基于YOLOv8 + BotSORT实现球员和足球检测与跟踪 (步骤 + 源码)
导? 读
????本文主要介绍基于YOLOv8和BotSORT实现球员和足球检测与跟踪?,并给出步骤和代码。
背景介绍
????本文旨在了解 YOLO 架构并在自定义数据集上对其进行训练,然后微调模型以获得更好的结果,并运行推理以了解最有效的方法。

????什么是YOLO?
??? YOLO(You Only Look Once)是一种最先进的目标检测算法,因其革命性的单通道检测技术而闻名,该技术提高了其速度和准确性,超越了同行。
??? YOLOv1最初于 2015 年提出,将对象检测视为回归问题,使用边界框计算类概率。此后它经历了很多改进,目前由 Ultralytics 维护,Ultralytics 发布了最新版本Yolov8。
????YOLO算法是如何工作的
????顾名思义,YOLO 算法在单次传递中对图像进行预测,这比在整个图像上卷积使用滑动窗口或在多个位置使用建议区域来定位对象的传统方法更好。
??? YOLO 的方法是将图像划分为 S x S 网格(如下所示),其中每个网格单元负责生成边界框和置信度得分输出。

????对于该图像中的每个网格单元,我们计算以下内容:
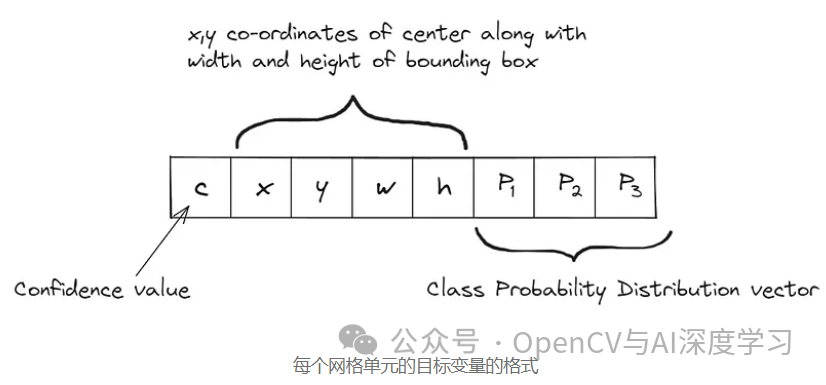
????第一个单元格指的是置信度值,它只是一个标签,决定是否有任何对象位于网格单元格内(0 或 1)。如果答案是肯定的,那么我们继续以 xywh 格式预测边界框的值,其中 x 和 y 是边界框中心的坐标,w 和 h 指边界的宽度和高度盒子。最后,我们有类概率分布向量,其中包含每个对象标签的预测分数,范围在 0到1之间。
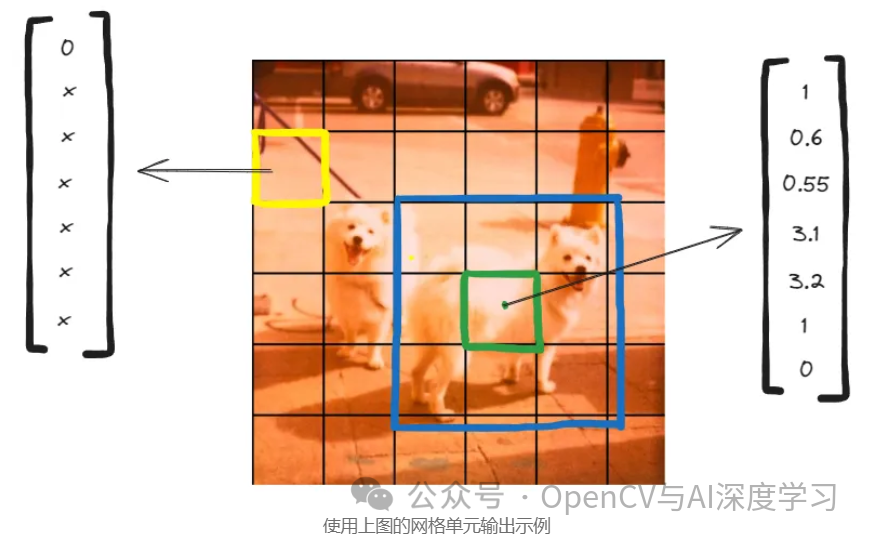
????如果我们看一下上面的图像,我们可以清楚地看到蓝色边界框定义了狗对象的真实边界。当我们查看绿色网格单元的输出向量时,我们试图预测蓝色边界框的中心,这是我们的真实标签。
????首先我们确定该网格单元中是否有一个对象,因为答案是肯定的,我们可以继续进一步分配 xywh 值,您可能已经注意到宽度和高度值超出了 0 和 1 范围。这是因为整个边界框的真实标签跨度超过了绿色网格单元,并且高度和宽度略多于 3 个网格单元。最后,关于我们的类别概率分数,绿色网格单元仅包含 dog 对象,因此我们可以轻松地将分数 1 分配给狗对象,将 0 分配给汽车对象。
????另外,如果我们看一下黄色网格单元,我们知道它不包含任何对象,因此我们可以简单地将置信值 0 分配给其输出向量。“x”表示无关项,这意味着我们可以安全地忽略输出向量中的所有其他值。
? ? ??
实现步骤
????下面是具体步骤:?
??【1】在我们的自定义数据集上训练 Yolov8。
????现在,让我们使用 Roboflow的球员和球检测数据集并使用 Yolov8 对其进行训练,使用的数据集:?
https://universe.roboflow.com/nikhil-chapre-xgndf/detect-players-dgxz0????首先我们需要安装 Ultralytics,它维护所有Yolo模型:
pip install ultralytics????接下来我们需要设置一个yaml文件来配置一些训练参数:
path: absolute path to dataset (/path/to/dataset)train: relative path from dataset (/train)test: relative path from dataset (/test)val: relative path from dataset (/val)# Define Classes and their Labelsnames:0: Ball1: Player2: Referee
????接下来我们需要选择 Yolov8 模型权重来开始训练:
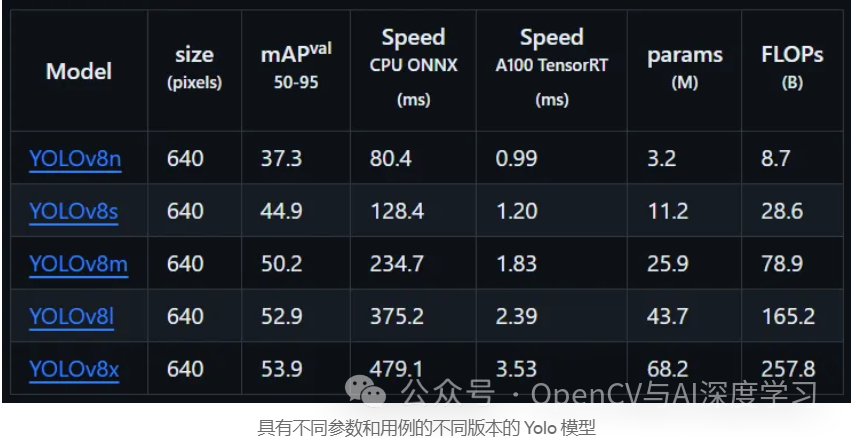
????对于我们的用例,我们将使用 Yolov8n (Nano),它是最轻、最快的模型,根据 mAP 分数,它不是最准确的模型,但经过足够的训练,它可以产生良好的结果,并具有更好的视频 fps追踪。???????
from ultralytics import YOLOimport torchimport os# Load the YOLOv8 modelmodel = YOLO('yolov8n.pt')# TRAININGif __name__ == '__main__':results = model.train(data="config.yaml", epochs=50, patience=5)
????如上所示,我们可以简单地从之前设置的 config.yaml 文件中加载数据。我们将开始训练 100个epoch,耐心参数跨越 10 epoch,这意味着如果连续10个 epoch 没有看到任何改进,模型将提前停止训练。
??【2】扩大网络维度以获得更好的结果。
????在训练期间面临的最大挑战是“球”类别的 mAP 分数很差,花了一段时间才意识到出了什么问题。Yolov8 通常期望输入图像为方形格式,对于非方形图像,它默认所有图像的宽度为 640px 以及相应的高度以保持纵横比,除非如下所示指定。


??【3】使用 GIMP 比较“Ball”类的大小。


????目标图像的质量和尺寸的下降在两个图像中都很明显,因此导致模型的检测效果较差。在训练时增加图像大小,不仅可以为“Ball”类别带来更好的 mAP 分数,还可以为所有其他类别带来更好的 mAP 分数。
????但这意味着我们应该始终使用最高分辨率的图像进行训练和推理以获得最佳结果,对吧?答案取决于,因为增加模型的网络维度将导致模型使用更多的训练资源并使其变慢。因此,我们需要找到一个最佳点来平衡模型的速度和准确性。

????另外,请记住,根据YOLO文档,网络维度只能是32的倍数。因此,经过一些考量后,我决定使用1088作为图像尺寸,同时记住最小对象的最小图像尺寸应大于15x15像素。
【4】模型性能。
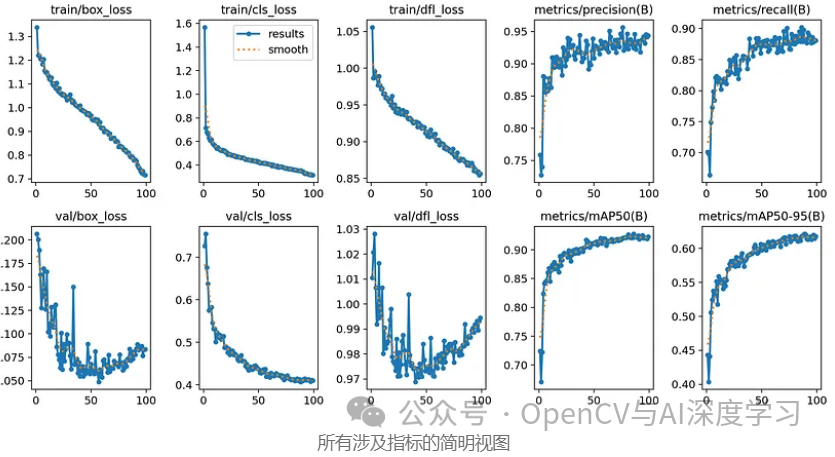
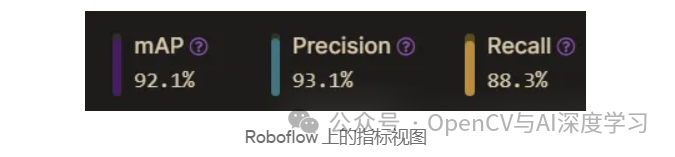
????完成训练后,我们可以使用上面显示的指标查看训练/验证结果,Yolov8 为每个指标准备了一个完整的目录,其中包含详细的图表和可视化以及模型权重,上面显示的只是一个简短的摘要。
????我们现在可以使用这个训练结果目录并将权重上传回 Roboflow 以作为模型部署,这可以用于辅助图像标签,也可以简单地在线部署以供公众使用。
????【5】使用我们的模型权重运行推理。
????现在,我们可以加载刚刚训练的最佳权重,并将其与 Ultralytics 提供的 BoTSORT跟踪器一起使用下面的脚本来跟踪视频剪辑,而不是使用默认权重。???????
import cv2from ultralytics import YOLO# Load the YOLOv8 model# model = YOLO('yolov8n.pt') ### Pre-trained weightsmodel = YOLO('runs/detect/train2/weights/best.pt') ### weights from trained model# Open the video filevideo_path = r"path/to/video"cap = cv2.VideoCapture(video_path)# Loop through the video frameswhile cap.isOpened():# Read a frame from the videosuccess, frame = cap.read()if success:# Run YOLOv8 tracking on the frame, persisting tracks between framesresults = model.track(frame, persist=True, show=True, tracker="botsort.yaml")# Visualize the results on the frameannotated_frame = results[0].plot()# Display the annotated framecv2.imshow("YOLOv8 Tracking", annotated_frame)# Break the loop if 'q' is pressedif cv2.waitKey(1) & 0xFF == ord("q"):breakelse:# Break the loop if the end of the video is reachedbreak# Release the video capture object and close the display windowcap.release()cv2.destroyAllWindows()
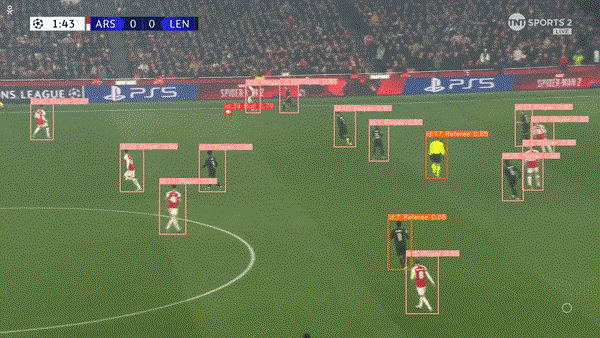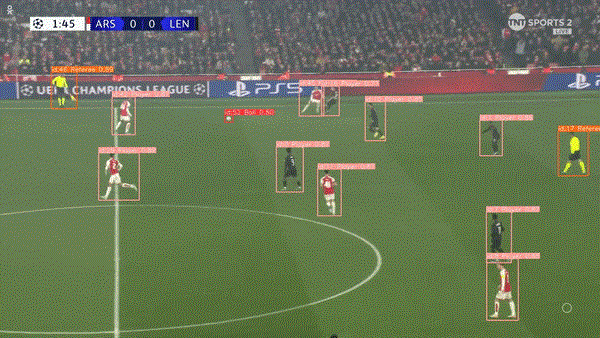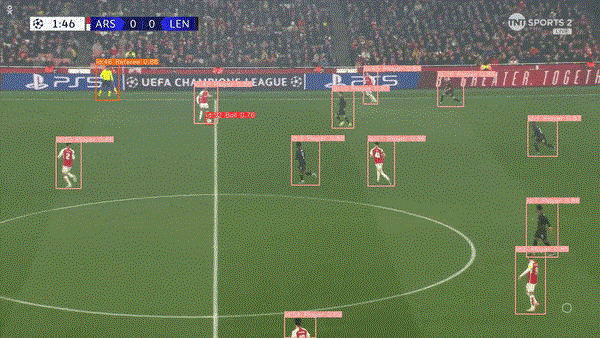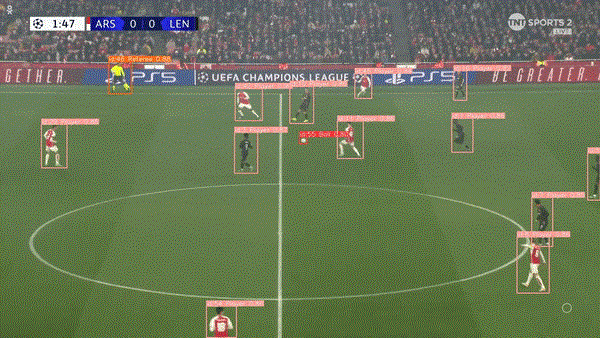
????在我们的检测模型中添加跟踪将有助于跟踪视频剪辑中连续帧中的对象,它通过为每个检测到的对象分配唯一的 ID 来实现这一点。因此,它还可以帮助绘制足球等物体随时间变化的轨迹,并根据其跨帧的运动绘制路径。
????最终运行结果:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!