多项式回归
4、多项式回归
4.1、多项式回归基本概念
??升维的目的是为了去解决欠拟合的问题的,也就是为了提高模型的准确率为目的的,因为当维度不够时,说白了就是对于预测结果考虑的因素少的话,肯定不能准确的计算出模型。
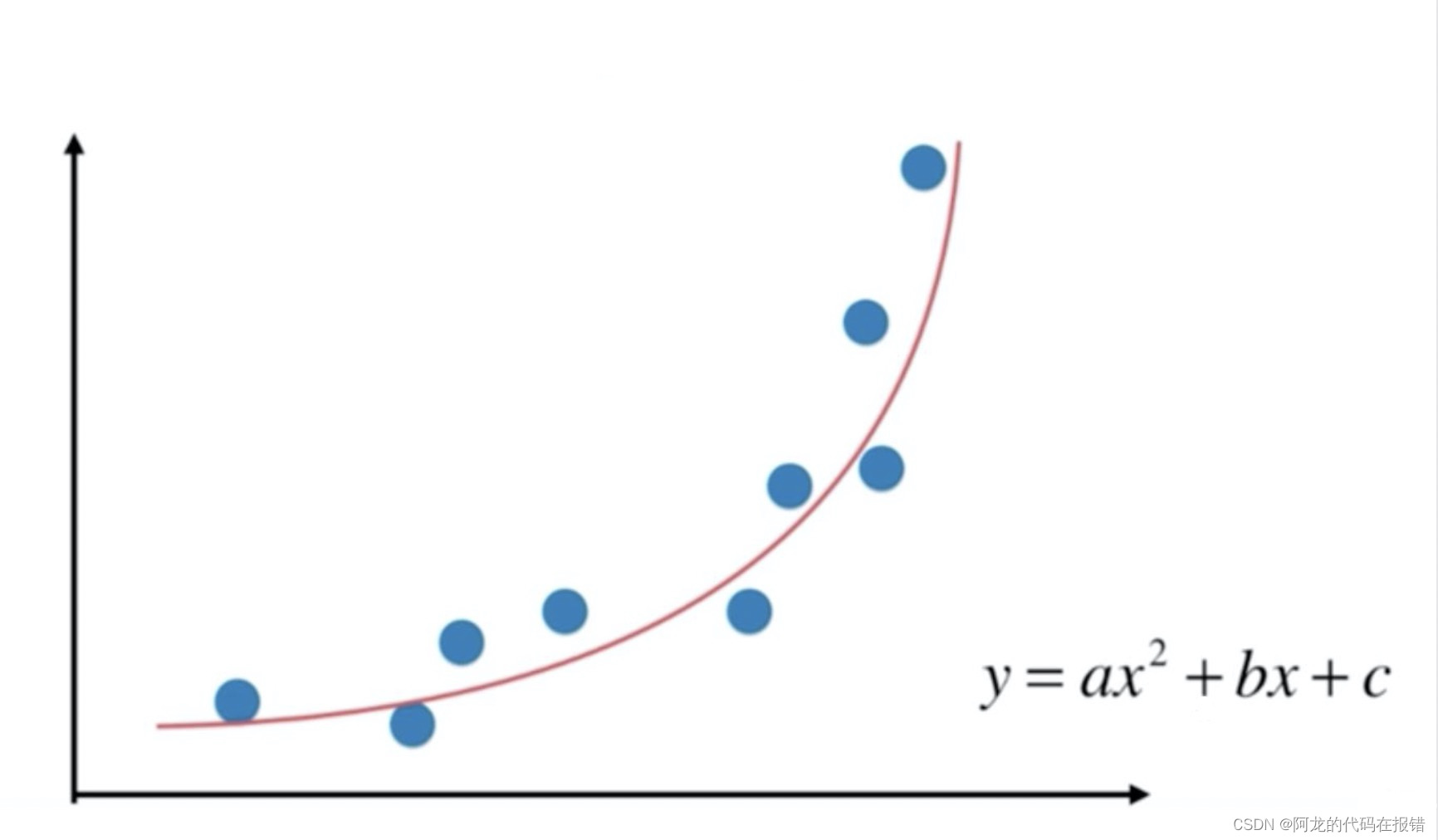
??在做升维的时候,最常见的手段就是将已知维度进行相乘(或者自乘)来构建新的维度,如下图所示。普通线性方程,无法拟合规律,必须是多项式,才可以完美拟合曲线规律,图中是二次多项式。
??对于多项式回归来说主要是为了扩展线性回归算法来适应更广泛的数据集,比如我们数据集有两个维度 x 1 、 x 2 x_1、x_2 x1?、x2?,那么用多元线性回归公式就是: y ^ = w 0 + w 1 x 1 + w 2 x 2 \hat{y} = w_0 + w_1x_1 + w_2x_2 y^?=w0?+w1?x1?+w2?x2?,当我们使用二阶多项式升维的时候,数据集就从原来的 x 1 、 x 2 x_1、x_2 x1?、x2?扩展成了 x 1 、 x 2 、 x 1 2 、 x 2 2 、 x 1 x 2 x_1、x_2、x_1^2、x_2^2、x_1x_2 x1?、x2?、x12?、x22?、x1?x2? 。因此多元线性回归就得去多计算三个维度所对应的w值: y ^ = w 0 + w 1 x 1 + w 2 x 2 + w 3 x 1 2 + w 4 x 2 2 + w 5 x 1 x 2 \hat{y} = w_0 + w_1x_1 + w_2x_2 + w_3x_1^2 + w_4x_2^2 + w_5x_1x_2 y^?=w0?+w1?x1?+w2?x2?+w3?x12?+w4?x22?+w5?x1?x2? 。
??此时拟合出来的方程就是曲线,可以解决一些线性回归的欠拟合问题!
1、普通的线性回归
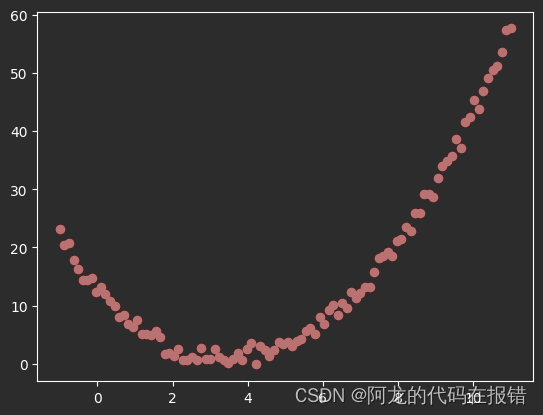
# 1.创建数据,并进行可视化
X = np.linspace(-1, 11, num=100)
y = (X - 5) ** 2 + 3 * X - 12 + np.random.randn(100)
X = X.reshape(-1, 1)
plt.scatter(X, y, color='red')
# 使用线性回归进行建模和预测
model1 = LinearRegression()
model1.fit(X, y)
y_pred = model1.predict(X_test)
plt.scatter(X, y, color='red')
plt.plot(X_test, y_pred, color='g')
从下图可以看出线性回归生成图像和真实的红点差距很大

2、多项式回归实战
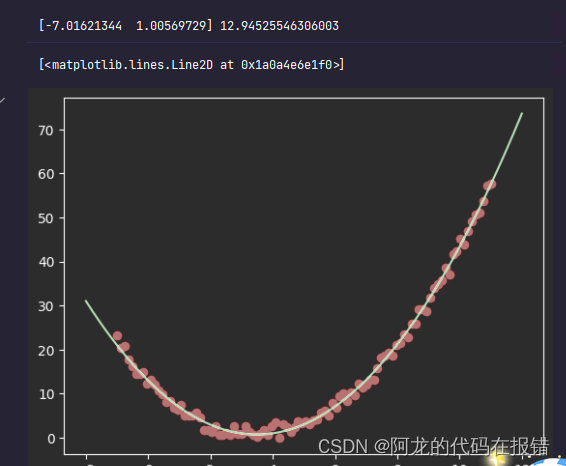
# 特征升维
X_ = np.c_[X, X ** 2]
model1.fit(X_, y)
print(model1.coef_, model1.intercept_)
# 预测值
X_test_ = np.c_[X_test, X_test ** 2]
y_pred1 = model1.predict(X_test_)
plt.scatter(X,y,color='r')
plt.plot(X_test,y_pred1,color='g')
经过多项式回归推导的线性回归的图像和基本和真实的图形重合
3、梯度下降
新导入包
from sklearn.linear_model import SGDRegressor
# 用于构造新特征
from sklearn.preprocessing import PolynomialFeatures
# 1.对数据进行升维
ploy = PolynomialFeatures(interaction_only=False)
x_poly = ploy.fit_transform(X) # 0次幂,1次幂,2次幂
x_poly

X = np.linspace(-1, 11, num=100)
y = (X - 5) ** 2 + 3 * X - 12 + np.random.randn(100)
X = X.reshape(-1, 1)
plt.scatter(X, y, color='red')

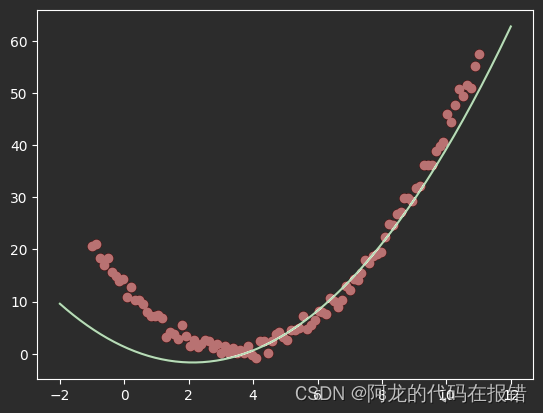
model2 = SGDRegressor(eta0=0.001,fit_intercept=False)
model2.fit(x_poly,y)
X_test_poly = ploy.transform(X_test)
y_pred2 = model2.predict(X_test_poly)
plt.scatter(X,y,color='red')
plt.plot(X_test,y_pred2,color='g')
print(model2.coef_,model2.intercept_)
归一化处理
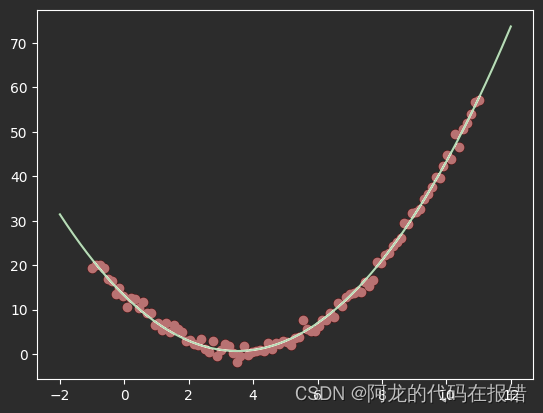
from sklearn.preprocessing import StandardScaler
model3 = SGDRegressor(eta0=0.1,fit_intercept=True)
scaler = StandardScaler()
X_poly_scaler = scaler.fit_transform(x_poly)
model3.fit(X_poly_scaler,y)
x_test_poly = ploy.transform(X_test)
x_test_poly_scaler = scaler.transform(x_test_poly)
y_pred3 = model3.predict(x_test_poly_scaler)
plt.scatter(X,y,color ='red')
plt.plot(X_test,y_pred3,color='g')
print(model3.coef_,model3.intercept_)
经过归一化处理和参数调优后预测值和真实点基本上重合
坚持学习,整理复盘

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【neo4j】desktop下载
- 文本生成探索:方法、任务与测评
- 计算机网络——基础知识(八)
- Ubuntu12.0安装g++过程及其报错
- 载波相位测量--基本概念、基本原理、观测方程
- 每日算法打卡:摘花生 day 14
- 【C++】演讲比赛流程管理系统
- ADI突发涨价函,涨幅10%-20% | 百能云芯
- idea 出现Cannot resolve symbol ‘springframework‘解决方法
- docker 安卓