RPA数据采集的优势及方法(保姆级教程)
当今的企业越来越依赖自动化RPA技术和爬虫工具来帮助他们更高效地获取数据。这些工具可以极大地提高数据采集效率,减少人为错误,同时也能更准确地洞察市场趋势和客户需求。但它们在方法和优势上有很大的不同。本文将探讨RPA数据采集(以实在RPA设计器为例)与传统爬虫工具之间的区别,并附上实在RPA数据采集保姆级教程。
一、RPA数据采集的优势:
RPA(Robotic?Process?Automation)是一种通过软件机器人来模拟和执行人类操作的技术。使用RPA进行数据采集的优势在于以下几个方面:
a.?多用途性:?自动化RPA不仅仅用于数据采集,它还可以直接对采集的数据进行处理,如保存到Excel、数据过滤、数据分析等,这种多用途性使其成为一个全面的解决方案,适用的场景和应用领域大幅提升。
b.?集成能力:?自动化RPA可以轻松与企业现有的系统和应用程序集成,这意味着它可以与ERP、CRM、数据库等系统协同工作,无需进行大规模的更改或定制开发,这种无缝的集成能力有助于提高效率和准确性。
c.?可视化开发:?自动化RPA通常提供可视化开发工具,使非技术人员能够轻松创建自动化任务,这降低了对编程和脚本技能的需求,使更多的人能够参与自动化流程的开发和维护。
d.?强大的错误处理:?自动化RPA具有强大的错误处理和异常处理功能,它可以监视任务的执行,并在出现问题时采取预定义的行动,从而提高了稳定性和可靠性。
e.?合规性:?RPA通常更容易实现合规性,因为它们模拟人类用户的操作,可以遵守网站的使用政策和法规。
二、传统爬虫工具的不足:
传统爬虫工具是一类专门设计用于从网站上收集信息的软件。它们的不足包括:
a.?集成能力:?传统爬虫工具通常不具备直接的集成能力,需要额外的开发工作来与其他目标系统集成。
b.?开发复杂度:传统爬虫工具通常需要编写脚本来定义采集规则,这对技术人员来说是一种优势,但对于非技术人员来说有一定门槛。
c.?适用场景:对应用软件、ERP等桌面软件支持较少,也不支持跨应用、跨浏览器等关联操作,传统爬虫工具更适用于从网页中获取数据。
三、手把手教你使用实在RPA-数据采集功能
使用版本:设计器6.8.0-SP4
添加数据采集组件
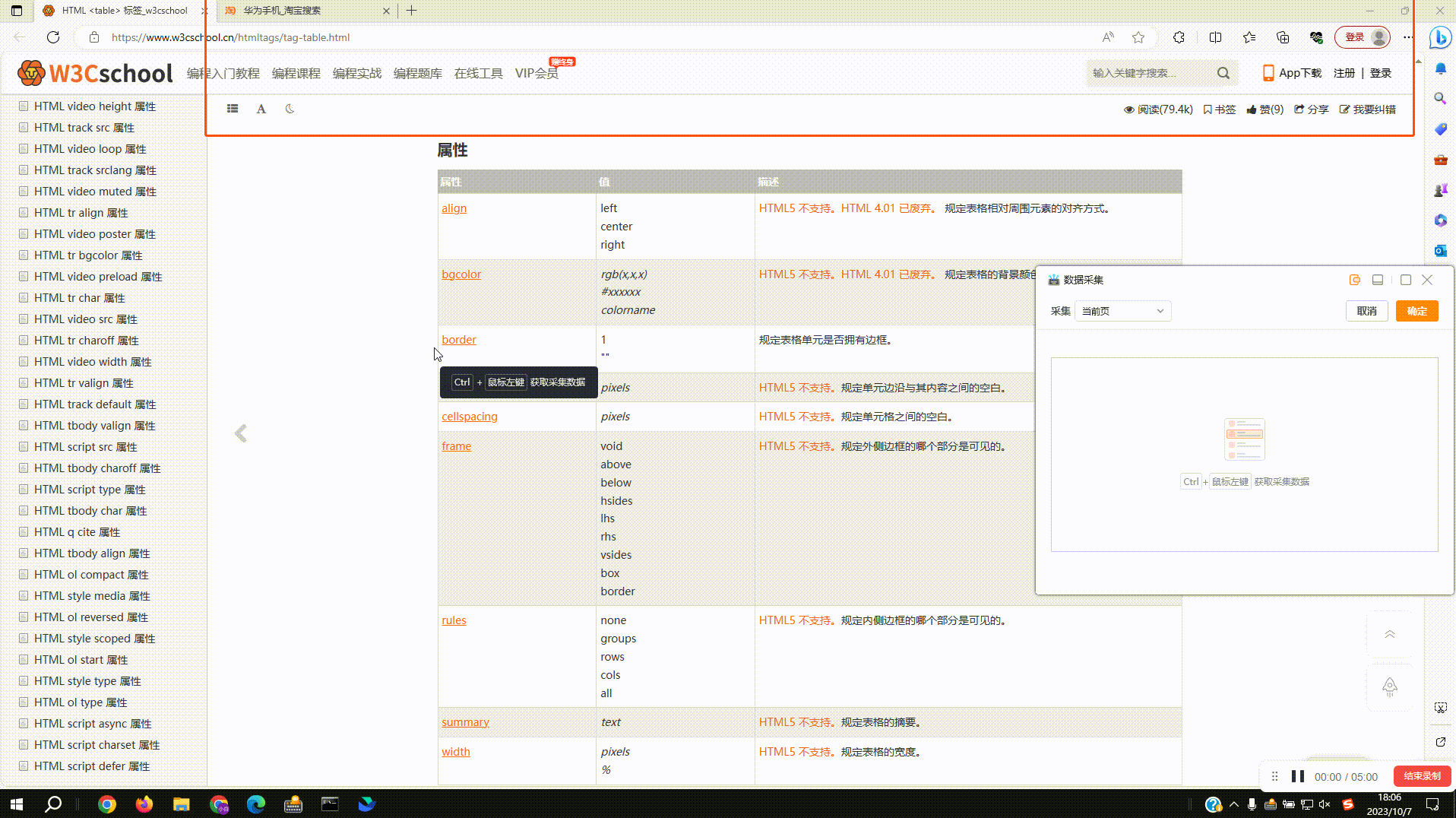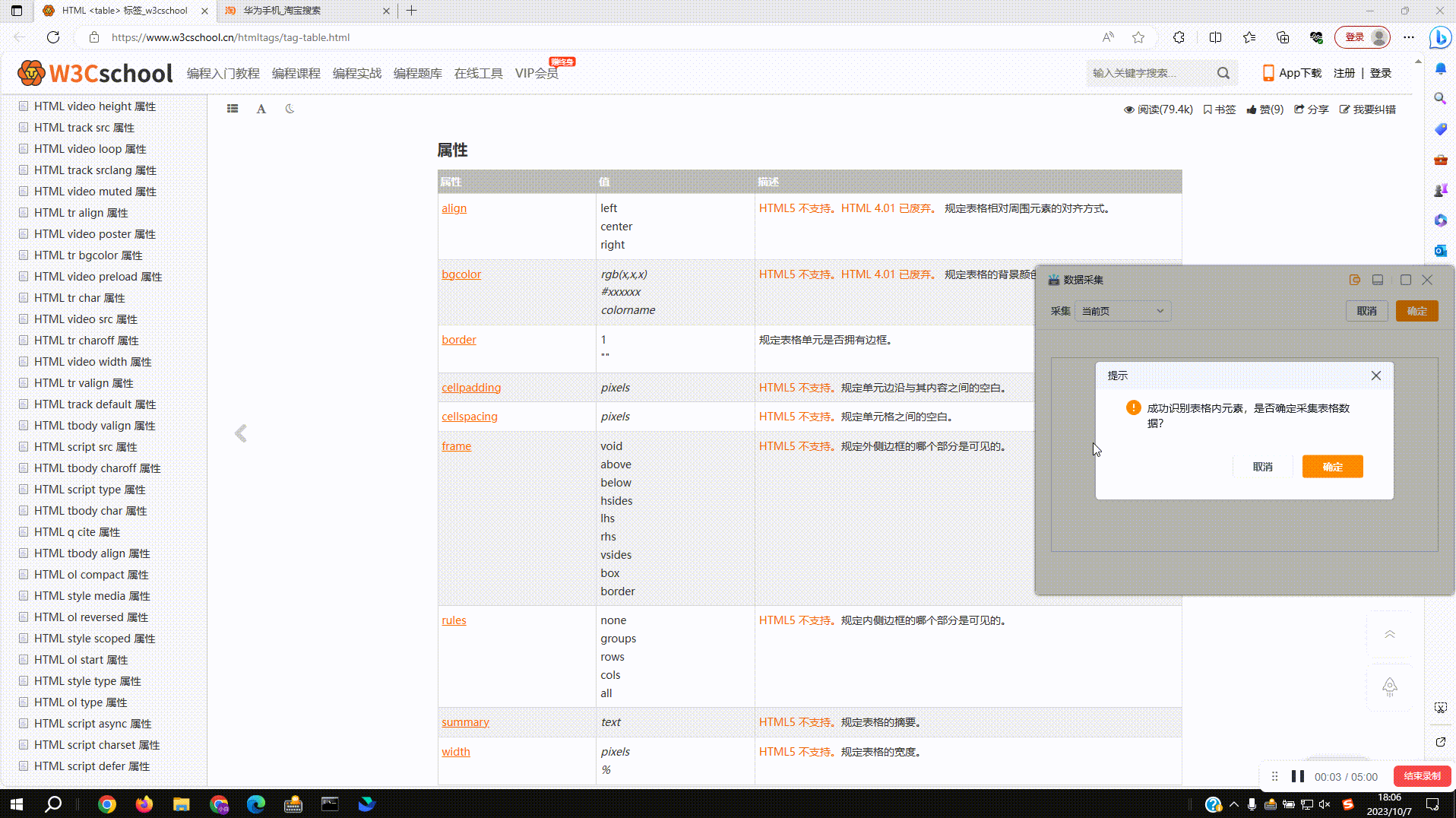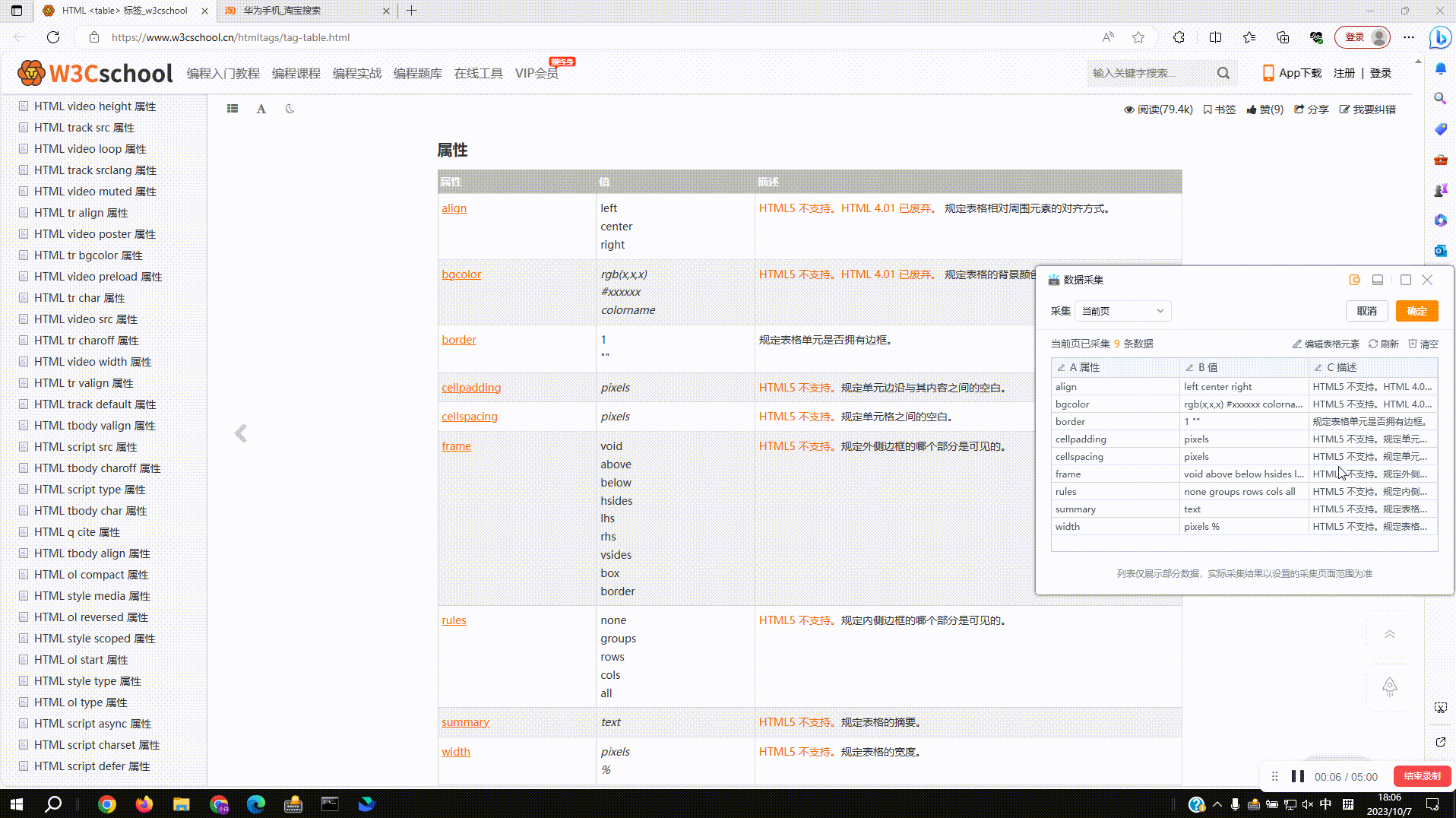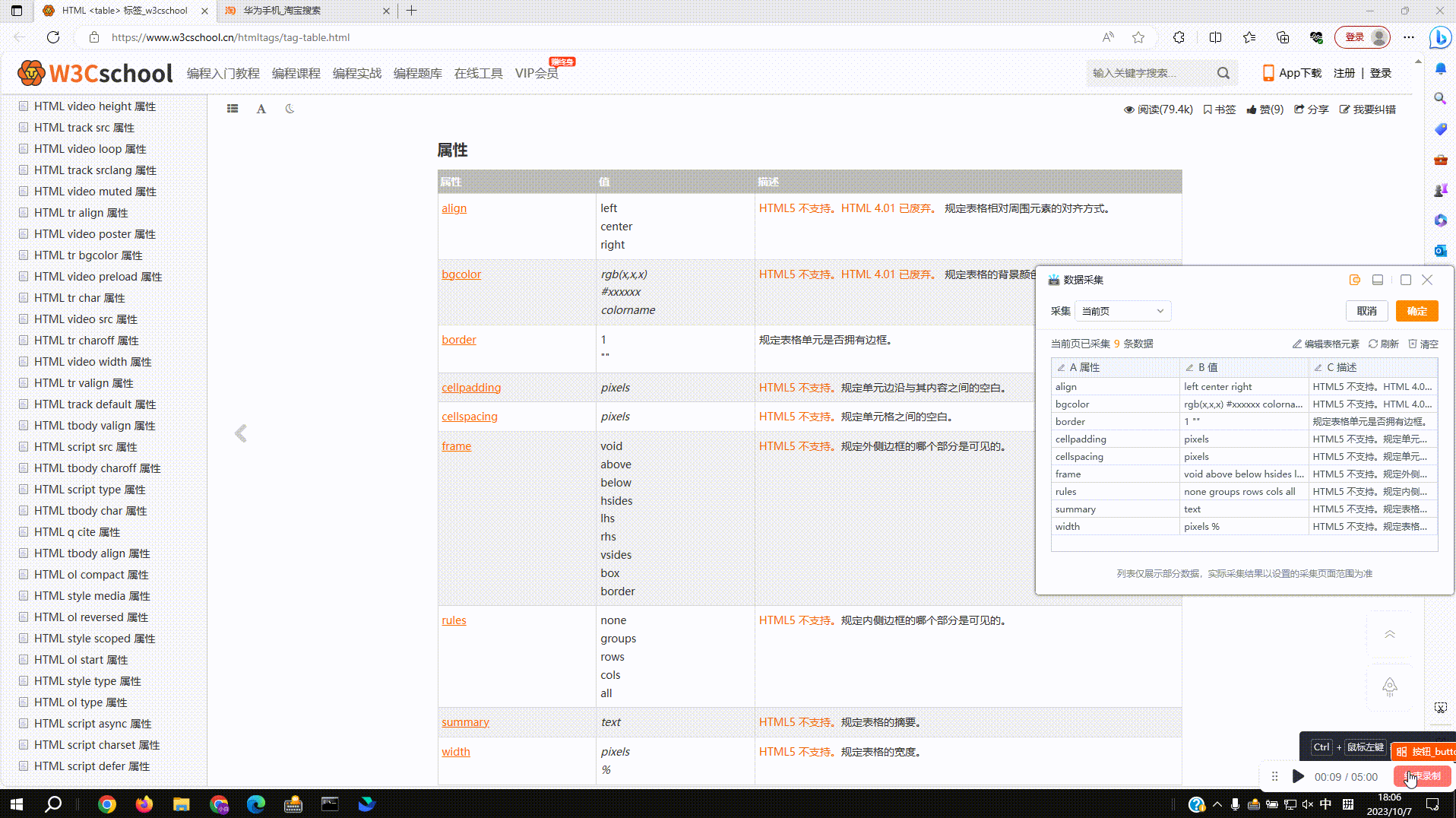
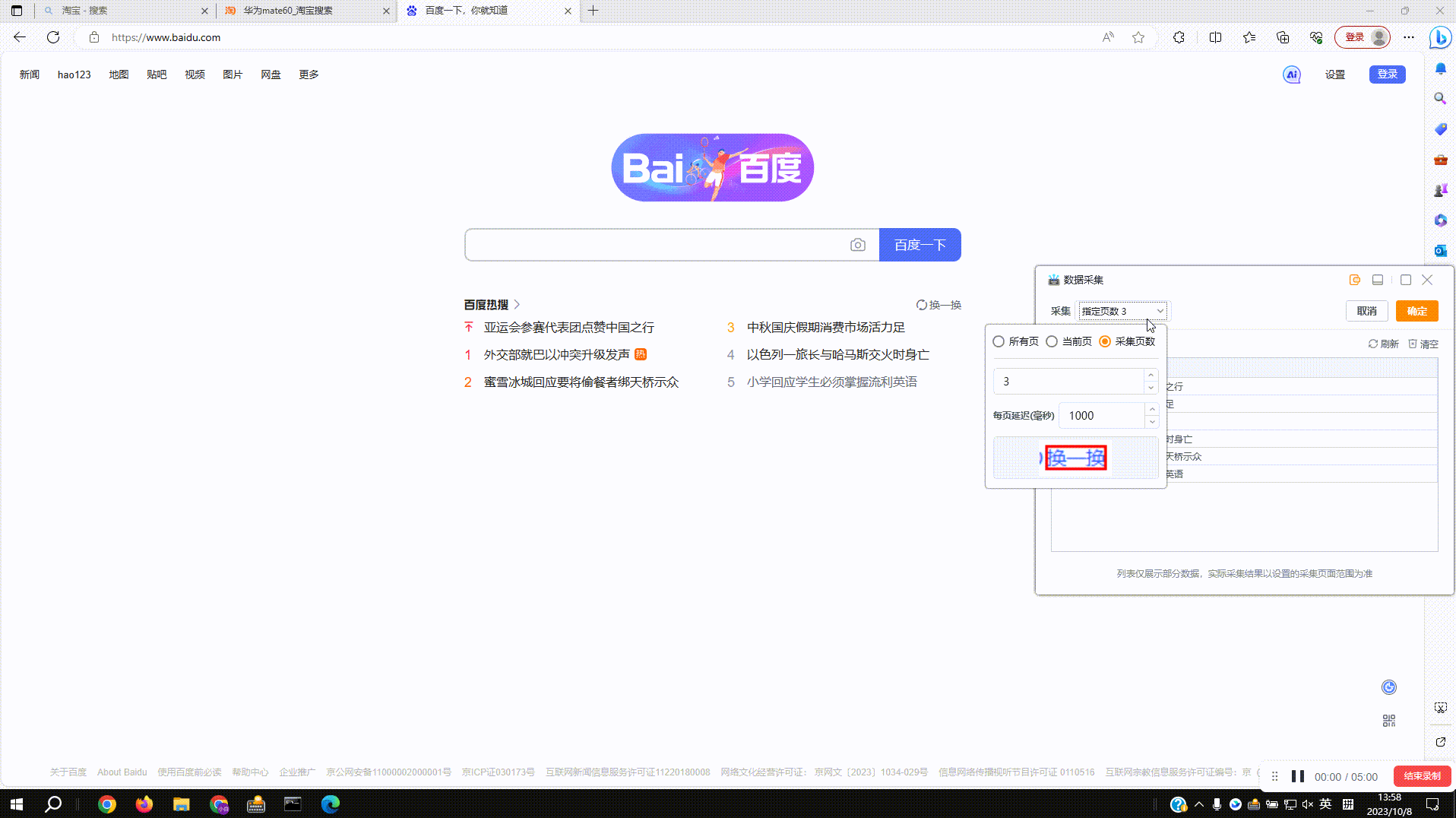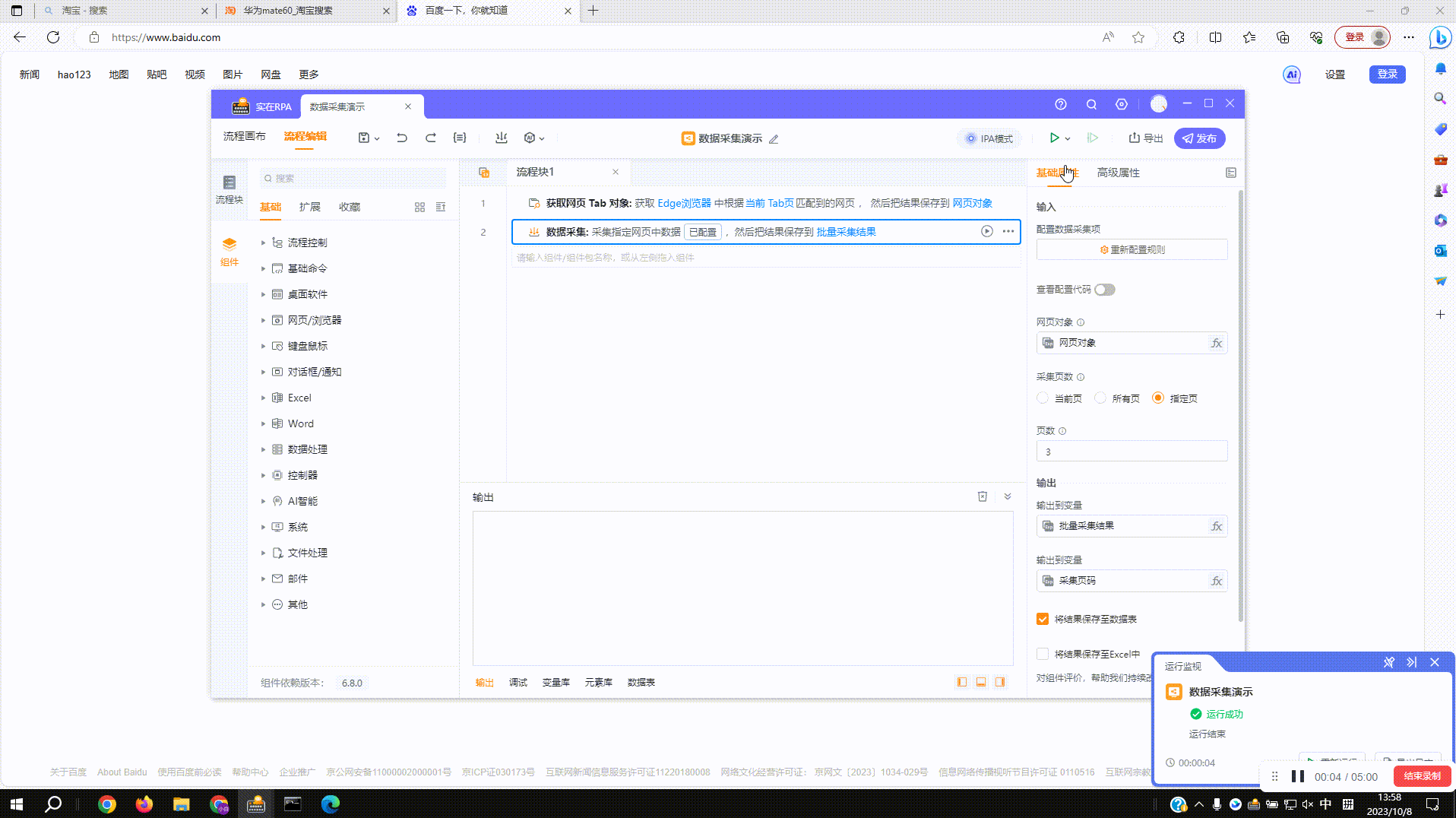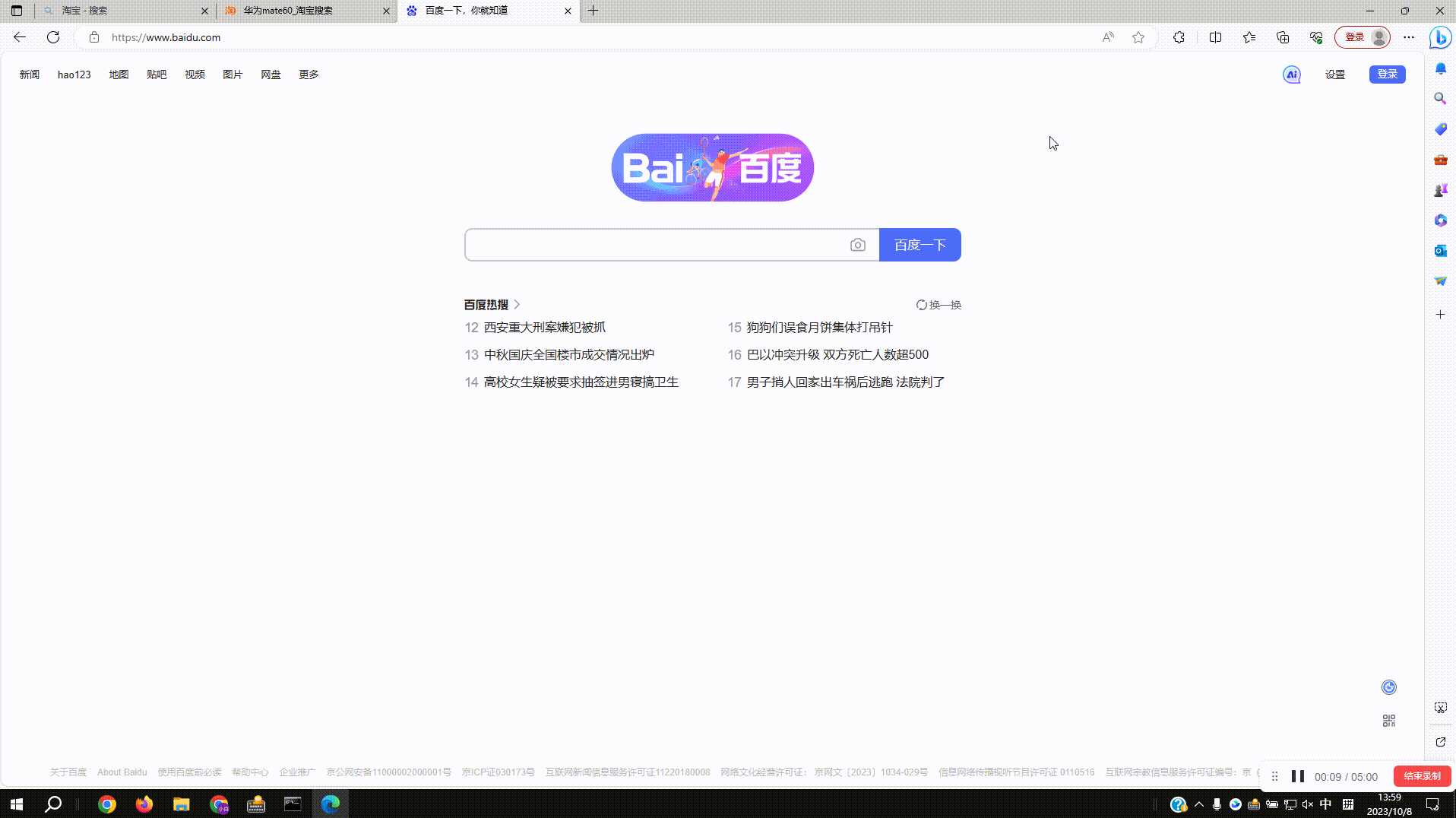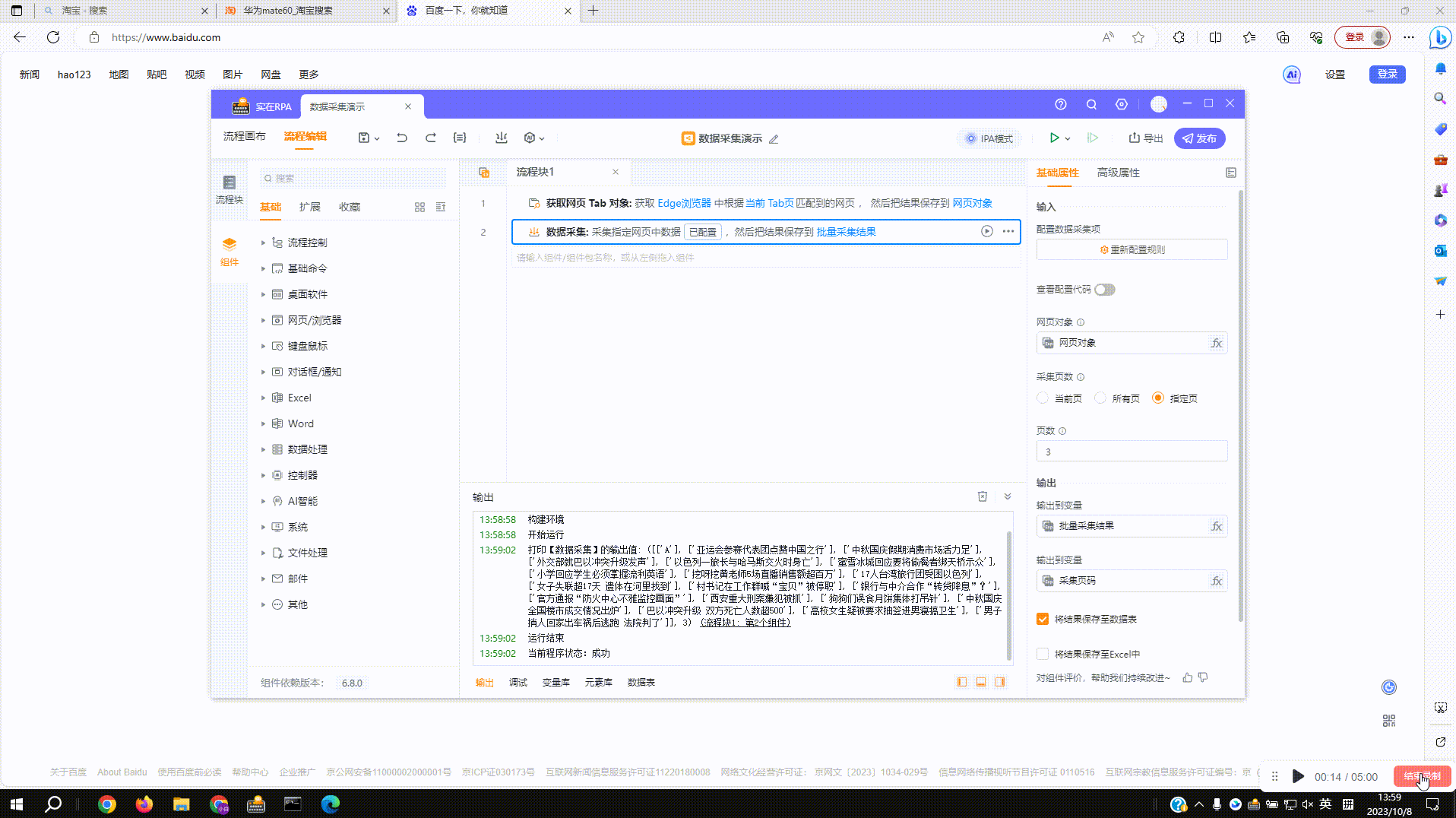
1.1?启动实在设计器后新建流程,点击顶部数据采集按钮添加组件,或者在左侧组件列表搜索添加
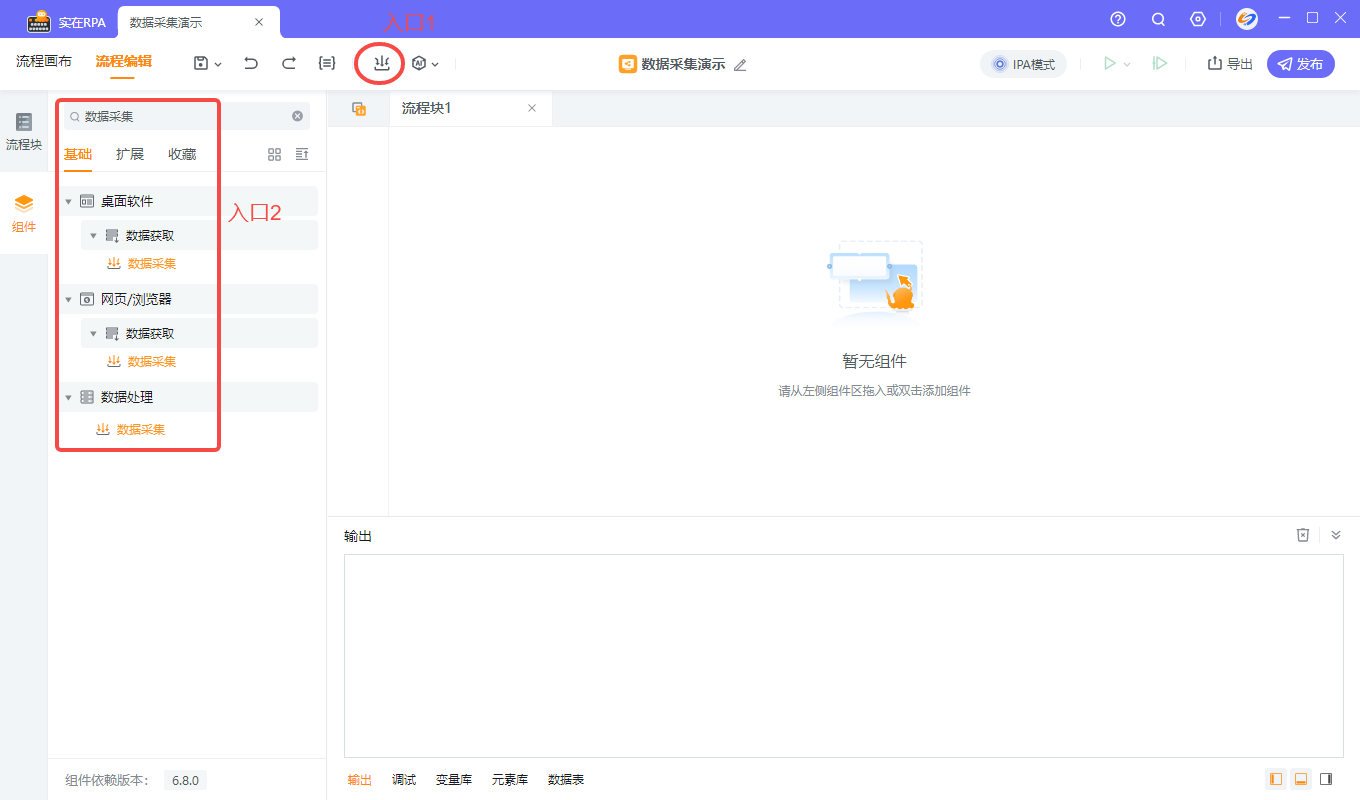
1.2?选择不同采集类型,采集网页类数据点击选项一,采集Windows桌面软件数据点击选项二。类型如果选择错误会有提示,退出采集重新添加组件即可
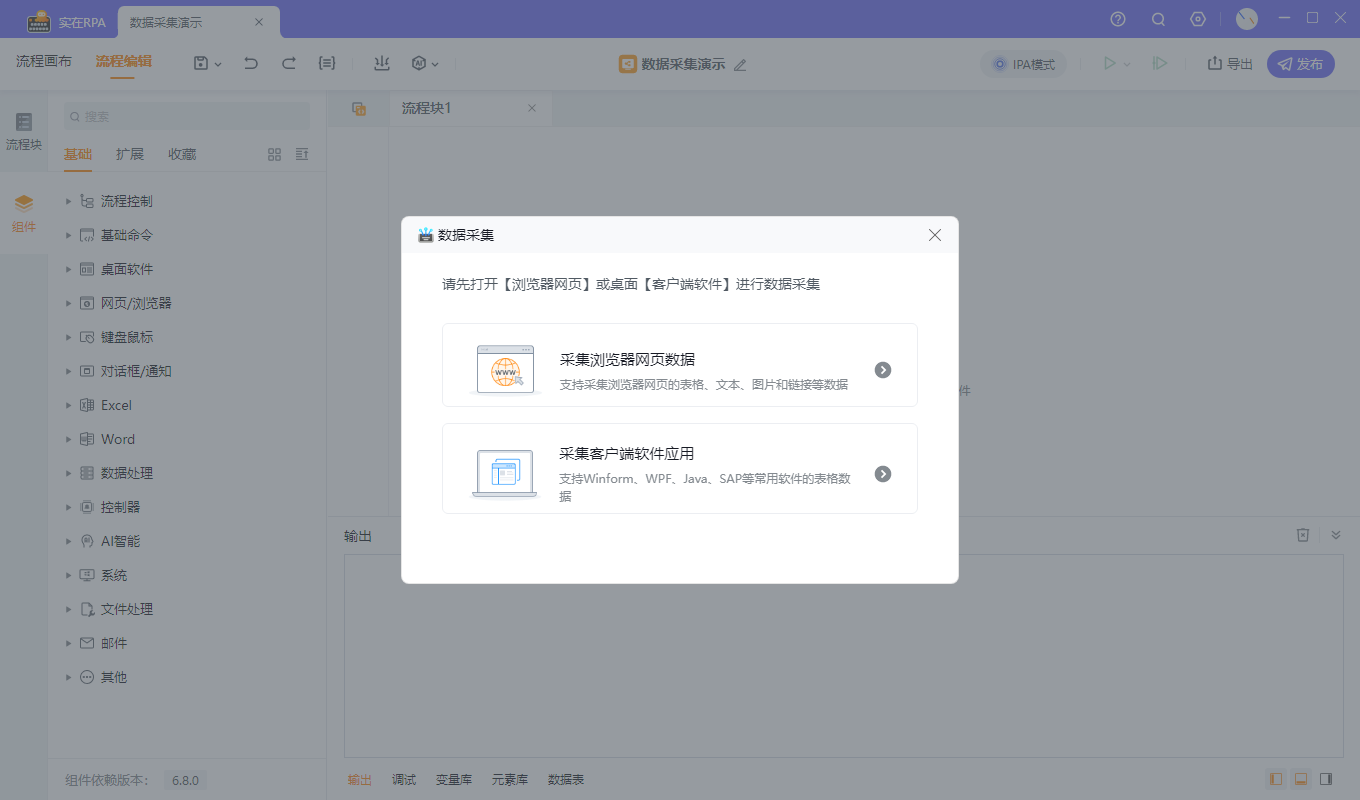
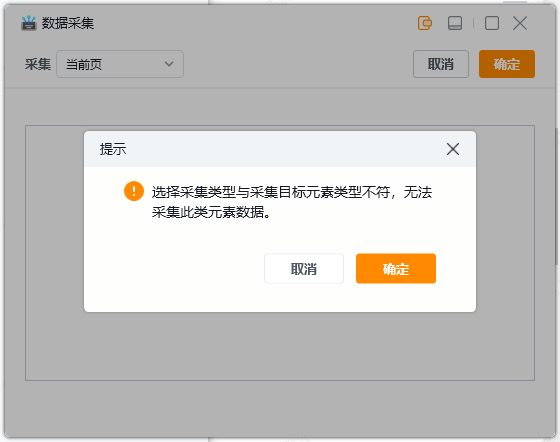
配置采集规则(以网页类型举例,软件类型操作相同)
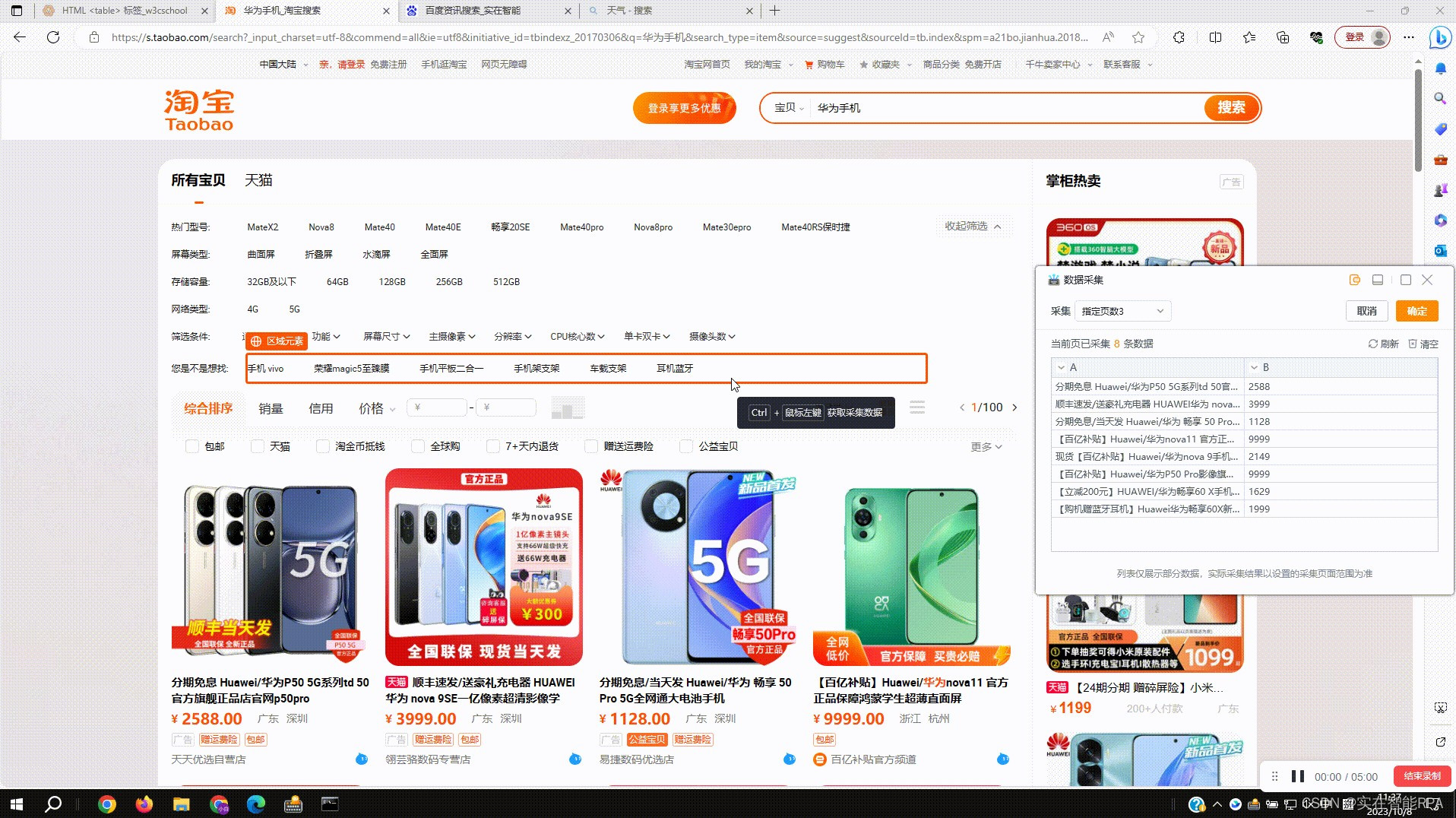
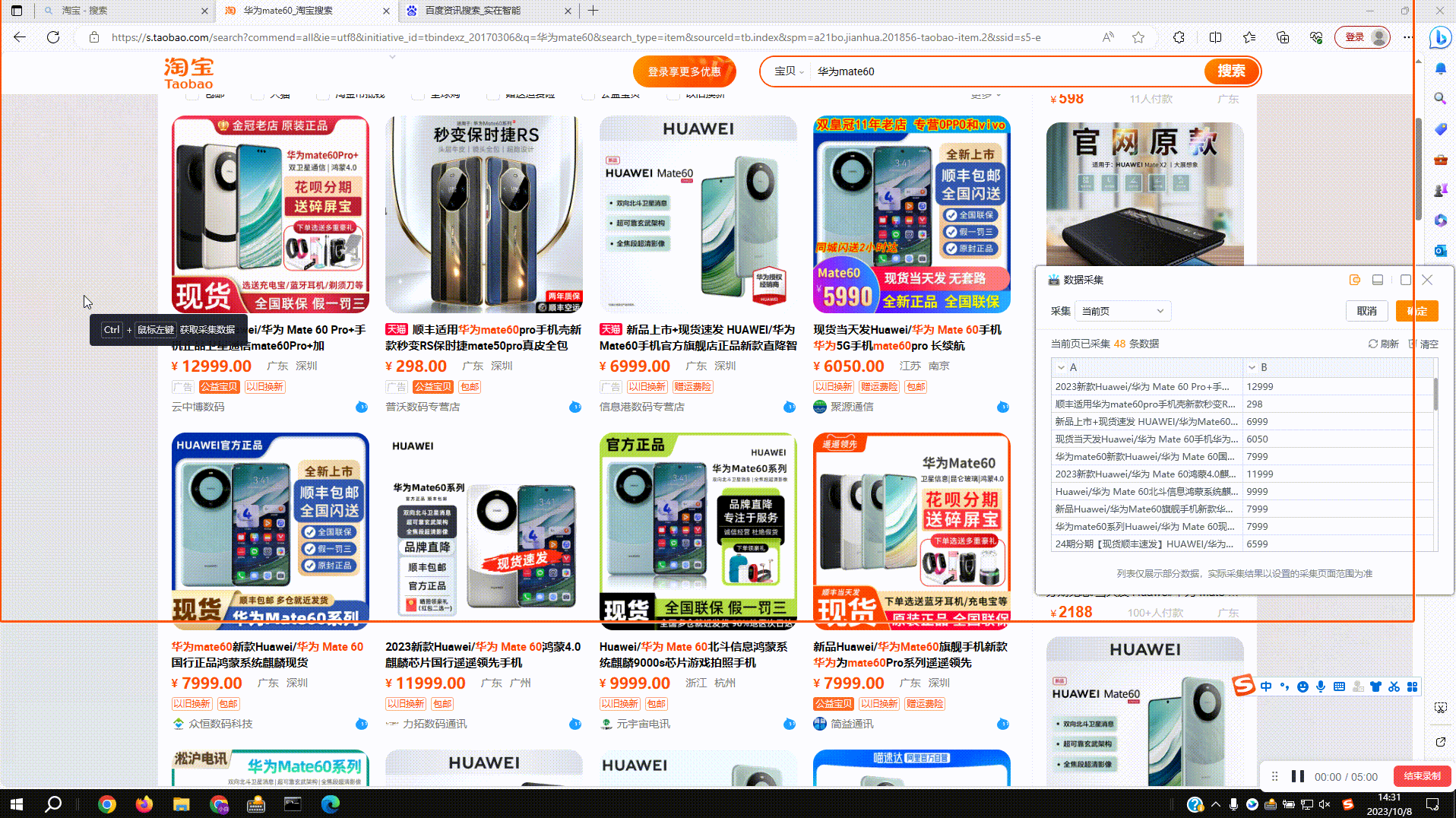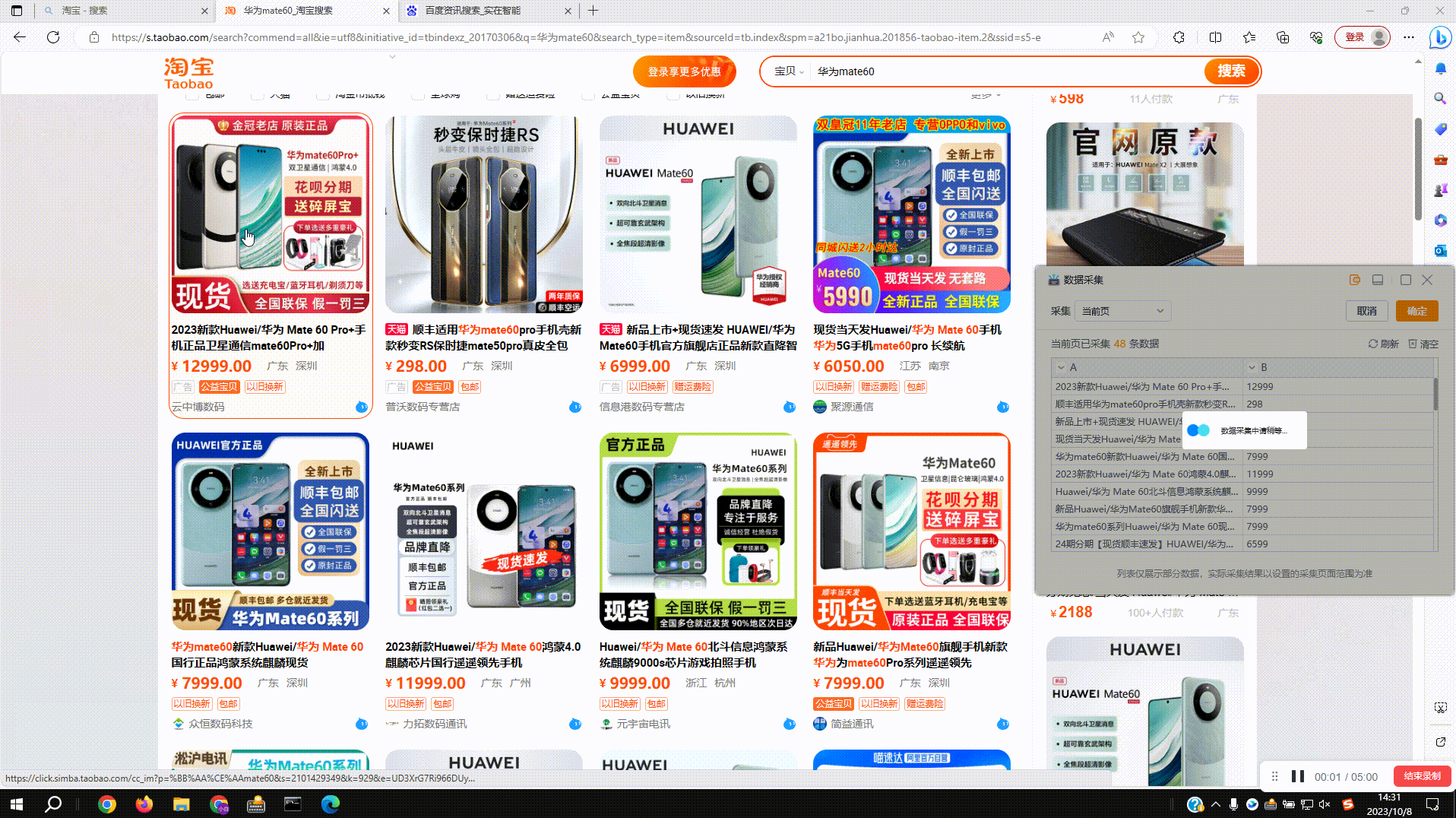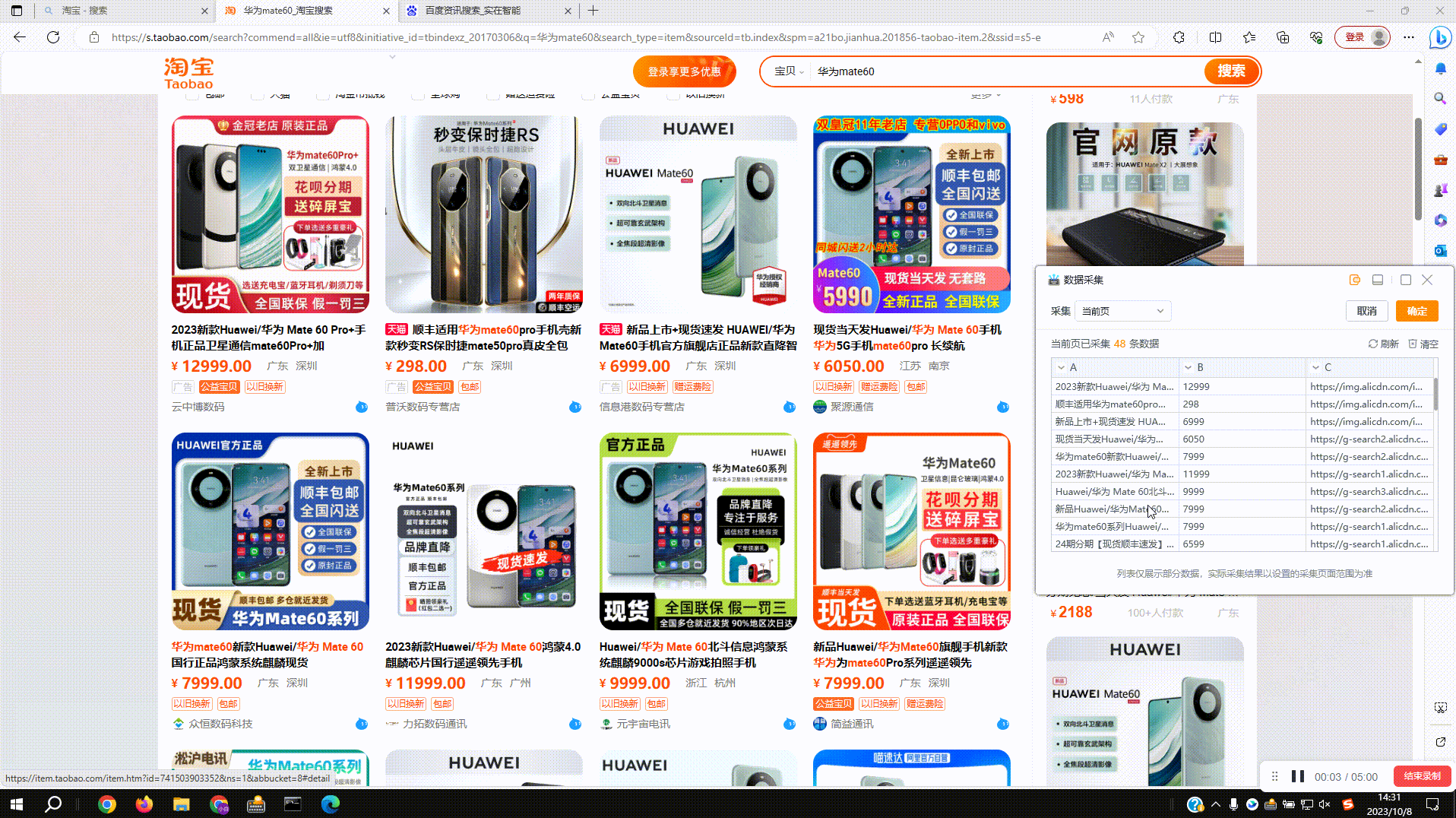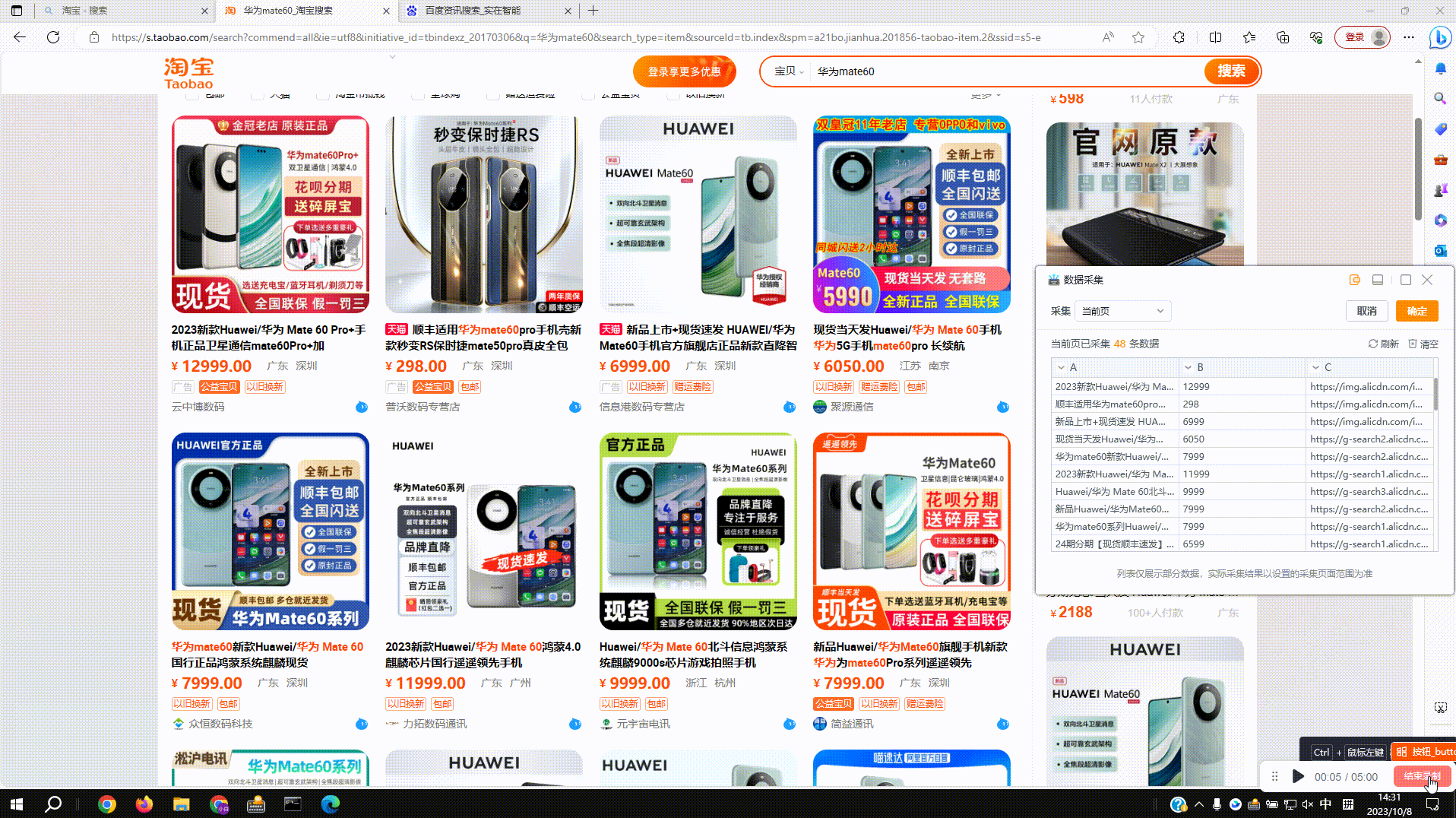
2.1?采集普通网页数据:拾取框选中待拾取的数据,按下Ctrl+右键后采集数据到右侧数据预览窗,再次按下后预览窗新增一列数据
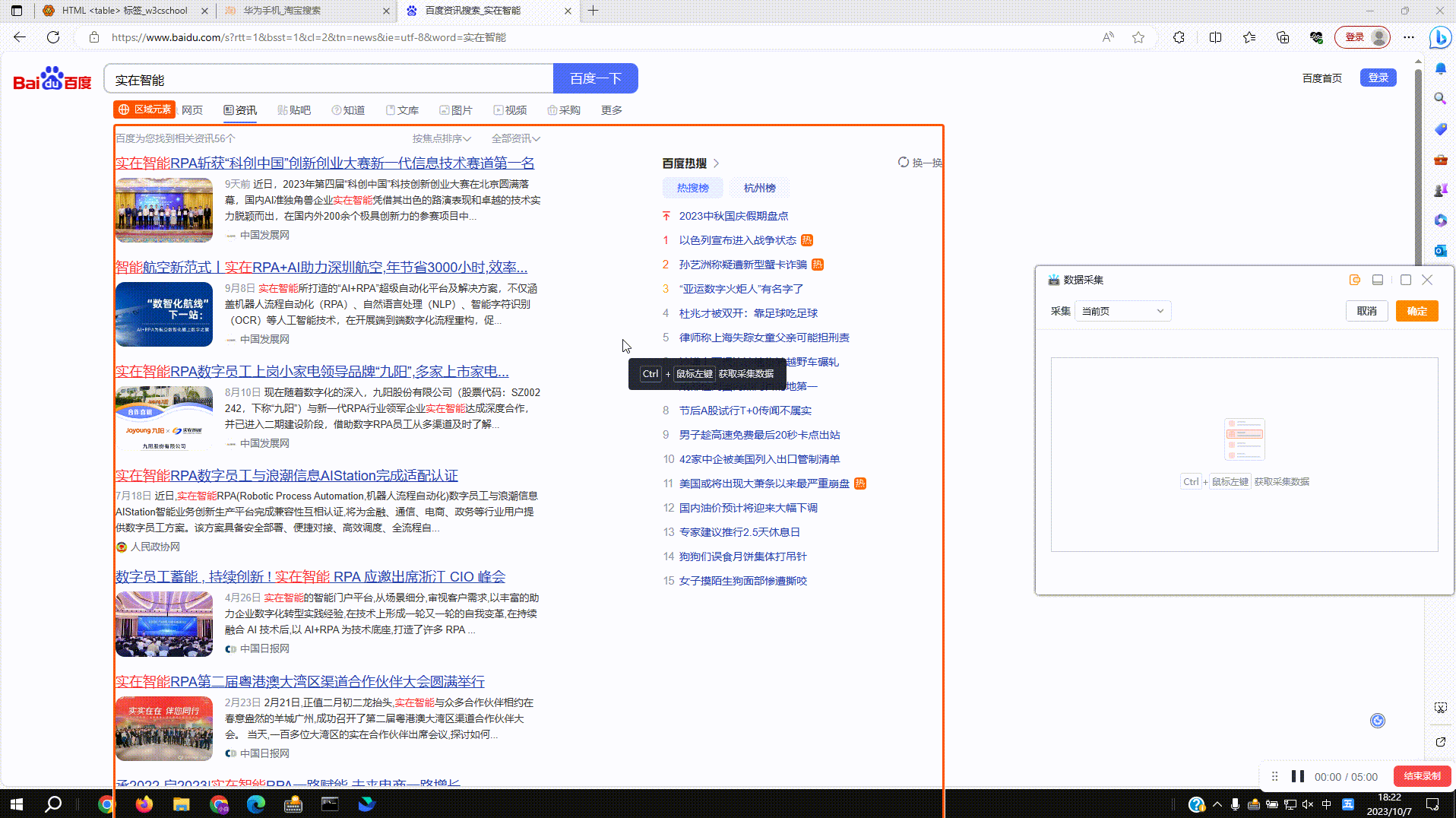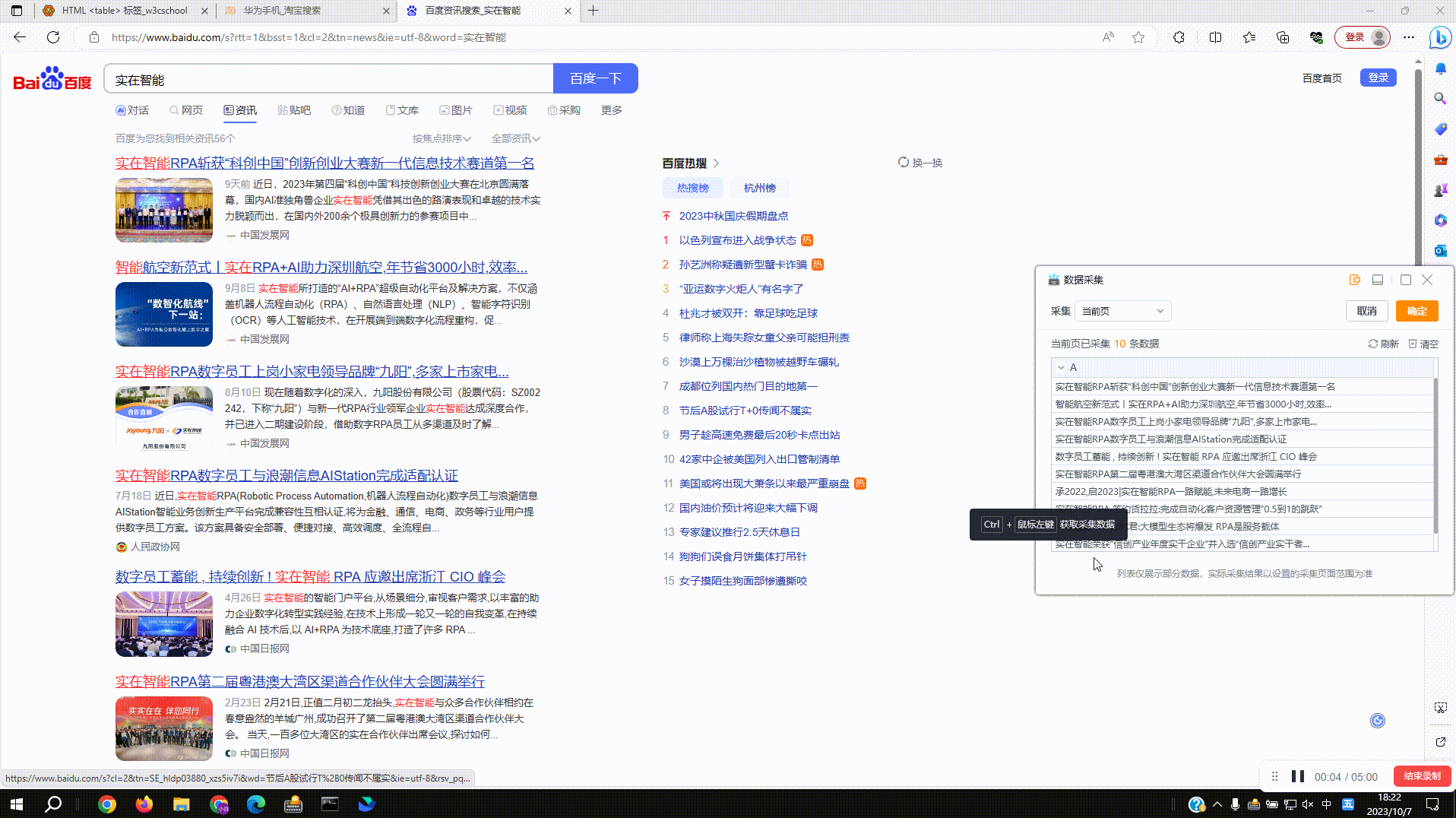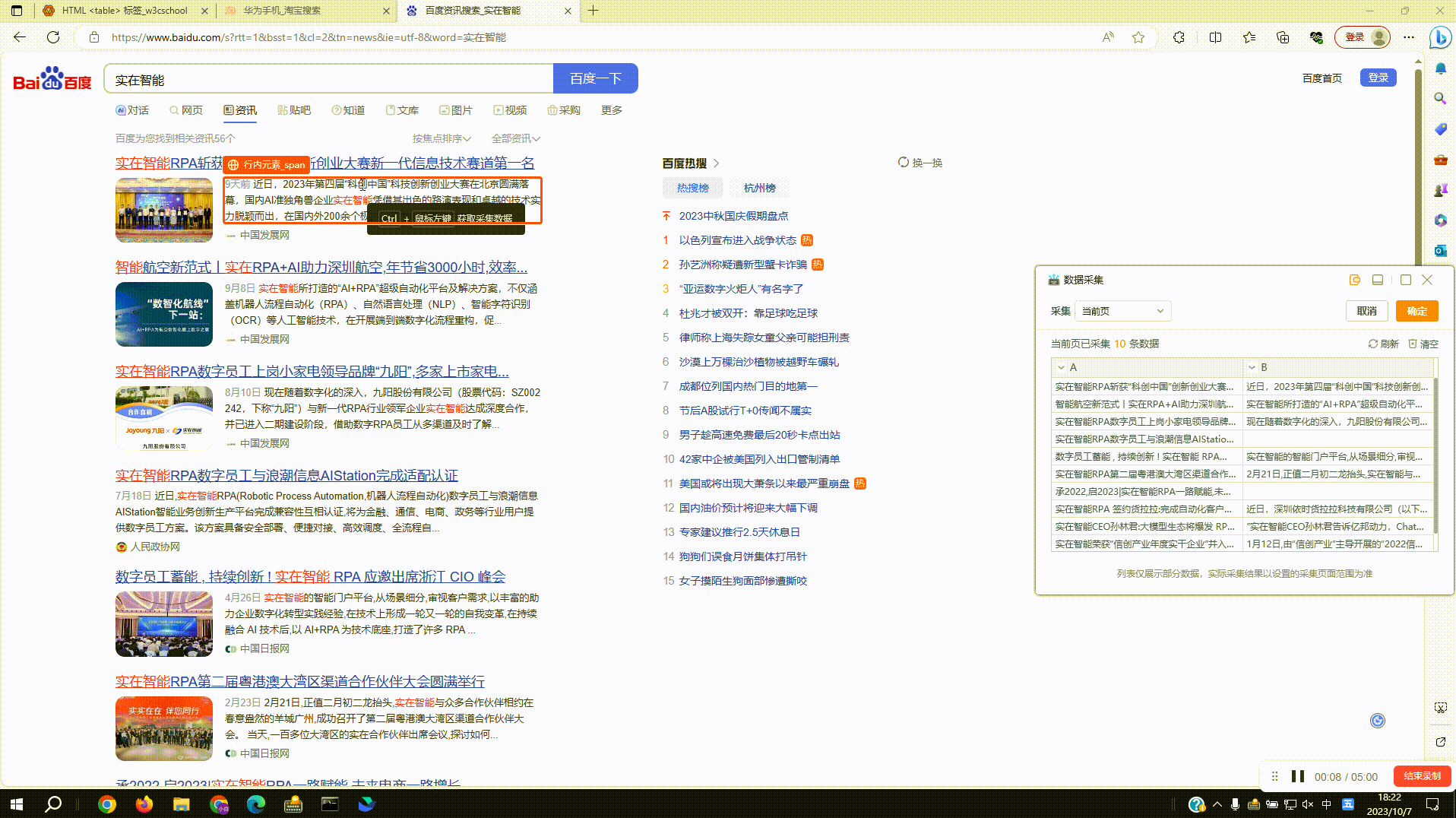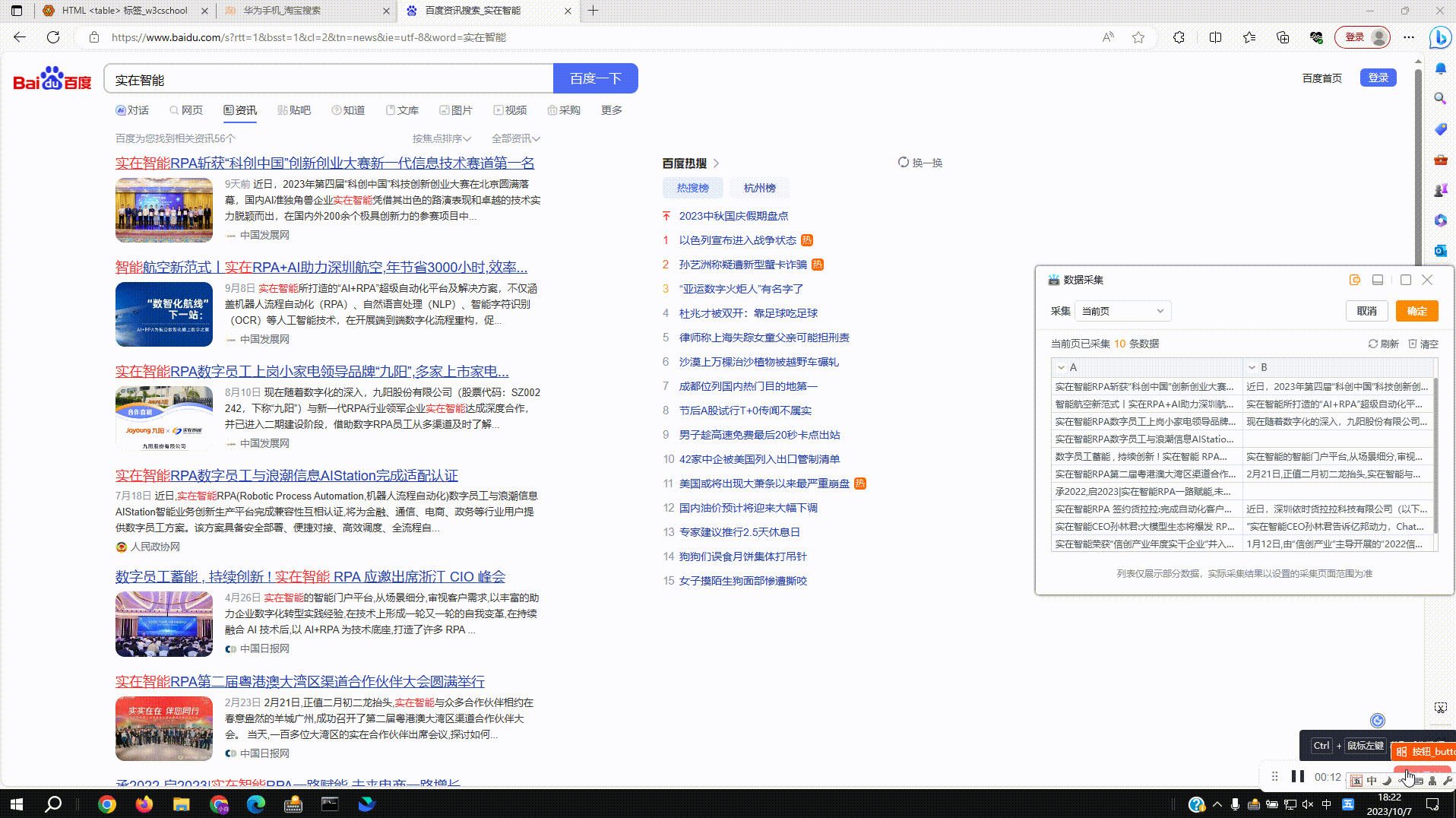
2.2?采集网页表格数据:支持对网页表格数据结构的自动识别,点击确定后即可实现全表数据的采集,点击取消后仍按单列来采集,同2.1
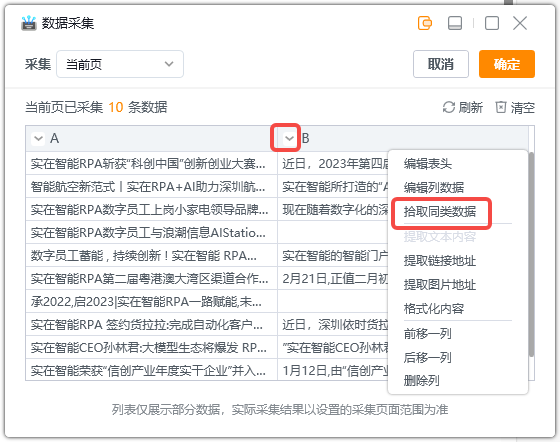
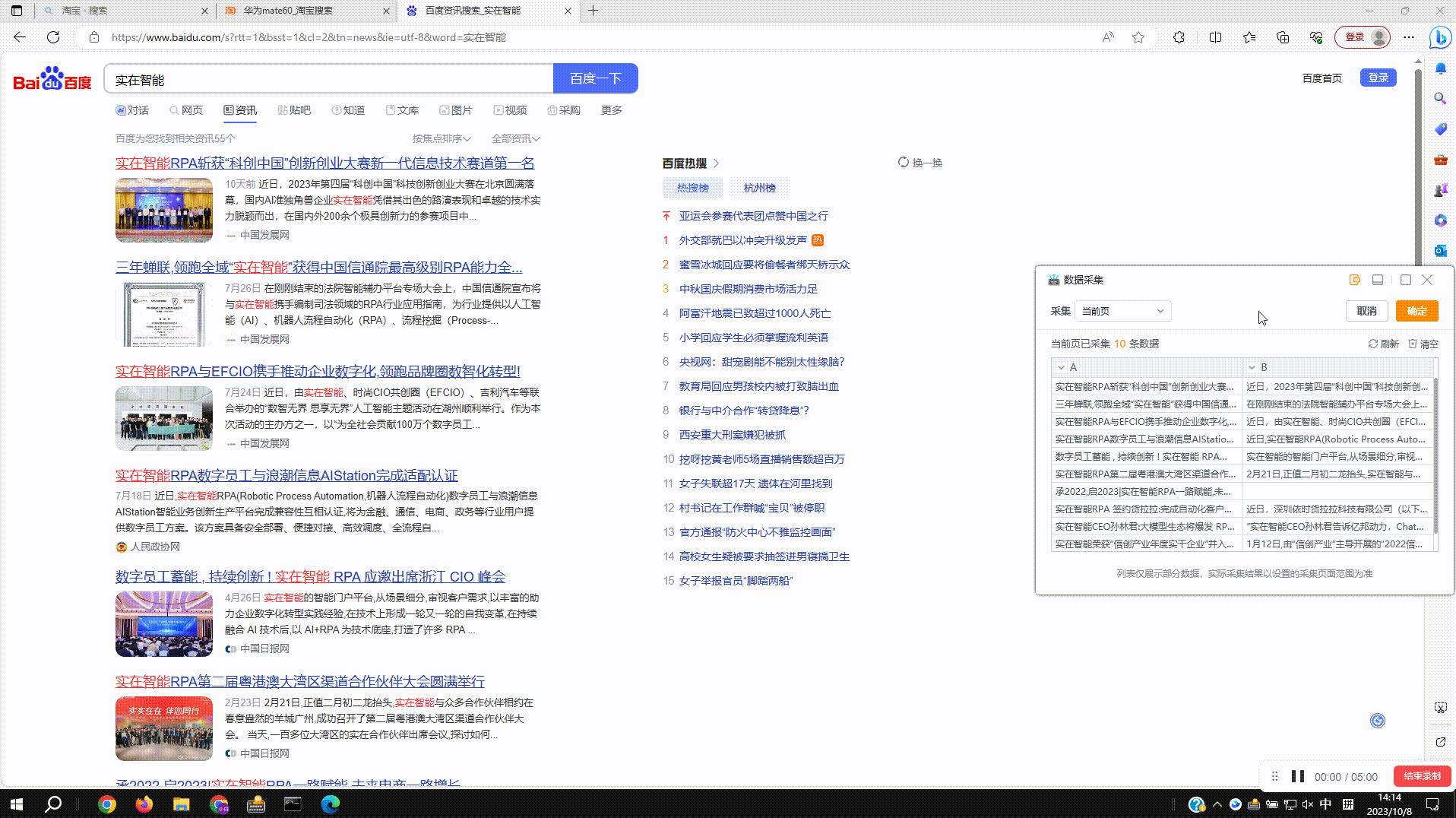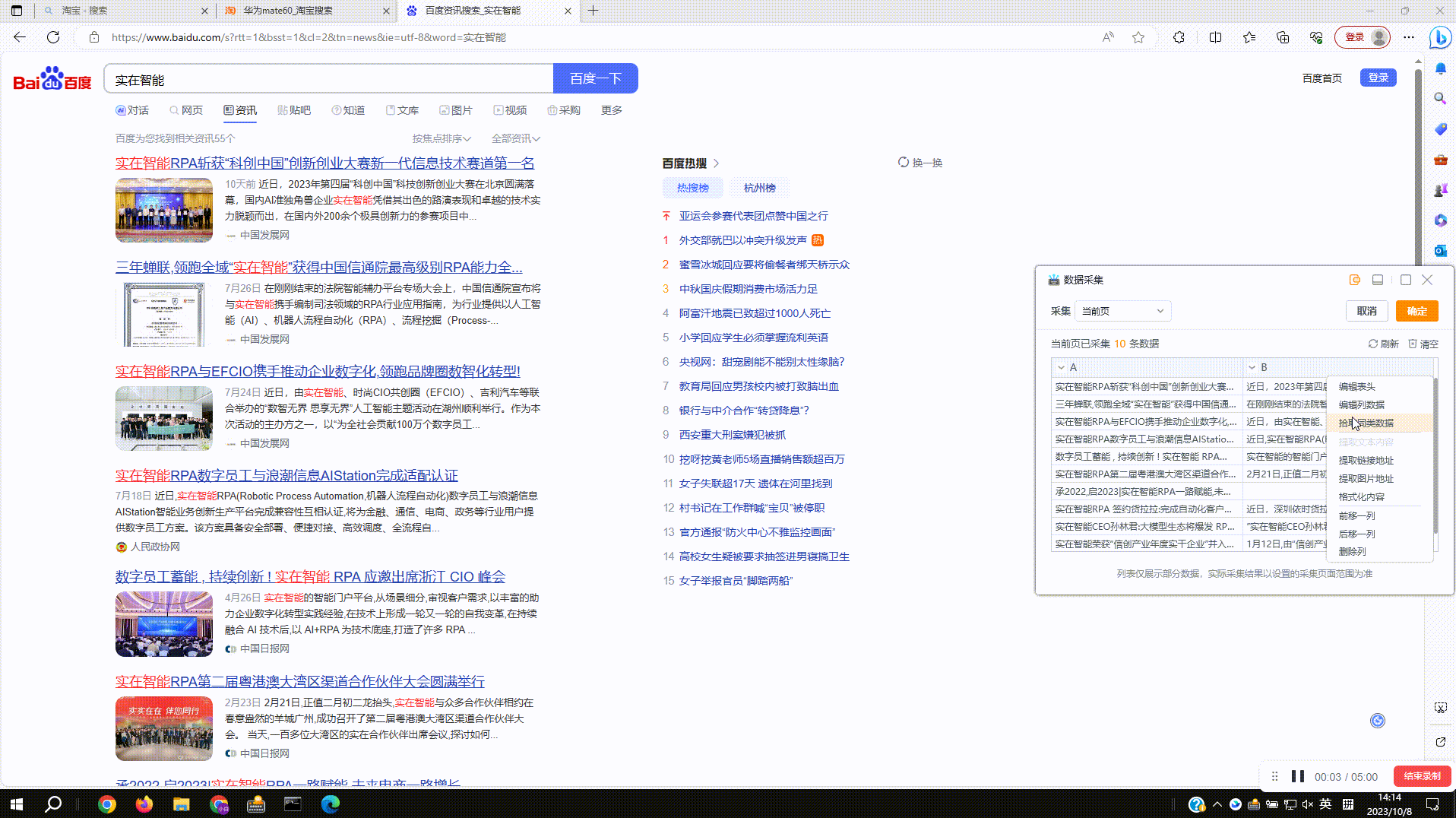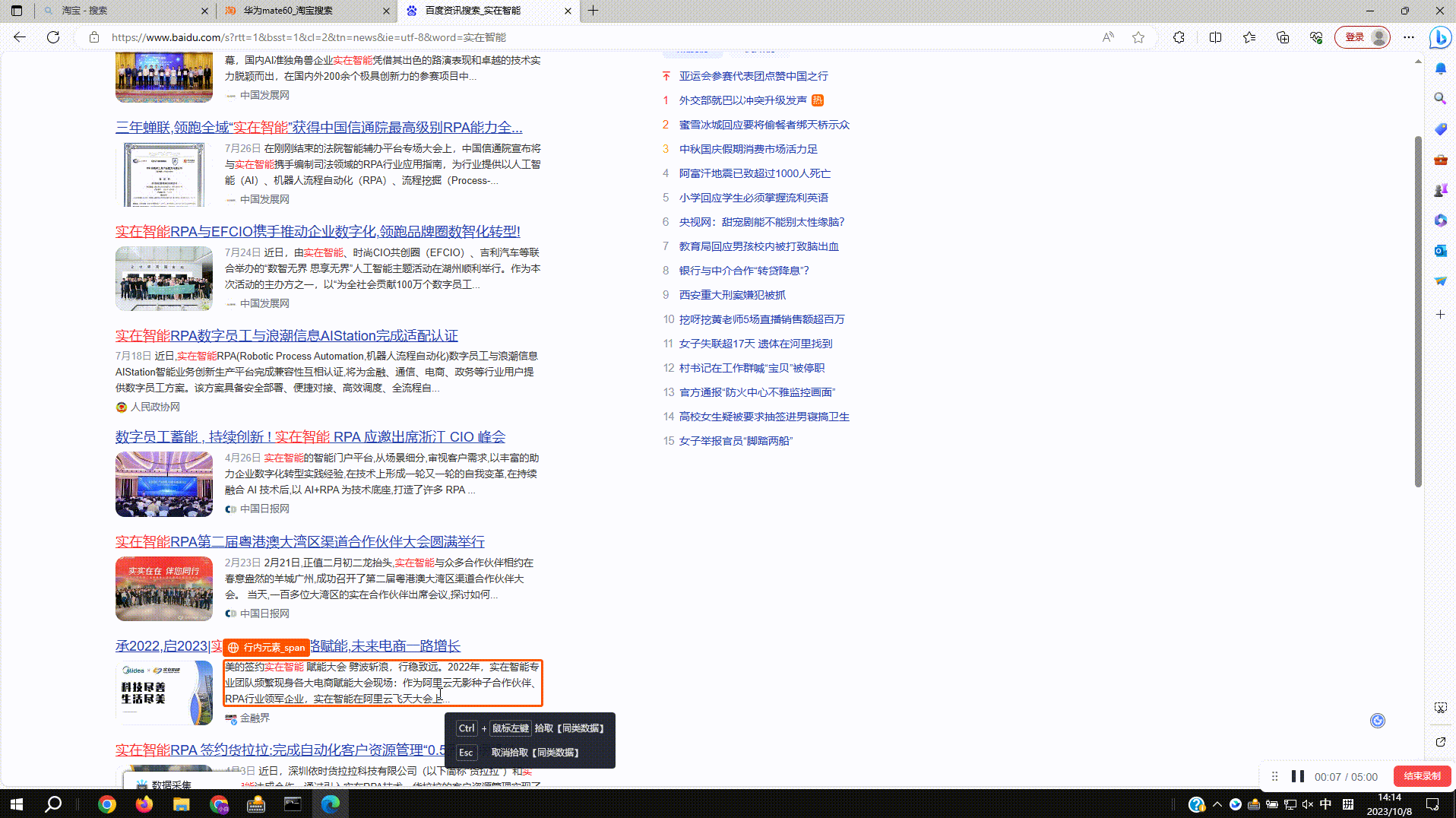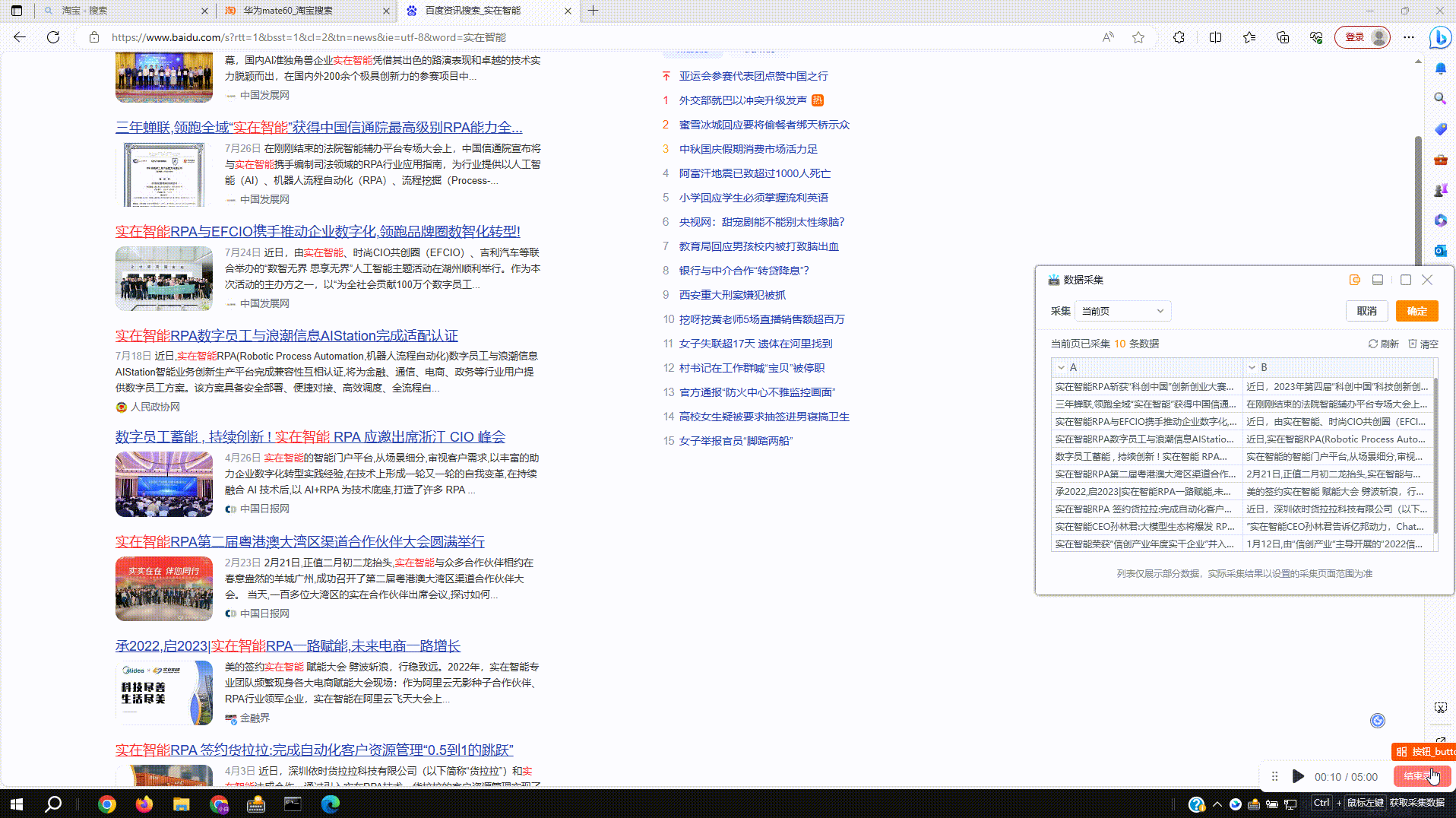
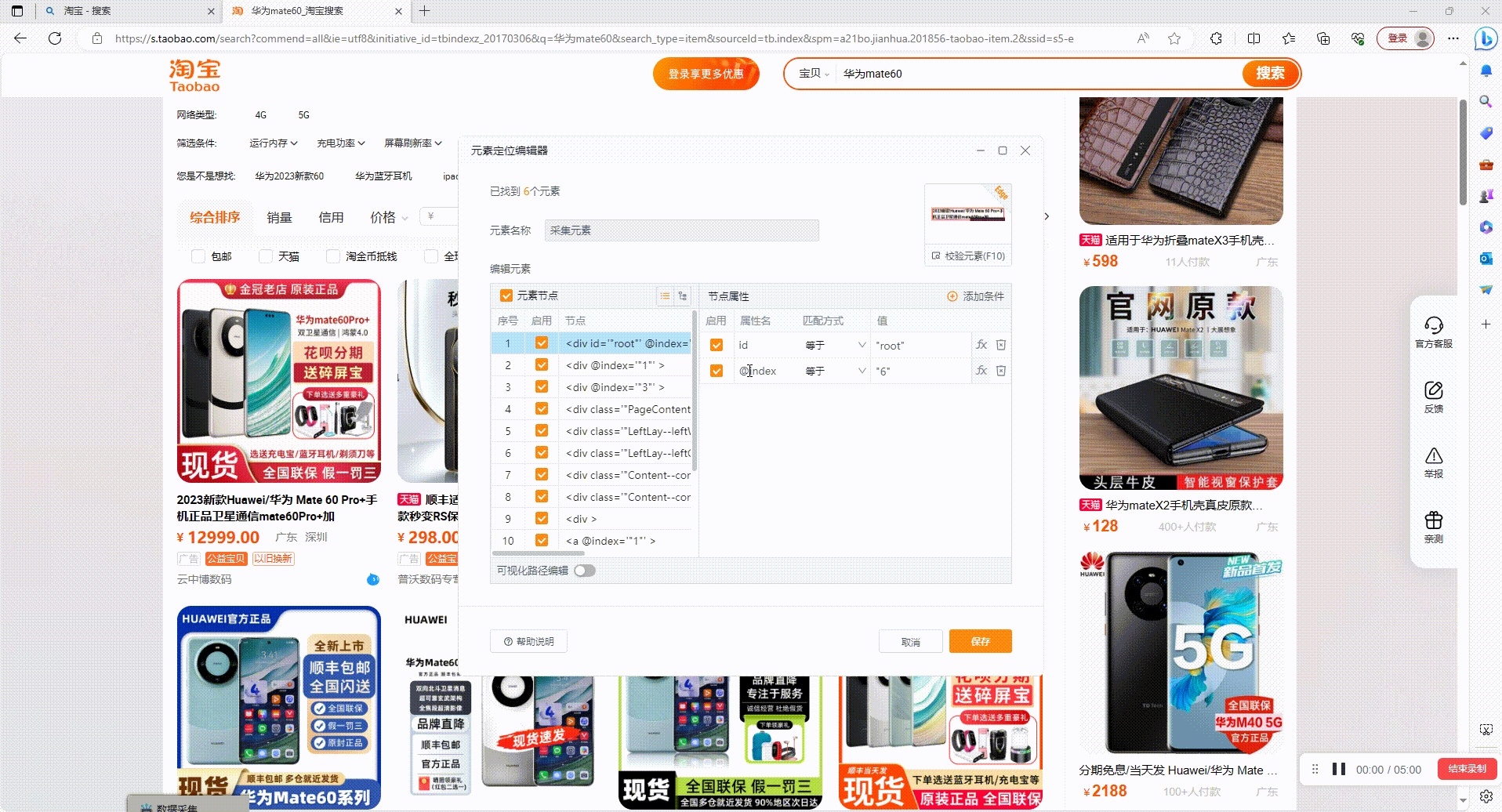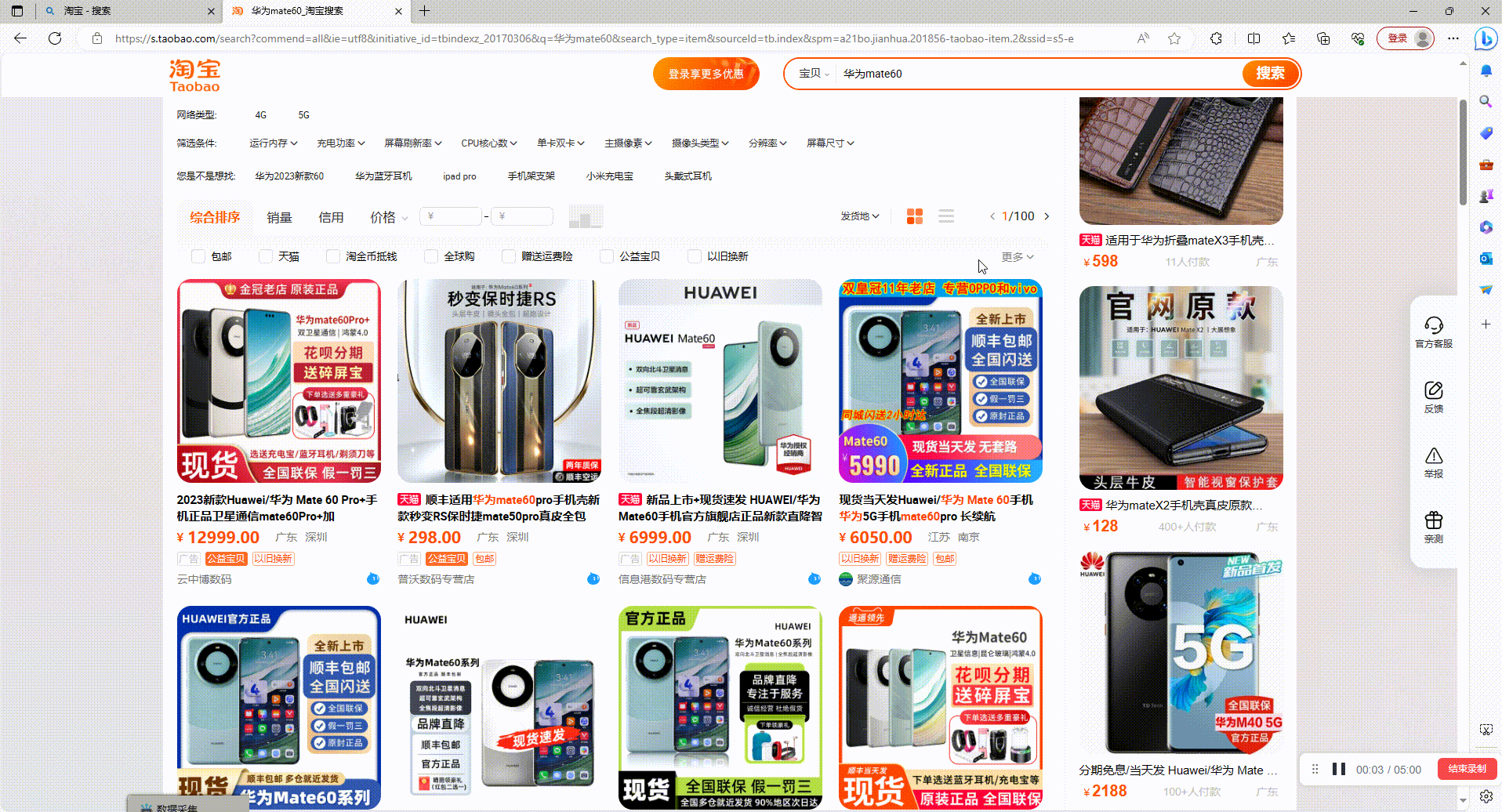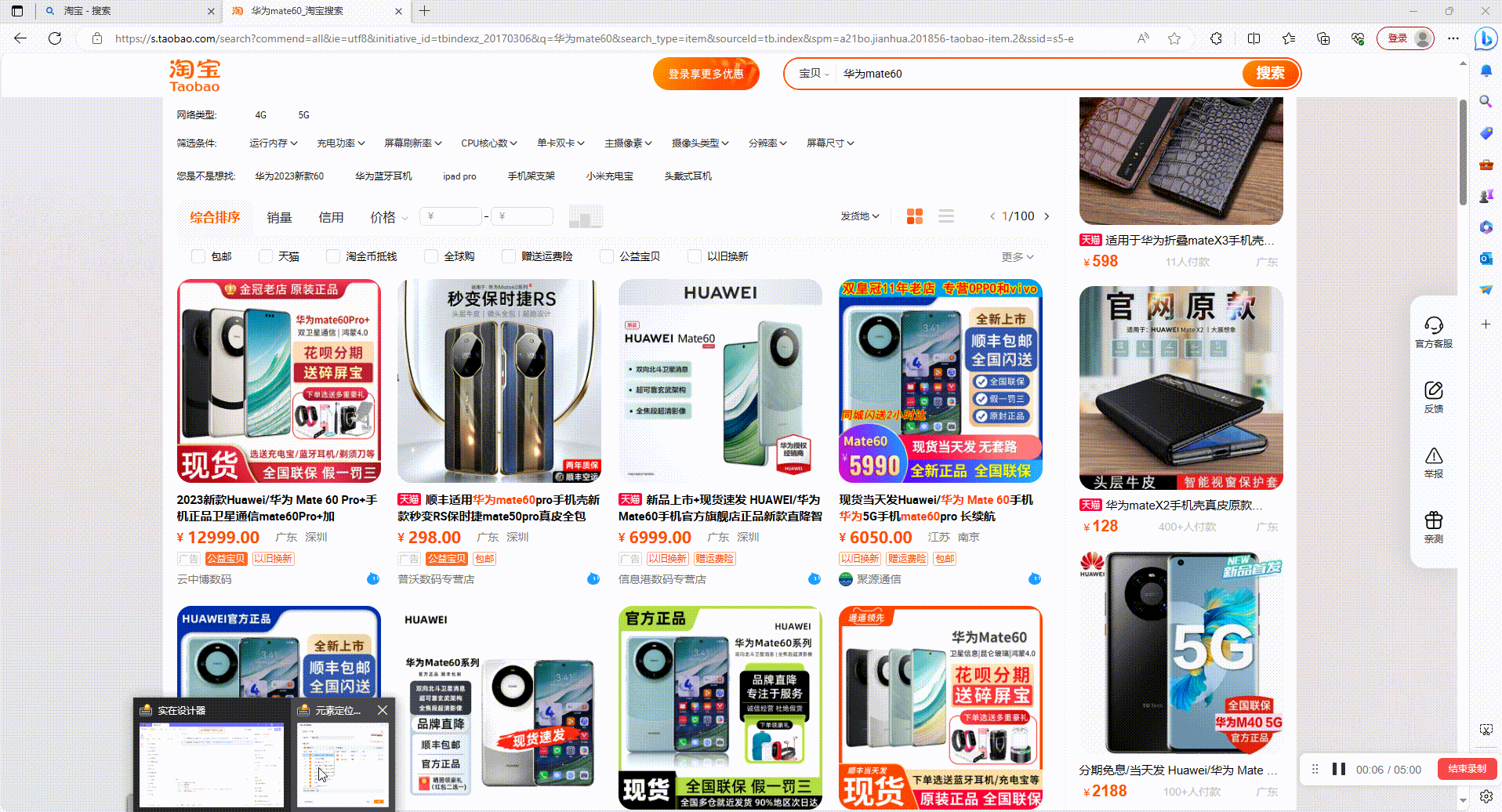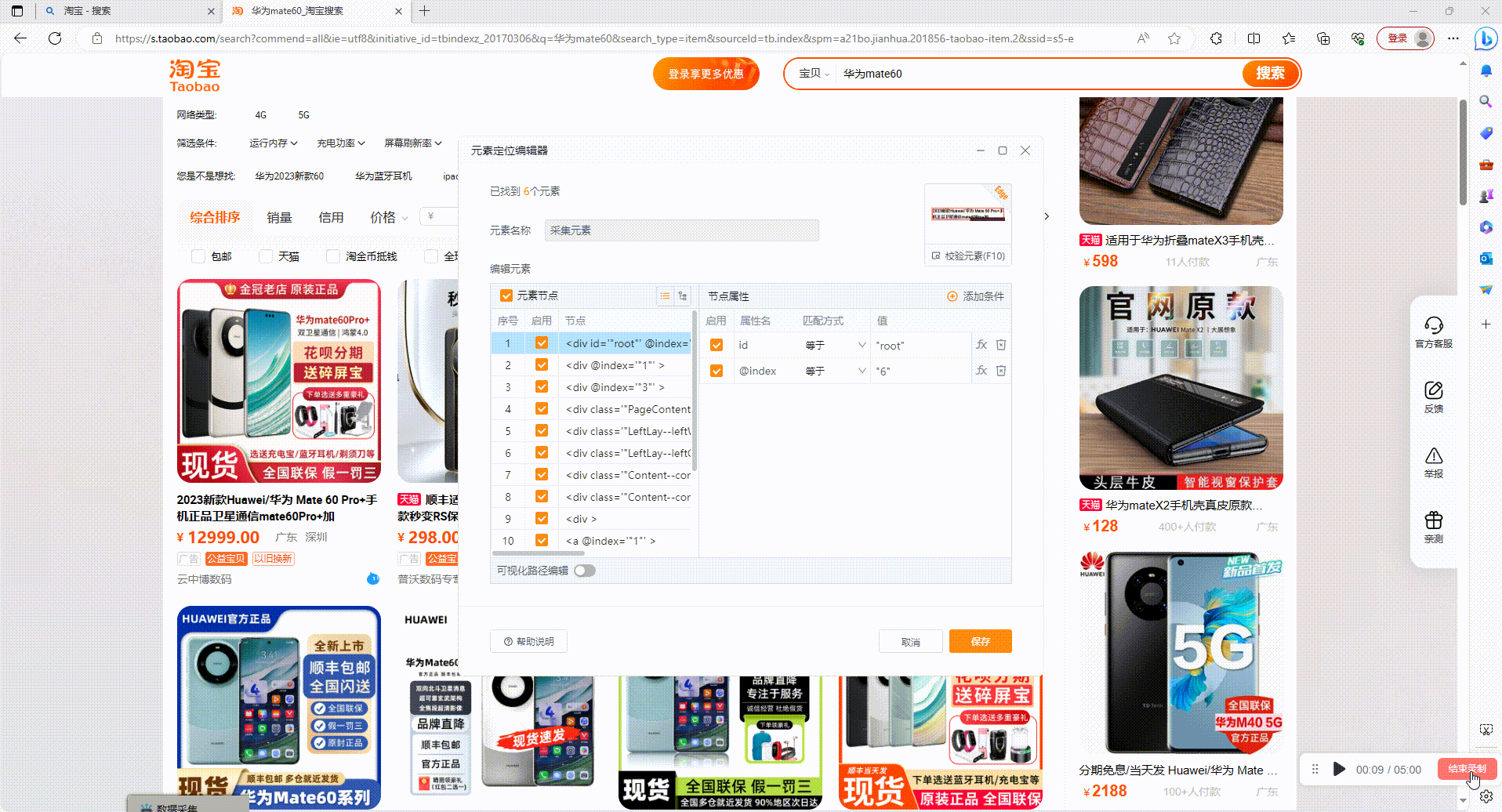
2.3?拾取同类数据:由于各种网页上的数据结构参差不齐,采集数据时如出现缺失的情况,可以使用拾取同类数据功能进行补齐。如图,点击缺失列的下拉菜单,选择拾取同类数据进行操作
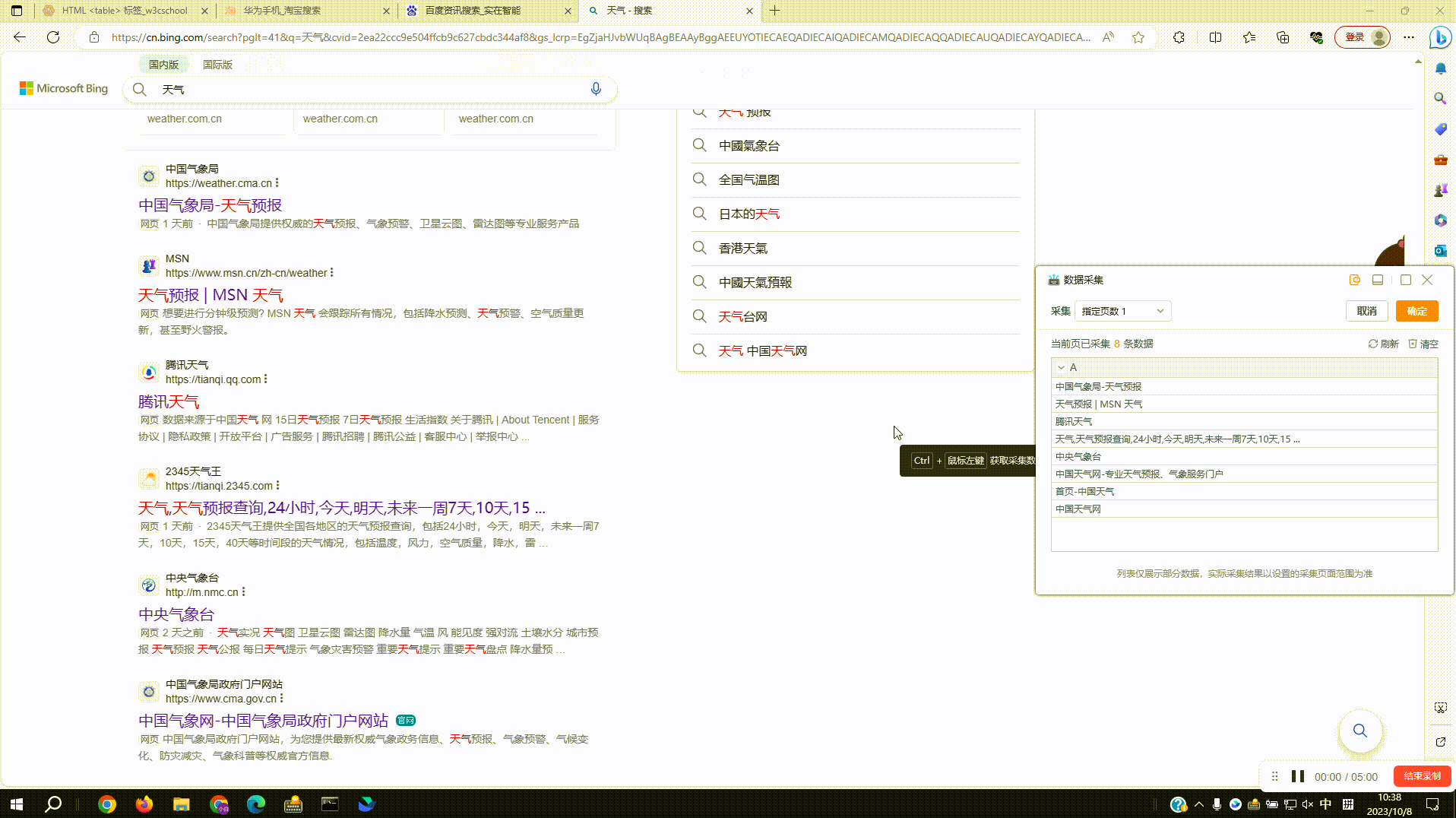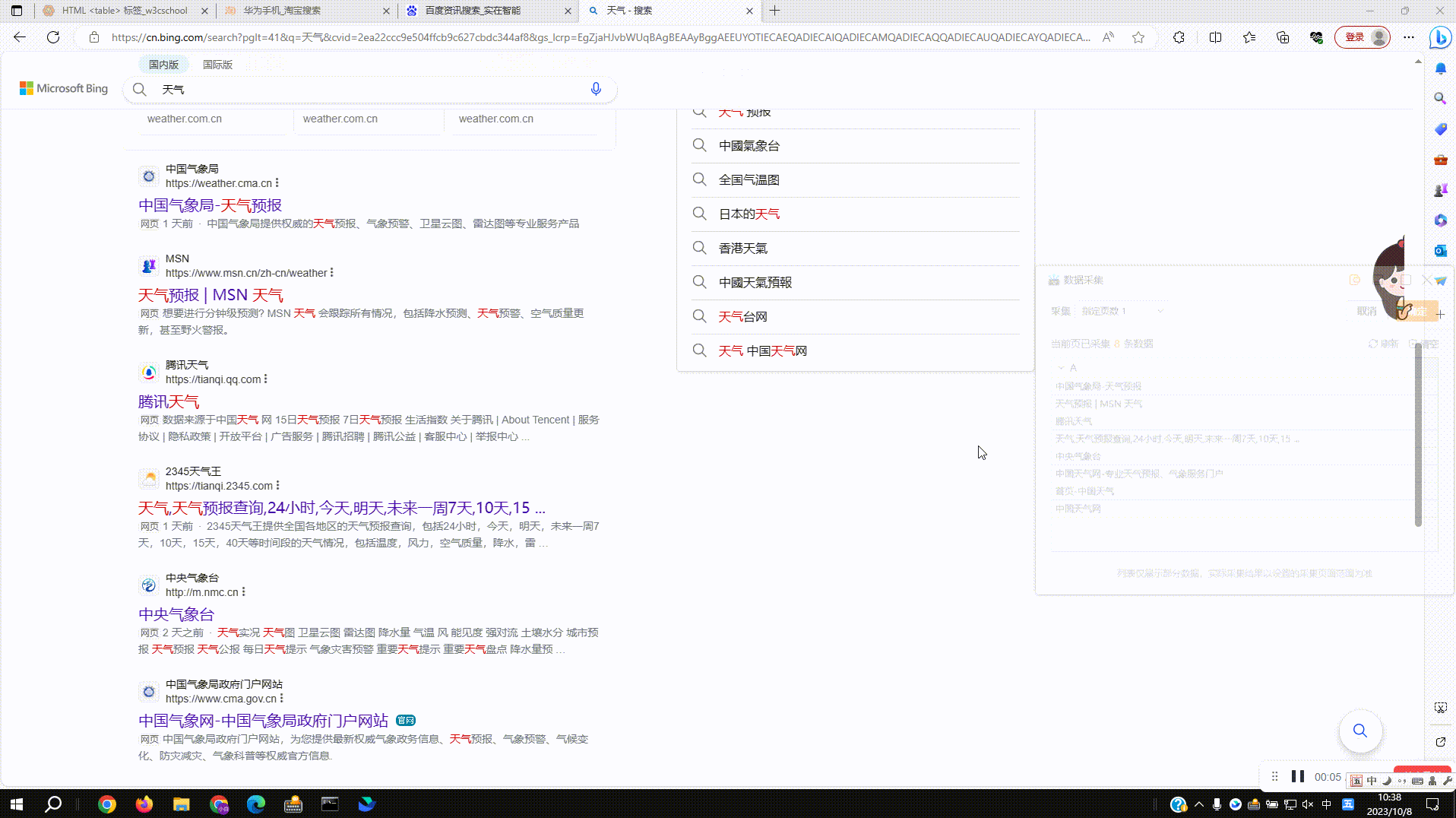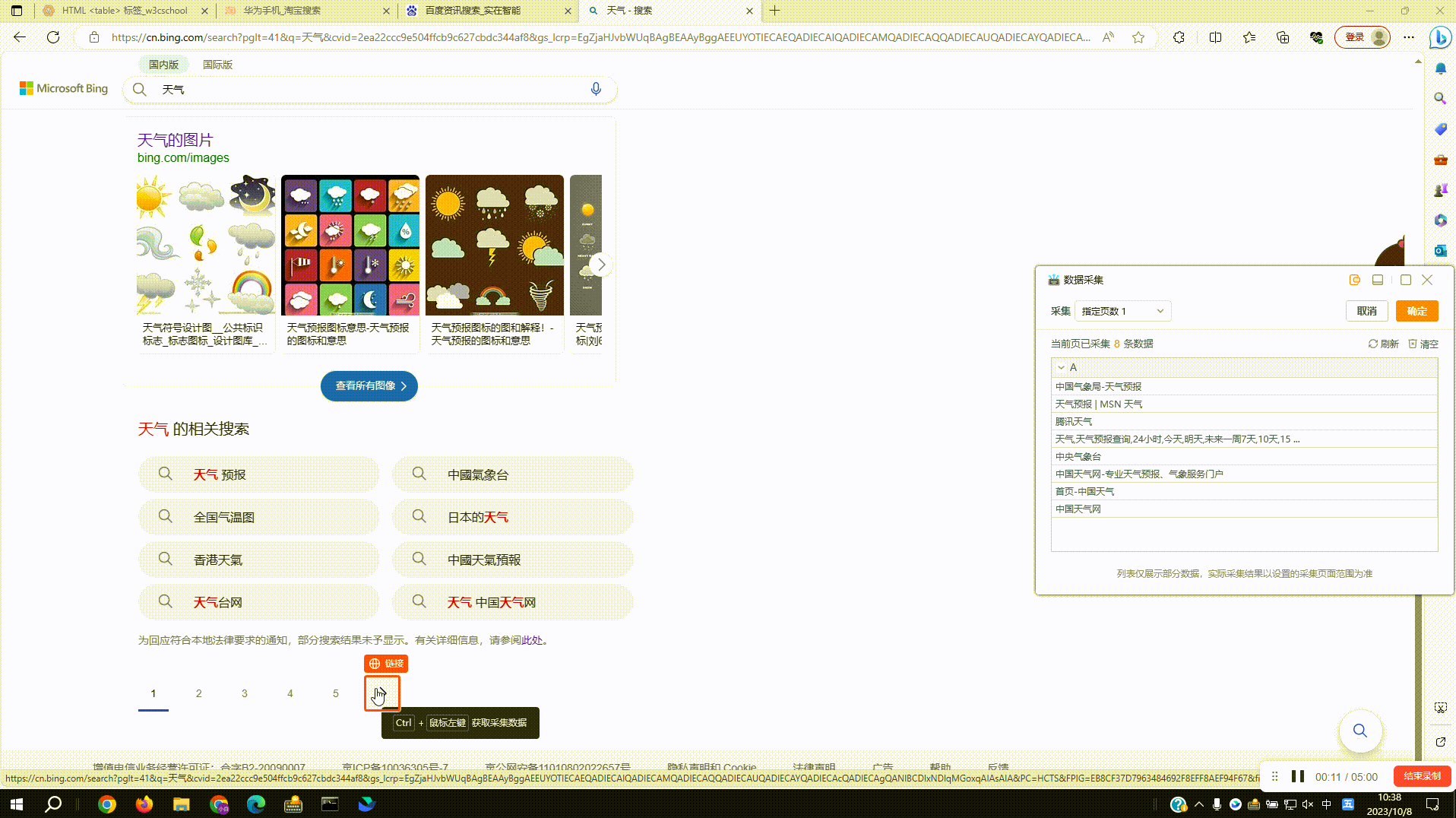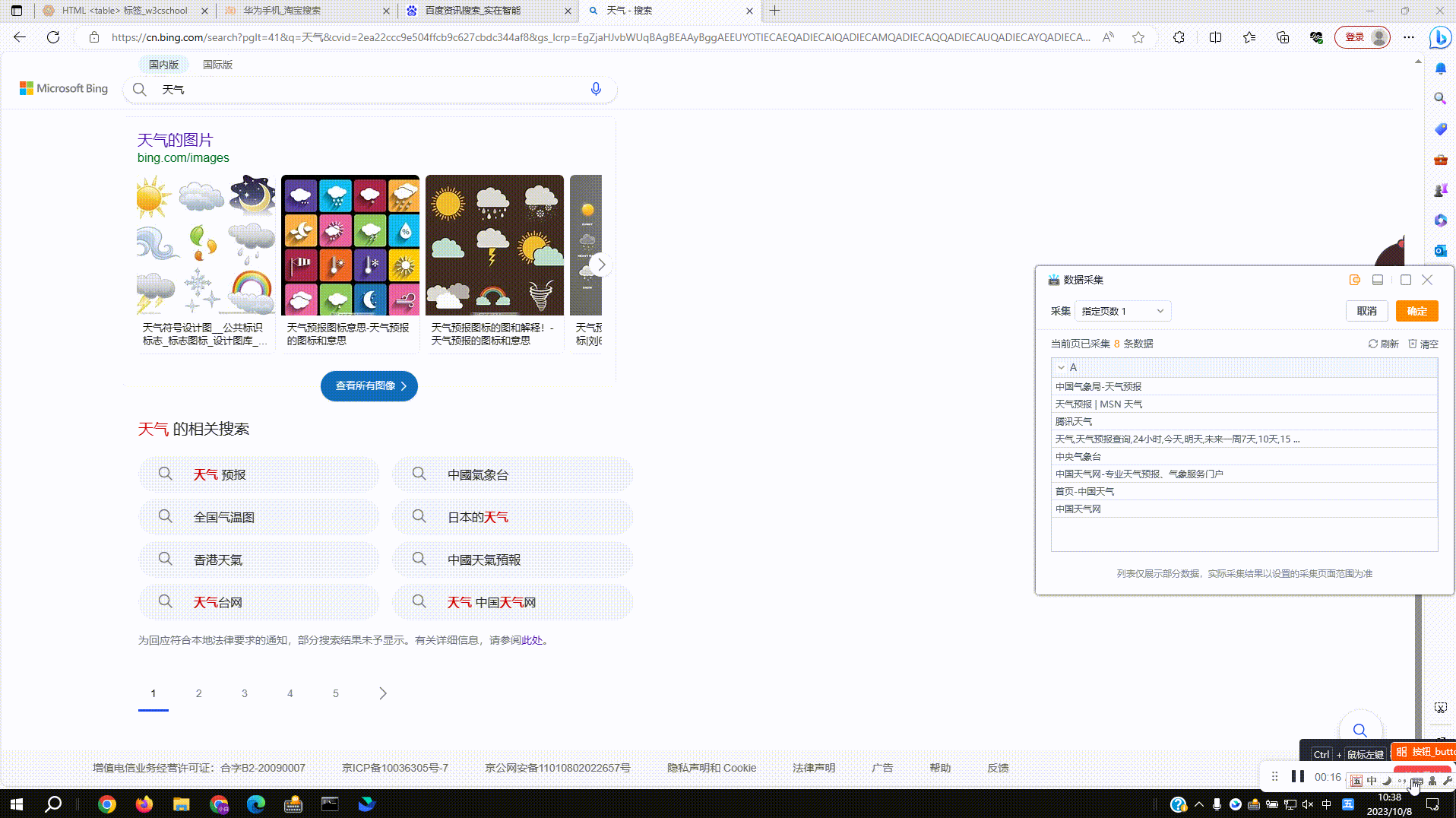
2.4?采集翻页按钮:实际采集场景中往往会采集很多页数据,配置采集规则时组件会基于一定规则自动拾取翻页按钮,如没有拾取到翻页按钮,则需要手动进行拾取
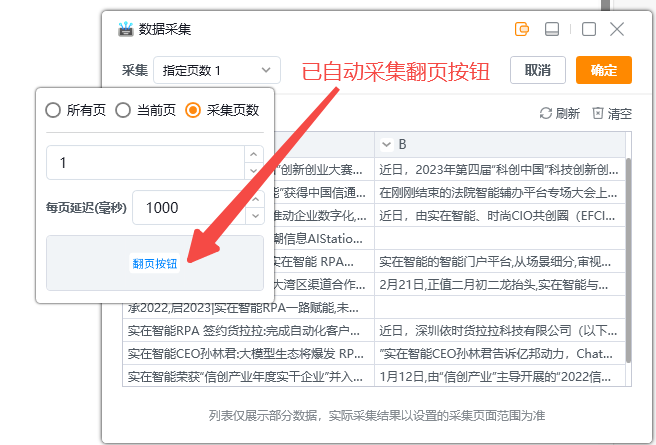
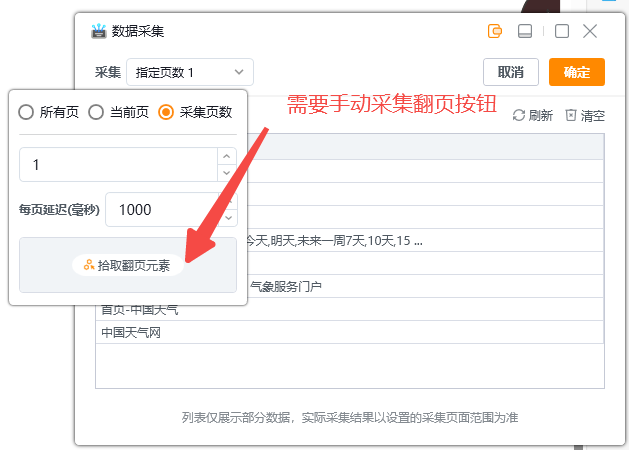
手动采集翻页按钮操作如下图:
2.5?保存采集配置:配置好采集规则后点击预览表右上角确定按钮,完成采集配置并自动添加网页对象组件
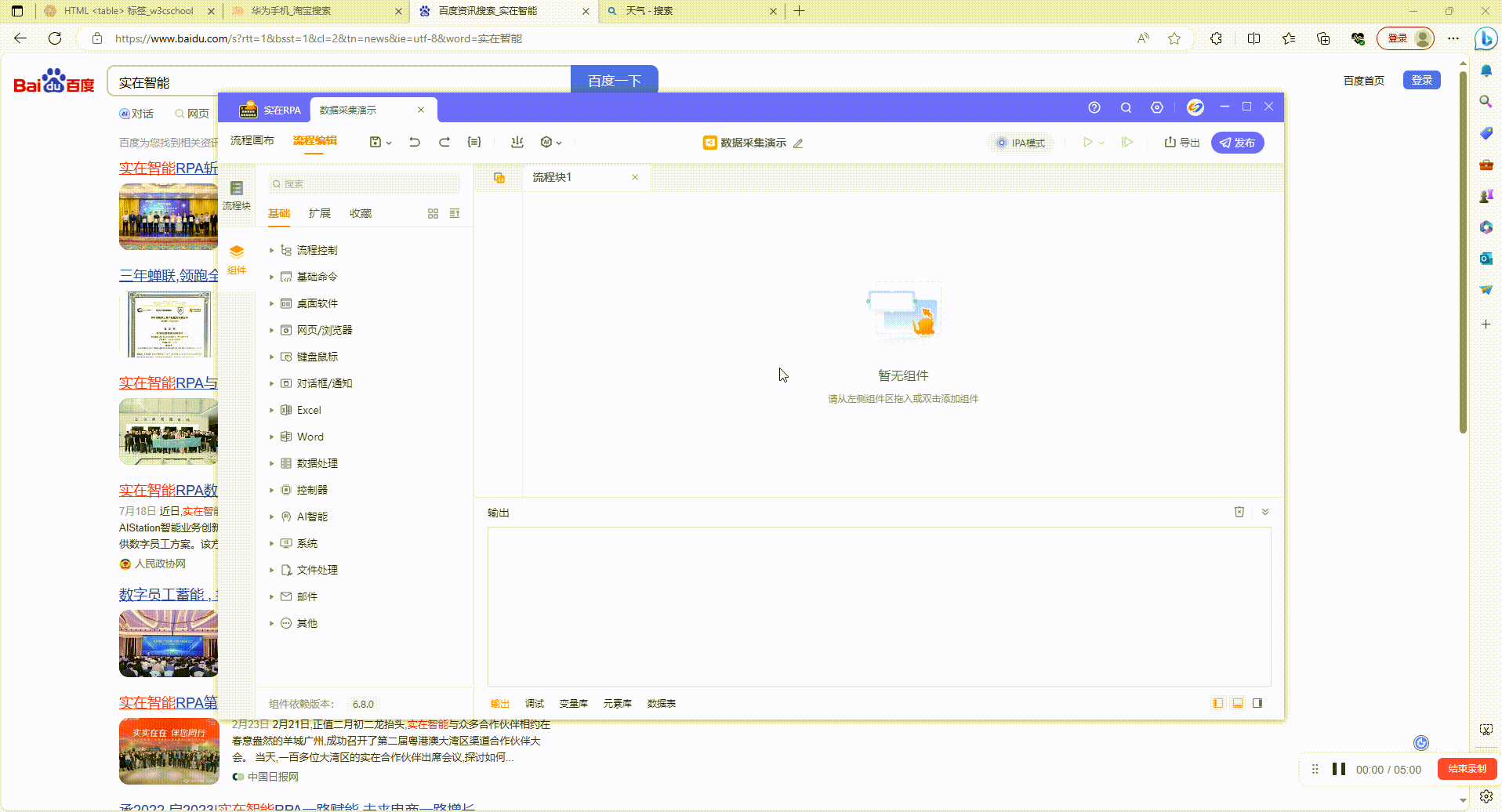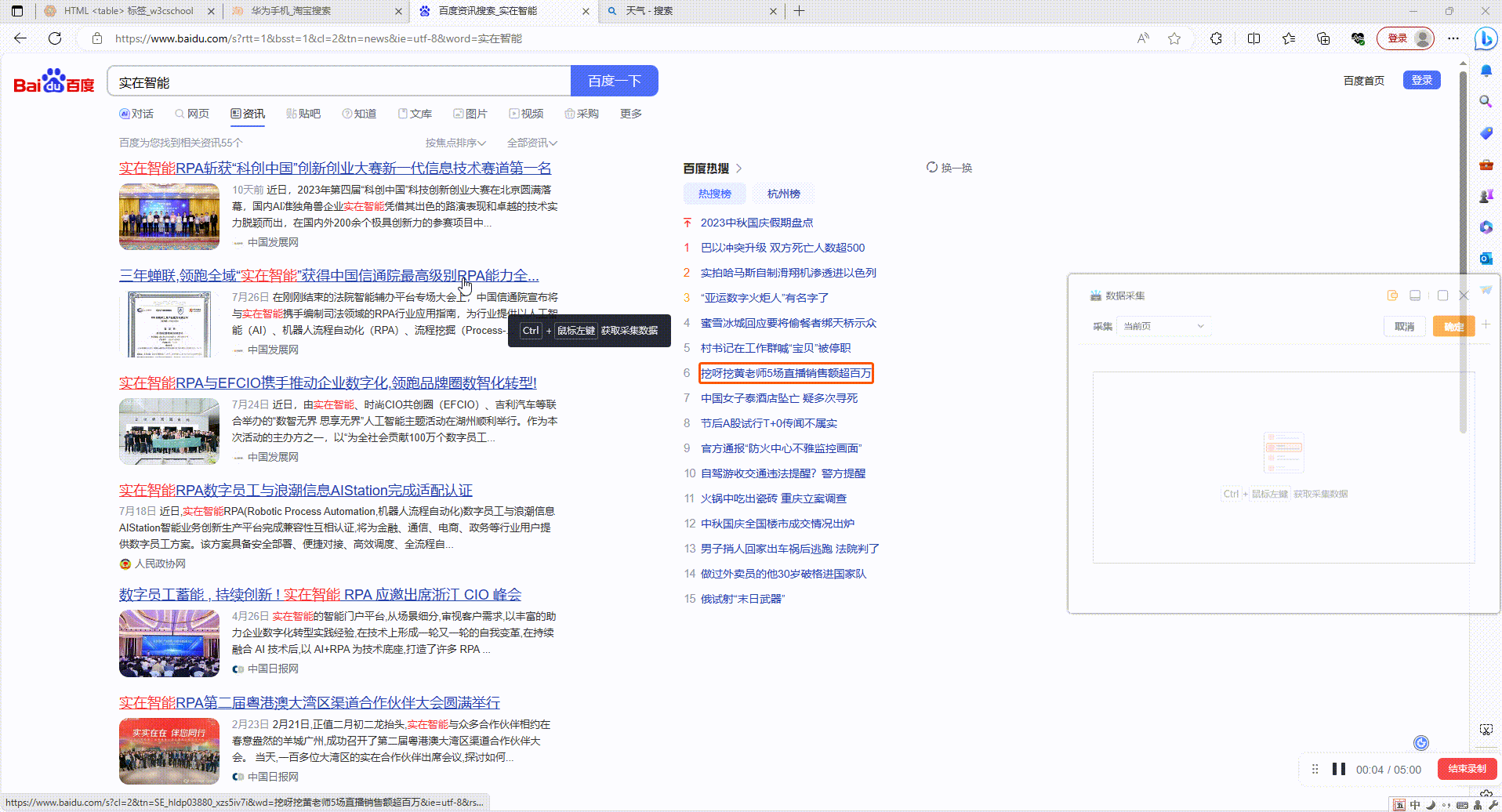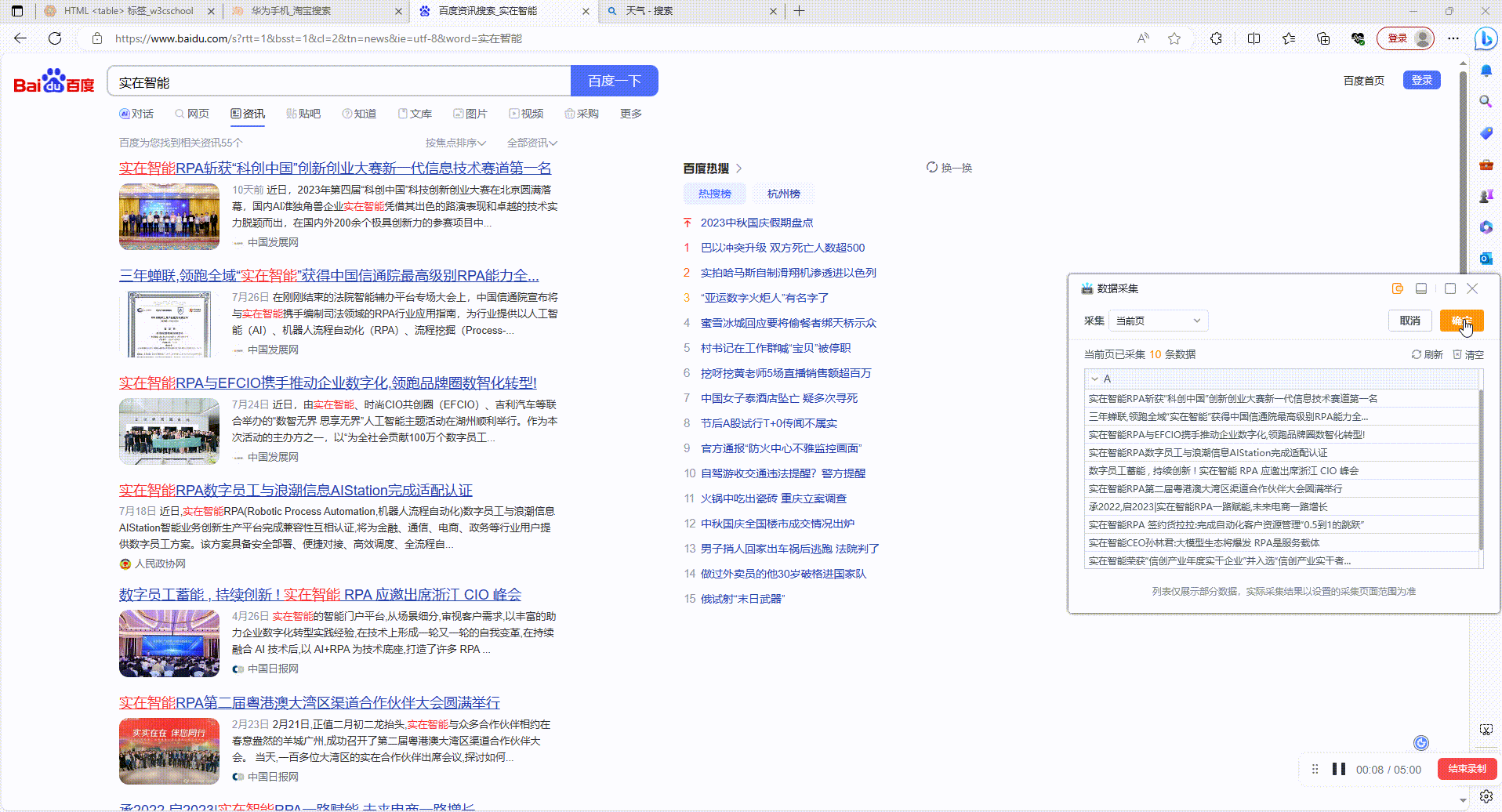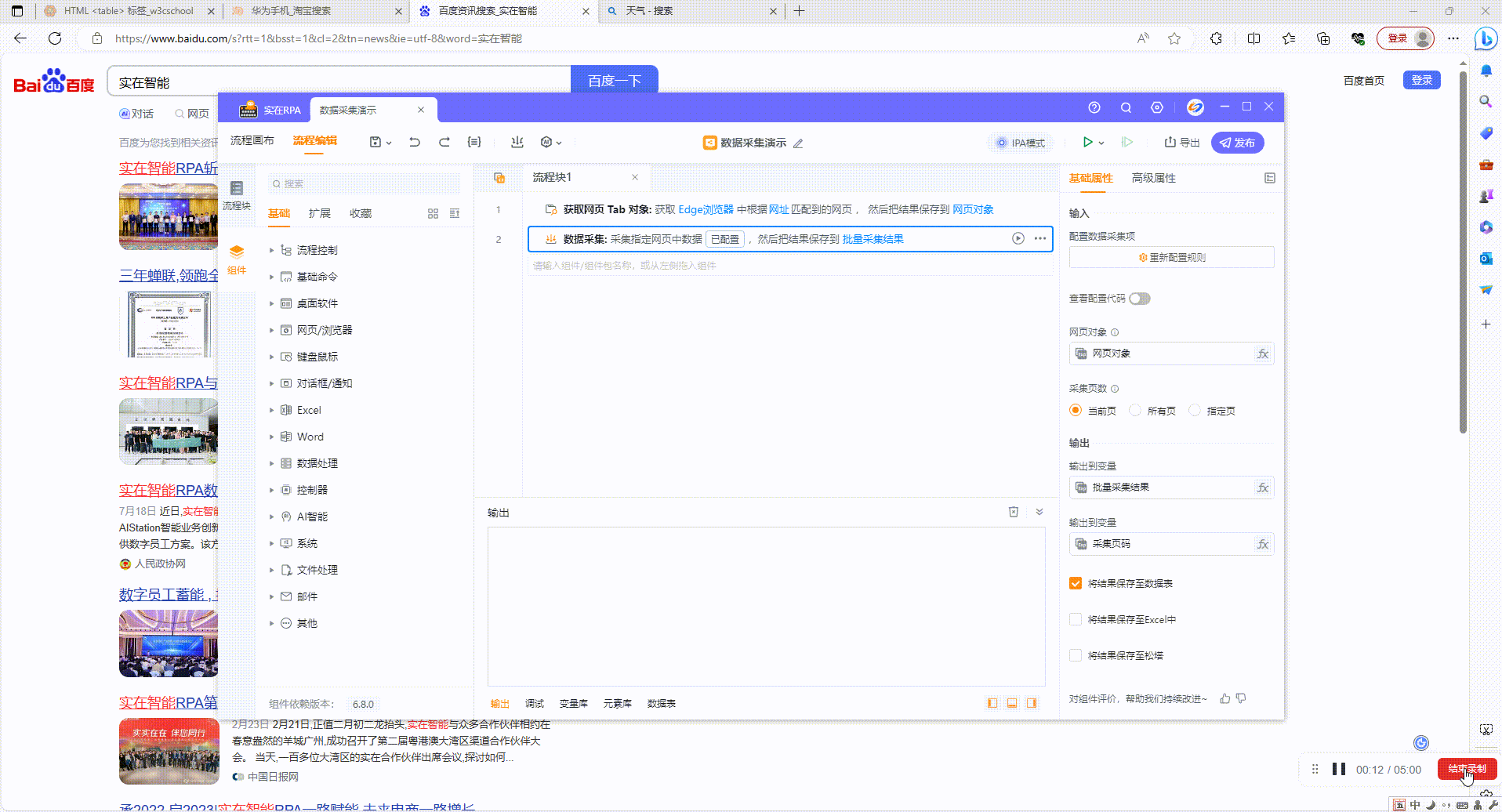
运行
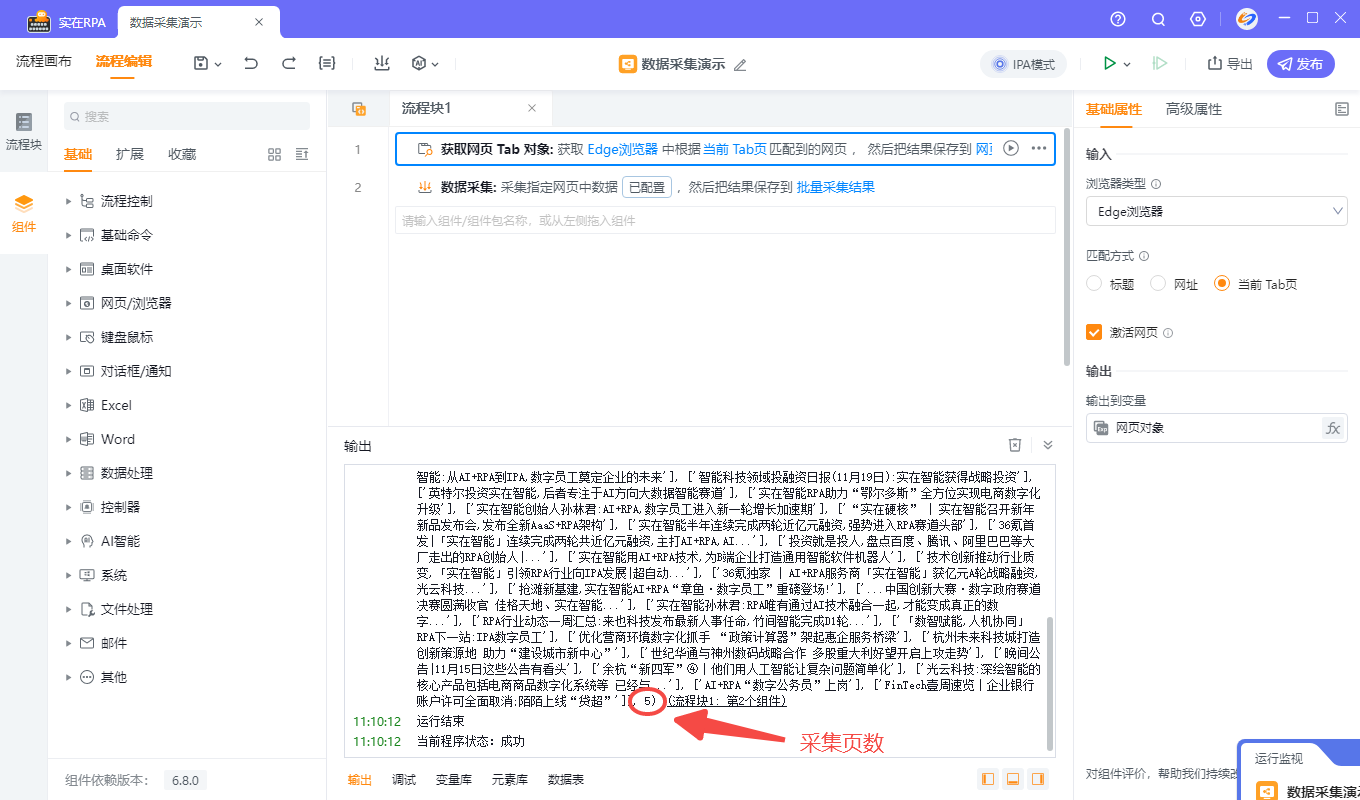
3.1?运行组件:如图设置采集5页内容,运行后根据设置页数进行采集
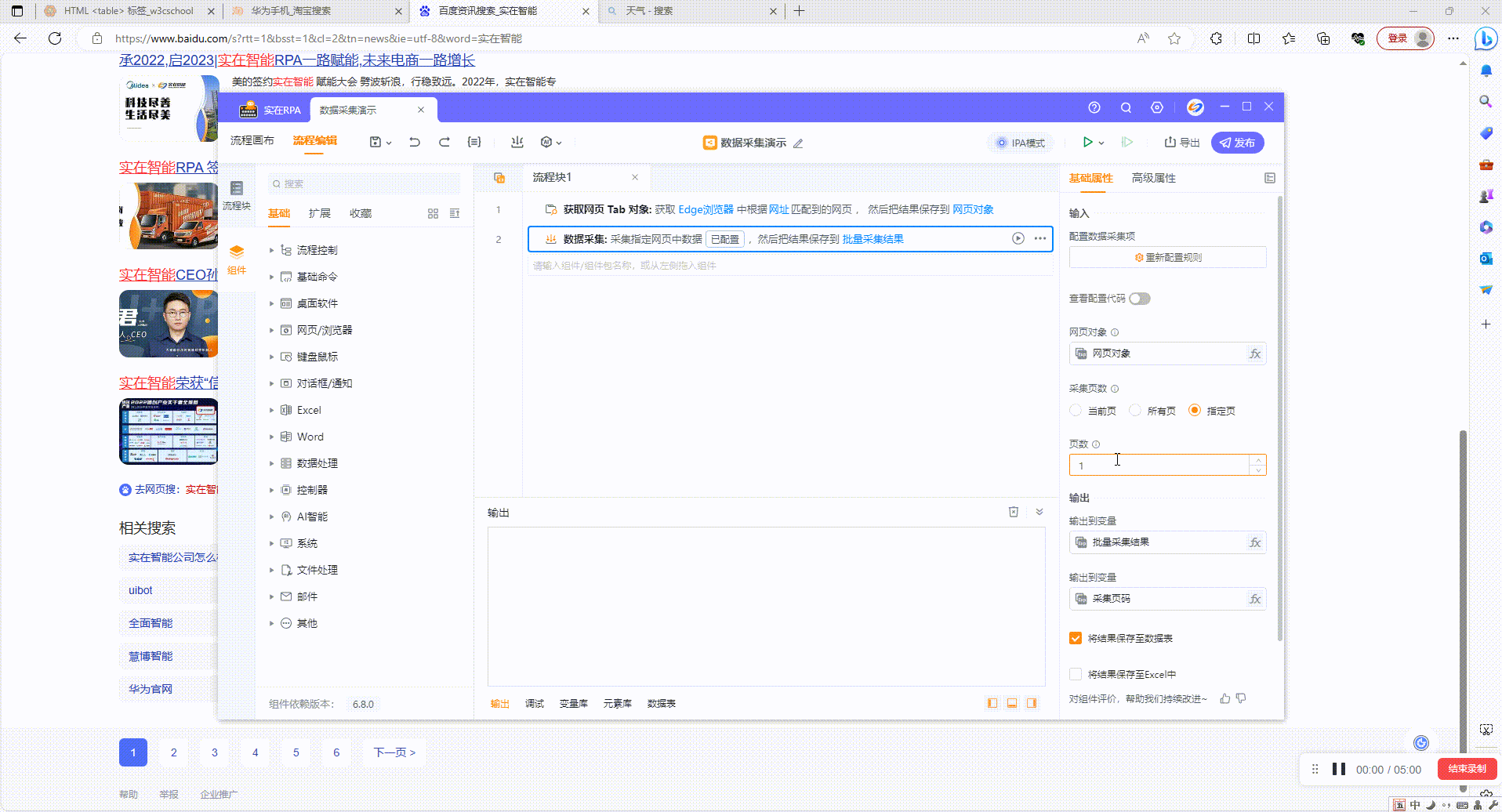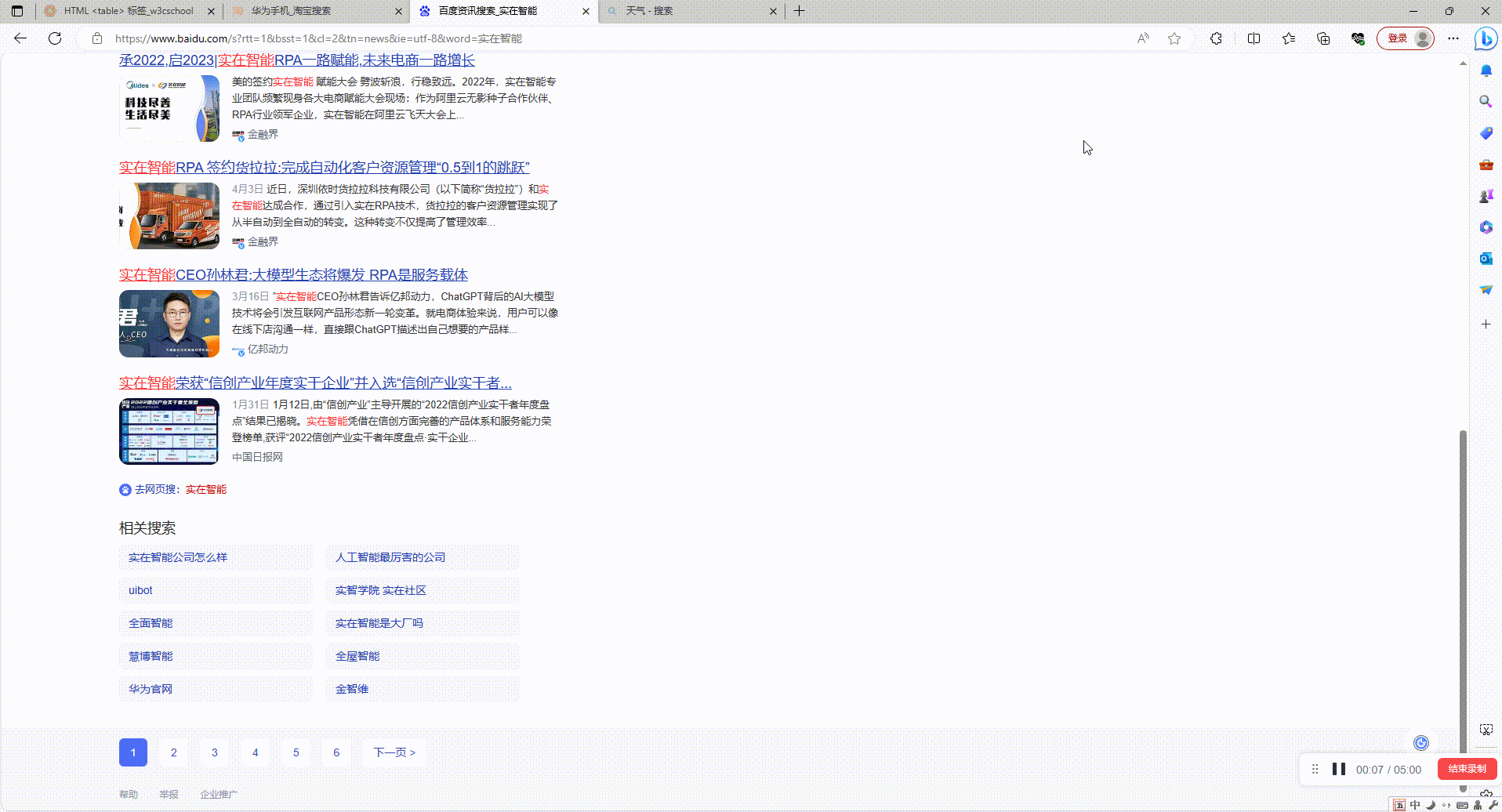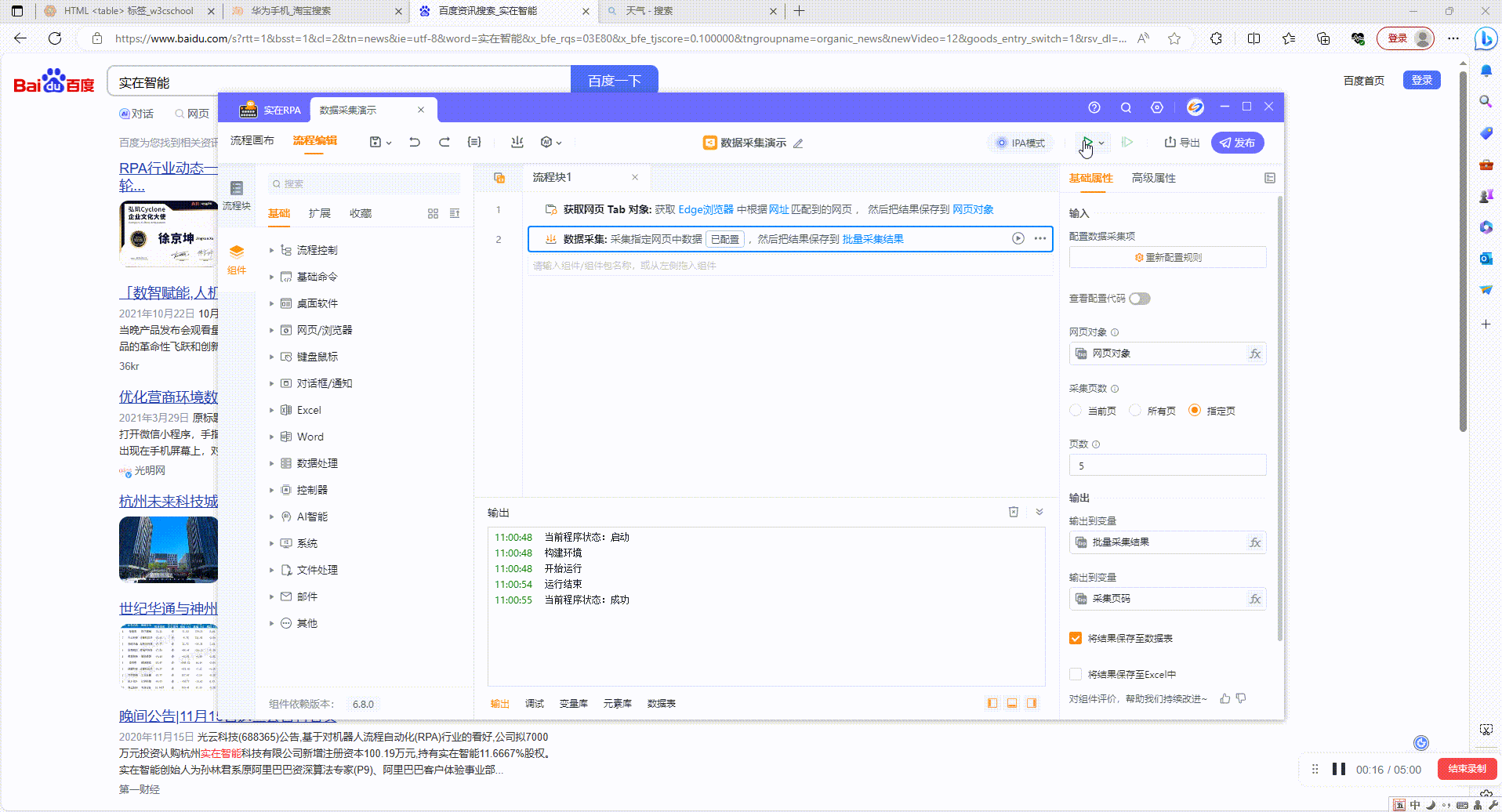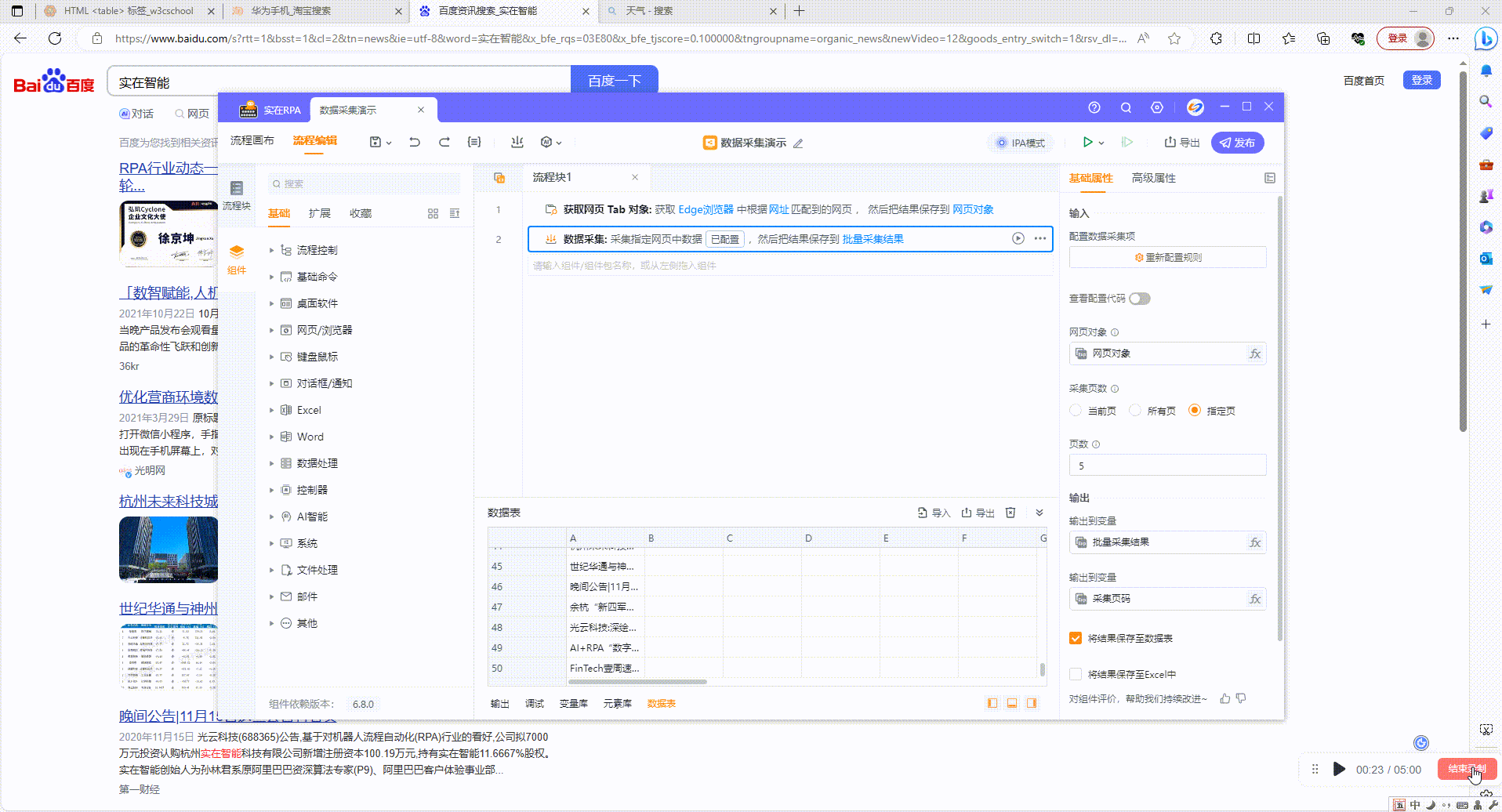
3.2?结果输出:运行结束后可在数据表、Excel、打印输出中查看采集结果
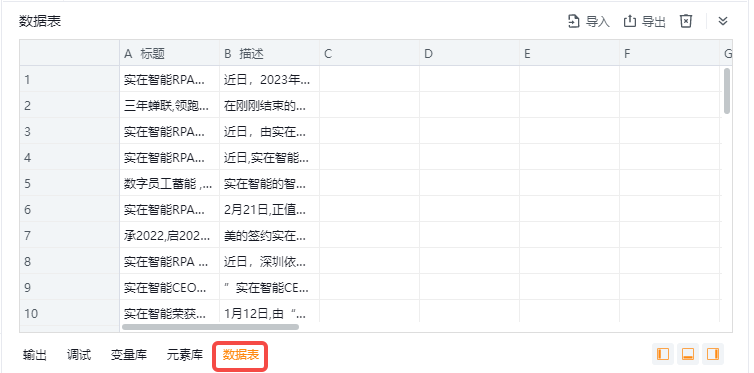
数据表查看结果:
Excel导出采集结果
打印输出结果:会同时打印出采集结果和采集页数
四、进阶用法
-
采集结果校验:点击采集列下拉选项,选择编辑列数据,点击校验后已采集的数据会高亮显示并显示采集个数,方便识别缺失数据所在位置,并进行拾取同类数据操作
2.页面滚屏:采集页面经常会有区域懒加载数据的情况,如图电商网站,需要滚动下拉后才能显示全部数据,此时可以在高级属性中设置页面滚屏次数来控制滚动条下拉,待数据全部加载完成后再采集内容。
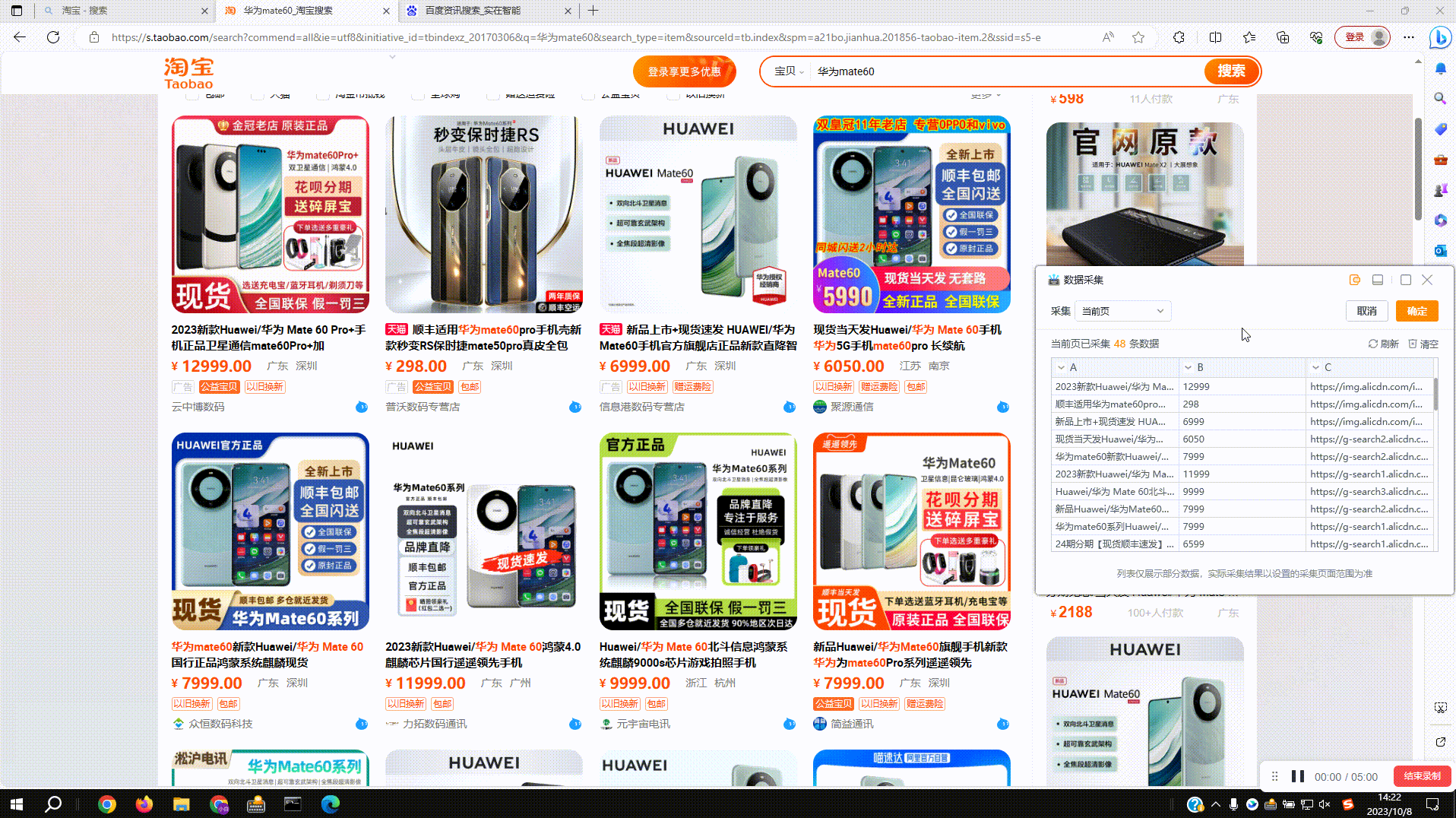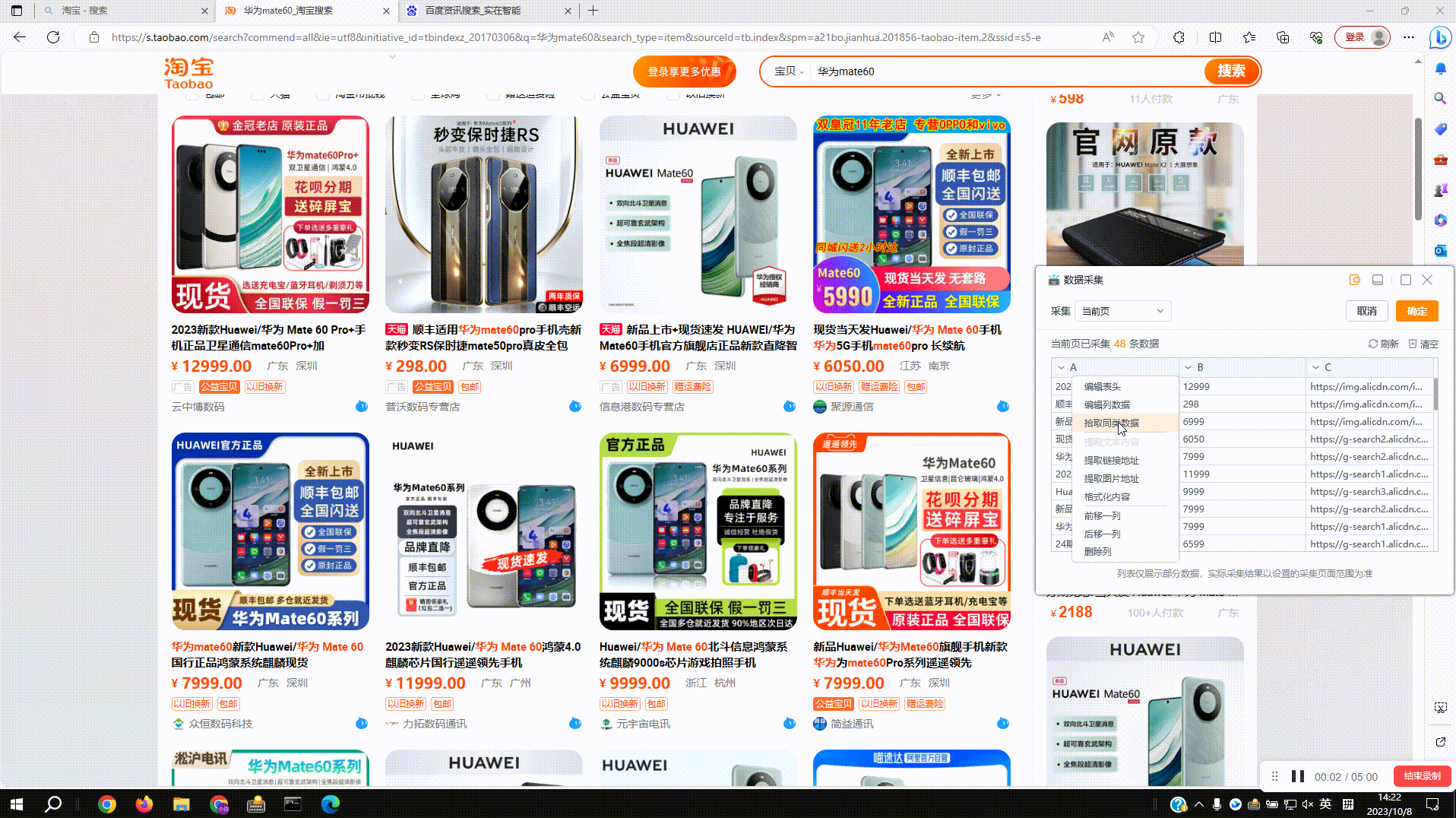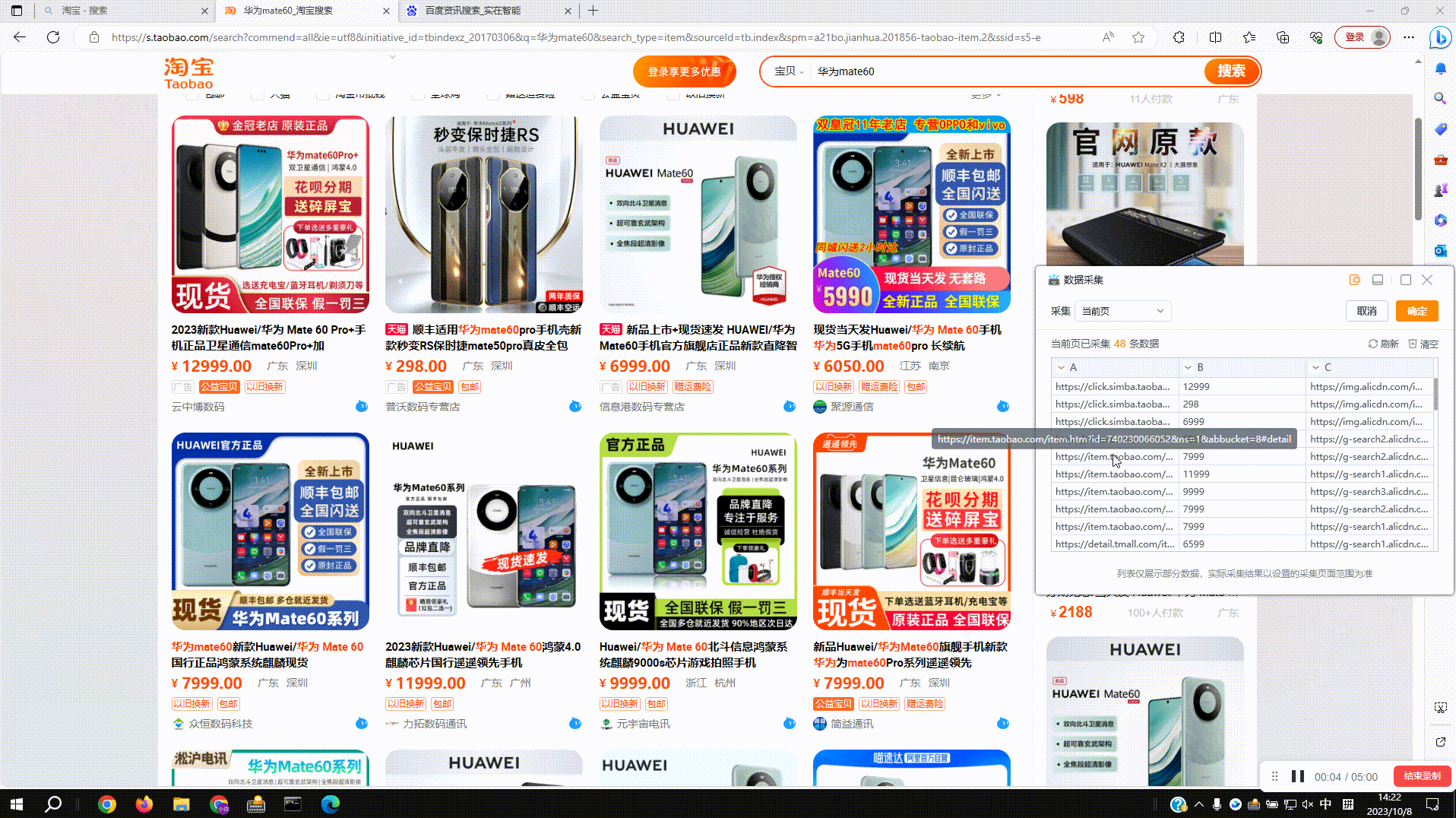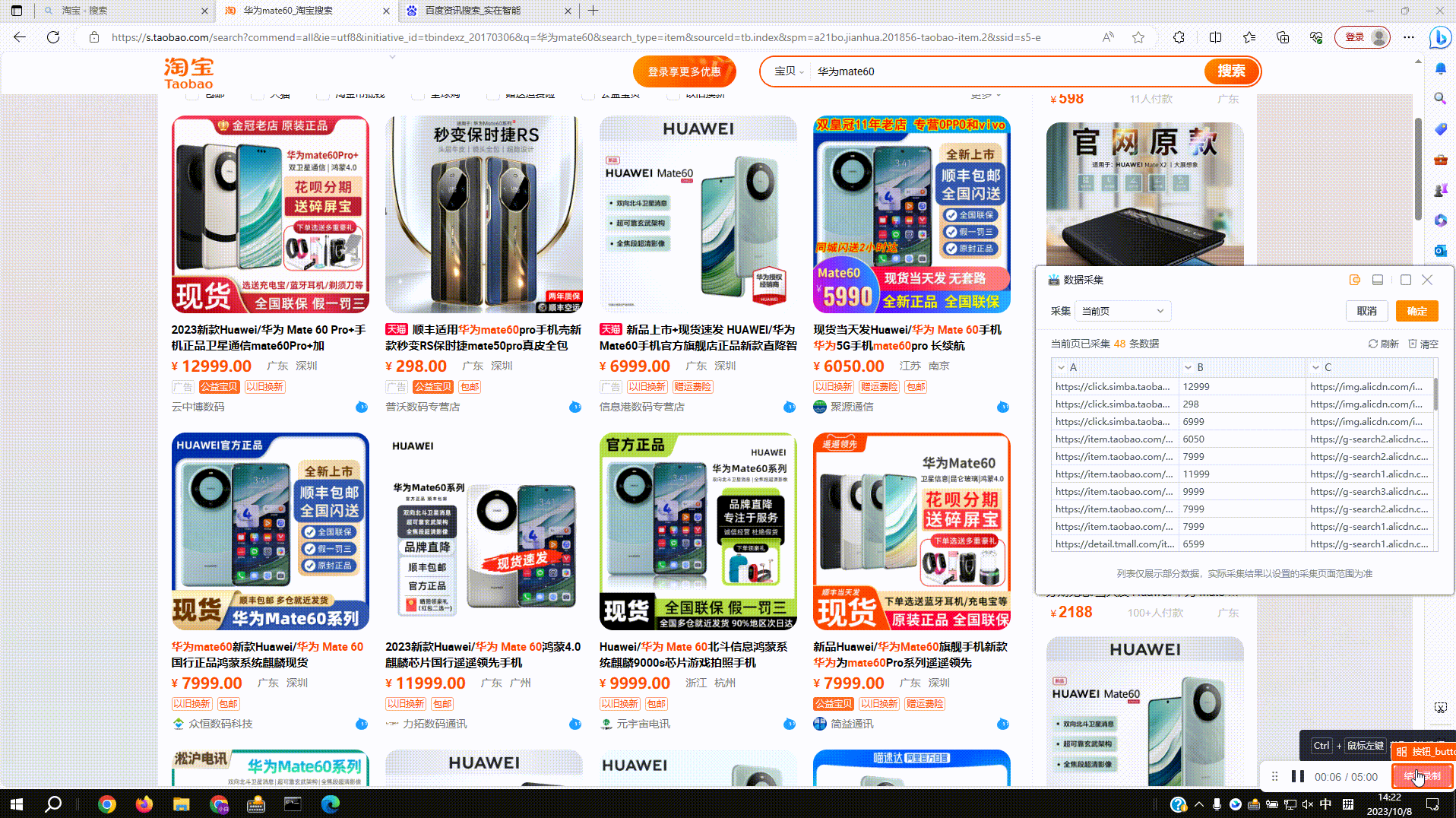
3.数据处理:采集内容如不符合预期,可以进行提取链接、图片地址、正则过滤等操作
3.1?采集内容链接:预览窗中点击下拉菜单,切换到提取链接地址即可,切换后如出现空白,可通过编辑列元素修改元素节点,保证链接所在的标签在最后一级即可
3.2?采集图片地址:采集图片内容后自动提取当前图片地址
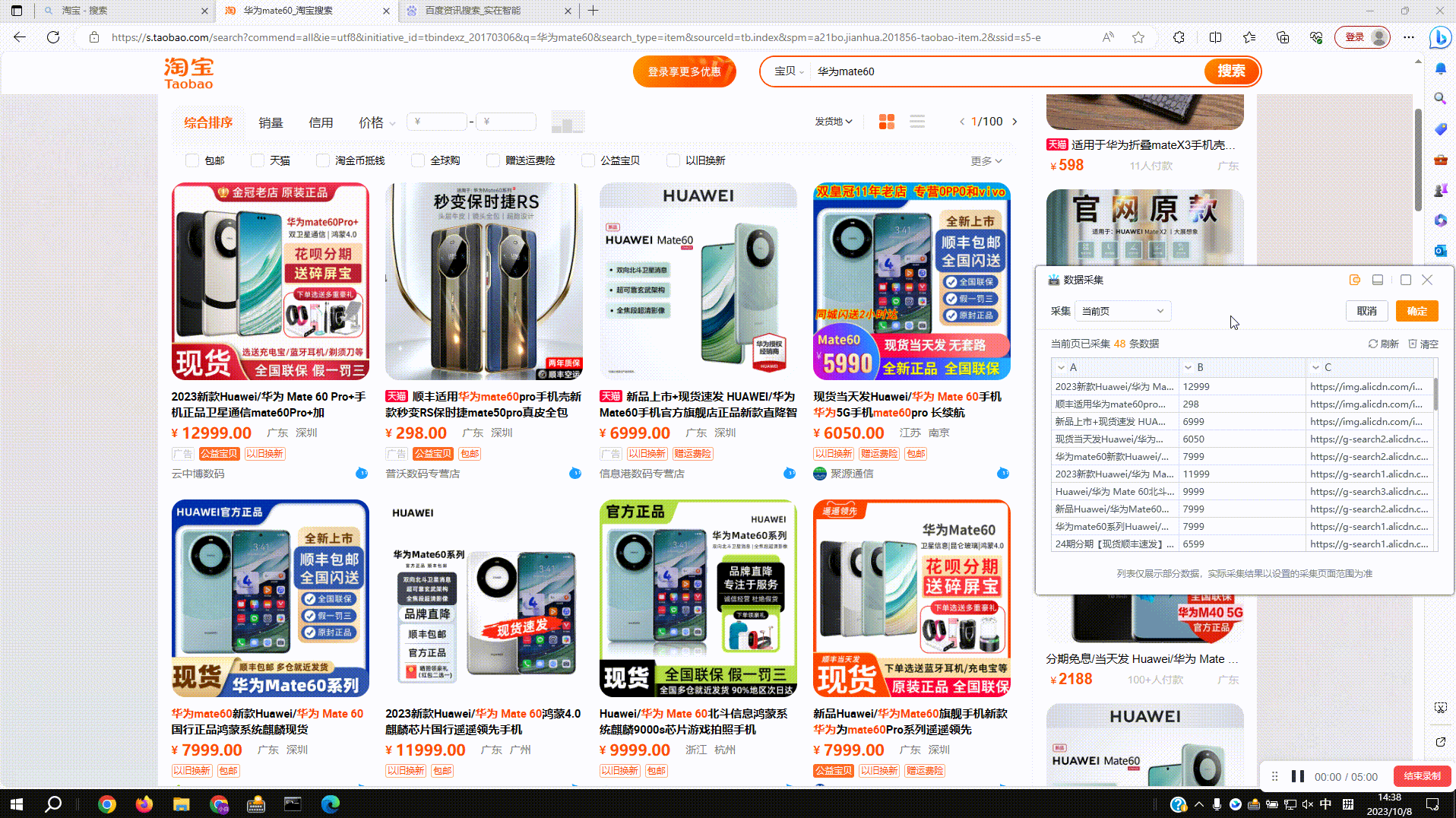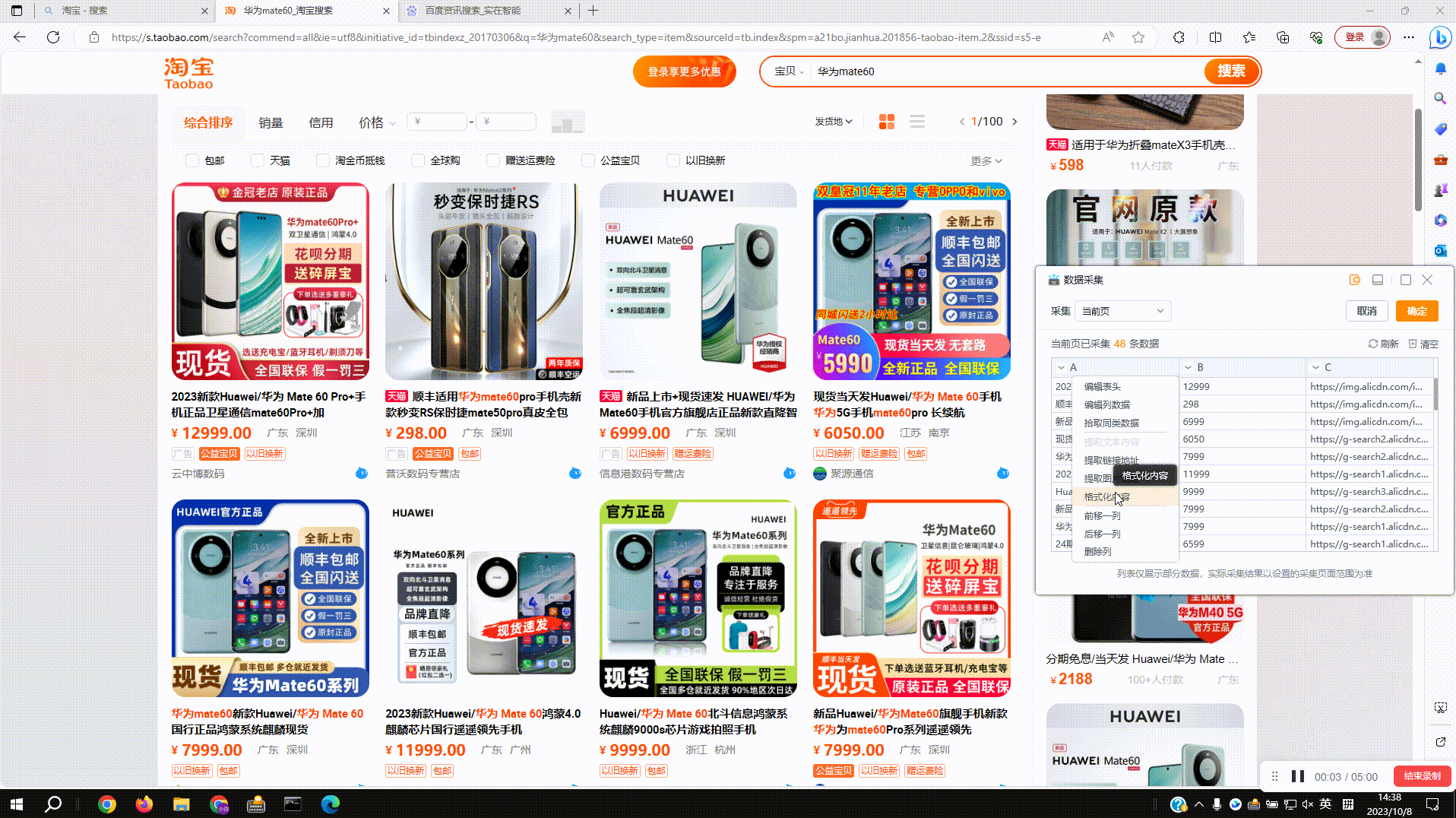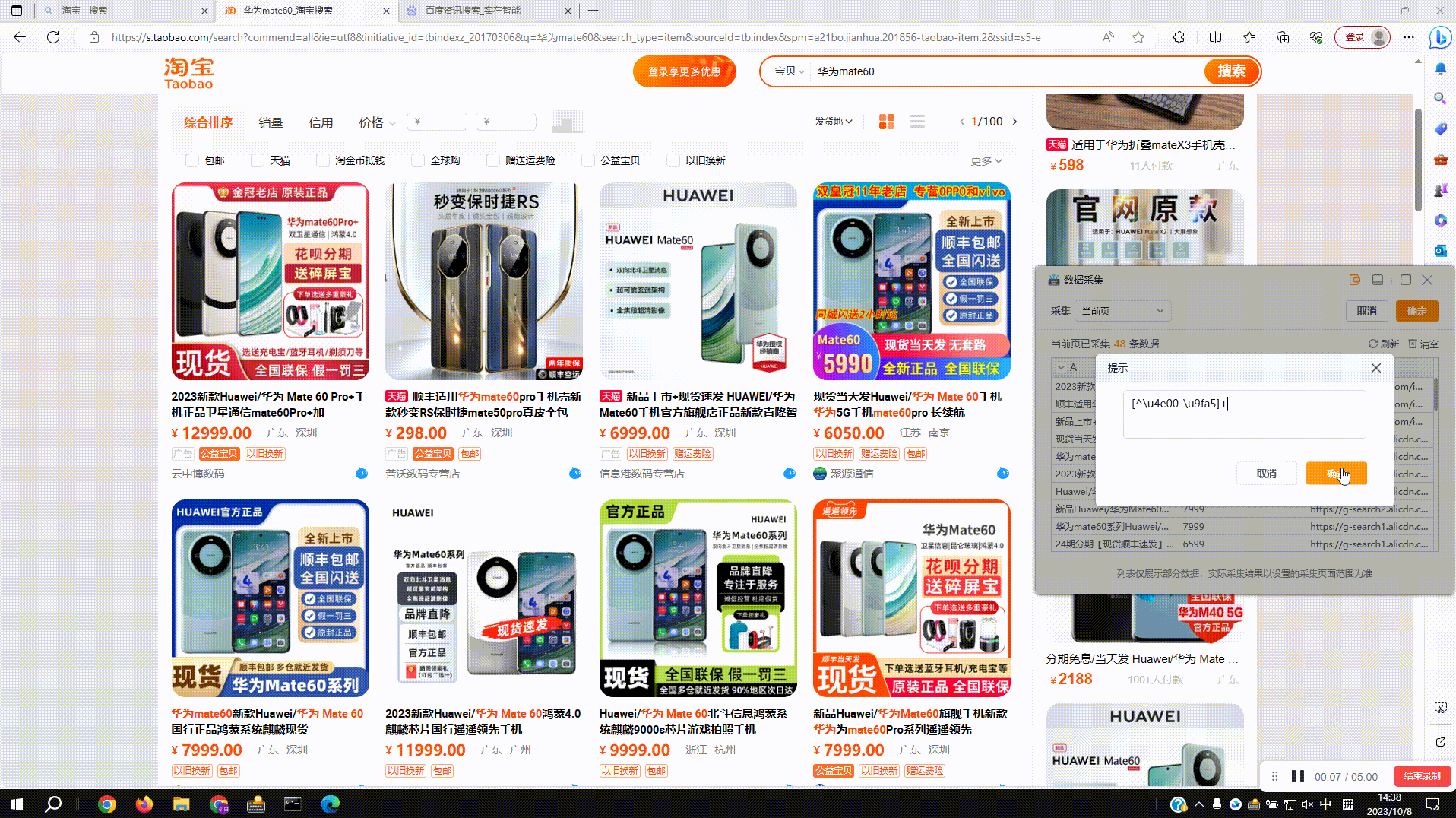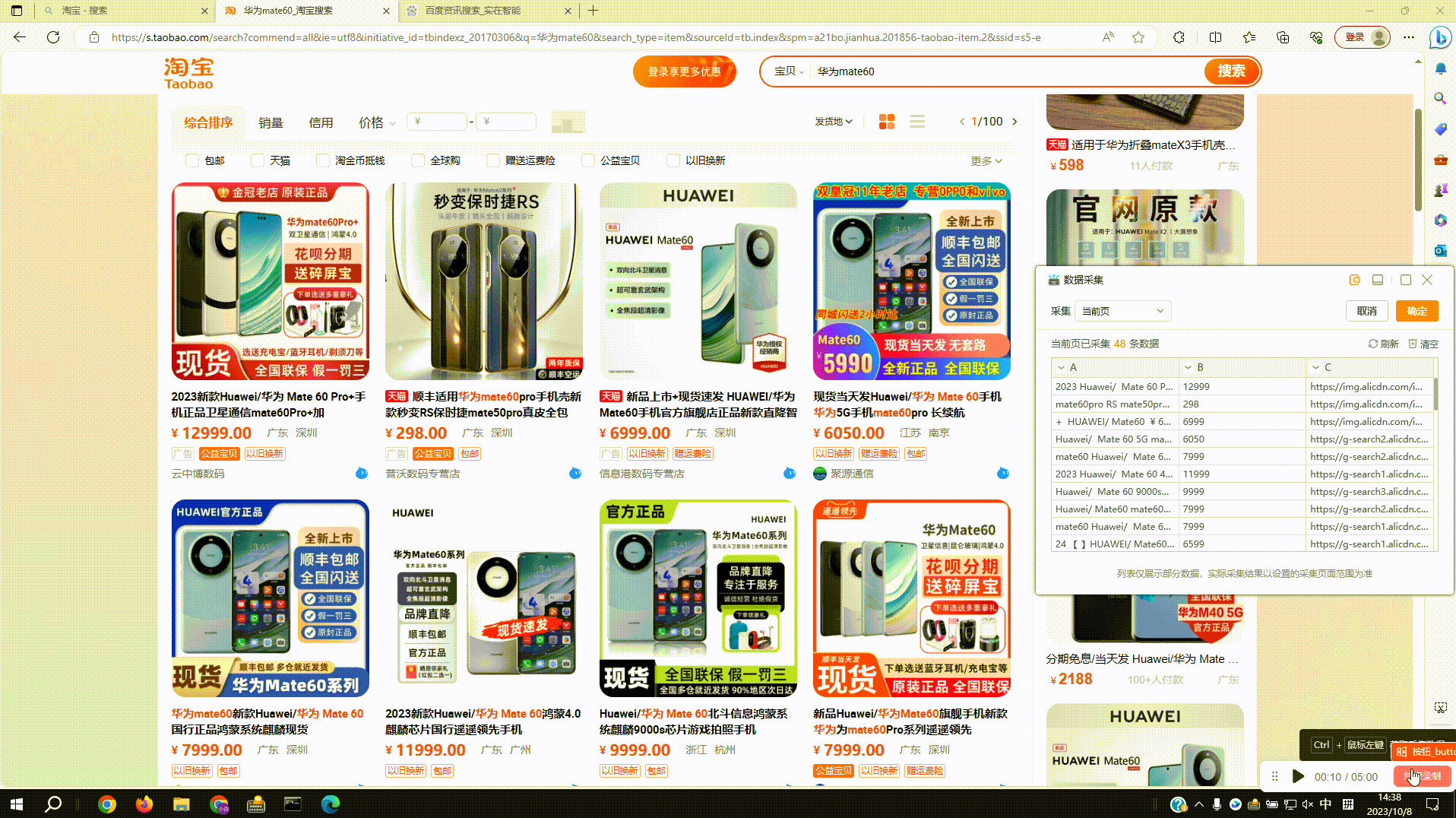
3.3?正则过滤:预览窗中点击下拉菜单,切换到格式化内容即可,如图过滤采集内容中的非中文字符
4.翻页按钮不仅仅只是翻页:如图百度首页没有翻页按钮,想采集更多热搜内容时就可以拾取【换一换】按钮,运行后会点击【换一换】来进行采集,其他类似场景下的重新加载、换一批等都可以参照这种方法
剧透一下,实在智能设计器690版本会带来全新升级的数据采集组件,更多好用又好玩的功能,一起期待吧~
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 代码随想录第三十六天(一刷&&C语言)|背包问题理论基础&&分割等和子集
- 基于FFmpeg的短视频编辑工具Cut
- k8s之陈述式资源管理
- Gateway网关
- 面试 React 框架八股文十问十答第七期
- 【无标题】
- Java面试基础|数据结构 -实时更新
- 端云协同,Akamai 与快手联合落地 QUIC 提升海外用户视频体验
- 【DOM笔记二】操作元素(修改元素内容,修改常见元素/表单元素/元素样式属性,排他思想,自定义属性操作,应用案例!)
- C++入门学习(十一)字符型