深度学习工具-如何选择服务器和GPU
深度学习训练通常需要大量的计算。目前,GPU是深度学习最具成本效益的硬件加速器。与CPU相比,GPU更便宜,性能更高,通常超过一个数量级。此外,一台服务器可以支持多个GPU,高端服务器最多支持8个GPU。更典型的数字是工程工作站最多4个GPU,这是因为热量、冷却和电源需求会迅速增加,超出办公楼所能支持的范围。对于更大的部署,云计算(例如亚马逊的P3和G4实例)是一个更实用的解决方案。
选择服务器
通常不需要购买具有多个线程的高端CPU,因为大部分计算都发生在GPU上。这就是说,由于Python中的全局解释器锁(GIL),CPU的单线程性能在有4-8个GPU的情况下可能很重要。所有的条件都是一样的,这意味着核数较少但时钟频率较高的CPU可能是更经济的选择。例如,当在6核4GHz和8核3.5GHz CPU之间进行选择时,前者更可取,即使其聚合速度较低。一个重要的考虑因素是,GPU使用大量的电能,从而释放大量的热量。这需要非常好的冷却和足够大的机箱来容纳GPU。如有可能,请遵循以下指南:
-
电源。GPU使用大量的电源。每个设备预计高达350W(检查显卡的峰值需求而不是一般需求,因为高效代码可能会消耗大量能源)。如果电源不能满足需求,系统会变得不稳定。
-
机箱尺寸。GPU很大,辅助电源连接器通常需要额外的空间。此外,大型机箱更容易冷却。
-
GPU散热。如果有大量的GPU,可能需要投资水冷。此外,即使风扇较少,也应以“公版设计”为目标,因为它们足够薄,可以在设备之间进气。当使用多风扇GPU,安装多个GPU时,它可能太厚而无法获得足够的空气。
-
PCIe插槽。在GPU之间来回移动数据(以及在GPU之间交换数据)需要大量带宽。建议使用16通道的PCIe 3.0插槽。当安装了多个GPU时,请务必仔细阅读主板说明,以确保在同时使用多个GPU时16×带宽仍然可用,并且使用的是PCIe3.0,而不是用于附加插槽的PCIe2.0。在安装多个GPU的情况下,一些主板的带宽降级到8×甚至4×。这部分是由于CPU提供的PCIe通道数量限制。
简而言之,以下是构建深度学习服务器的一些建议。
-
初学者。购买低功耗的低端GPU(适合深度学习的廉价游戏GPU,功耗150-200W)。如果幸运的话,大家现在常用的计算机将支持它。
-
1个GPU。一个4核的低端CPU就足够了,大多数主板也足够了。以至少32 GB的DRAM为目标,投资SSD进行本地数据访问。600W的电源应足够。买一个有很多风扇的GPU。
-
2个GPU。一个4-6核的低端CPU就足够了。可以考虑64 GB的DRAM并投资于SSD。两个高端GPU将需要1000瓦的功率。对于主板,请确保它们具有两个PCIe 3.0 x16插槽。如果可以,请使用PCIe 3.0 x16插槽之间有两个可用空间(60毫米间距)的主板,以提供额外的空气。在这种情况下,购买两个具有大量风扇的GPU。
-
4个GPU。确保购买的CPU具有相对较快的单线程速度(即较高的时钟频率)。可能需要具有更多PCIe通道的CPU,例如AMD Threadripper。可能需要相对昂贵的主板才能获得4个PCIe 3.0 x16插槽,因为它们可能需要一个PLX来多路复用PCIe通道。购买带有公版设计的GPU,这些GPU很窄,并且让空气进入GPU之间。需要一个1600-2000W的电源,而办公室的插座可能不支持。此服务器可能在运行时声音很大,很热。不想把它放在桌子下面。建议使用128 GB的DRAM。获取一个用于本地存储的SSD(1-2 TB NVMe)和RAID配置的硬盘来存储数据。
-
8 GPU。需要购买带有多个冗余电源的专用多GPU服务器机箱(例如,每个电源为1600W时为2+1)。这将需要双插槽服务器CPU、256 GB ECC DRAM、快速网卡(建议使用10 GBE),并且需要检查服务器是否支持GPU的物理外形。用户GPU和服务器GPU之间的气流和布线位置存在显著差异(例如RTX 2080和Tesla V100)。这意味着可能无法在服务器中安装消费级GPU,因为电源线间隙不足或缺少合适的接线(本书一位合著者痛苦地发现了这一点)。
选择GPU
目前,AMD和NVIDIA是专用GPU的两大主要制造商。NVIDIA是第一个进入深度学习领域的公司,通过CUDA为深度学习框架提供更好的支持。因此,大多数买家选择NVIDIA GPU。
NVIDIA提供两种类型的GPU,针对个人用户(例如,通过GTX和RTX系列)和企业用户(通过其Tesla系列)。这两种类型的GPU提供了相当的计算能力。但是,企业用户GPU通常使用强制(被动)冷却、更多内存和ECC(纠错)内存。这些GPU更适用于数据中心,通常成本是消费者GPU的十倍。
如果是一个拥有100个服务器的大公司,则应该考虑英伟达Tesla系列,或者在云中使用GPU服务器。对于实验室或10+服务器的中小型公司,英伟达RTX系列可能是最具成本效益的,可以购买超微或华硕机箱的预配置服务器,这些服务器可以有效地容纳4-8个GPU。
GPU供应商通常每一到两年发布一代,例如2017年发布的GTX 1000(Pascal)系列和2019年发布的RTX 2000(Turing)系列。每个系列都提供几种不同的型号,提供不同的性能级别。GPU性能主要是以下三个参数的组合:
-
计算能力。通常大家会追求32位浮点计算能力。16位浮点训练(FP16)也进入主流。如果只对预测感兴趣,还可以使用8位整数。最新一代图灵GPU提供4-bit加速。不幸的是,目前训练低精度网络的算法还没有普及;
-
内存大小。随着模型变大或训练期间使用的批量变大,将需要更多的GPU内存。检查HBM2(高带宽内存)与GDDR6(图形DDR)内存。HBM2速度更快,但成本更高;
-
内存带宽。当有足够的内存带宽时,才能最大限度地利用计算能力。如果使用GDDR6,请追求宽内存总线。
对于大多数用户,只需看看计算能力就足够了。请注意,许多GPU提供不同类型的加速。例如,NVIDIA的Tensor Cores将操作符子集的速度提高了5x。确保所使用的库支持这一点。GPU内存应不小于4GB(8GB更好)。尽量避免将GPU也用于显示GUI(改用内置显卡)。如果无法避免,请添加额外的2GB RAM以确保安全。
下图比较了各种GTX 900、GTX 1000和RTX 2000系列的(GFlops)和价格(Price)。价格是维基百科上的建议价格。

由上图,可以看出很多事情:
-
在每个系列中,价格和性能大致成比例。Titan因拥有大GPU内存而有相当的溢价。然而,通过比较980 Ti和1080 Ti可以看出,较新型号具有更好的成本效益。RTX 2000系列的价格似乎没有多大提高。然而,它们提供了更优秀的低精度性能(FP16、INT8和INT4);
-
GTX 1000系列的性价比大约是900系列的两倍;
-
对于RTX 2000系列,浮点计算能力是价格的“仿射”函数。
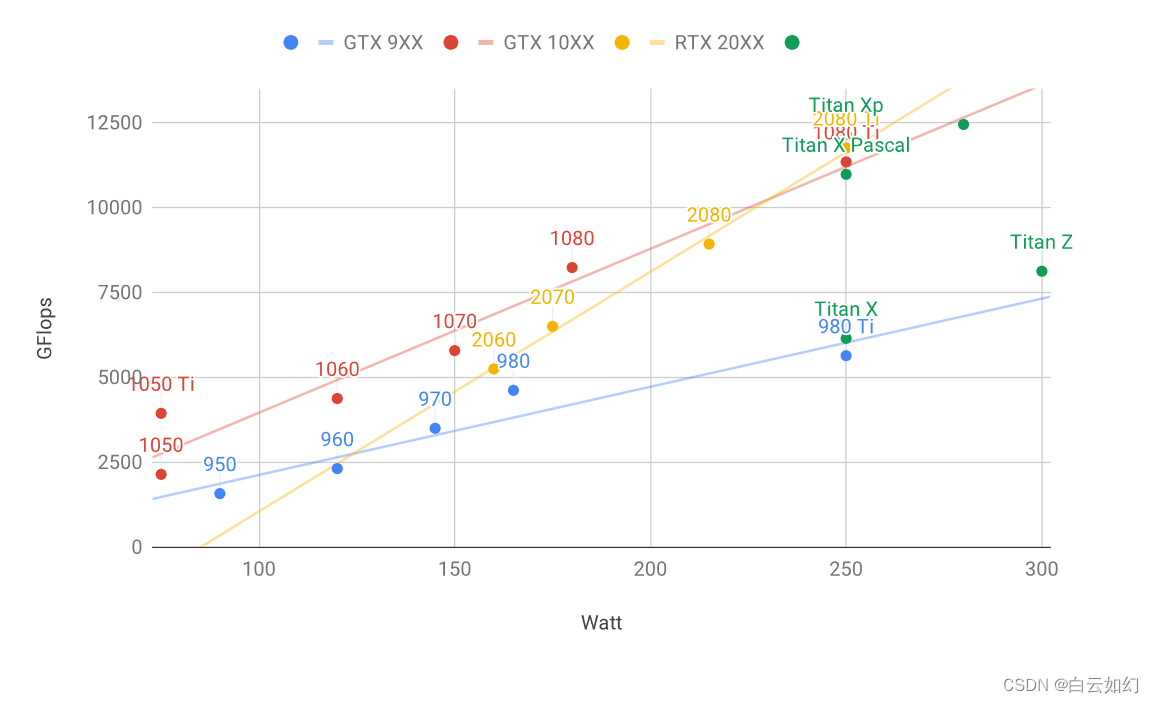
上图显示了能耗与计算量基本成线性关系。其次,后一代更有效率。这似乎与对应于RTX 2000系列的图表相矛盾。然而,这是TensorCore不成比例的大能耗的结果。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Spring Boot Starters
- 力扣LCR 165. 解密数字(动态规划)
- 【运维知识大神篇】运维界的超神器Kubernetes教程2(资源清单编写+镜像下载策略+容器重启策略+资源限制详解+端口映射详解+K8s故障排查技巧)
- Pytorch:模型的保存加载、模型微调、GPU的使用
- 编码(Encoding)
- windows I/O 基础
- SynchronousQueue介绍
- 分布式链路追踪专栏——分布式链路追踪:Skywalking 探针模型设计
- kali安装HTTrack报错Unable to locate package httrack
- Pytorch从零开始实战17