《Redis:NoSQL演进之路与Redis深度实践解析》
文章目录
关于NoSQL
在引出Redis之前,我们需要首先认识到NoSQL这个概念。也就是非关系型数据库。
我们在学校学的更多的是关系型数据库MySQL。这里引入了非关系型数据库-NoSQL。
为什么引入NoSQL
这里需要探讨的是MySQL的发展演进!
1、单机MySQL
在90年代,APP和web应用通过数据访问层(jdbc)访问数据库实例。
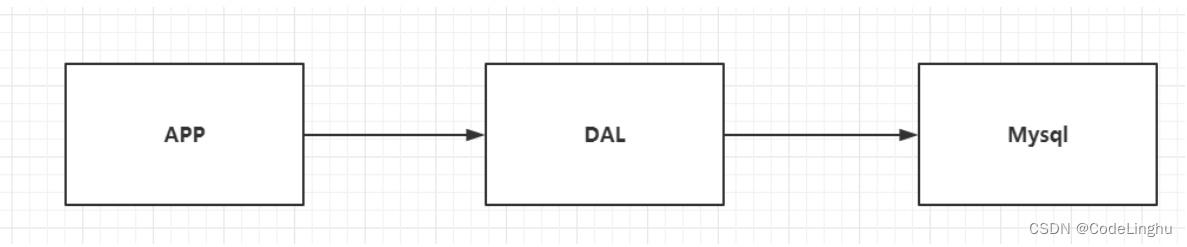
这个年代,网站的访问量不大,所以数据库的压力不会太大。而且使用的网页还是html静态网页,那么服务器的压力也不会大。
单机年代的数据库瓶颈
这个时代,数据的瓶颈如下:
- 数据量如果太大,一个机器放不下
- 数据索引量太多,机器内存也放不下
- 访问量(读写混合),一个服务器压力太大
出现上面的情况,所以进入了如下的新时代。
2、Memcached(缓存) + MySQL + 垂直拆分 (读写分离)
Memcached也是一个缓存技术,但是后来被Redis取代了。与memcached相比,Redis功能更强大,更受欢迎并且得到更好的支持。Memcached只能做Redis可以做的一小部分。即使Redis的功能重叠,Redis也更好。
以前的公司遇到高并发的问题,首先从产品的角度出发,优化数据结构和索引---->文件缓存(IO)----->Memcached缓存。
数据库的本质就是读和写,缓存技术的发展就是用来解决读!而读写分离、分库分表是用来解决 写!。
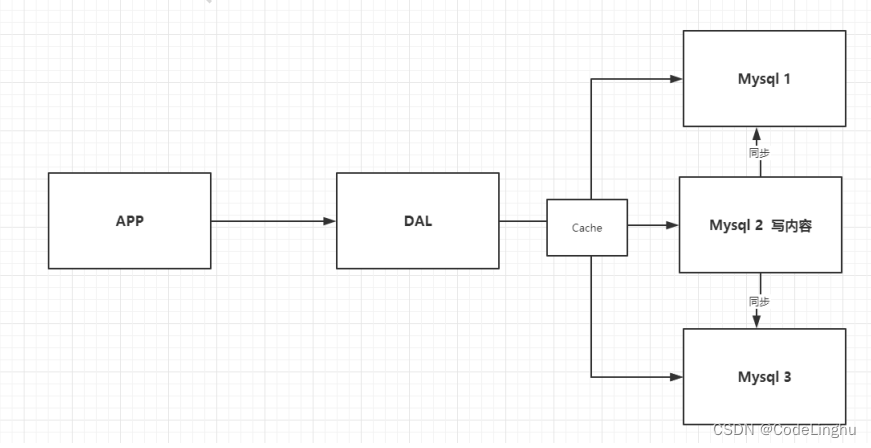
后来采用如上图所示,Cache用Memcached缓存技术,外加3台服务器,采用“主从同步,读写分离”的思想分担数据库服务器的压力。mysql2服务器负责将
Memcached缓存写入的数据同步到mysql1和mysql2服务器,最后让Memcached缓存分别读取mysql1和mysql2服务器的内容。
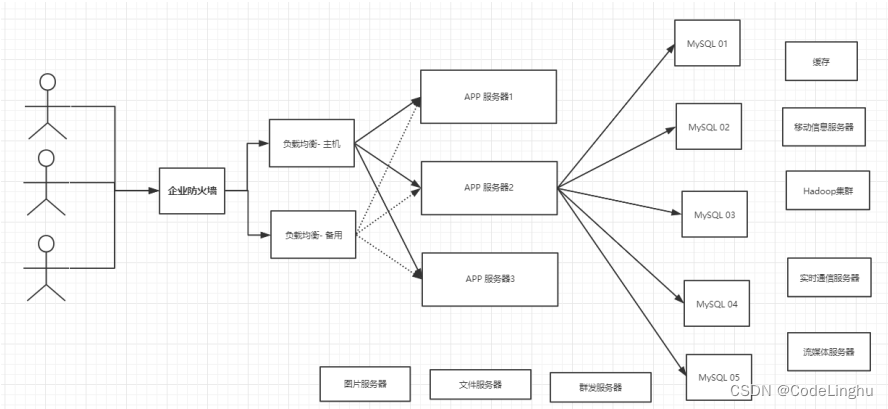
3、分库分表+水平拆分+MySQL集群
单个数据库节点,也就是主从节点,形成如下一个服务集群:

其实上面这个过程就叫做 分库分表、水平拆分、MySQL集群。
在这个集群中,S负责让M去读;M负责从缓存从写数据进来。

4、如今的网络架构
2010-2020这十年间,世界发生了变化,比如国家发射了卫星,很多互联网公司开始做定位,定位的实时传输数据量非常大,非常快,如果再用MySQL关系型数据库就不行了!这十年里还诞生了博客,微博等现象级产品,这些产品需要存储一些比较大的文件,博客,图片,数据库表很大,效率就会很低!!如果有一种专门的数据库来处理这种数据就很OK!
比如我们看到过,一篇博客爆款浏览量10w+!如果用传统的关系型数据库是不行的,数据量太大了,这里就需要先把文章数据源通过json格式存到Redis里面,然后分库分表进行读写存储。
目前一个基本的互联网项目!
5、总结
通过MySQL的发展演进,我们知道了用户的个人信息、社交网络、地理位置、用户自己生成的数据、用户日志等等数据是爆发增长的,这个时候我们就需要NoSQL数据库,因为NoSQL可以处理以上的情况。
NoSQL的定义
NoSQL = Not Only SQL (不仅仅是SQL)
关系型数据库:表格 ,行 ,列
泛指非关系型数据库的,随着web2.0互联网的诞生!传统的关系型数据库很难对付web2.0时代!尤其是超大规模的高并发的社区! 暴露出来很多难以克服的问题,NoSQL在当今大数据环境下发展的十分迅速,Redis是发展最快的,而且是我们当下必须要掌握的一个技术!很多的数据类型用户的个人信息,社交网络,地理位置。这些数据类型的存储不需要一个固定的格式!不需要多月的操作就可以横向扩展的 ! Map<String,Object> 使用键值对来控制!
NoSQL的分类
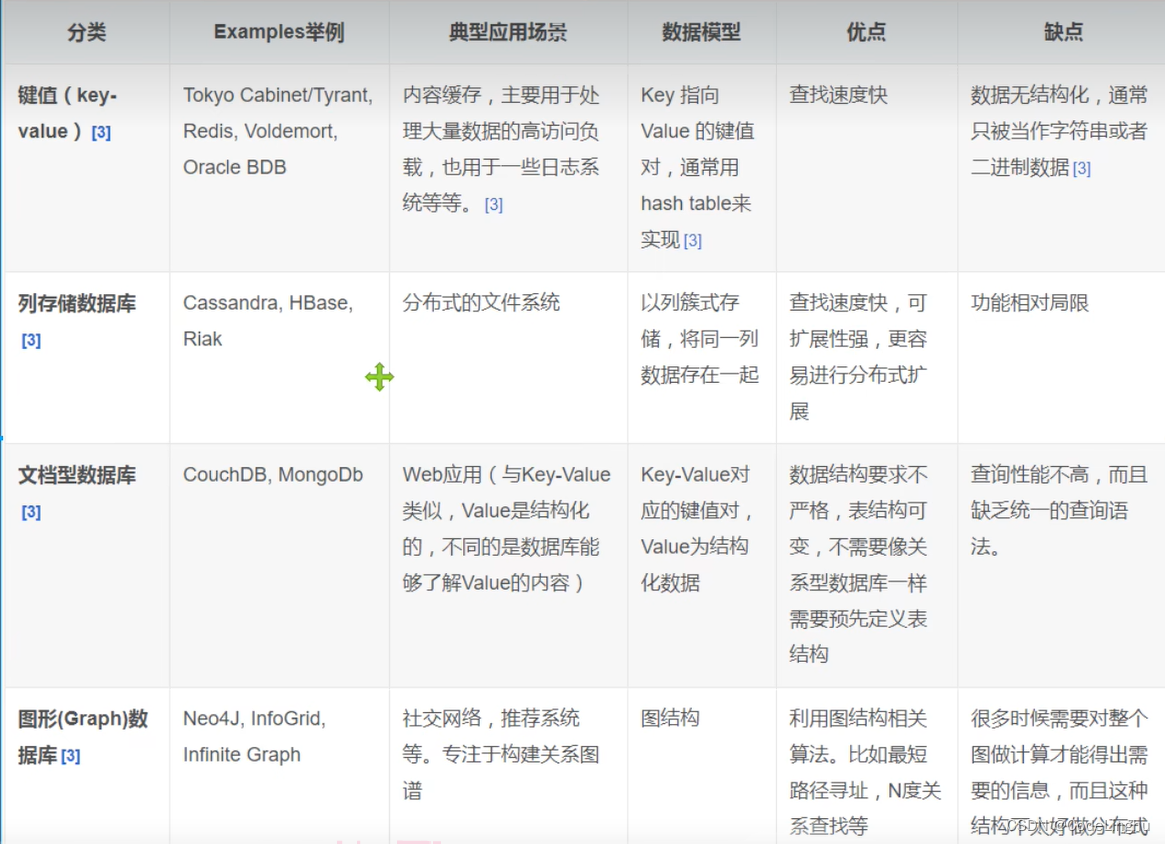
非关系型数据库的分类如下:
- KV键值对
- 文档型数据库
- 列存储数据库
- 图关系数据库
四者对比:
Redis入门
Redis(Remote Dictionary Server ),即远程字典服务 !
是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,
并提供多种语言的API
redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从同步)。免费和开源!是当下最热门的 NoSQL 技术之一!也被人们称之为结构化数据库!
Redis能干嘛?
- 内存存储、持久化,内存中是断电即失、所以说持久化很重要(rdb、aof)
- 效率高,可以用于高速缓存
- 发布订阅系统
- 地图信息分析
- 计时器、计数器(浏览量!)
Redis推荐都是在Linux服务器上搭建的,我们是基于Linux学习!
Redis基础知识
- Redis默认有6个数据库。默认使用的是第0个,可以使用
select切换数据库。
127.0.0.1:6379> select 3
OK
127.0.0.1:6379[3]> dbsize
(integer) 0
127.0.0.1:6379[3]>
127.0.0.1:6379[3]> set name linghu
OK
127.0.0.1:6379[3]> get name
"linghu"
127.0.0.1:6379[3]>
127.0.0.1:6379[3]> key *
(error) ERR unknown command `key`, with args beginning with: `*`,
127.0.0.1:6379[3]> keys *
1) "name"
127.0.0.1:6379[3]> flushdb
OK
127.0.0.1:6379[3]> flushall
OK
127.0.0.1:6379[3]> keys *
(empty list or set)
127.0.0.1:6379[3]>
五大数据类型
Redis 是一个开源(BSD许可)的,内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件MQ。 它支持多种类型的数据结构,如 字符串(strings), 散列(hashes), 列表(lists), 集合(sets), 有序集合(sorted sets) 与范围查询, bitmaps, hyperloglogs 和 地理空间(geospatial) 索引半径查询。 Redis 内置了 复制(replication),LUA脚本(Lua scripting), LRU驱动事件(LRU eviction),事务(transactions) 和不同级别的 磁盘持久化(persistence), 并通过Redis哨兵(Sentinel)和自动 分区(Cluster)提供高可用性(high availability)。
Redis-Key
Redis Keys 命令用于查找所有符合给定模式 pattern 的 key 。。
127.0.0.1:6379> keys * # 查看所有的key
(empty list or set)
127.0.0.1:6379> set name kuangshen # set key
OK
127.0.0.1:6379> keys *
1) "name"
127.0.0.1:6379> set age 1
OK
127.0.0.1:6379> keys *
1) "age"
2) "name"
127.0.0.1:6379> EXISTS name # 判断当前的key是否存在
(integer) 1
127.0.0.1:6379> EXISTS name1
(integer) 0
127.0.0.1:6379> move name 1 # 移除当前的key
(integer) 1
127.0.0.1:6379> keys *
1) "age"
127.0.0.1:6379> set name qinjiang
OK
127.0.0.1:6379> keys *
1) "age"
2) "name"
127.0.0.1:6379> clear
127.0.0.1:6379> keys *
1) "age"
2) "name"
127.0.0.1:6379> get name
"qinjiang"
127.0.0.1:6379> EXPIRE name 10 # 设置key的过期时间,单位是秒
(integer) 1
127.0.0.1:6379> ttl name # 查看当前key的剩余时间
(integer) 4
127.0.0.1:6379> ttl name
(integer) 3
127.0.0.1:6379> ttl name
(integer) 2
127.0.0.1:6379> ttl name
(integer) 1
127.0.0.1:6379> ttl name
(integer) -2
127.0.0.1:6379> get name
(nil)
127.0.0.1:6379> type name # 查看当前key的一个类型!
string
127.0.0.1:6379> type age
string
String(字符串)
127.0.0.1:6379[3]> set key1 v1 #设置值
OK
127.0.0.1:6379[3]> get key1 #获得值
"v1"
127.0.0.1:6379[3]> keys * #获取所有key
1) "age"
2) "key1"
127.0.0.1:6379[3]> exists key1 #判断某一个key是否存在
(integer) 1
127.0.0.1:6379[3]> append key1 "hello" #追加字符串。如果当前key不存在,相当于setkey
(integer) 7
127.0.0.1:6379[3]> get keys
(nil)
127.0.0.1:6379[3]> get key
(nil)
127.0.0.1:6379[3]> get key1
"v1hello"
127.0.0.1:6379[3]> strlen key1 #获取字符串长度!
(integer) 7
127.0.0.1:6379[3]> append key1 "linghu"
(integer) 13
127.0.0.1:6379[3]> get key1
"v1hellolinghu"
127.0.0.1:6379[3]>
127.0.0.1:6379[3]> set views 0 #初始浏览量为0
OK
127.0.0.1:6379[3]> get views
"0"
127.0.0.1:6379[3]> incr views #自增浏览量为1
(integer) 1
127.0.0.1:6379[3]> incr views
(integer) 2
127.0.0.1:6379[3]> get views
"2"
127.0.0.1:6379[3]> decr views #自减浏览量为1
(integer) 1
127.0.0.1:6379[3]> decr views
(integer) 0
127.0.0.1:6379[3]> incrby views 10 #可以设置步长,指定增量!
(integer) 10
127.0.0.1:6379[3]> incrby views 10
(integer) 20
127.0.0.1:6379[3]> decrby views 5
(integer) 15
127.0.0.1:6379[3]>
127.0.0.1:6379> set key1 "hello,linghu" #设置key1的值
OK
127.0.0.1:6379> get key1
"hello,linghu"
127.0.0.1:6379> getrange key1 0 3 #截取字符串[0,3]
"hell"
127.0.0.1:6379> getrange key1 0 -1 #获取全部的字符串 和get key是一样的
"hello,linghu"
#替换
127.0.0.1:6379> set key2 abcdefg
OK
127.0.0.1:6379> get key2
"abcdefg"
127.0.0.1:6379> setrange key2 1 xx # 指定替换的位置
(integer) 7
127.0.0.1:6379> get key2
"axxdefg"
127.0.0.1:6379> setrange key2 1 xx
(integer) 7
127.0.0.1:6379> setex key3 30 "hello" #30秒后key3会过期
OK
127.0.0.1:6379> ttl key3
(integer) 21 #21秒,倒计时30秒
127.0.0.1:6379> get key3
"hello"
##检查是否存在名为 mykey 的键。
#如果不存在,则设置该键的值为 "redis"。
#如果存在,则不执行任何操作。
127.0.0.1:6379> setnx mykey "redis"
(integer) 1
127.0.0.1:6379> keys *
# key3已经过期了
1) "key2"
2) "mykey"
3) "key1"
127.0.0.1:6379> ttl key3
(integer) -2
127.0.0.1:6379> setnx mykey "MongoDB" #如果myKey存在,创建失败
(integer) 0
127.0.0.1:6379> get mykey
"redis"
#批量存在和批量获取
127.0.0.1:6379> mset k1 v1 k2 v2 k3 v3 #同时设置多个值
OK
127.0.0.1:6379> keys *
1) "key2"
2) "key1"
3) "k3"
4) "k1"
5) "k2"
6) "mykey"
127.0.0.1:6379> mget k1 k2 k3 #同时获取多个值
1) "v1"
2) "v2"
3) "v3"
127.0.0.1:6379> msetnx k1 v1 k4 v4
(integer) 0
127.0.0.1:6379> get key4
(nil)
127.0.0.1:6379>
127.0.0.1:6379> mset user:1:name linghu user:1:age 2
OK
127.0.0.1:6379> mget user:1:name user:1:age
1) "linghu"
2) "2"
127.0.0.1:6379> getset db redis# 如果不存在值,则返回 nil
(nil)
127.0.0.1:6379> get db
"redis"
127.0.0.1:6379> getset db mongodb# 如果存在值,获取原来的值,并设置新的值
"redis"
127.0.0.1:6379> get db
"mongodb"
127.0.0.1:6379>
List(列表)
127.0.0.1:6379> lpush list one #将一个或多个值,拆入到列表头部
(integer) 1
127.0.0.1:6379> lpush list two
(integer) 2
127.0.0.1:6379> lpush list three
(integer) 3
127.0.0.1:6379> lrange list 0 -1 #获取到list表中的所有元素
1) "three"
2) "two"
3) "one"
127.0.0.1:6379> lrange list 0 1
1) "three"
2) "two"
127.0.0.1:6379> rpush list righr
(integer) 4
127.0.0.1:6379> lrange list 0 -1
1) "three"
2) "two"
3) "one"
4) "righr"
127.0.0.1:6379> lpop list#移除列表左边第一个元素
"three"
127.0.0.1:6379> rpop list#移除列表右边第一个元素
"righr"
127.0.0.1:6379> lrange list 0 -1
1) "two"
2) "one"
127.0.0.1:6379> lindex list 1# 获取列表第一个索引的元素值
"one"
127.0.0.1:6379> lindex list 0
"two"
#获取list列表的长度
127.0.0.1:6379> llen list
(integer) 2
127.0.0.1:6379>
127.0.0.1:6379> lrange list 0 -1
1) "two"
2) "one"
127.0.0.1:6379> lrem list 1 one #移除指定的值
(integer) 1
127.0.0.1:6379> lrange list 0 -1
1) "two"
127.0.0.1:6379> lpush list three
(integer) 2
127.0.0.1:6379> keys *
1) "list"
2) "k3"
3) "k1"
4) "user:1:age"
5) "k2"
6) "mykey"
7) "key2"
8) "user:1:name"
9) "db"
10) "key1"
127.0.0.1:6379> rpush mylist "hello"
(integer) 1
127.0.0.1:6379> rpush mylist "hello1"
(integer) 2
127.0.0.1:6379> rpush mylist "hello2"
(integer) 3
127.0.0.1:6379> rpush mylist "hello3"
(integer) 4
127.0.0.1:6379> ltrim mylist 1 2
OK
127.0.0.1:6379> lrange mylist 0 -1
1) "hello1"
2) "hello2"
127.0.0.1:6379> rpush mylist "hello"# 移除列表最后一个元素。将他移动到新的列表中
(integer) 3
127.0.0.1:6379> rpush mylist "hello1"
(integer) 4
127.0.0.1:6379> rpush mylist "hello2"
(integer) 5
127.0.0.1:6379> rpoplpush mylist myotherlist
"hello2"
127.0.0.1:6379> lrange mylist 0 -1
1) "hello1"
2) "hello2"
3) "hello"
4) "hello1"
127.0.0.1:6379> exists list
(integer) 1
127.0.0.1:6379> lset list 0 item
OK
127.0.0.1:6379>
127.0.0.1:6379> lrange list 0 0
1) "item"
127.0.0.1:6379> lset list 1 other
OK
127.0.0.1:6379> rpush mylist "hello"
(integer) 5
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> rpush mylist "hello"
(integer) 1
127.0.0.1:6379> rpush mylist "world"
(integer) 2
127.0.0.1:6379> linsert mylist before "world" "other"
(integer) 3
#将某个具体的值插入到指定元素之前
127.0.0.1:6379> lrange mylist 0 -1
1) "hello"
2) "other"
3) "world"
127.0.0.1:6379> linsert mylist after world new
(integer) 4
127.0.0.1:6379> lrange mylist 0 -1
1) "hello"
2) "other"
3) "world"
4) "new"
127.0.0.1:6379>
小结
- 它实际上是一个链表,before,after,left,right都可以插入值
- 如果key不存在,就会创建新链表
- 如果key存在,新增内容
- 如果移除所有值,空链表,也代表不存在
- 在两边插入或者改动值,效率最高!中间元素,相对来说效率会低一点!
Set(集合)
127.0.0.1:6379> sadd myset "hello"
(integer) 1
127.0.0.1:6379> sadd myset "linghu"
(integer) 1
127.0.0.1:6379> sadd myset "love linghu"
(integer) 1
127.0.0.1:6379> smembers myset
1) "linghu"
2) "love linghu"
3) "hello"
127.0.0.1:6379> sismember myset hello
(integer) 1
127.0.0.1:6379> sismember myset world
(integer) 0
127.0.0.1:6379> scard myset
(integer) 3
127.0.0.1:6379> srem myset hello
(integer) 1
127.0.0.1:6379> scard myset
(integer) 2
127.0.0.1:6379> smembers myset
1) "linghu"
2) "love linghu"
127.0.0.1:6379>
127.0.0.1:6379> srandmember myset
"love linghu"
127.0.0.1:6379>
#随机删除一些元素
127.0.0.1:6379> spop myset
"linghu"
127.0.0.1:6379> smembers myset
1) "love linghu"
127.0.0.1:6379>127.0.0.1:6379> sadd myset "hello"
(integer) 1
127.0.0.1:6379> sadd myset "world"
(integer) 1
127.0.0.1:6379> sadd myset "linghu"
(integer) 1
127.0.0.1:6379> sadd myset2 "set2"
(integer) 1
#将一个特定的值随机移动到另外一个set集合中
127.0.0.1:6379> smove myset myset2 "linghu"
(integer) 1
127.0.0.1:6379> smembers myset
1) "world"
2) "hello"
127.0.0.1:6379> smembers myset2
1) "set2"
2) "linghu"
127.0.0.1:6379>
Hash(哈希)
127.0.0.1:6379> hset myhash field1 linghu
(integer) 1
127.0.0.1:6379> hget myhash field1
"linghu"
127.0.0.1:6379> hset myhash field1 hello field2 world
(integer) 1
127.0.0.1:6379> hmset myhash field1 hello field2 world
OK
127.0.0.1:6379> hmget myhash field1 field2
1) "hello"
2) "world"
127.0.0.1:6379> hgetall myhash
1) "field1"
2) "hello"
3) "field2"
4) "world"
127.0.0.1:6379> hdel myhash field1
(integer) 1
127.0.0.1:6379> hgetall myhash
1) "field2"
2) "world"
127.0.0.1:6379> hlen myhash
(integer) 1
127.0.0.1:6379> hexists myhash field1
(integer) 0
127.0.0.1:6379> hexists myhash field3
(integer) 0
127.0.0.1:6379> hkeys myhash
1) "field2"
127.0.0.1:6379> hvals myhash
1) "world"
127.0.0.1:6379>
127.0.0.1:6379> hset myhash field3 5 #指定增量
(integer) 1
127.0.0.1:6379> hincrby myhash field3 1
(integer) 6
127.0.0.1:6379> hincrby myhash field3 -1
(integer) 5
127.0.0.1:6379> hsetnx myhash field4 hello #如果不存在则可以设置
(integer) 1
127.0.0.1:6379> hsetnx myhash field4 world #如果存在则不能设置
(integer) 0
127.0.0.1:6379>
Zset(有序集合)
127.0.0.1:6379> zadd myset 1 one
(integer) 1
127.0.0.1:6379> zadd myset 2 two 3 three #添加多个值
(integer) 2
127.0.0.1:6379> zrange myset 0 -1
1) "one"
2) "two"
3) "three"
127.0.0.1:6379>
#排序如何实现?
127.0.0.1:6379> zadd salary 2500 xiaohong#添加3个用户
(integer) 1
127.0.0.1:6379> zadd salary 5000 zhangsan
(integer) 1
127.0.0.1:6379> zadd salary 500 linghu
(integer) 1
127.0.0.1:6379> zrangebyscore salary -inf +inf#显示全部用户,从小到大
1) "linghu"
2) "xiaohong"
3) "zhangsan"
127.0.0.1:6379> zrevrange salary 0 -1
1) "zhangsan"
2) "xiaohong"
3) "linghu"
127.0.0.1:6379> zrangebyscore salary -inf +inf withscores
1) "linghu"
2) "500"
3) "xiaohong"
4) "2500"
5) "zhangsan"
6) "5000"
127.0.0.1:6379> zrangebyscore salary -inf 2500 withscores#显示工资小于2500员工的升序排序
1) "linghu"
2) "500"
3) "xiaohong"
4) "2500"
127.0.0.1:6379> zrange salary 0 -1
1) "linghu"
2) "xiaohong"
3) "zhangsan"
127.0.0.1:6379> zrem salary linghu
(integer) 1
#移除rem中的元素
127.0.0.1:6379> zrange salary 0 -1
1) "xiaohong"
2) "zhangsan"
127.0.0.1:6379> zcard salary
(integer) 2
127.0.0.1:6379> zadd myset 1 hello
(integer) 1
127.0.0.1:6379> zadd myset 2 world 3 linghu
(integer) 2
127.0.0.1:6379> zcount myset 1 3
(integer) 6
127.0.0.1:6379> zcount myset 1 2
(integer) 4
127.0.0.1:6379> zrange myset 0 -1
1) "hello"
2) "one"
3) "two"
4) "world"
5) "linghu"
6) "three"
127.0.0.1:6379>
三种特殊数据类型
Geospatial地理位置
Geospatial Indexes 是 Redis 提供的一种数据结构,用于存储和查询地理位置信息。它可以将地理位置的经度和纬度编码为二维平面上的点,并支持根据距离或矩形区域查询附近的地理位置点,这使得它在很多场景下被广泛应用,比如 LBS(Location Based Service)、智能推荐、出行规划等。
geoadd命令
geoadd命令用来添加地理位置,我们一般会下载城市数据,直接通过Java程序一次性导入!
127.0.0.1:6379> geoadd china:city 116.40 39.90 beijing
(integer) 1
127.0.0.1:6379> geoadd china:city 121.47 31.23 shanghai
(integer) 1
127.0.0.1:6379> geoadd china:city 106.50 29.53 chongqing 114.05 22.52 shenzhen
(integer) 2
127.0.0.1:6379>
geopos命令
获取当前定位:一定是一个坐标值!
127.0.0.1:6379> geopos china:city chongqing
1) 1) "106.49999767541885376"
2) "29.52999957900659211"
127.0.0.1:6379>
geodist命令
两人之间的距离!
单位:
- m表示单位米
- km表示千米
- mi表示英里
- ft表示英尺
127.0.0.1:6379> geodist china:city beijing shanghai km#上海到北京的直线距离是1067km
"1067.3788"
127.0.0.1:6379>
georadius命令
以给定的经纬度为中心,找出某一半径内的元素。
如何查找附近的人?需要先获得所有附近人的地址,定位!,通过半径来查询!
127.0.0.1:6379> georadius china:city 110 30 1000 km #以110,30这个经纬度为中心,寻找方圆1000km内的城市
1) "chongqing"
2) "shenzhen"
127.0.0.1:6379> georadius china:city 110 30 1000 km withdist#显示到中间距离的位置
1) 1) "chongqing"
2) "341.9374"
2) 1) "shenzhen"
2) "924.6408"
127.0.0.1:6379> georadius china:city 110 30 1000 km withcoord#显示他人的定位信息
1) 1) "chongqing"
2) 1) "106.49999767541885376"
2) "29.52999957900659211"
2) 1) "shenzhen"
2) 1) "114.04999762773513794"
2) "22.5200000879503861"
127.0.0.1:6379> georadius china:city 110 30 1000 km withcoord count 1 #显示这个距离周围的信息指定数量,只显示1个
1) 1) "chongqing"
2) 1) "106.49999767541885376"
2) "29.52999957900659211"
127.0.0.1:6379> georadius china:city 110 30 1000 km withcoord count 2
1) 1) "chongqing"
2) 1) "106.49999767541885376"
2) "29.52999957900659211"
2) 1) "shenzhen"
2) 1) "114.04999762773513794"
2) "22.5200000879503861"
127.0.0.1:6379>
georadiusmember命令
127.0.0.1:6379> georadiusbymember china:city beijing 1000 km#找出位于指定元素周围的其他元素
1) "beijing"
127.0.0.1:6379> georadiusbymember china:city beijing 500 km
1) "beijing"
127.0.0.1:6379> georadiusbymember china:city shanghai 500 km
1) "shanghai"
127.0.0.1:6379>
geohash命令
127.0.0.1:6379> geohash china:city beijing chongqing #将二维的经纬度转换为一维的字符串
1) "wx4fbxxfke0"
2) "wm5xzrybty0"
127.0.0.1:6379>
总结
- GEO的底层实现原理其实是Zset!
Hyperloglog命令
网页的访问,一个人访问一个网站多次,但是还是算作一个人!
如果允许容错,那么一定使用 Hyperloglog。
127.0.0.1:6379> pfadd mykey a b c d e f g h i j#创建第一组元素 mykey
(integer) 1
127.0.0.1:6379> pfcount mykey#统计mykey元素的基数数量
(integer) 10
127.0.0.1:6379> pfadd mykey2 i j z x c v b n m#创建第二组元素mykey2
(integer) 1
127.0.0.1:6379> pfcount mykey2
(integer) 9
127.0.0.1:6379> pfmerge mykey3 mykey mykey2合并两组mykey mykey2=》mykey3并集
OK
127.0.0.1:6379> pfcount mykey3#看并集的数量!
(integer) 15
127.0.0.1:6379>
Bitmap命令
位存储
统计用户信息、活跃,不活跃;登录,未登录;打卡,未打卡!两个状态的场景,都可以用Bitmaps!
Bitmap位图,数据结构!都是操作二进制位来进行记录,就只有0和1两个状态!
127.0.0.1:6379> setbit sign 0 1
(integer) 0
127.0.0.1:6379> setbit sign 1 0
(integer) 0
127.0.0.1:6379> setbit sign 2 0
(integer) 0
127.0.0.1:6379> setbit sign 3 1
(integer) 0
127.0.0.1:6379> setbit sign 4 1
(integer) 0
127.0.0.1:6379> setbit sign 5 0
(integer) 0
127.0.0.1:6379> setbit sign 6 0
(integer) 0
127.0.0.1:6379> getbit sign 3#查看某一天是否打卡
(integer) 1
127.0.0.1:6379> getbit sign 6
(integer) 0
127.0.0.1:6379> bitcount sign#统计这周的打卡记录
(integer) 3
127.0.0.1:6379>
以上是用,bitmap来记录周一到周日打卡!
周一:1 周二:0 周三:0 周四:1…
事务
Redis事务的本质:一组命令的集合!一个事务中所有命令都会被序列化,在事务执行过程中,会按照顺序执行!
Redis事务没有没有隔离级别的概念!
Redis单条命令式保存原子性的,但是事务不保证原子性!
Redis的事务:
- 开启事务(multi)
- 命令入队(…)
- 执行事务(exec)
正常执行事务
127.0.0.1:6379> multi #开启事务,就跟点了一个鞭炮一样
OK
127.0.0.1:6379> set k1 v1
QUEUED
127.0.0.1:6379> set k2 v2
QUEUED
127.0.0.1:6379> get k2
QUEUED
127.0.0.1:6379> set k3 v3
QUEUED
127.0.0.1:6379> exec #执行事务
1) OK
2) OK
3) "v2"
4) OK
127.0.0.1:6379>
放弃事务
127.0.0.1:6379> multi#开启事务
OK
127.0.0.1:6379> set k1 v1
QUEUED
127.0.0.1:6379> set k2 v2
QUEUED
127.0.0.1:6379> set k4 v4
QUEUED
127.0.0.1:6379> discard#取消事务
OK
127.0.0.1:6379> get k4#事务队列中的命令都不会被执行!
(nil)
127.0.0.1:6379>
编译型异常【代码有问题,命令有问题,事务中所有命令不再执行】
127.0.0.1:6379> multi
OK
127.0.0.1:6379> set k1 v1
QUEUED
127.0.0.1:6379> set k2 v2
QUEUED
127.0.0.1:6379> set k3 v3
QUEUED
127.0.0.1:6379> getset k3#错误的命令
(error) ERR wrong number of arguments for 'getset' command
127.0.0.1:6379> set k4 v4
QUEUED
127.0.0.1:6379> set k5 v5
QUEUED
127.0.0.1:6379> exec#执行事务报错
(error) EXECABORT Transaction discarded because of previous errors.
127.0.0.1:6379> get k5#所有命令都不会被执行~
(nil)
127.0.0.1:6379>
运行时异常I/O(如果事务队列中存在语法错误,那么执行命令的时候,其他命令可以正常执行,错误命令抛出异常~)
127.0.0.1:6379> set k1 "v1"
OK
127.0.0.1:6379> multi
OK
127.0.0.1:6379> incr k1#会执行失败~
QUEUED
127.0.0.1:6379> set k2 v2
QUEUED
127.0.0.1:6379> set k3 v3
QUEUED
127.0.0.1:6379> get k3
QUEUED
127.0.0.1:6379> exec
1) (error) ERR value is not an integer or out of range#虽然第一条命令执行报错了,但是其他命令依旧正常执行!
2) OK
3) OK
4) "v3"
127.0.0.1:6379> get k2
"v2"
127.0.0.1:6379> get k3
"v3"
127.0.0.1:6379>
总结
Redis支持乐观锁。
悲观锁
- 很悲观,认为什么时候都会出现问题,无论做什么都会加锁
乐观锁
- 很乐观,认为什么时候都不会出现问题,所以不会上锁!更新数据的时候去判断一下,在此期间是否有人去修改过这个数据
- 获取Version
- 更新的时候比较version
Jedis
Jedis是Redis官方推出的可以用Java操作Redis的连接开发工具!属于Java操作Redis的中间件。
Ping测试
- 连接数据库
- 操作命令
- 断开连接
<dependencies>
<!-- https://mvnrepository.com/artifact/redis.clients/jedis -->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>5.1.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.alibaba.fastjson2/fastjson2 -->
<dependency>
<groupId>com.alibaba.fastjson2</groupId>
<artifactId>fastjson2</artifactId>
<version>2.0.43</version>
</dependency>
</dependencies>
package com.linghu;
import redis.clients.jedis.Jedis;
/**
* @author linghu
* @date 2024/1/9 11:33
*/
public class TestPing {
public static void main(String[] args) {
Jedis jedis = new Jedis("127.0.0.1",6379);
System.out.println(jedis.ping());
}
}
常用API
所有的API命令都是上面对应学过的Redis命令,一个都没有变化!
- String
- List
- Set
- Hash
- ZSet
package com.linghu;
import org.json.JSONObject;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.Transaction;
/**
* @author linghu
* @date 2024/1/9 11:33
*/
public class TestPing {
public static void main(String[] args) {
Jedis jedis = new Jedis("127.0.0.1",6379);
jedis.flushDB();
JSONObject jsonObject = new JSONObject();
jsonObject.put("hello","world");
jsonObject.put("name","linghu");
//开启事务
Transaction multi = jedis.multi();
String result = jsonObject.toString();
try {
multi.set("user1",result);
multi.set("user2",result);
int i=1/0;//代码抛出异常,执行失败!
multi.exec();//执行事务!
} catch (Exception e) {
multi.discard();//放弃事务
e.printStackTrace();
} finally {
System.out.println(jedis.get("user1"));
System.out.println(jedis.get("user2"));
jedis.close();//关闭连接
}
}
}
SpringBoot整合
1、导入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
<version>2.7.10</version>
</dependency>
2、配置连接
spring.redis.host=127.0.0.1
spring.redis.port=6379
3、测试
package com.linghu;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.test.context.ActiveProfiles;
import org.springframework.test.context.junit4.SpringRunner;
import javax.annotation.Resource;
/**
* @author linghu
* @date 2024/1/15 11:02
*/
@SpringBootTest(classes = Redis02SpringbootApplicationTest.class)
@RunWith(SpringRunner.class)
@ActiveProfiles(profiles = {"dev"})
public class Redis02SpringbootApplicationTest {
@Resource
private RedisTemplate<String, String> redisTemplate;
@Test
public void contextLoads(){
redisTemplate.opsForValue().set("mykey","关注令狐");
System.out.println(redisTemplate.opsForValue().get("mykey"));
}
}
Redis持久化
Redis是内存数据库,如果不将内存中的数据库状态保存到磁盘,那么一旦服务器进程退出,服务器中的数据库状态也会消失。所以Redis提供了持久化功能。【主从设备中经常放到从设备上】
RDB(Redis DataBase)
什么是RDB?
RDB是Redis的一种数据持久化到磁盘的策略,是一种以内存快照形式保存Redis数据的方式。所谓快照,就是把某一时刻的状态以文件的形式进行全量备份到磁盘,这个快照文件就称为RDB文件,其中RDB是Redis DataBase的缩写。
AOF(Append Only File)
Redis会将每一个收到的写命令都通过write函数追加到文件中。通俗的理解就是日志记录。【不怎么使用】
AOF 保存的是 appendonly.aof文件
优点:
- 每一次修改都同步,文件的完整会更加好!
- 每秒同步一次,可能会丢失一秒的数据
- 从不同步,效率最高的!
缺点:
- 相对于数据文件来说,aof远远大于 rdb,修复的速度也比 rdb慢!
- Aof 运行效率也要比 rdb 慢,所以我们redis默认的配置就是rdb持久化
Redis发布订阅
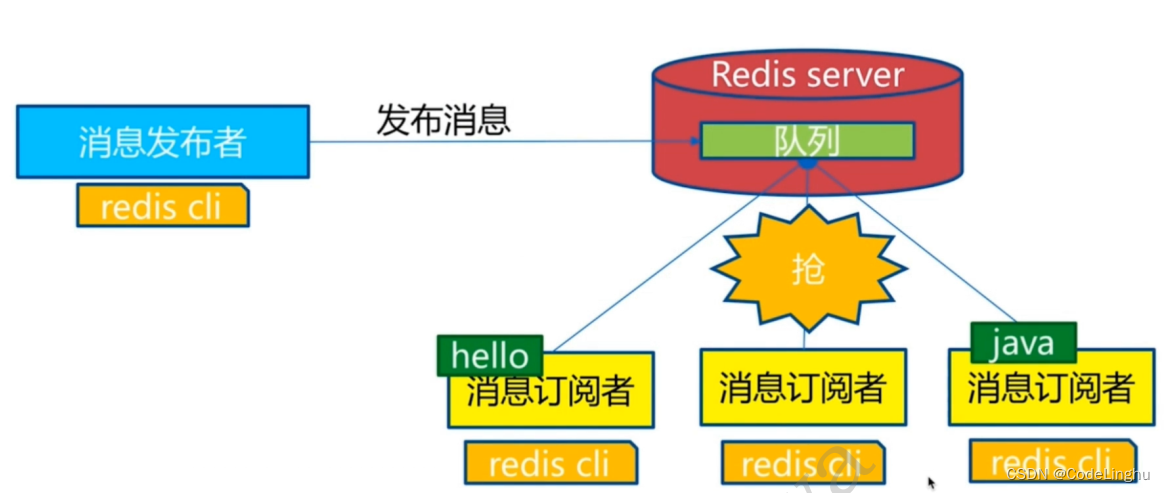
Redis发布订阅(pub/sub)是一种消息通信模式:发送者pub发送消息,订阅者sub接收消息。微信,微博,关注系统。
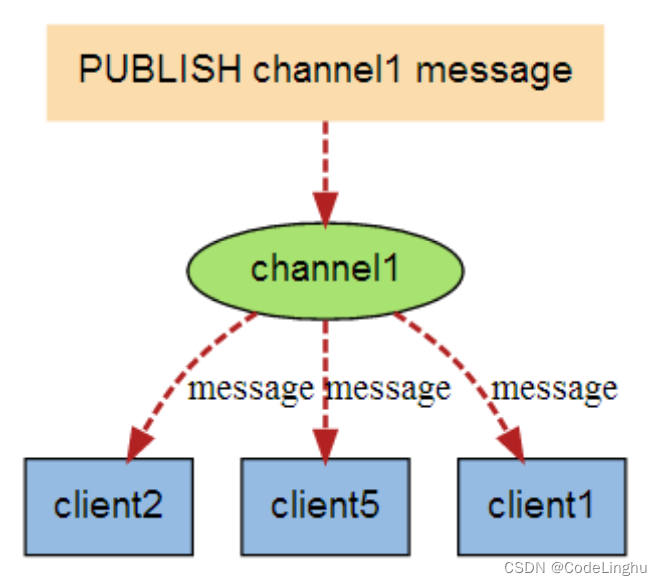
下图展示了频道channel1,以及订阅这个频道的三个客户端-client2、client5和client1之间的关系:
订阅端:
127.0.0.1:6379> subscribe linghu #订阅一个频道linghu
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "linghu"
3) (integer) 1
1) "message"
2) "linghu"
3) "hello,linghu"#收到的推送的消息
发送端:
127.0.0.1:6379> publish linghu "hello,linghu"#发布者发布消息到频道上
(integer) 1
127.0.0.1:6379>
哨兵模式
当主服务器宕机后,需要手动把一台从服务器切换成主服务器,这就需要人工干预,费时费力。这个时候提出了 哨兵模式。
Redis从2.8开始正式提供了Sentinel(哨兵)架构来解决这个问题。
哨兵模式是一种特殊模式,首先Redis提供了哨兵的命令,哨兵是一个独立的进程,作为进程,它会独立运行。其原理是 哨兵通过发送命令,等待Redis服务器响应,从而监控运行多个Redis实例。
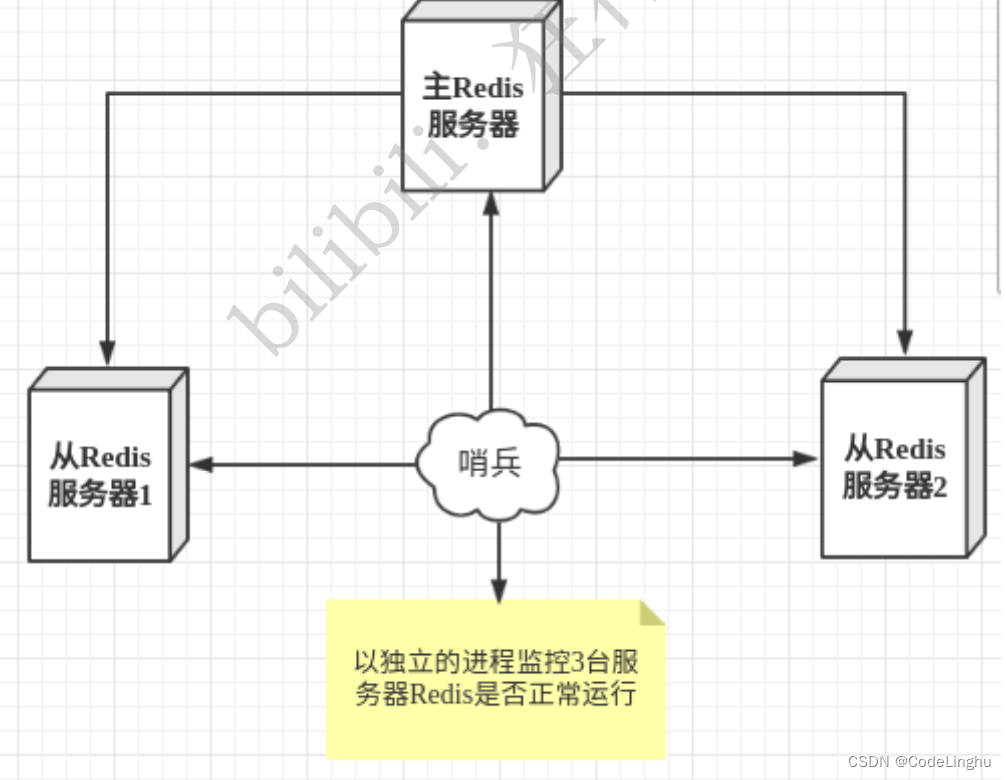
哨兵的两个作用:
- 通过发送命令,让Redis服务器返回监控其运行状态,包括主服务器和从服务器。
- 当哨兵检测到master宕机,会自动将slave切换成master,然后通过发布订阅模式通知其他从服务器,修改配置文件,让他们切换主机。
一个哨兵对Redis服务器进行监控可能会出现问题,为此,我们可以使用多个哨兵进行监控。各个哨兵之间还会进行监控,这样就形成了多哨兵模式。
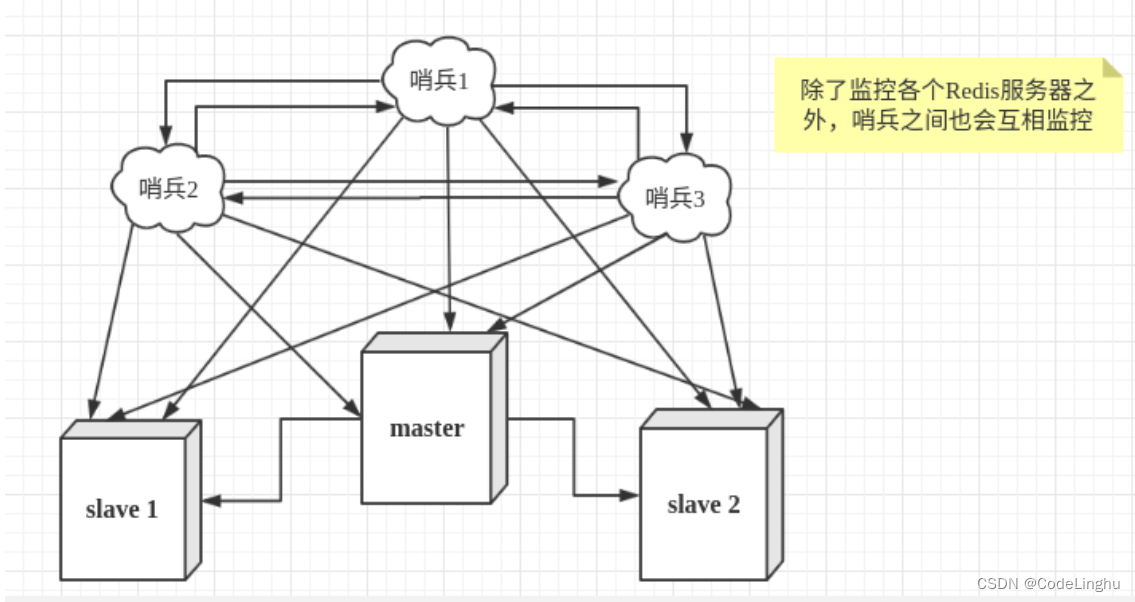
主观下线
假设主服务器宕机,哨兵1先检测到这个结果,系统并不会马上进行failover过程,仅仅是哨兵1主观的认为主服务器不可用
客观下线
当后面的哨兵也检测到主服务器不可用,并且数量达到一定值时,那么哨兵之间就会进行一次投票,投票的结果由一个哨兵发起,进行failover[故障转移]操作。切换成功后,就会通过发布订阅模式,让各个哨兵把自己监控的从服务器实现切换主机
优点:
- 哨兵集群,基于主从复制模式,所有的主从配置优点,它全有
- 主从可以切换,故障可以转移,系统的可用性就会更好
- 哨兵模式就是主从模式的升级,手动到自动,更加健壮!
缺点:
- Redis 不好啊在线扩容的,集群容量一旦到达上限,在线扩容就十分麻烦!
- 实现哨兵模式的配置其实是很麻烦的,里面有很多选择!
Redis缓存穿透和雪崩
目前企业中对Redis缓存技术的运用,如下:
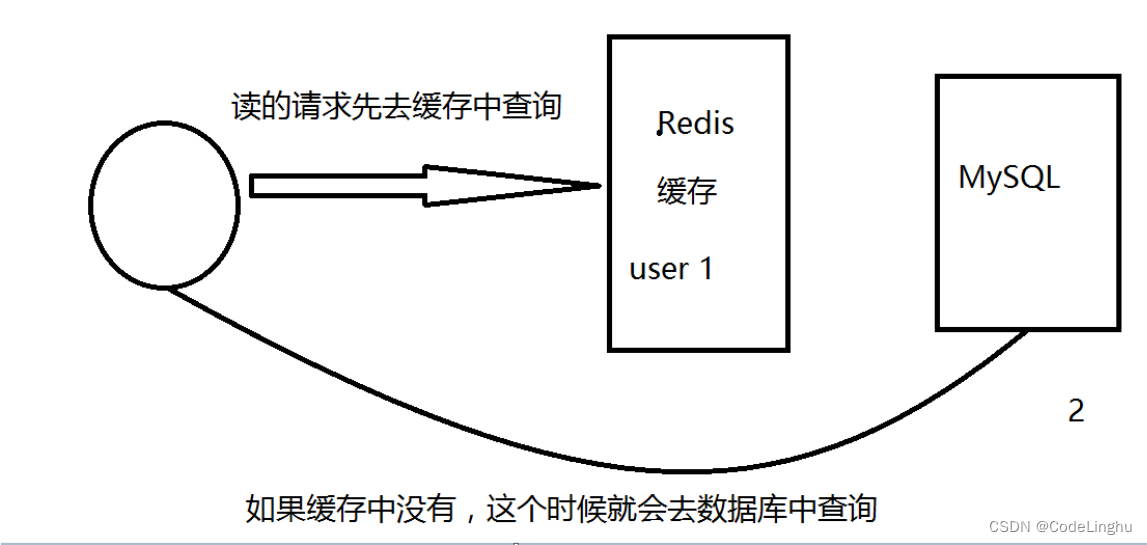
客户端首先请求Redis缓存,查询到了直接获取;查询不到就会去数据库中直接查询。
缓存穿透
用户想要查询一个数据,发现redis内存数据库没有,也就是缓存没有命中,于是向持久层数据库查询。发现也没有,于是本次查询失败。当用户很多的时候,缓存都没有命中,于是都去请求了持久层数据库。这会给持久层数据库造成很大的压力,这时候就相当于出现了缓存穿透 。
解决方案
1、布隆过滤器
我们可以把布隆过滤器理解为一个set集合,我们可以通过add往里面添加元素,通过contains来判断是否包含某个元素。
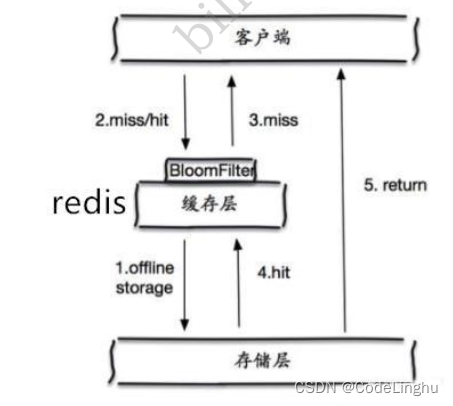
客户端发送过来的数据会首先进行校验,不符合规则进行丢弃,从而避免了对底层存储层系统的查询压力。
2、缓存空对象
当存储层没有被命中(客户端查询不到数据),即使返回的空对象也将其缓存起来,同时会设置一个过期时间,之后再进行访问这个数据将会从缓存中获取,保护了后端数据源。

以上两种方法会存在问题:
- 如果空值能够被缓存起来,这就意味着缓存需要更多的空间存储更多的键,因为这当中可能会有很多的空值的键;
- 即使对空值设置了过期时间,还是会存在缓存层和存储层的数据会有一段时间窗口的不一致,这对于需要保持一致性的业务会有影响
缓存击穿
缓存击穿,是指一个key非常热点,在不停的扛着大并发,大并发集中对这一个点进行访问,当这个key在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,就像在一个屏障上凿开了一个洞 。
解决方案
1、设置热点数据永不过期
从缓存层面来看,没有设置过期时间,所以不会出现热点 key 过期后产生的问题
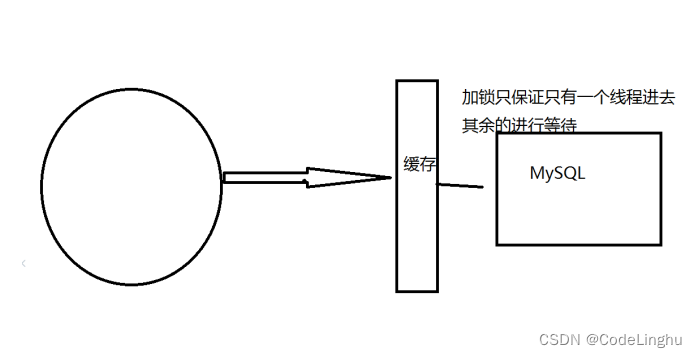
2、加互斥锁
使用分布式锁,保证对于每个key同时只有一个线程去查询后端服务,其他线程没有获得分布式锁的权限,因此只需要等待即可。这种方式将高并发的压力转移到了分布式锁 。
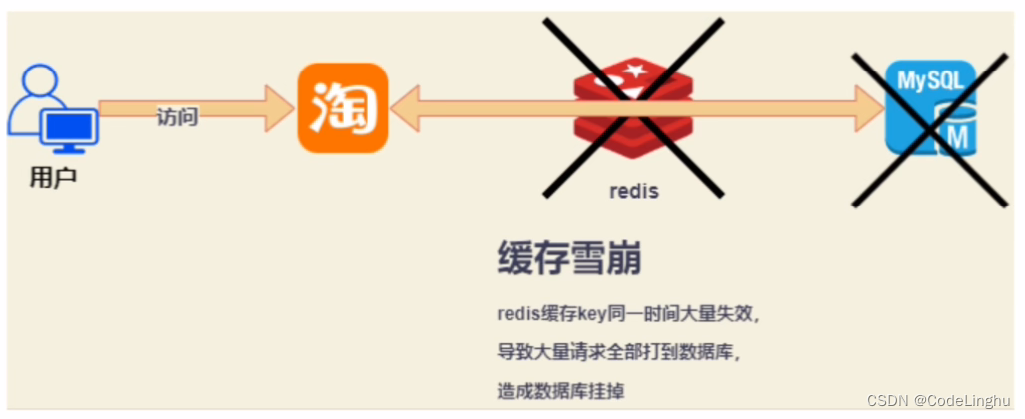
缓存雪崩
缓存雪崩,是指在某一个时间段,缓存集中过期失效。Redis 宕机!
解决方案
1、Redis高可用
多增设几台redis,这样一台挂掉之后其他的还可以继续工作,其实就是搭建的集群
2、限流降级
在缓存失效后,通过加锁或者队列来控制读数据库写缓存的线程数量
3、数据预热
在正式部署之前,我先把可能的数据先预先访问一遍,这样部分可能大量访问的数据就会加载到缓存中。在即将发生大并发访问前手动触发加载缓存不同的key,设置不同的过期时间,让缓存失效的时间点尽量均匀。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!