VLCounter: Text-aware Visual Representation for Zero-Shot Object Counting
VLCounter: Text-aware Visual Representation for Zero-Shot Object Counting
VLCounter: Text-aware Visual Representation for Zero-Shot Object Counting
AAAI2024
https://github.com/seunggu0305/VLCounter
- 视觉语言模型
- 在FSC-147上比clip-count的MAE低了零点几
1. Visual-Language Base
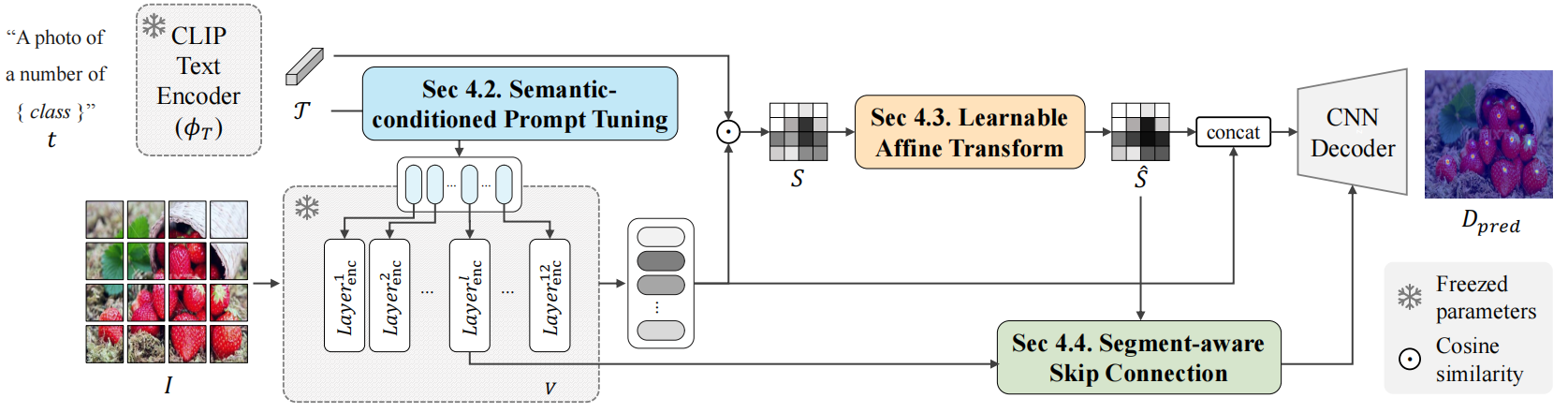
S i j ( V , T ) = v i j T T ∣ ∣ v i j ∣ ∣ ∣ T ∣ ∣ S_{i j}(\mathcal{V},\mathcal{T})=\frac{v_{i j}\mathcal{T}^T}{||v_{i j}|||\mathcal{T}||} Sij?(V,T)=∣∣vij?∣∣∣T∣∣vij?TT?
T: 语义嵌入向量 V: 块嵌入向量 S: 相似度图
S表示图像块和文本的相似度程度,可以帮助解码器定位目标。
D p r e d = ? d e c o d e r ( [ ν , S ] ) {\cal D}_{\mathrm{pred}}=\phi_{\mathrm{decoder}}([\nu,S]) Dpred?=?decoder?([ν,S]) L c o u n t = ∣ ∣ D p r e d ? D g t ∣ ∣ 2 2 {\mathcal{L}}_{\mathrm{count}}=||D_{\mathrm{pred}}-D_{\mathrm{gt}}||_{2}^{2} Lcount?=∣∣Dpred??Dgt?∣∣22?
2. Visual-Language Counter
2.1 语义条件下的提示微调 (SPT)
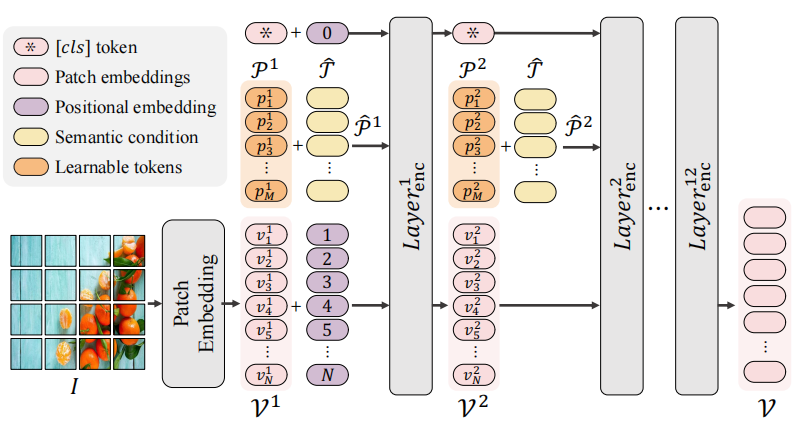
P ^ l = [ p 1 l + T ^ , p 2 l + T ^ , p M l + T ^ ] , \hat{\mathcal{P}}^l=[p_1^l+\hat{\mathcal{T}},p_2^l+\hat{\mathcal{T}},p_M^l+\hat{\mathcal{T}}], P^l=[p1l?+T^,p2l?+T^,pMl?+T^], [ [ c l s ] , _ , V l + 1 ] = L a y e r e n c l ( [ [ c l s ] , P ^ l , V l ] ) , [[cls],\_,\mathcal{V}^{l+1}]=Layer_{\mathrm{enc}}^{l}([[cls],\hat{\mathcal{P}}^{l},\mathcal{V}^{l}]), [[cls],_,Vl+1]=Layerencl?([[cls],P^l,Vl]),
目的是突出显示相应区域的目标
2.2 可学习的仿射变换 (LAT)
由于物体计数的目标是找到物体的中心点而不是整个物体区域,相似图S中包含的信息与训练期间需要回传的损失之间可能会存在差异。
通过将S变换为 S ^ \hat{S} S^, 围绕单独的物体建立更加任务相关的视觉语义关联
S ^ = W ? S + B \hat{S}=W\otimes S+B S^=W?S+B
W , B ∈ R H × W \begin{aligned}W,B\in&\mathbb{R}^{H\times W}\end{aligned} W,B∈?RH×W? 是可学习的矩阵,使用排名感知对比损失直接优化计数图 S ^ \hat{S} S^,以学习对象计数的正确激活度。
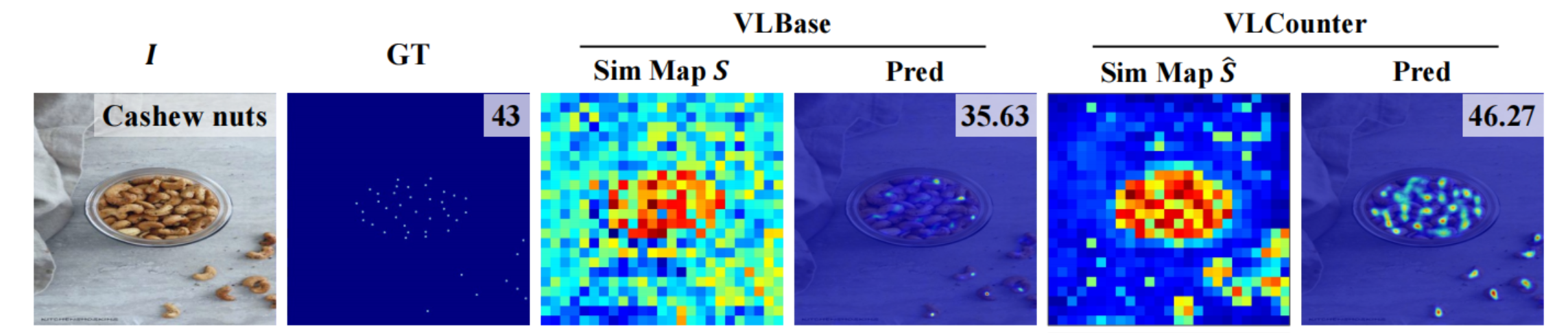
突出显示包含目标的区域,抑制不包含目标的区域
2.3 分段感知跳跃连接(SaSC)

为了使用CLIP特征中保留的局部语义信息, 采用跳跃连接, 将图片编码器的中间特征混合到解码器的对应层中, 保证模型对没有见过的类别的泛化能力
F k = L a y e r d e c k ( F k ? 1 + ? p r o j k ( V l ) ? S ^ ) , \mathcal{F}^k=Layer_{\mathrm{dec}}^k(\mathcal{F}^{k-1}+\phi_{\mathrm{proj}}^k(\mathcal{V}^l)\otimes\hat{S}), Fk=Layerdeck?(Fk?1+?projk?(Vl)?S^),
2.4 损失函数
L c o u n t \mathcal{L}_\mathrm{count} Lcount?训练整个模型以学习计数目标,但在SPT和LAT中的重点是学习生成针对计数的相似性映射, 所以采用排名感知对比损失来优化 S ^ \hat{S} S^,将对象中心附近的图像块赋予更高激活度。
将真实密度图标准化为在0和1之间映射的值, 来确定正负样本
L
r
a
n
k
=
?
∑
k
=
1
K
log
?
∑
S
^
i
∈
S
^
r
p
o
s
exp
?
(
S
^
i
/
τ
)
∑
S
^
j
∈
(
S
^
r
p
o
s
∪
S
^
r
n
e
g
)
exp
?
(
S
^
j
/
τ
)
\mathcal{L}_{\mathrm{rank}}=-\sum_{k=1}^K\log\frac{\sum_{\hat{S}_i\in\hat{S}_r^{\mathrm{pos}}}\exp(\hat{S}_i/\tau)}{\sum_{\hat{S}_j\in(\hat{S}_r^{\mathrm{pos}}\cup\hat{S}_r^{\mathrm{neg}})}\exp(\hat{S}_j/\tau)}
Lrank?=?k=1∑K?log∑S^j?∈(S^rpos?∪S^rneg?)?exp(S^j?/τ)∑S^i?∈S^rpos??exp(S^i?/τ)?
L
t
o
t
a
l
=
L
c
o
u
n
t
+
λ
?
L
r
a
n
k
,
\mathcal{L}_\mathrm{total}=\mathcal{L}_\mathrm{count}+\lambda\cdot\mathcal{L}_\mathrm{rank},
Ltotal?=Lcount?+λ?Lrank?,
3. 性能

4. 消融实验

M1就是VLBase,M5是VLCounter
M2加入语义条件下的提示微调后,MAE降低很多,表明了与语义条件相结合微调的重要性
M4加入分段感知跳跃连接,表明CLIP编码器中的分层中间表示在语义上也是有意义的存在。

在VPT中使用语义条件T可以使得提示更加语义特定
使用计数图S的语义条件可以抑制与对象无关的信息

由于计数任务主要假设每张图像中存在多个实例,将文本提示修改为复数形式也可以提高性能
5. 对比CLIP-count


Open-world Text-specified Object Counting
BMVC 2023
https://github.com/niki-amini-naieni/CounTX/
端到端的单阶段开放类别物体计数模型
zero-shot
1. CounTX

图像编码器: CLIP ViT-B-16(16x16的块尺寸, 12层, 最终嵌入向量维度是512), 没有用到输出的分类向量
文本编码器: CLIP ViT-B-16(context length是77, 12层, 最终嵌入向量维度是512)
特征交互模块: 使用了两个Transformer解码器层, 图像块特征作为query, 文本特征作为K和V, 来建模图像和文本的相似性
解码器: f?的输出被重塑成具有512通道的空间特征图。每个通道使用双线性插值放大到24×24像素。然后,通过具有256个滤波器的卷积层进行上采样,将其高度和宽度增加两倍, 操作做4次。将特征图的尺寸变为和输入图像一样, 但是有256个通道。这些通道使用一个1×1卷积组合成一个单通道密度图。该密度图通过求和来估计物体数量。
损失函数: L ( Y ^ , Y ) = 1 H × W ∑ p , q ( ( Y ^ ) p , q ? ( Y ) p , q ) 2 \mathcal{L}(\hat{Y},Y)=\frac1{H\times W}\sum_{p,q}((\hat{Y})_{p,q}-(Y)_{p,q})^2 L(Y^,Y)=H×W1?∑p,q?((Y^)p,q??(Y)p,q?)2
2. FSC-147-D

FSC-147的增强版本,对类别描述做了修正或更加详细的描述
大部分只是在原始类别名称前加了"the", 少部分做了修正或更加详细的描述
3. 性能
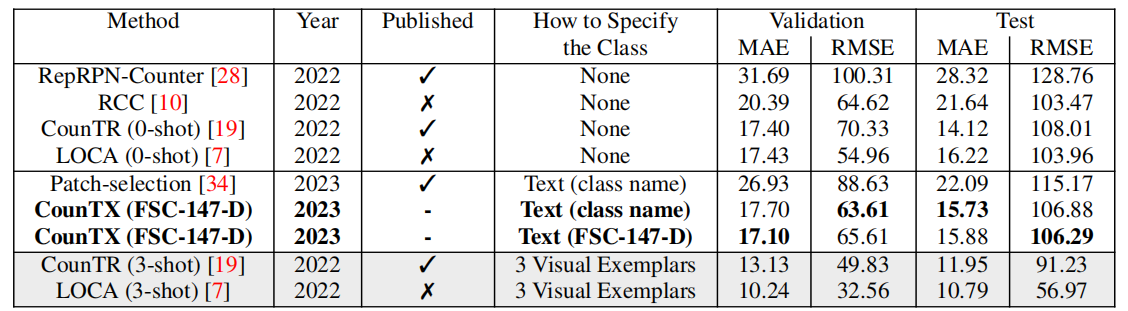
训练时使用的都是FSC-147-D
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!