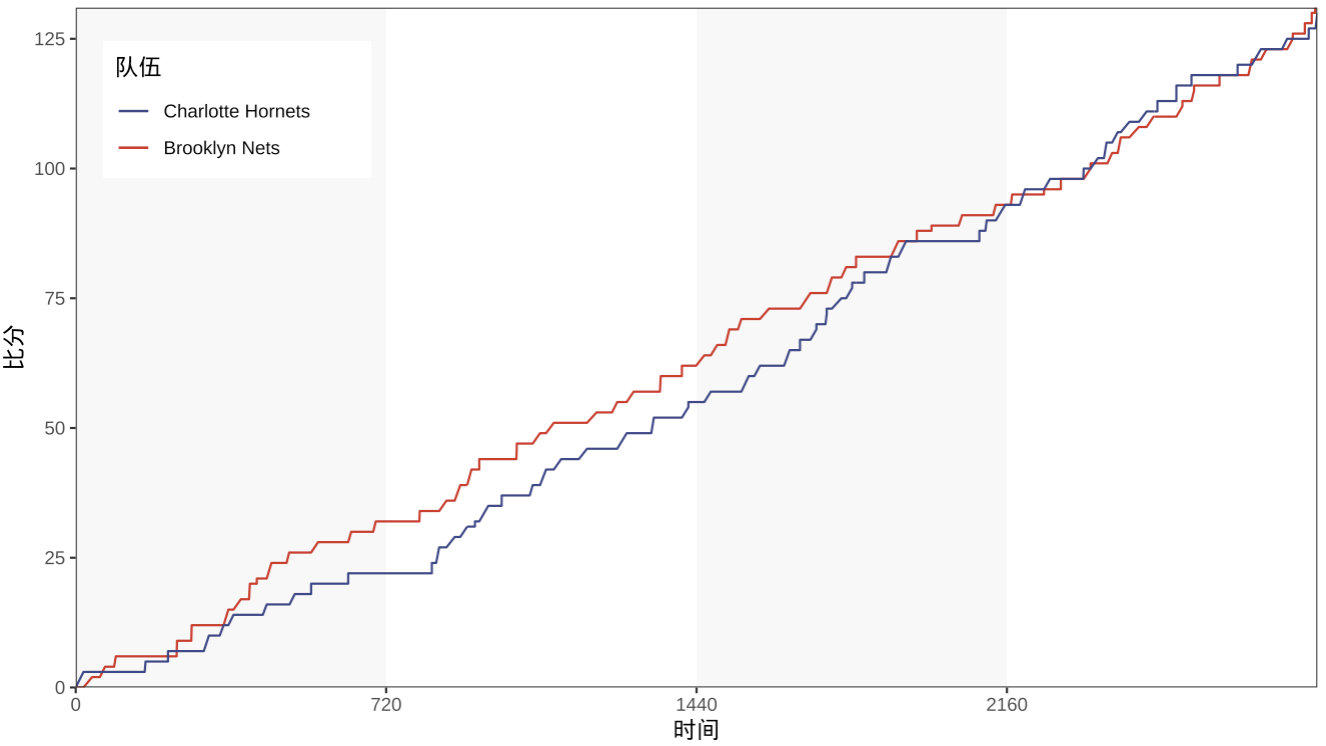
本文主要实现下论文中的得分数据图。下面是该论文中的大量主客场球队的得分路径图。本文主要针对某一场比赛的两支队伍进行可视化。
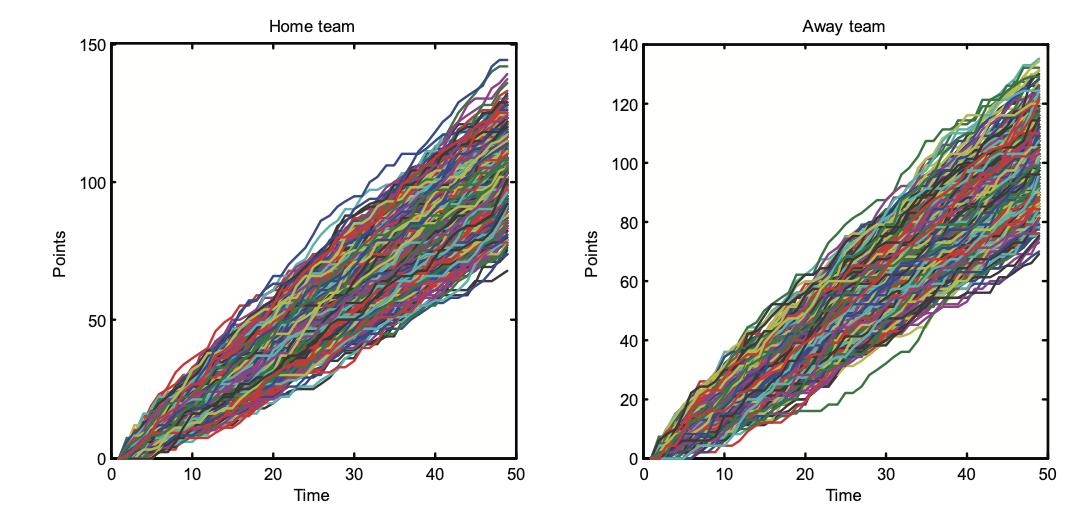
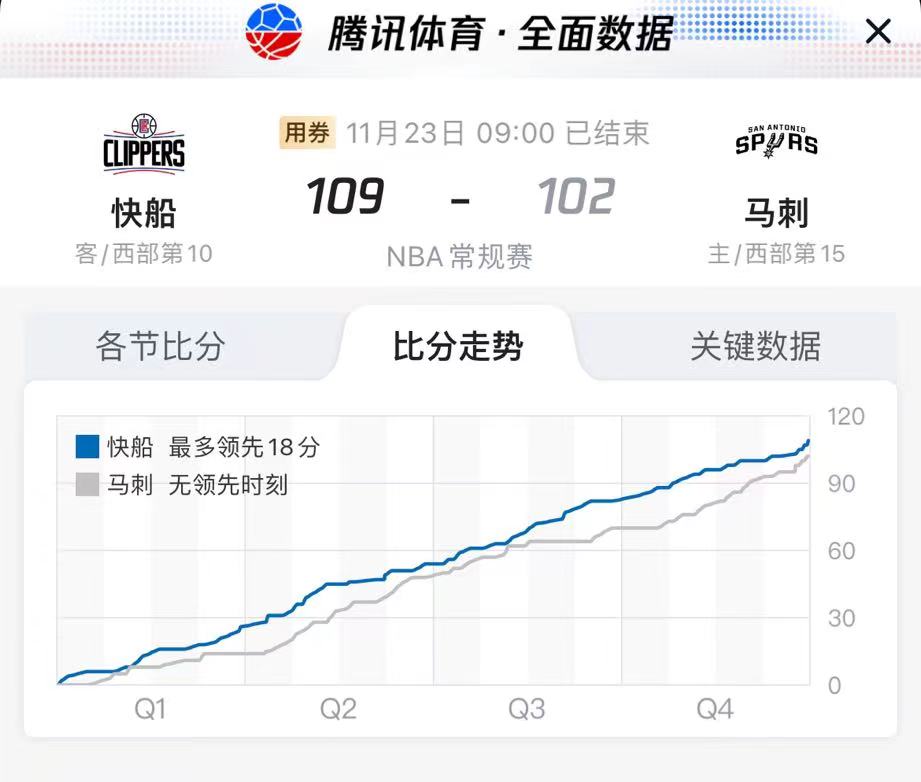
希望得到类似“腾讯体育”中的图形,如下所示:
案例教程
数据介绍
本文数据来自于该网站,需要对数据进行爬取。当然如果有合适的 R 包直接提供也是很不错的选择,体育相关 R 包可见: 。
这里以 2022 年 1 月 1 日的 印第安纳步行者 与 洛杉矶快船 的比赛作为案例。首先,加载该数据:
data1 = read_excel("1月/01-01-202 Indiana Pacers VS Los Angeles Clippers.xls")
colnames(data1) = c("序号","时间","比分")
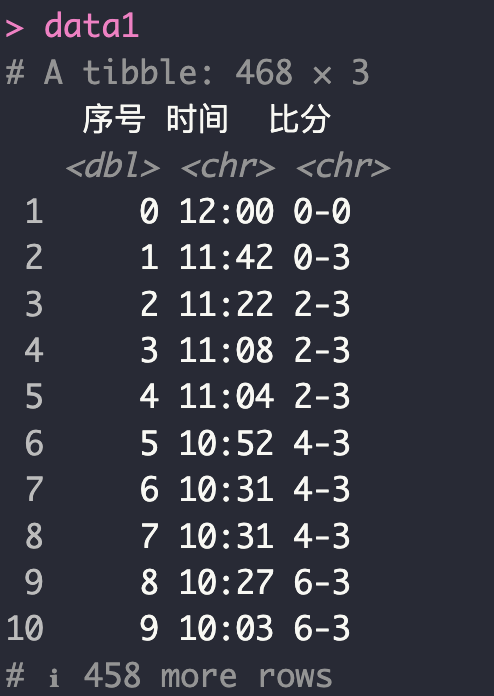
数据包含三列,得分发生变化时,就会记录一条数据。该数据包含了 468 行。
数据预处理
接下来,对数据进行预处理。小编为了方便起见,写了一个简单的函数。
data_precess = function(data1,home = "Charlotte Hornets", away = "Brooklyn Nets"){
# 将“比分”列中的“0-0”转换为两列数据
new_data <- separate(data1, col = "比分", into = c("主队比分", "客队比分"), sep = "-")
# 将“时间”列中的字符串转换为时间值
new_data$时间 <- as.numeric(ms(new_data$时间))
new_data$时间 <- max(new_data$时间) - new_data$时间
time_pr = time_process(new_data$时间)
new_data$新时间 = time_pr$new_dat
new_data$节次 <- factor(time_pr$index)
new_data$主队比分 = as.numeric(new_data$主队比分)
new_data$客队比分 = as.numeric(new_data$客队比分)
return(data = new_data)
}
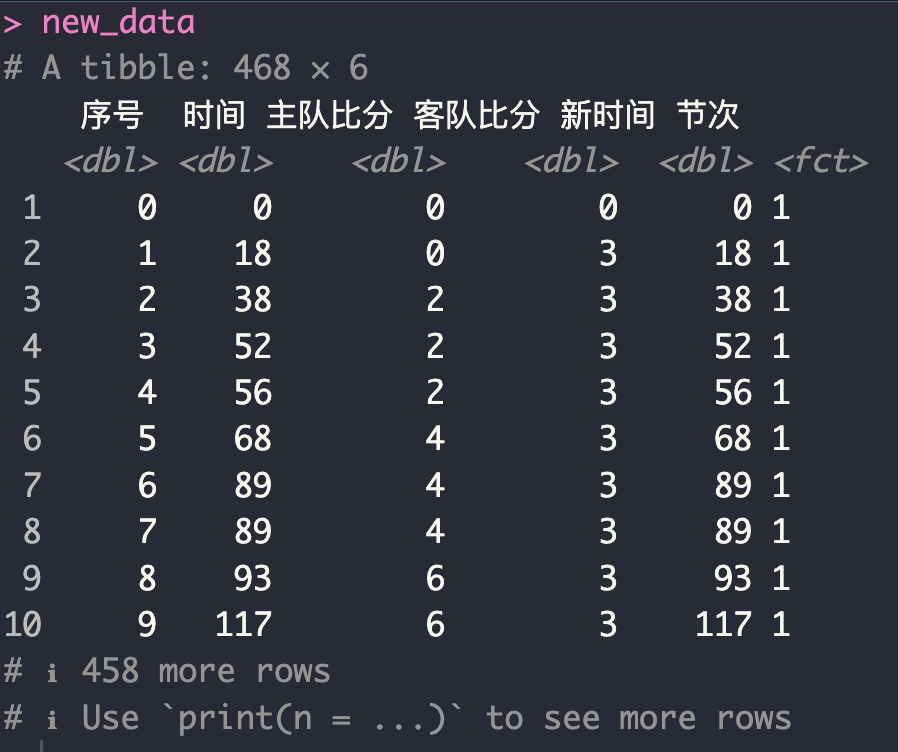
运行下面代码,你将获得数据处理后的结果:
home = "Charlotte Hornets"
away = "Brooklyn Nets"
new_data = data_precess(data1, home = home, away = away)
主要思路就是把主客队的得分拆分成两列,并给出新的时间刻度和节次。
数据可视化
处理完数据,就可以进行可视化了。代码比较简单,主要使用 geom_line() 添加两条折线,使用 geom_rect() 添加阴影部分来区分不同的节次。此外,添加一些细节调整。
new_data %>%
ggplot(aes(x = 新时间)) +
geom_rect(xmin = 0, xmax = 720, ymin = -Inf, ymax = Inf, fill = "#F7F7F7", alpha = 0.5) +
geom_rect(xmin = 0+720*2, xmax = 3*720, ymin = -Inf, ymax = Inf, fill = "#F7F7F7", alpha = 0.5) +
geom_line(aes(y = 主队比分, color = "Home")) +
geom_line(aes(y = 客队比分, color = "Away")) +
# facet_wrap(vars(节次)) +
scale_x_continuous(expand = c(0,0),breaks = seq(0, 2160, 720)) +
scale_y_continuous(expand = c(0,0)) +
scale_color_manual(name = "队伍",
values = c("Home" = "#DA2F20", "Away" = "#3E498D"),
labels = c(home,away))+
labs(x = "时间", y = "比分") +
theme_bw() + theme(panel.grid = element_blank(),
legend.position = c(0.13,0.9))
小编有话说
-
该图仅仅展示了两个队伍整场比赛的得分情况,更多探索分析还能进行,例如:计算最大分差,比分交替领先次数等。
-
本文所提论文就是基于这样的得分数据,使用随机过程进行建模与预测。这是一个很不错的出发点,更多的统计知识应用到该数据中还需要我们进一步探索。
-
如果读者们对这类体育数据感兴趣,欢迎一起交流合作!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- RHCE 【在openEuler系统中搭建基本论坛(网站)】
- Python进程间通信
- 报错Property ‘sqlSessionFactory‘ or ‘sqlSessionTemplate‘ are required
- 深度学习 pytorch的使用(张量2)
- 挑战Python100题(6)
- java单列标准写法
- 4.C语言——数组
- OD 学校的位置
- linux Tcp总结
- 【LeetCode-406】根据身高重建队列(贪心)