Python爬虫练习:爬取网页需要信息
发布时间:2024年01月13日
首先要下载requests和lxml模块
命令为:pip install requests 和pip install lxml


第一步导入模块,发送请求,获取数据,并存入文件01.html
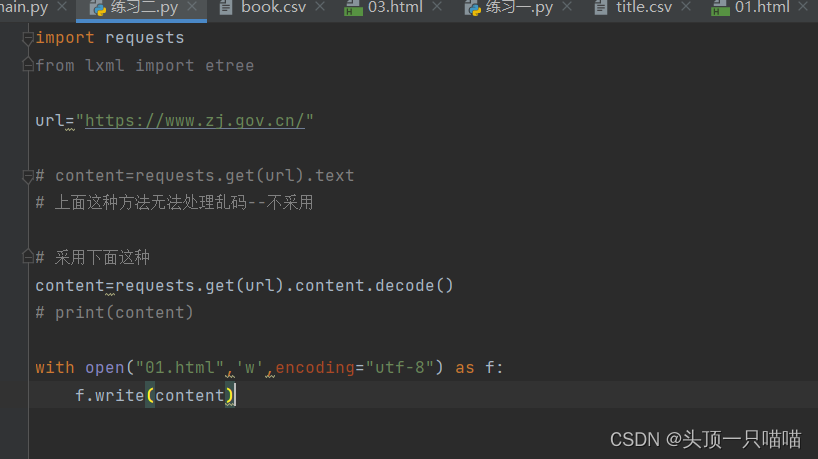 此时01.html为?(说明已经存入)
此时01.html为?(说明已经存入)
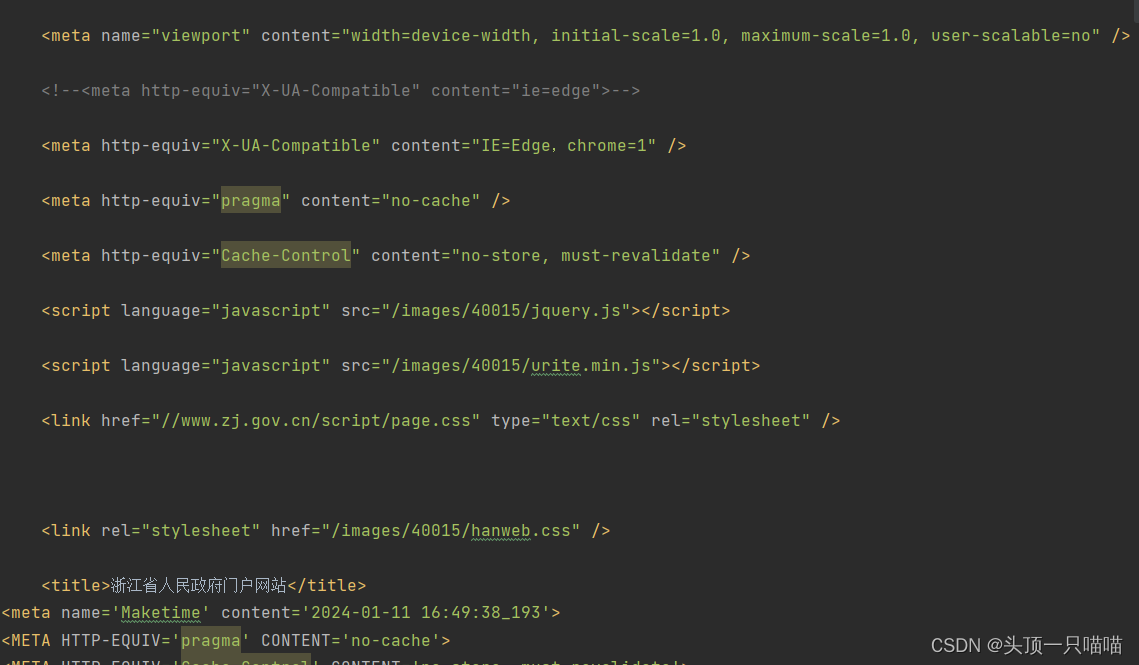
第二步:从01.html中读取数据,处理数据(获取标题)
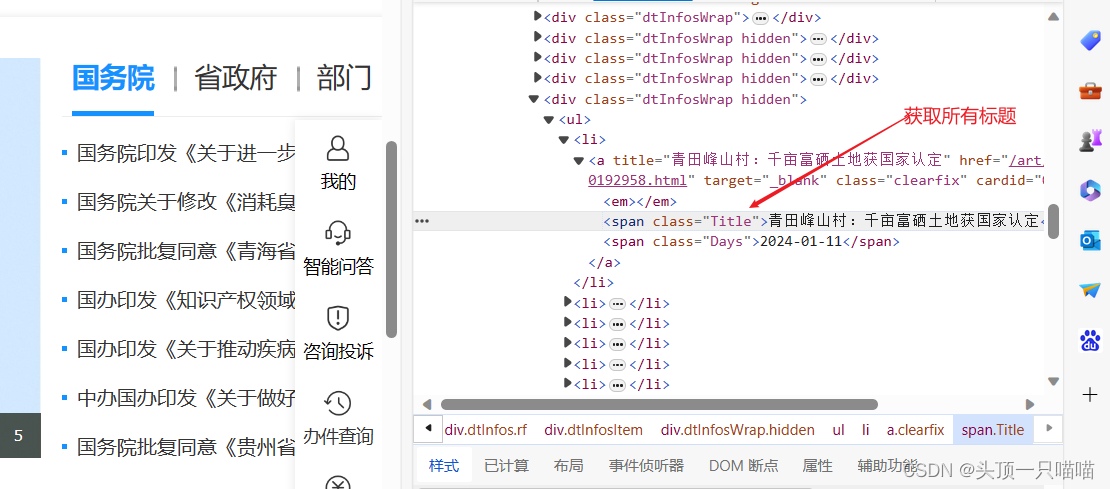
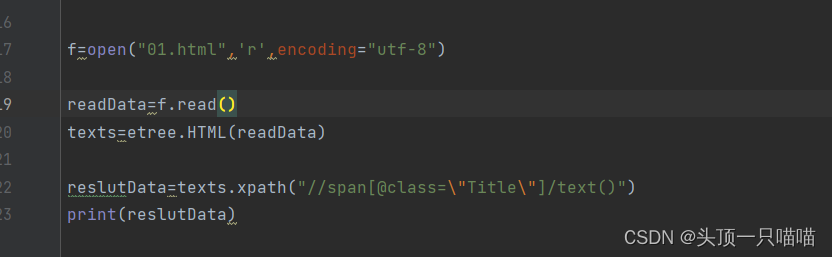
reslutData打印结果:
 ?
?
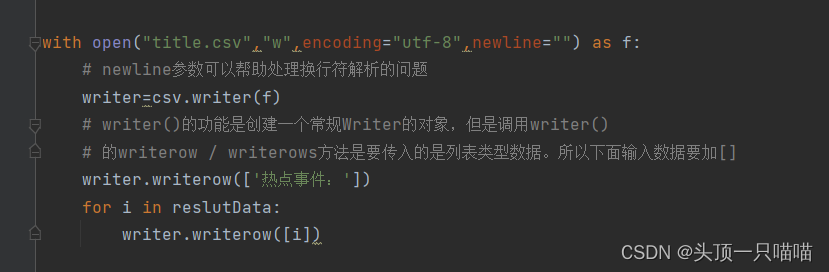
第三步将处理过后的数据存入title.csv文件,最前面加上:热点事件:
 ?
?
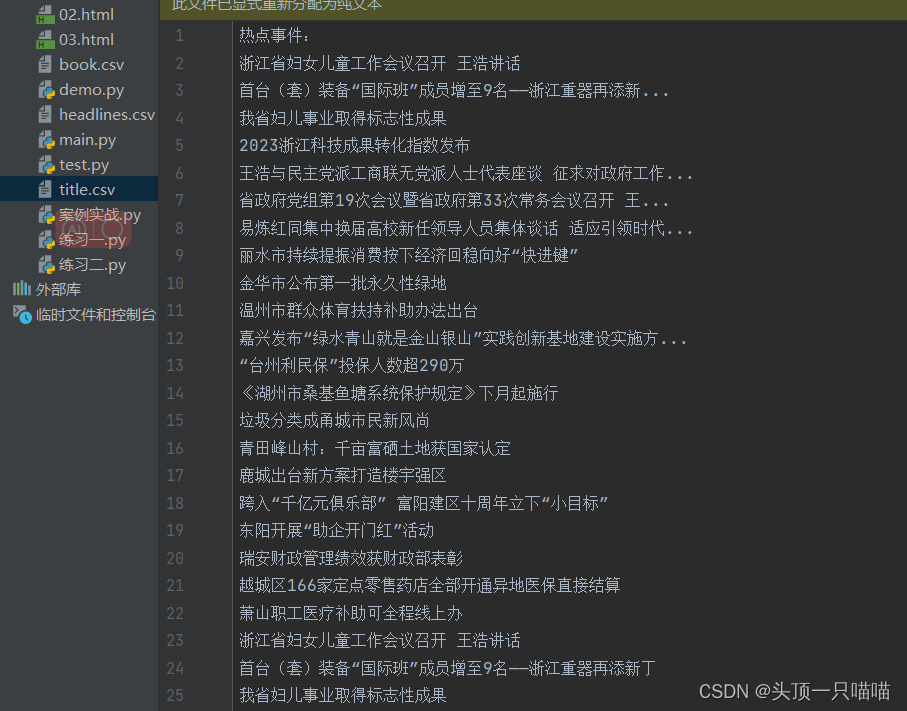
此时我们就得到了结果文件title.csv:
最后送上所有代码:
import csv
# 因为要将文件存为csv格式
import requests
from lxml import etree
url="https://www.zj.gov.cn/"
# content=requests.get(url).text
# 上面这种方法无法处理乱码--不采用
# 采用下面这种
content=requests.get(url).content.decode()
# print(content)
with open("01.html",'w',encoding="utf-8") as f:
f.write(content)
f=open("01.html",'r',encoding="utf-8")
readData=f.read()
texts=etree.HTML(readData)
# 转化为html格式
reslutData=texts.xpath("//span[@class=\"Title\"]/text()")
# 如上图所示我们要的是带有Title类的span标签
print(reslutData)
with open("title.csv","w",encoding="utf-8",newline="") as f:
# newline参数可以帮助处理换行符解析的问题
writer=csv.writer(f)
# writer()的功能是创建一个常规Writer的对象,但是调用writer()
# 的writerow / writerows方法是要传入的是列表类型数据。所以下面输入数据要加[]
writer.writerow(['热点事件:'])
for i in reslutData:
writer.writerow([i])?
?
文章来源:https://blog.csdn.net/zxn275266/article/details/135533241
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- CSAPP 第七章 Linking part2
- 计算机视觉(CV)技术的优势
- 【JS笔记】JavaScript语法 《基础+重点》 知识内容,快速上手(四)
- 【算法专题】递归算法
- Spring Boot快速搭建一个简易商城项目三,【加入购物车篇】
- 力扣(leetcode)第80题删除有序数组中的重复项 II(Python)
- 动态路由综合实验-RIP
- 计算机网络(第八版)期末复习(第三章数据链路层)
- 在线客服系统中的全渠道服务:多渠道整合与无缝沟通体验
- 【架构专题】不会业务稳定性建设架构师直接开除!!!