探索数据之美:深入Seaborn的数据可视化艺术与技巧【第26篇—python:Seaborn】
Seaborn是一款基于Matplotlib的统计数据可视化库,其高级接口和精美的默认样式使得数据可视化更加简便和美观。
1. 引言
Seaborn在数据可视化中具有以下特点和优势:
- 简化API: Seaborn的API设计简洁易用,特别适合初学者。几行代码即可生成漂亮且具有信息量的图表。
- 美观的默认样式: Seaborn具备吸引人的默认颜色和样式,无需额外配置即可生成专业外观的图表,减轻用户的设计负担。
- 统计图表支持: Seaborn专注于统计数据可视化,提供多种内置图表类型,如箱线图、热力图、小提琴图等,更适合展示和分析统计信息。
- 颜色映射: Seaborn提供强大的颜色映射功能,使用户能更好地传达数据的差异和模式。
- 与Pandas集成: Seaborn与Pandas数据框良好集成,使数据分析和可视化更加流畅。

2. Seaborn基础
2.1 安装和环境设置
在使用Seaborn之前,需要通过以下命令使用pip安装Seaborn:
pip install seaborn
安装完成后,在Python中引入Seaborn:
import seaborn as sns
2.2 常用数据可视化函数
Seaborn提供多种常用的数据可视化函数,使得创建各种图表变得简单。以下是一些常用函数的示例:
-
散点图:
sns.scatterplot(x='feature1', y='feature2', data=data) -
折线图:
sns.lineplot(x='x_axis', y='y_axis', data=data) -
直方图:
sns.histplot(x='variable', data=data, bins=30, kde=True) -
箱线图:
sns.boxplot(x='category', y='value', data=data) -
热力图:
sns.heatmap(data.corr(), annot=True, cmap='coolwarm')
2.3 设置样式和颜色主题
Seaborn允许用户通过设置样式和颜色主题来定制图表外观。
-
设置样式:
sns.set_style('whitegrid') -
设置颜色主题:
sns.set_palette('pastel') -
设置图表尺寸:
sns.set(rc={'figure.figsize':(10, 6)})
这些设置使得用户能够更灵活地调整Seaborn图表的外观,以适应特定的需求和个人偏好。
3. 数据准备与导入
3.1 使用Pandas库加载和处理数据
Pandas是一个强大的数据分析库,以下是一些常见的数据准备与导入任务:
-
加载数据:
data = pd.read_csv('your_data.csv') -
查看数据前几行:
print(data.head()) -
数据信息:
print(data.info()) -
描述性统计:
print(data.describe())
3.2 数据清理和缺失值处理
在数据分析中,清理和处理缺失值是关键步骤。
-
检测缺失值:
print(data.isnull().sum()) -
处理缺失值:
data = data.dropna() -
重复值处理:
print(data.duplicated().sum()),data = data.drop_duplicates() -
数据类型转换:
data['column_name'] = data['column_name'].astype(int)
这些任务确保加载的数据是干净、整洁的,并且能够得到准确的分析和可视化结果。
4. Seaborn中的常见图表
4.1 折线图和散点图:展示趋势和变量关系
- 折线图:
sns.lineplot(x='x_variable', y='y_variable', data=data)
import seaborn as sns
import matplotlib.pyplot as plt
sns.lineplot(x='x_variable', y='y_variable', data=data)
plt.show()
- 散点图:
sns.scatterplot(x='x_variable', y='y_variable', data=data)
sns.scatterplot(x='x_variable', y='y_variable', data=data)
plt.show()
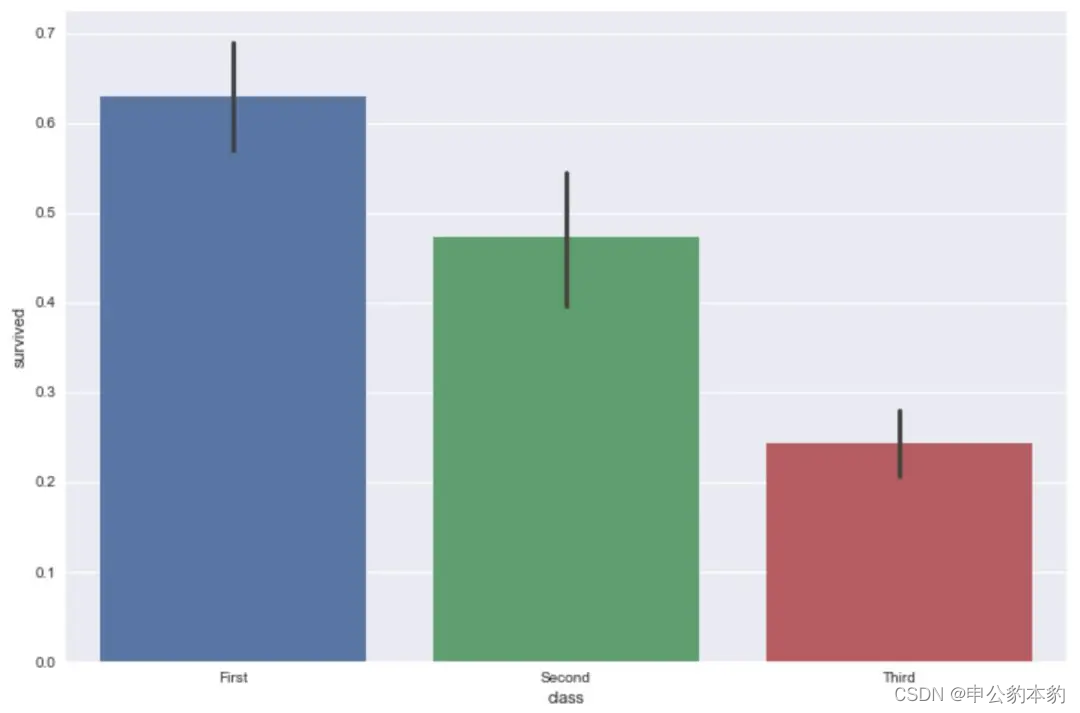
4.2 条形图和箱线图:比较和分布可视化
- 条形图:
sns.barplot(x='category', y='value', data=data)
sns.barplot(x='category', y='value', data=data)
plt.show()
- 箱线图:
sns.boxplot(x='category', y='value', data=data)
sns.boxplot(x='category', y='value', data=data)
plt.show()
4.3 热力图:矩阵数据的可视化
- 热力图:
sns.heatmap(data.corr(), annot=True, cmap='coolwarm')
sns.heatmap(data.corr(), annot=True, cmap='coolwarm')
plt.show()
这些图表有助于更好地理解数据中的趋势、关系和分布,为数据分析和决策提供可视化支持。
5. 高级Seaborn技巧
5.1 多图表和子图:创建复杂的布局
- 多图表布局:使用
plt.subplots()创建多个图表,使用plt.subplot()设置子图位置。
import seaborn as sns
import matplotlib.pyplot as plt
fig, axes = plt.subplots(nrows=2, ncols=2)
sns.scatterplot(x='x1', y='y1', data=data, ax=axes[0, 0])
sns.lineplot(x='x2', y='y2', data=data, ax=axes[0, 1])
sns.barplot(x='category', y='value', data=data, ax=axes[1,
0])
sns.boxplot(x='category', y='value', data=data, ax=axes[1, 1])
plt.show()
5.2 样式和颜色映射:个性化图表外观
-
样式设置:
sns.set_style('whitegrid') -
颜色映射:
custom_palette = sns.color_palette("Paired", 10)
sns.set_style('whitegrid')
sns.set_palette(custom_palette)
5.3 Seaborn和Matplotlib的结合使用
Seaborn建立在Matplotlib之上,可以方便地结合使用。
import matplotlib.pyplot as plt
import seaborn as sns
fig, ax = plt.subplots()
with sns.axes_style("darkgrid"):
ax.plot(x, y)
plt.show()
这些高级技巧允许创建更复杂、更个性化的图表布局,并通过样式和颜色映射使图表更具吸引力。结合Seaborn和Matplotlib,能够更灵活地满足特定项目的需求。
6. 实战案例: 使用Seaborn处理真实数据集
在实际项目中,可以使用Seaborn处理真实数据集,创建独特而有说服力的数据可视化项目。以下是基本步骤:
-
导入必要的库:
import seaborn as sns,import matplotlib.pyplot as plt,import pandas as pd -
加载真实数据集:
sales_data = pd.read_csv('sales_data.csv') -
数据清理和处理:对数据进行清理,处理缺失值、重复值等。
-
创建独特的数据可视化项目:使用Seaborn创建一个独特而有说服力的数据可视化项目。
sns.lineplot(x='date', y='sales', data=sales_data, hue='product_category')
plt.title('Product Sales Trend Over Time')
plt.show()
sns.boxplot(x='product_category', y='profit', data=sales_data)
plt.title('Profit Distribution Across Product Categories')
plt.show()
- 个性化图表外观:添加标题、轴标签、颜色映射等。
plt.title('Product Sales Trend Over Time')
plt.xlabel('Date')
plt.ylabel('Sales')
- 展示和分享:展示和分享你的数据可视化项目,确保清晰传达信息并引起观众兴趣。
plt.show()
当处理真实数据集时,确保在实施这些步骤时充分了解数据的特征,以便选择适当的可视化方法。以下是继续实施实战案例的步骤:
6.2 实战案例步骤
- 导入必要的库:
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
- 加载真实数据集:
# 例如,从CSV文件加载数据集
sales_data = pd.read_csv('sales_data.csv')
- 数据清理和处理:
在清理数据时,确保处理缺失值、重复值等,以确保数据的质量。
# 例如,删除缺失值
sales_data = sales_data.dropna()
- 创建独特的数据可视化项目:
使用Seaborn创建一个独特而有说服力的数据可视化项目。例如,绘制产品销售趋势和利润分布。
# 例如,绘制产品销售趋势
sns.lineplot(x='date', y='sales', data=sales_data, hue='product_category')
plt.title('Product Sales Trend Over Time')
plt.show()
# 例如,绘制利润分布箱线图
sns.boxplot(x='product_category', y='profit', data=sales_data)
plt.title('Profit Distribution Across Product Categories')
plt.show()
- 个性化图表外观:
在图表中添加标题、轴标签、颜色映射等,以使其更具吸引力。
# 例如,添加标题和轴标签
plt.title('Product Sales Trend Over Time')
plt.xlabel('Date')
plt.ylabel('Sales')
# 例如,设置颜色映射
custom_palette = sns.color_palette("Set2", len(sales_data['product_category'].unique()))
sns.set_palette(custom_palette)
- 展示和分享:
最后,展示和分享你的数据可视化项目,确保其能够清晰传达信息并引起观众的兴趣。
# 展示图表
plt.show()
通过这些步骤,你可以利用Seaborn强大的功能,将真实数据转化为有力的可视化呈现,为数据分析和决策提供更直观的支持。
7. Seaborn的进阶应用
在使用Seaborn进行数据可视化时,还有一些进阶的技巧和功能可以提升你的图表质量和表达能力。
7.1 自定义调色板
通过使用自定义调色板,你可以更好地控制图表中的颜色,使其更符合你的需求和主题。
# 例如,创建一个自定义调色板
custom_palette = sns.color_palette("husl", 3)
sns.set_palette(custom_palette)
7.2 标题和标签的更多个性化选项
Seaborn允许你在标题和标签中使用更多的文本格式和样式,以增加可读性。
# 例如,使用Markdown格式添加粗体标题
plt.title('**Product Sales Trend** Over Time')
7.3 添加注释
通过添加注释,你可以在图表中突出显示特定的数据点或趋势,提供更多的信息。
# 例如,添加趋势线的注释
plt.annotate('Sales Increase', xy=(10, 1000), xytext=(5, 1200),
arrowprops=dict(facecolor='black', shrink=0.05))
7.4 使用FacetGrid进行多图表展示
FacetGrid是Seaborn中的一个强大工具,可以轻松创建包含多个子图表的网格,以更好地比较不同类别的数据。
# 例如,使用FacetGrid创建多个箱线图
g = sns.FacetGrid(data, col="category", col_wrap=3, height=4)
g.map(sns.boxplot, "value")
7.5 调整图表布局
使用plt.subplots_adjust函数可以调整图表的布局,包括间距和子图之间的距离。
# 例如,调整图表布局
plt.subplots_adjust(left=0.1, bottom=0.1, right=0.9, top=0.9, wspace=0.4, hspace=0.4)
这些进阶的应用技巧能够使你更好地掌握Seaborn,提高图表的可读性和表达力。
8. 总结
在这篇文章中,我们深入了解了Seaborn的基础知识,学习了如何安装和使用Seaborn库进行数据可视化。我们涵盖了常用的图表类型,从简单的散点图到复杂的箱线图和热力图。通过一个实战案例,我们展示了如何使用Seaborn处理真实数据集,创建有力的数据可视化项目。
进一步地,我们介绍了Seaborn的一些高级技巧,包括自定义调色板、更多个性化选项、添加注释、多图表展示以及图表布局的调整。这些技巧使你能够更灵活地应对各种数据可视化需求。
通过学习和应用Seaborn,你可以更加轻松地创建具有吸引力和信息性的数据可视化,为数据科学和分析工作提供更强有力的支持。希望这篇文章对你在使用Seaborn进行数据可视化方面有所帮助。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 亚信安慧AntDB数据库实现千亿级用户稳定服务与超融合功能的融合
- 由delete和insert操作导致的死锁问题
- 【实用技巧】Steam Wallpaper Engine 壁纸引擎向手机导入壁纸方法
- Git——IDEA集成Git(详细)
- 如何禁止员工安装新软件(如何限制员工电脑随意安装程序)
- ?安全可靠测评结果公告(2023年第1号)
- openGauss学习笔记-198 openGauss 数据库运维-常见故障定位案例-分析查询效率异常降低的问题
- Kafka下沉到HDFS报错
- 超级干货!五个步骤教你从0到1搭建FP独立站!
- 算法—删除有序数组重复项