关于设计模式、Java基础面试题
前言
之前为了准备面试,收集整理了一些面试题。
本篇文章更新时间2023年12月27日。
最新的内容可以看我的原文:https://www.yuque.com/wfzx/ninzck/cbf0cxkrr6s1kniv
设计模式
单例共有几种写法?
细分起来就有9种:懒汉(初始加载资源过多时使用)、饿汉、静态内部类、枚举(防止反序列化创建新对象)、ThreadLocal单例
建造者模式和工厂方法模式的区别是什么?
工厂模式注重创建一个产品,不关心创建细节;
建造者模式也是创建一个产品,同时关注组成的细节。
总结就是一个关注整体、一个关注细节。
简单工厂、工厂方法和抽象工厂之间的区别是什么?
使用场景有一些区别:
- 简单工厂:适用于类关系简单、不复杂 并且 确定之后几乎不扩展的情况。
- 工厂方法:适用于需要根据运行时上下文信息动态选择实现类的时候。
- 抽象工厂方法模式:适用于创建一组相关 或 相互依赖的对象时使用。
桥接模式与适配器模式的区别是什么?
从目的来看,桥接模式关注的是分离,适配器关注的是合并、配合。
适配器模式分为哪几类?每类的应用场景是什么?
类适配器、对象适配器、接口适配器。
装饰器模式与代理模式的区别是什么?
共同点:都是让两个类一起配合工作。
区别:目标、侧重不一样
- 装饰器模式:侧重扩展功能、增加职能;
- 代理模式:侧重对被代理对象的访问控制。
模板设计模式的适用场景是什么?
适用于流程固定但是具体实现有区别的场景。
策略模式的优缺点是什么?
优点:避免多重条件转移语句、算法实现跟使用者分离、避免重复代理。
缺点:必须要知道所有策略类
扩展:可结合工厂模式、享元模式。
责任链模式的优缺点有哪些?
优点:减少对象之间的耦合,灵活指派处理者。
缺点:较长的责任链,可能会影响性能。
访问者模式的适用场景及优缺点有哪些?
适用场景:数据结构 与 数据操作 分离 ;
优点:容易扩展新操作;
缺点:增加新接收比较麻烦。
泛型的上限限定和下限限定是什么?
上限限定:是某个类或其子类;
public static <T extends MyClass> void addToList(List<T> list) {}
下限限定:是某个类或其超类。
public static void addToList(List<? super AbstractMyClass> list) {}
泛型的类型擦除和侨界方法是什么?
类型擦除:编译期间将泛型替换为普通类型,没有指定上、下限定的话就是Object,否则就是指定的边界类。
Java基础
反射的适用场景有哪些?
应用场景:动态加载类和实例化对象、动态代理和AOP、获取注解信息、编写通用的框架和工具类。
反射的优点和缺点
优点:动态灵活;
缺点:1.性能开销:反射涉及动态解析类型和方法的调用,有一定的性能开销;2.安全性问题:绕过访问控制修饰符的限制;3.可读性变差。
静态嵌套类与内部类区别
静态嵌套类不依赖外部类就可以进行实例化;
内部类要进行实例化的话,需要先实例化外部类。
抽象方法不能被static、native、synchronized修饰?
对
当一个线程进入一个对象的 synchronized 方法 A 之后, 其它线程是否可进入此对象的 synchronized 方法 B?
不能。只能进入非synchronized的方法。
对于同一个对象或者class来说。
finally 中的代码一定会执行吗?
不一定,比如虚拟机终止时、try内死循环。
SPI 是什么
提供一套标准接口,让服务提供方(第三方)实现,然后使用合适的方式(比如 Service Loader)发现这个服务实现并调用。
SPI 和 API 有啥区别?
目的不一样:SPI 用于扩展,让第三方实现;API 是对外提供服务,不支持扩展。
序列化和反序列化是什么?
序列化:将对象持久化到磁盘、写到数据库或在网络传输时,需要将对象序列化成二进制流;
反序列化:将二进制流数据还原成对象。
BIO、NIO 和 AIO 的区别?
BIO:同步阻塞IO,知道数据准备就绪、拷贝完成才继续执行;
NIO:同步非阻塞IO,Java中采用IO多路复用模型,避免了CPU资源的浪费。它可以将多个通道(Channel)注册到选择器(Selector),选择器通过select系统调用进行监控,当数据准备好之后让用户线程继续执行。
在linux2.6内核,还支持epoll系统调用,能监控无限多的FD,而且不会随FD增多而降低效率。
AIO:异步IO,基于事件以及回调机制实现,当数据准备好的时候,系统通知用户线程进行后续操作。
什么是语法糖?
为了方便程序而设计的特殊语法。对编程功能没有影响,主要是让代码更加简洁。
什么是检查异常,不受检查异常,运行时异常?并分别举例说明
检查异常(Checked Exceptions):这类异常是Exception及其子类的成员,它们在编译时被强制要求处理,否则程序无法通过编译。例如,如果程序要访问一个文件,但该文件不存在,就会出现一个IOException,这是一个检查异常。
运行时异常(Runtime Exceptions):这类异常是RuntimeException类及其子类的成员,它们在程序运行时可能发生,但不强制要求处理。例如,如果程序中出现空指针异常(NullPointerException)或数组越界异常(IndexOutOfBoundsException),这些都是运行时异常。运行时异常通常是由程序的逻辑错误引起的,因此程序应该尽量避免这些错误。
不受检查异常:运行时发生,一般是程序逻辑问题引起的。
finally块一定会执行吗?
JVM停止时不执行;for循环内的break、return不会。
public static void main(String[] args) {
for (int i = 0; i < 2; i++) {
try {
System.out.println("开始try块");
if(i == 0) {
// break;
return;
}
} catch (Exception e) {
System.out.println("执行了catch块,异常信息为:" + e.getMessage());
} finally {
System.out.println("执行finally块");
}
}
}
try、catch、finally语句块的执行顺序
如上。
一个空Object对象的占多大空间?
64位操作系统下,等于对象头的大小,即16字节。关闭指针压缩则是32
对象的组成
对象头+实际数据+对其填充。
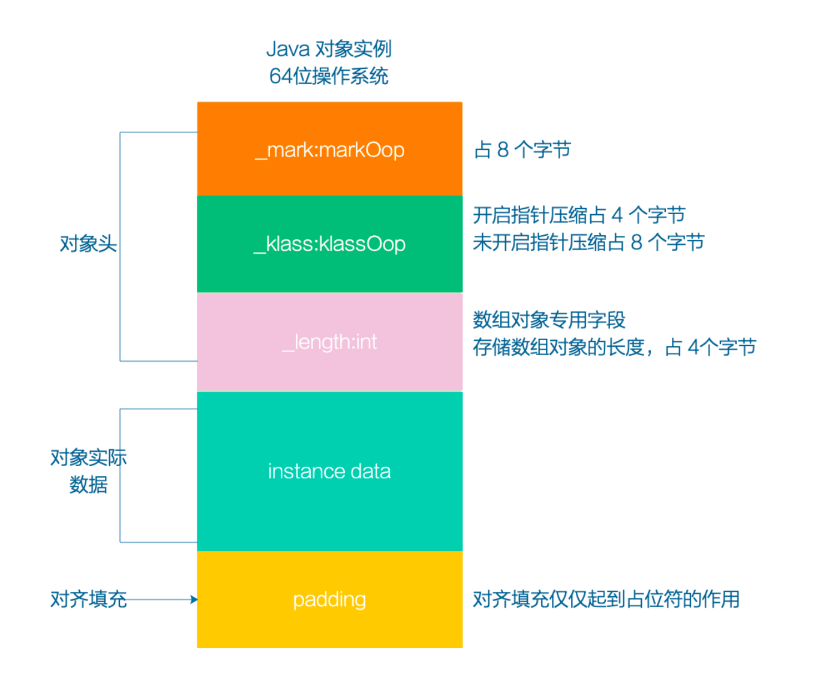
对象头组成
- Mark Word(标记字段):Mark Word是对象头的核心部分,它用于存储对象的标记信息和运行时状态。Mark Word的具体结构和含义可能会因不同的虚拟机实现而有所差异,但通常包括以下内容:
- 对象的哈希码(HashCode):用于支持对象的哈希操作,如在HashMap中使用。
- 锁状态标志(Lock State Flags):用于支持对象的同步操作,如加锁、解锁等。
- GC标记(GC Mark):用于垃圾回收器标记对象的存活状态。
- 偏向锁(Biased Lock):用于支持对象的偏向锁优化,以提高单线程访问对象的性能。
- 类型指针(Class Metadata Pointer):类型指针指向对象所属的类元数据(Class Metadata),包括对象的类型信息、方法表(Virtual Method Table)等。通过类型指针,虚拟机可以确定对象的类型和方法的调用。

拆箱和装箱的过程
Integer数值范围在[-128, 127]的,将从对象池中获取。
Integer a = 1:自动装箱,从对象池中获取对象。
a++;先拆箱,自增之后,装箱
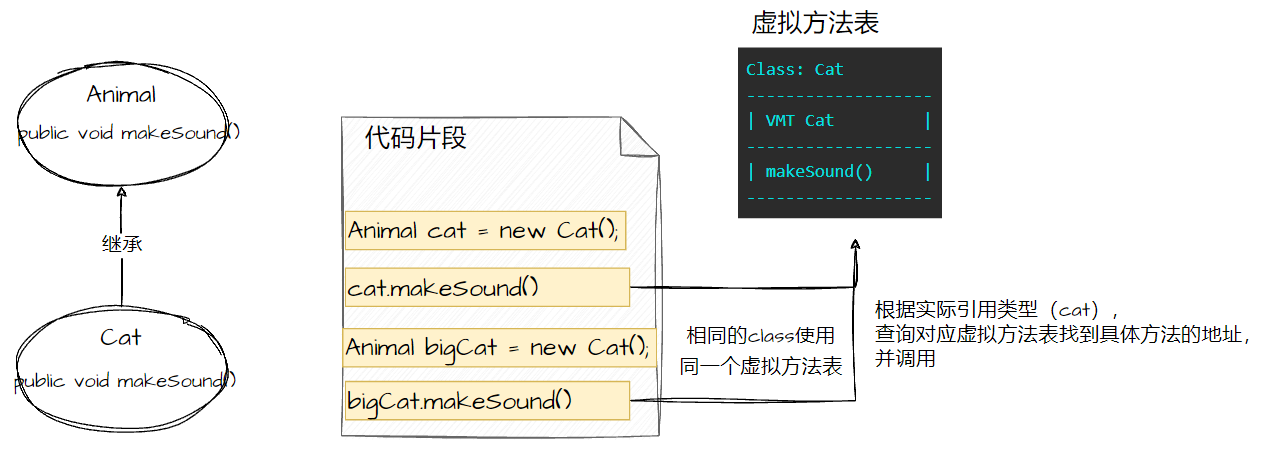
多态实现原理
回顾多态的三个必要条件:

区分实现方式与实现原理,实现方式:继承+重写。
而多态的实现原理是:动态绑定 + 虚拟方法表。
而非私有、非静态和非 final 的方法是动态绑定的;
同一个class的多个实例,共用同一张虚拟方法表。
虚拟方法表在链接阶段&初始化。
集合
ArrayList的优缺点
优点:高效的随机访问;尾插、尾删较快;1.5倍动态扩容;
缺点:动态扩容需要重新分配内存,影响性能;不是线程安全;删除、插入元素可能需要移动元素,会损失一些性能;可能会有一些空间的浪费。
ArrayList和ListList区别
ArrayList:基于数组实现,具有高效的随机访问能力;在插入、删除元素时,可能需要最差的情况下需要
ArrayList初始容量
使用无参构造器创建的ArrayList,默认是一个空数组,没有分配空间,直到调用add()方法,会将初始容量设置为10。
ArrayList扩容机制
每次扩容原来的一半。
以add(T t)为入口,插入元素前先检查容量,如果不够,那就计算要扩容到多少大小,然后检查要扩容的大小是否超过限制,最后使用Arrays.copyOf方法进行数组拷贝。
基层调用System.arraycopy(original, 0, copy, 0, Math.min(original.length, newLength));
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1); // 每次扩容原来的一半。
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
LinkedList是双向链表还是单向链表
双向链表。这样删除、插入更高效;但是对比单向链表,需要的空间就多一些、实现也更复杂一些。
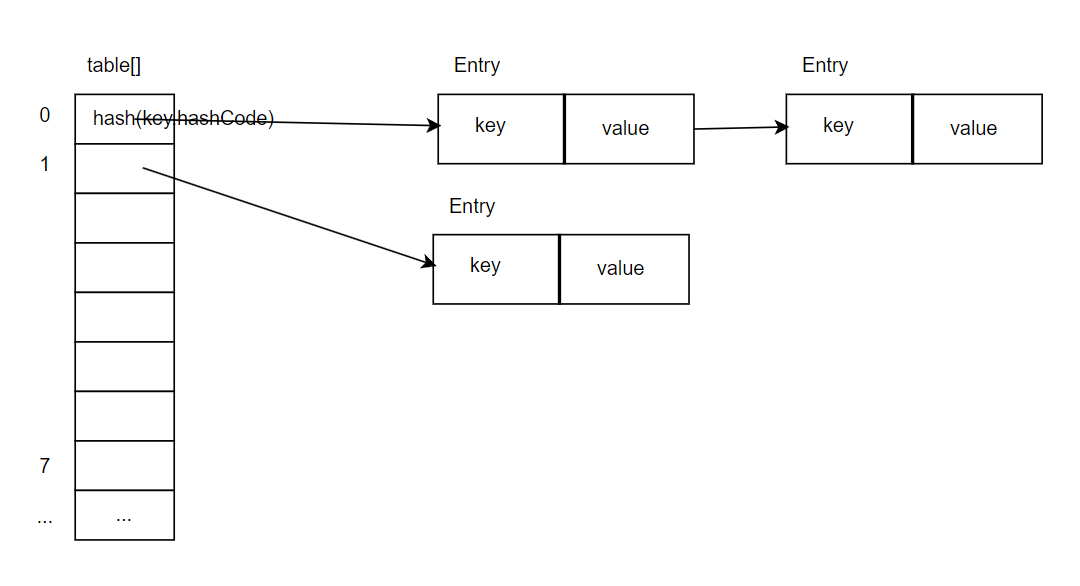
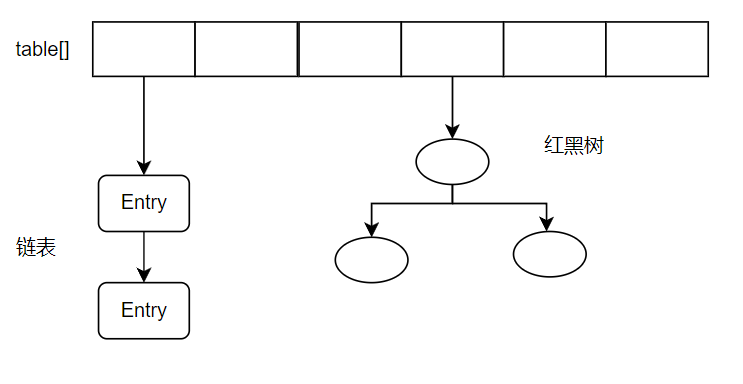
HashMap jdk1.7和1.8的实现有什么区别
- 数据结构:JDK8引入了红黑树解决链表过长问题,数组类型改为Node。
- 哈希冲突解决方式上:JDK7是采用头插法将元素插入链表,JDK8采用尾查法;
- 扩容机制:JDK7扩容是在put操作中进行,当链表大于8时将重建数组和链表,并重新散列;JDK8的话,扩容是在resize方法进行,当元素数量达到需要调整的阈值时(容量*0.75),将触发扩容方法,创建更大的数组,将旧元素重新hash分配到新数组。
HashMap 的长度为什么是 2 的幂次方
为了让HashMap存取高效,让数据分配得更均匀,减少哈希碰撞。
HashMap 多线程操作导致死循环问题
JDK7之前,当桶中有多个元素需要进行扩容的时候,多线程同时进行,可能会生产环形链表,导致死循环。
JDK8采用了尾插法避免环形链表。
比较 HashSet、LinkedHashSet 和 TreeSet 三者的异同
- 相同:全部实现Set接口,都不是线程安全的;
- 区别:最大的区别是底层结构不同,
- HashSet:hash表;
- LinkedHashSet:链表 + hash表、
- TreeSet:红黑树。
HashMap底层结构
异同:
JDK8之后,new HashMap()不会创建一个长度为16的数组了。调用put的时候才创建。
JDK8之后,使用Node[]作为数组类型;
JDK8之后,使用数组+链表+红黑树,之前使用的是数组+链表。
下面是数据结构图:
JDK7
JDK8
HashMap什么时候转红黑树?
链表长度大于等于8并且数组长度大于等于64时。
HashMap红黑树为什么6的时候退回链表?
链表更简单、数据量小的时候,链表可能查得更快
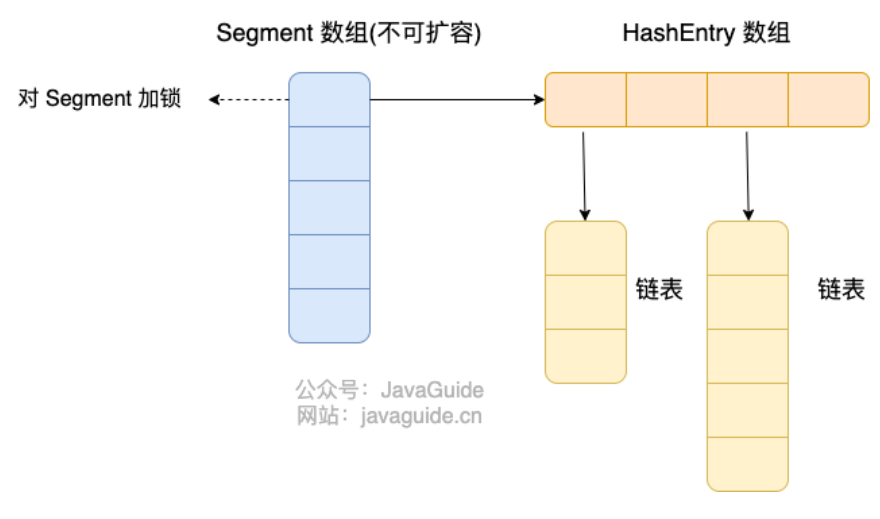
ConcurrentHashMap底层结构
JDK7
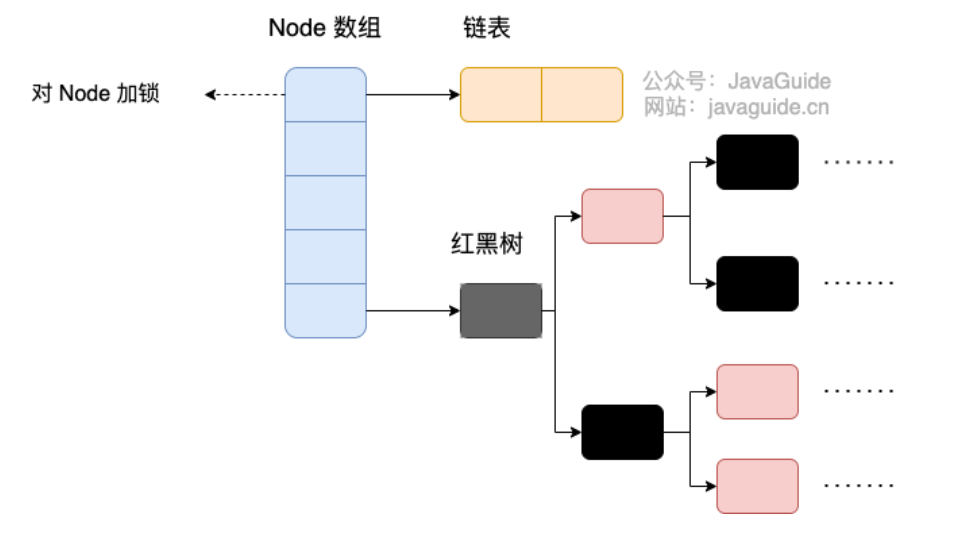
JDK8
跟HashMap类似,采用CAS + synchronized保证并发安全。
JDK 1.7 和 JDK 1.8 的 ConcurrentHashMap 实现有什么不同?
数据结构不同:JDK7采用分段数组 + 条目数组 + 链表;JDK8采用数组 + 链表 + 红黑树;
并发程度不同:JDK7并发程度由分段数量决定;JDK8对Node加锁,并发读更大。
ConcurrentHashMap 为什么 key 和 value 不能为 null?
从设计上来说:用null的话无法区分是找不到才返回空还是原本就是null;
从源码上来看:需要取hashCode,空的key会抛出空指针异常。
ConcurrentHashMap 能保证复合操作的原子性吗?
不能。但是提供了一些复合操作原子性的方法,如putIfXX、compute等。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 21. C++ volatile关键字
- 自己写的Js有序的Map, 并且支持Key为对象
- GB/T 41480-2022 门和卷帘的防烟性能
- 【Minecraft外网联机教程】Linux搭建我的世界MC服务器
- Jmeter 性能-监控服务器
- 跨镜动线分析丨用AI解读顾客行为,助力零售企业运营与增长
- Swift 周报 第四十期
- 正则化实战( Lasso 套索回归,Ridge 岭回归)
- K8S中将一个Deployment暴露出一个指定的外部端口,生成yaml
- Kafka(五)生产者