CCF模拟题 202312-3 树上搜索
CCF模拟题 202312-3 树上搜索
题目背景:
西西艾弗岛大数据中心为了收集用于模型训练的数据,推出了一项自愿数据贡献的系统。岛上的居民可以登录该系统,回答系统提出的问题,从而为大数据中心提供数据。为了保证数据的质量,系统会评估回答的正确性,如果回答正确,系统会给予一定的奖励。
近期,大数据中心需要收集一批关于名词分类的数据。系统中会预先设置若干个名词类别,这些名词类别存在一定的层次关系。例如,“动物”是“生物”的次级类别,“鱼类”是“动物”的次级类别,“鸟类”是“动物”的次级类别,“鱼类”和“鸟类”是“动物”下的邻居类别。这些名词类别可以被按树形组织起来,即除了根类别外,每个类别都有且仅有一个上级类别。
并且所有的名词都可以被归类到某个类别中,即每个名词都有且仅有一个类别与其对应。一个类别的后代类别的定义是:若该类别没有次级类别,则该类别没有后代类别;否则该类别的后代类别为该类别的所有次级类别,以及其所有次级类别的后代类别。
下图示意性地说明了标有星号的类别的次级类别和后代类别。
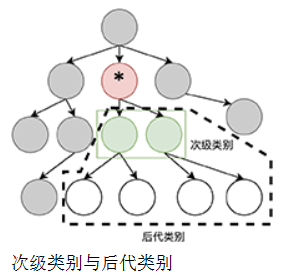
系统向用户提出问题的形式是:某名词是否属于某类别,而用户可以选择“是”或“否”来回答问题。该问题的含义是:某名词是否可以被归类到某类别或其后代类别中。
例如,要确定名词“鳕鱼”的类别,系统会向用户提出“鳕鱼是否属于动物”,当用户选择“是”时,系统会进一步询问“鳕鱼是否属于鱼类”,当用户选择“是”时,即可确定“鳕鱼”可以被归类到“鱼类”这一类别。
此外,如果没有更具体的分类,某一名词也可以被归类到非叶子结点的类别中。例如,要确定“猫”的类别,系统可以向用户提出“猫是否属于动物”,当用户选择“是”时,系统会进一步分别询问“猫”是否属于“鱼类”和“鸟类”,当两个问题收到了否定的答案后,系统会确定“猫”的类别是“动物”。
大数据中心根据此前的经验,已经知道了一个名词属于各个类别的可能性大小。为了用尽量少的问题确定某一名词的类别,大数据中心希望小 C 来设计一个方法,以减少系统向用户提出的问题的数量。
问题描述:
小 C 观察了事先收集到的数据,并加以统计,得到了一个名词属于各个类别的可能性大小的信息。具体而言,每个类别都可以赋予一个被称为权重的值,值越大,说明一个名词属于该类别的可能性越大。由于每次向用户的询问可以获得两种回答,小 C 联想到了二分策略。他设计的策略如下:
1、对于每一个类别,统计它和其全部后代类别的权重之和,同时统计其余全部类别的权重之和,并求二者差值的绝对值,计为 ωδ;
2、选择 ωδ 最小的类别,如果有多个,则选取编号最小的那一个,向用户询问名词是否属于该类别;
3、如果用户回答“是”,则仅保留该类别及其后代类别,否则仅保留其余类别;
4、重复步骤 1,直到只剩下一个类别,此时即可确定名词的类别。
小 C 请你帮忙编写一个程序,来测试这个策略的有效性。你的程序首先读取到所有的类别及其上级次级关系,以及每个类别的权重。你的程序需要测试对于被归类到给定类别的名词,按照上述策略提问,向用户提出的所有问题。
输入格式
从标准输入读入数据。
输入的第一行包含空格分隔的两个正整数 n 和 m,分别表示全部类别的数量和需要测试的类别的数量。所有的类别从 1 到 n 编号,其中编号为 1 的是根类别。
输入的第二行包含 n 个空格分隔的正整数 ω1,ω2,…,ωn,其中第 i 个数 ωi 表示编号为 i 的类别的权重。
输入的第三行包含 (n-1) 个空格分隔的正整数 p1,p2,…,pn,其中第 i 个数 p(i+1) 表示编号为 (i+1) 的类别的上级类别的编号,其中 pi∈[1,n]
接下来输入 m 行,每行一个正整数,表示需要测试的类别编号。
输出格式
输出 m 行,每行表示对一个被测试的类别的测试结果。表示按小 C 的询问策略,对属于给定的被测类别的名词,需要依次向用户提出的问题。
每行包含若干空格分隔的正整数,每个正整数表示一个问题中包含的类别的编号,按照提问的顺序输出。
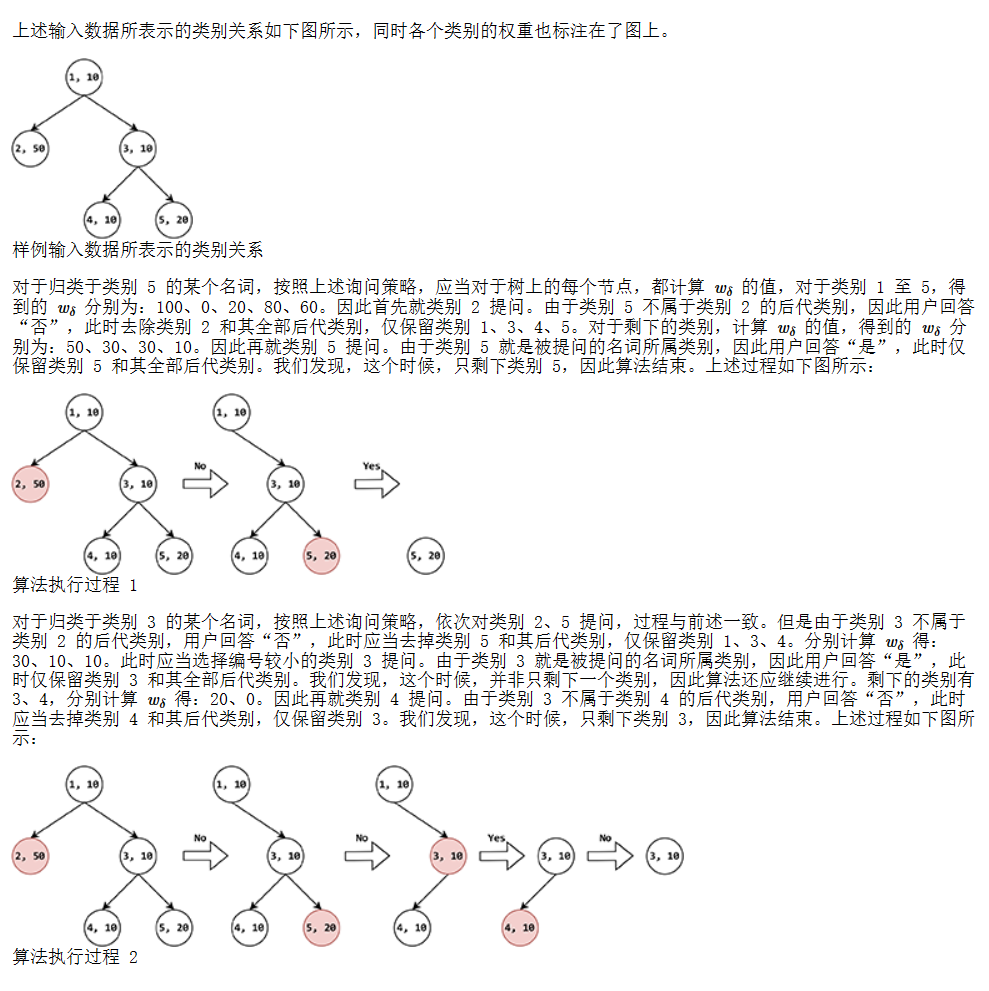
样例1输入
5 2
10 50 10 10 20
1 1 3 3
5
3
样例1输出
2 5
2 5 3 4
样例解释

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Rancher2部署MySQL无法挂载Longhorn创建的pvc,怎么办?
- 能见度监测站在交通中有哪些作用
- VScode远程连接服务器,Pycharm专业版下载及远程连接(深度学习远程篇)
- 04 思维导图的方式回顾ospf
- Java 基础(一)
- 史诗级别的UI、api测试思路和框架实现过程
- R4S软路由如何在iStoreOS后配置远程桌面本地电脑公网地址
- java spring cloud 企业工程管理系统源码+二次开发+定制化服务
- NLP深入学习(三):TF-IDF 详解以及文本分类/聚类用法
- 如何在本地部署现有气象大模型