Prometheus 架构全面解析
在本指南中,我们将详细介绍 Prometheus 架构。
Prometheus 是一个用 Golang 编写的开源监控和告警系统,能够收集和处理来自各种目标的指标。您还可以查询、查看、分析指标,并根据阈值收到警报。
此外,在当今世界,可观测性对每个组织来说都变得至关重要,而 Prometheus 是开源领域的关键可观测性工具之一。
在这篇博客中,我们将了解 Prometheus 的所有关键组件,以及它们如何协同工作以使整个监控系统正常工作。
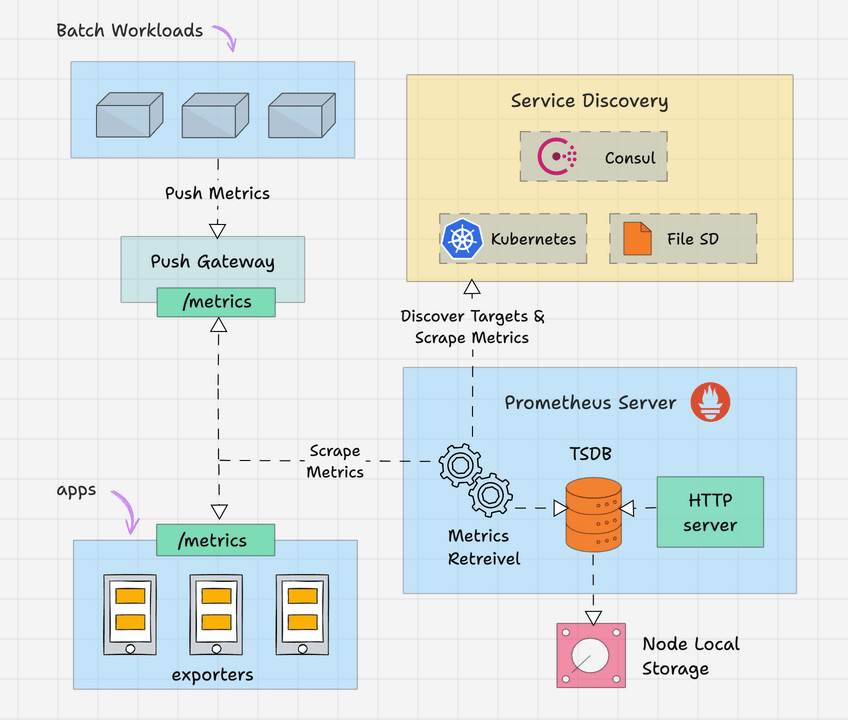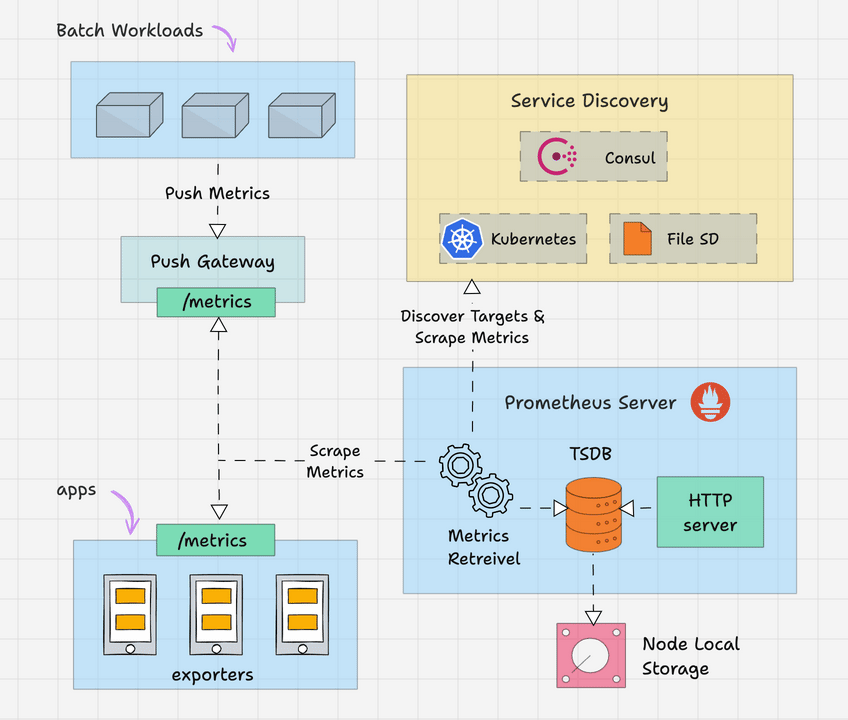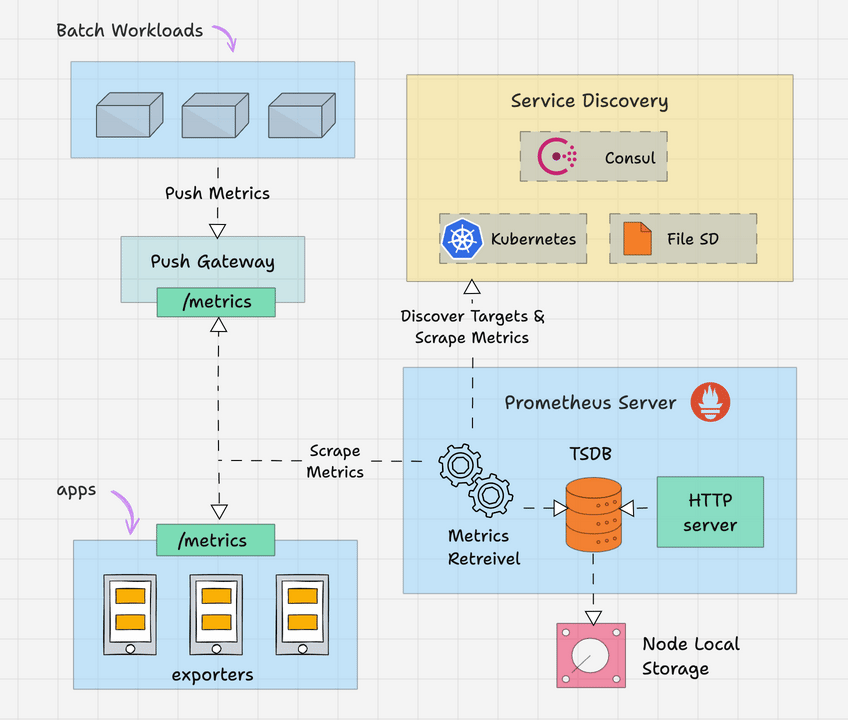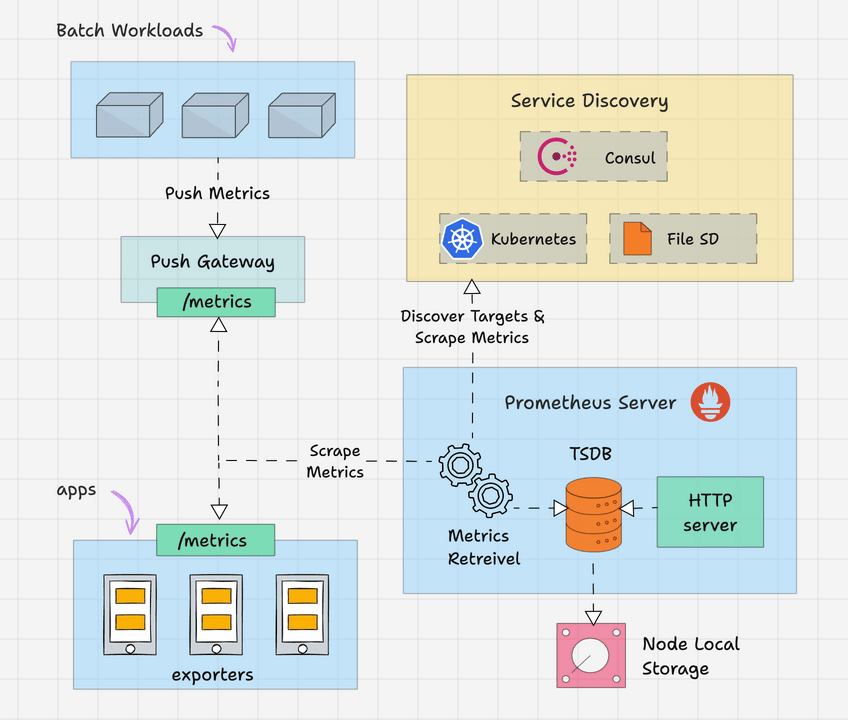
Prometheus 架构
以下是 Prometheus 架构的高级概述。
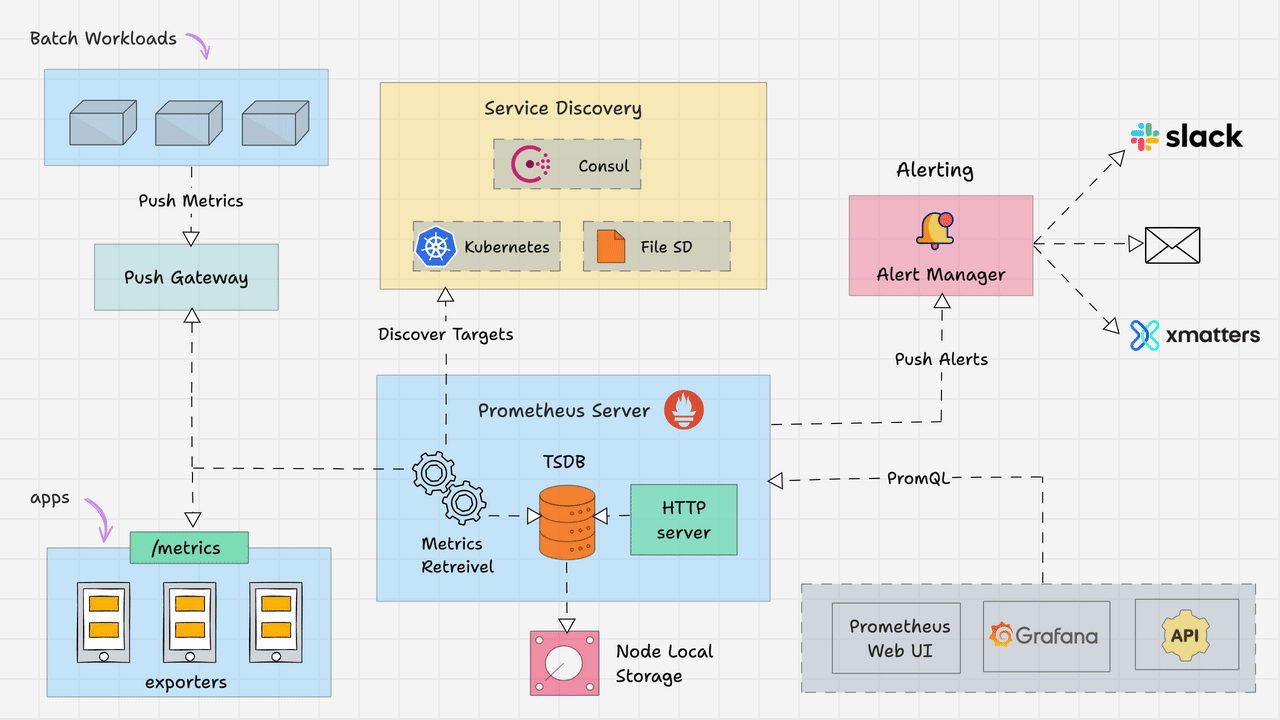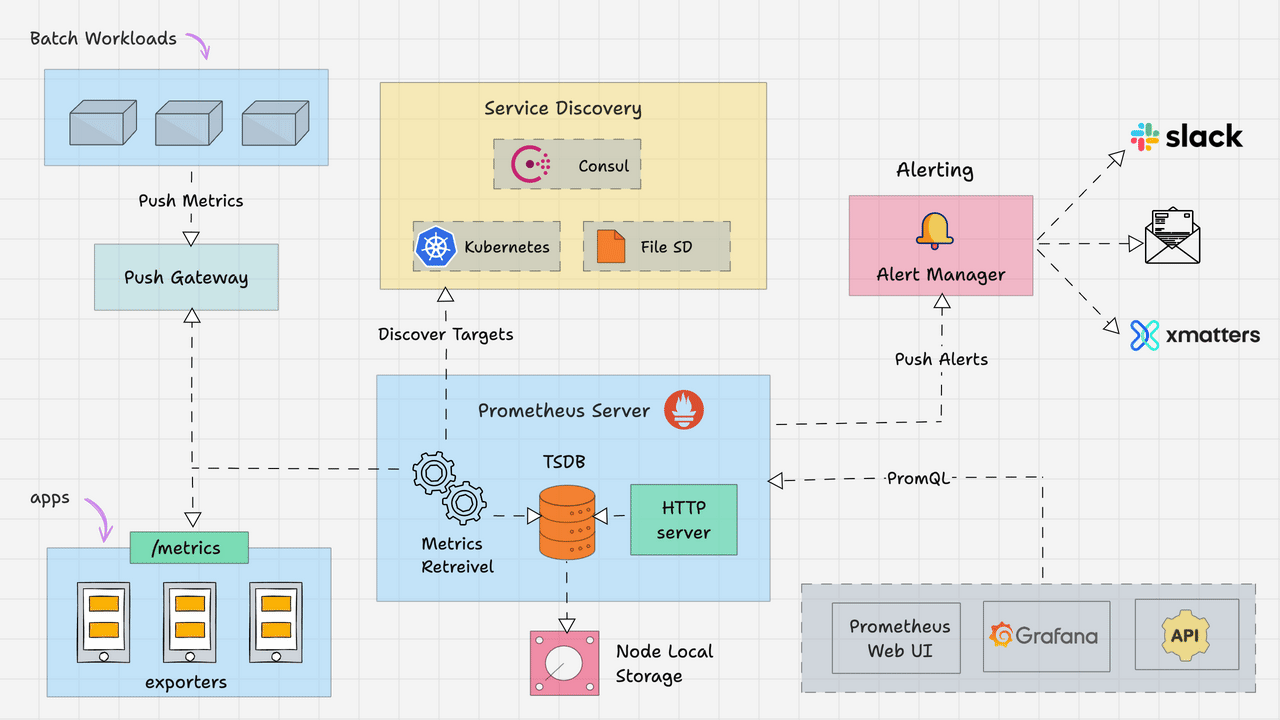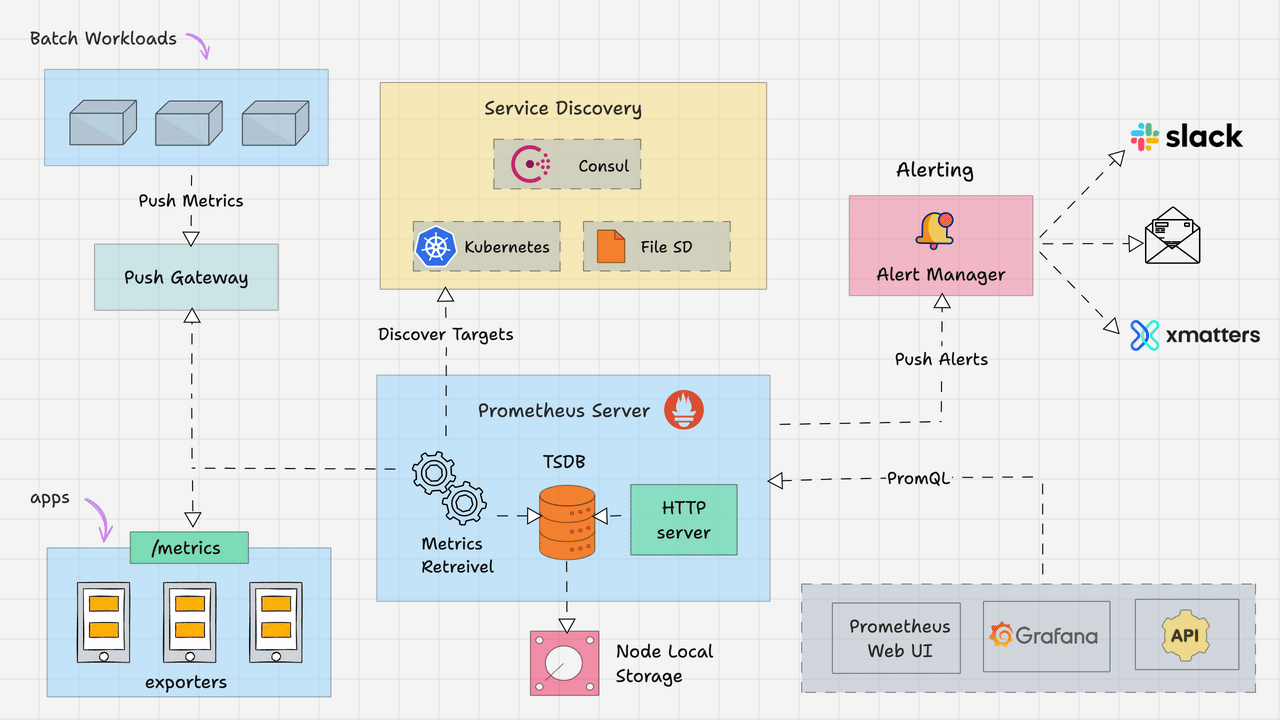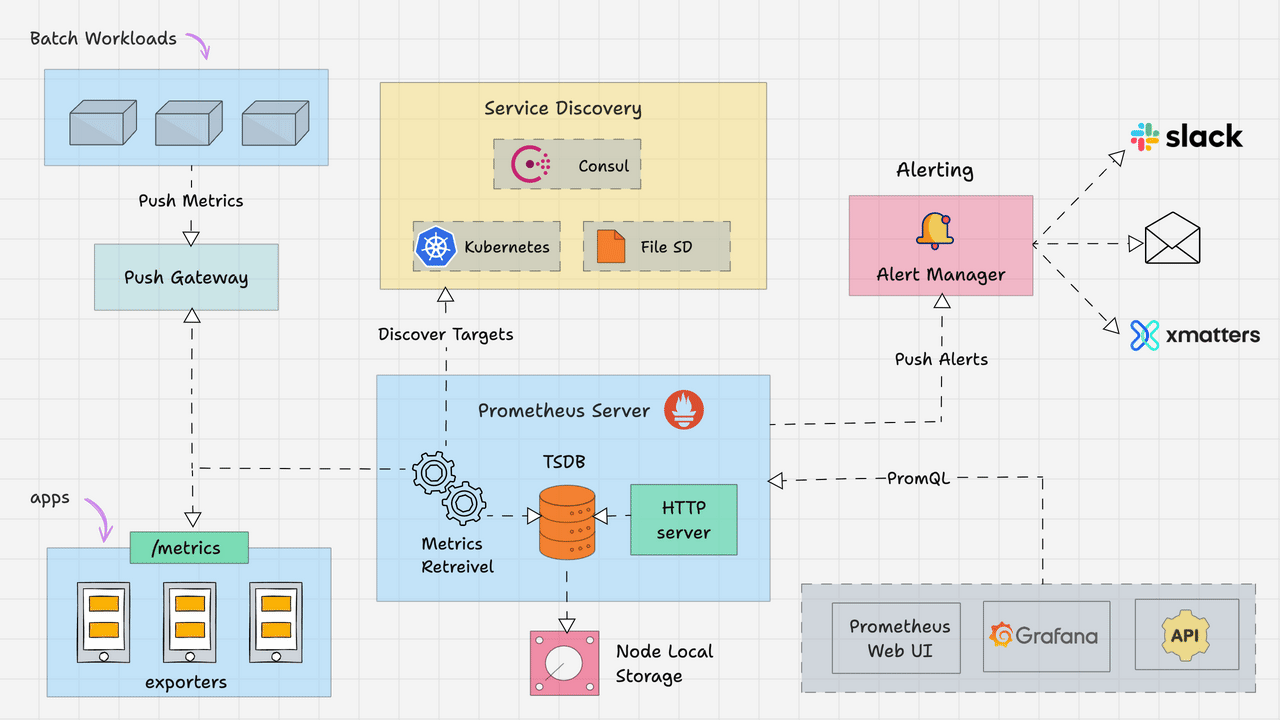
Prometheus 主要由以下部分组成。
- Prometheus 服务器
- 服务发现
- 时序数据库(TSDB)
- 目标
- 导出器
- 推送网关
- 警报管理器
- 客户端库
- PromQL系列
让我们详细看一下每个组件。
Prometheus 服务器
Prometheus 服务器是基于指标的监控系统的大脑。服务器的主要工作是使用拉取模型从各种目标收集指标。
Target 只不过是服务器、pod、端点等,我们将在下一主题中详细介绍。
使用 Prometheus 从目标收集指标的一般术语称为抓取(pull)。
Prometheus 会根据?Prometheus 配置文件中提到的抓取间隔定期抓取指标。
下面是一个示例配置。
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_timeout: 10s
rule_files:
- "rules/*.rules"
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
- job_name: 'node-exporter'
static_configs:
- targets: ['node-exporter:9100']
alerting:
alertmanagers:
- static_configs:
- targets: ['alertmanager:9093']时序数据库(TSDB)
prometheus 接收的指标数据会随时间变化(CPU、内存、网络 IO 等)。它称为时间序列数据。因此,Prometheus 使用时间序列数据库?(TSDB) 来存储其所有数据。
默认情况下,Prometheus 将其所有数据以有效的格式(块)存储在本地磁盘中。随着时间的流逝,它会压缩所有旧数据以节省空间。它还具有保留策略来删除旧数据。
Prometheus 还提供远程存储选项。这主要是存储可扩展性、长期存储、备份和灾难恢复等所必需的。
Prometheus 目标
Target 是 Prometheus 抓取指标的来源。目标可以是服务器、服务、Kubernetes Pod、应用程序端点等。
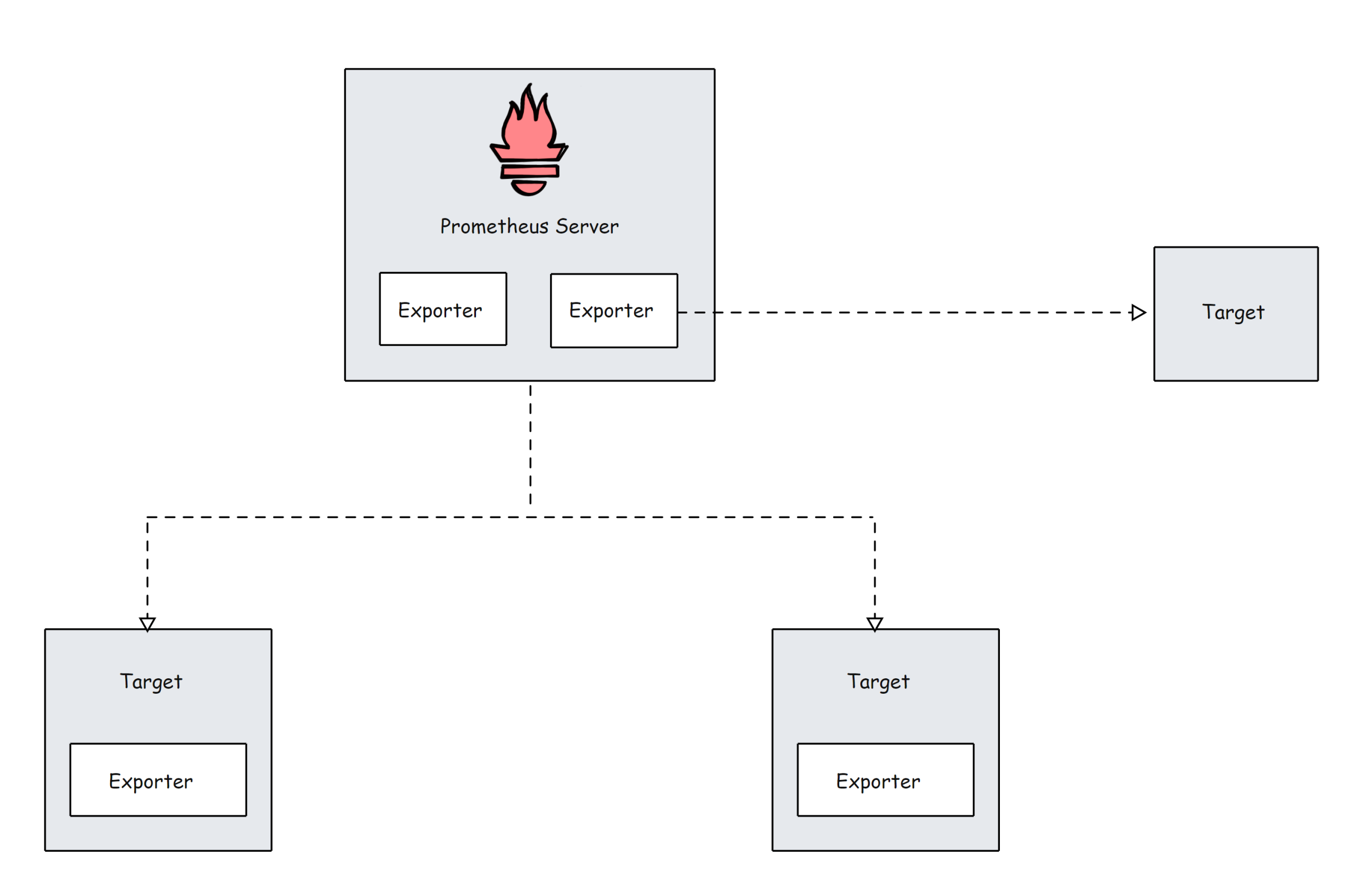
默认情况下,prometheus 在目标路径下查找指标。可以在目标配置中更改默认路径。这意味着,如果您未指定自定义指标路径,Prometheus 会在?/metrics?下查找指标。/metrics
目标配置位于配置文件的scrape_configs下。下面是一个示例配置。Prometheus
scrape_configs:
- job_name: 'node-exporter'
static_configs:
- targets: ['node-exporter1:9100', 'node-exporter2:9100']
- job_name: 'my_custom_job'
static_configs:
- targets: ['my_service_address:port']
metrics_path: '/custom_metrics'
- job_name: 'blackbox-exporter'
static_configs:
- targets: ['blackbox-exporter1:9115', 'blackbox-exporter2:9115']
metrics_path: /probe
- job_name: 'snmp-exporter'
static_configs:
- targets: ['snmp-exporter1:9116', 'snmp-exporter2:9116']
metrics_path: /snmp从目标端点,prometheus?需要特定文本格式的数据。每个指标都必须位于新行上。
通常,这些指标使用在目标上运行的?prometheus 导出器在目标节点上公开。
Prometheus 导出器
导出器就像在目标上运行的代理。它将指标从特定系统转换为 prometheus 理解的格式。
它可以是 CPU、内存等系统指标,也可以是 Java JMX 指标、MySQL 指标等。
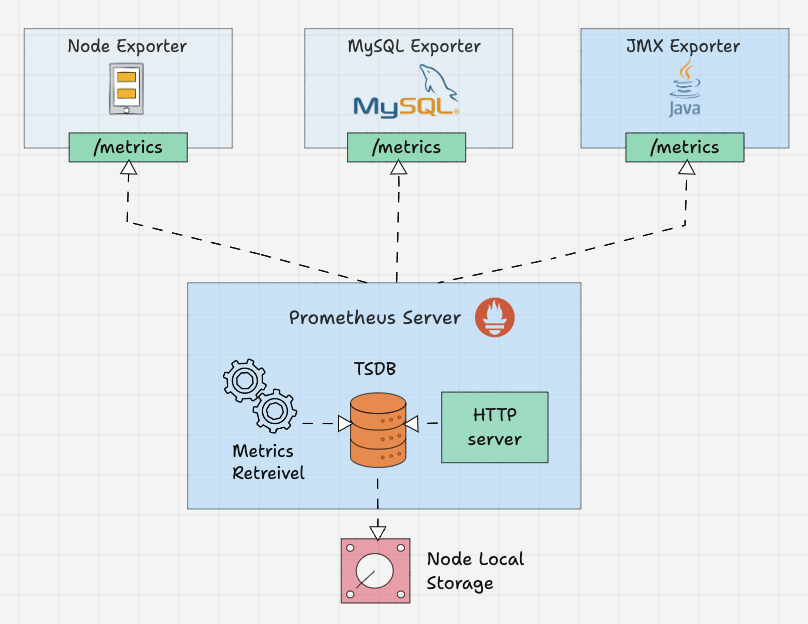
默认情况下,这些转换后的指标由导出器在目标的?/metrics?路径(HTTPS 端点)上公开。
例如,如果要监视服务器的 CPU 和内存,则需要在该服务器上安装节点导出器,并且节点导出器会在?/metrics?上以 prometheus 指标格式公开?CPU 和内存指标。
一旦 Prometheus?提取了指标,它将组合指标名称、标签、值和时间戳,为该数据提供结构。
有很多社区导出器可用,但只有其中一些得到了 Prometheus 的正式批准。如果需要更多自定义项,则需要创建自己的导出器。
Prometheus 将导出器分为各个部分,例如数据库、硬件、问题跟踪器和持续集成、消息传递系统、存储、公开 Prometheus 指标的软件、其他第三方实用程序等。
您可以从官方文档中查看每个类别的出口商列表。
在 Prometheus 配置文件中,所有导出器的详细信息都将在 .scrape_configs
scrape_configs:
- job_name: 'node-exporter'
static_configs:
- targets: ['node-exporter1:9100', 'node-exporter2:9100']
- job_name: 'blackbox-exporter'
static_configs:
- targets: ['blackbox-exporter1:9115', 'blackbox-exporter2:9115']
metrics_path: /probe
- job_name: 'snmp-exporter'
static_configs:
- targets: ['snmp-exporter1:9116', 'snmp-exporter2:9116']
metrics_path: /snmpPrometheus 服务发现
Prometheus 使用两种方法从目标中抓取指标。
- 静态配置:当目标具有静态?IP 或 DNS 端点时,我们可以将这些端点用作目标。
- 服务发现:在大多数自动缩放系统和分布式系统(如 Kubernetes)中,目标不会有静态终结点。在这种情况下,将使用 prometheus 服务发现来发现目标端点,并将目标自动添加到 prometheus 配置中。
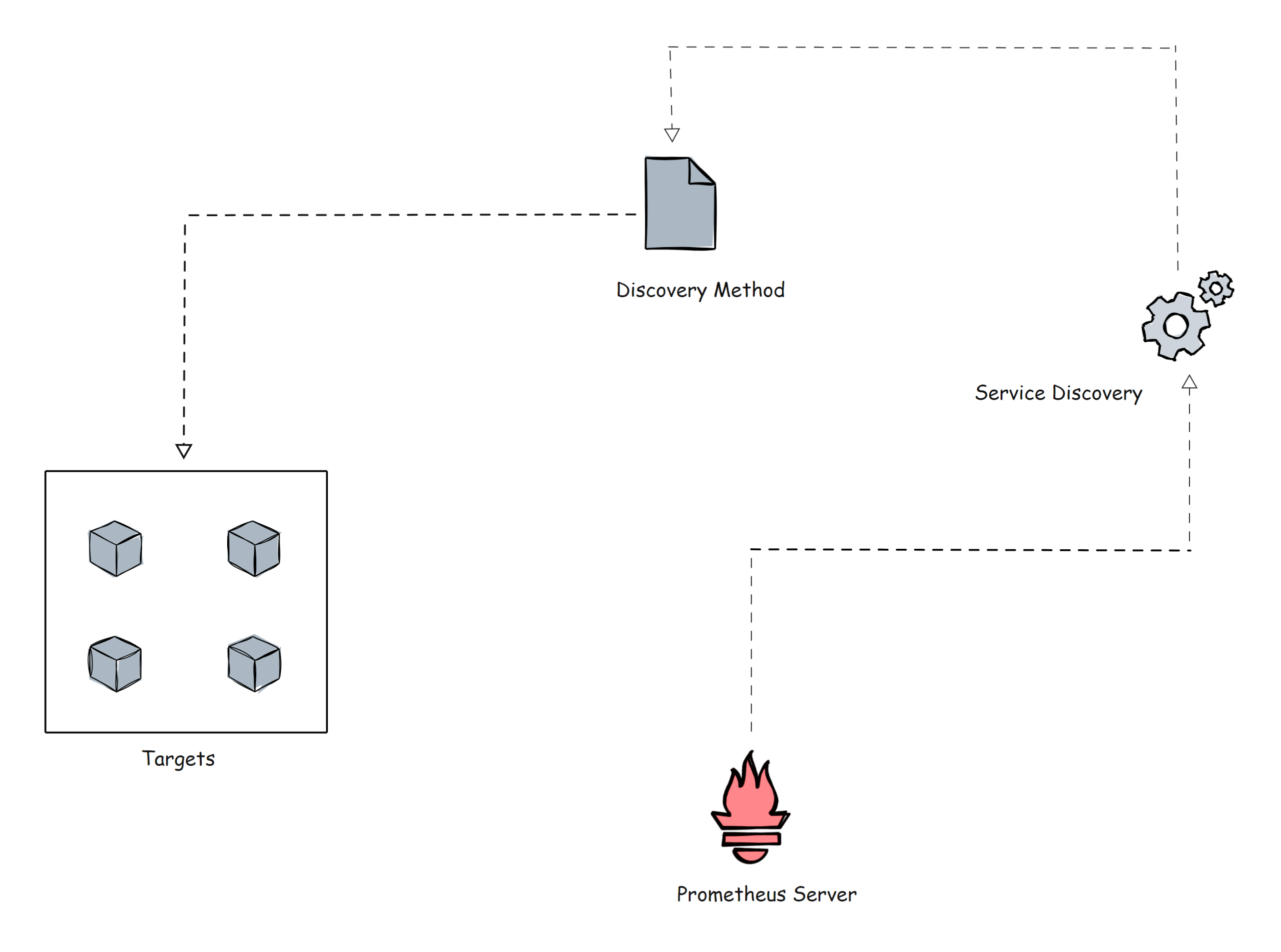
在继续之前,让我展示一个使用?Prometheus 配置文件的?Kubernetes 服务发现块的小示例。kubernetes_sd_configs
scrape_configs:
- job_name: 'kubernetes-apiservers'
kubernetes_sd_configs:
- role: endpoints
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: default;kubernetes;httpsKubernetes 是动态目标的完美示例。在这里,您不能使用静态目标方法,因为?Kubernetes 集群中的目标(Pod)本质上是短暂的,并且很可能是短暂的。
Kubernetes 中还有基于文件的服务发现。它适用于静态目标,但经典静态配置与静态配置之间的主要区别在于,在这种情况下,我们创建单独的 JSON 或 YAML 文件并将目标信息保存在其中file_sd_configs。Prometheus 将读取文件以识别目标。static_configs?file_sd_configs
不仅这两个,还有各种服务发现方法可用,例如 consul_sd_configs(prometheus 从?consul?获取目标详细信息)、ec2_sd_configs等。
要了解有关配置详细信息的更多信息,请访问官方文档。
Prometheus 推送网关
默认情况下,Prometheus 使用拉取机制来获取指标。
但是,在某些情况下,需要将指标推送到 prometheus。
让我们举一个在?Kubernetes cronjob?上运行的批处理作业的例子,该作业每天根据某些事件运行 5 分钟。在这种情况下,Prometheus 将无法使用拉取机制正确抓取服务级别指标。
因此,为了等待 prometheus 拉取指标,我们需要将指标推送到 prometheus。为了推送指标,prometheus 提供了一个名为?Pushgateway 的解决方案。?它是一种中间网关。
Pushgateway?需要作为独立组件运行。批处理作业可以将指标推送到 pushgateway 端点,Pushgateway?会公开这些指标。然后 prometheus 从 Pushgateway 中抓取这些指标。
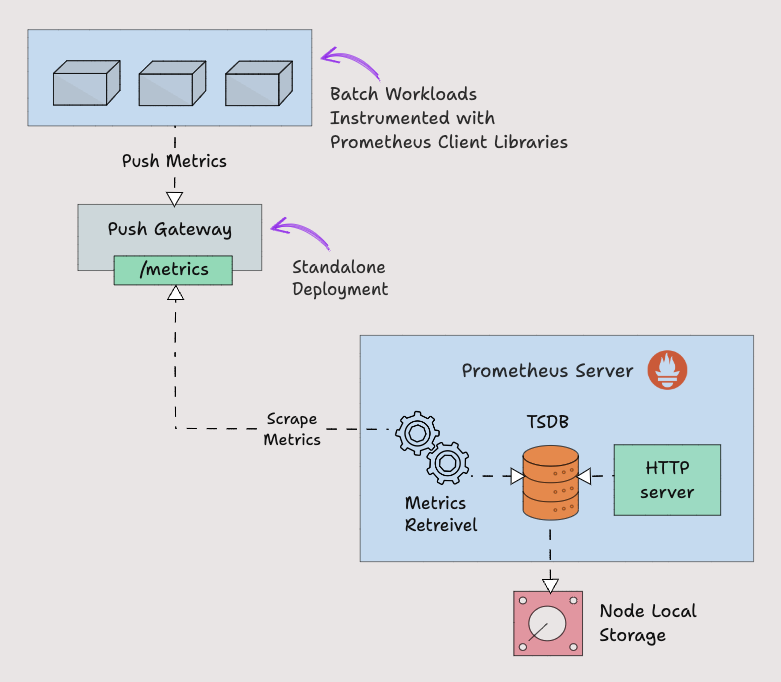
Pushgateway 将指标数据临时存储在内存存储中。它更像是一个临时缓存。
Pushgateway?配置也将在配置中的部分下进行配置。scrape_configs?Prometheus
scrape_configs:
- job_name: "pushgateway"
honor_labels: true
static_configs:
- targets: [pushgateway.monitoring.svc:9091]要将指标发送到 Pushgateway,您需要使用 prometheus?客户端库并检测应用程序或脚本以公开所需的指标。
Prometheus 客户端库
Prometheus?客户端库是软件库,可用于检测应用程序代码,以 Prometheus 理解的方式公开指标。
如果需要自定义检测或想要创建自己的导出器,可以使用客户端库。
一个非常好的用例是需要将指标推送到 Pushgateway 的批处理作业。批处理作业需要使用客户端库进行检测,以 prometheus 格式公开需求指标。
以下示例公开了名为?batch_job_records_processed_total?的自定义指标。Python Client Library
from prometheus_client import start_http_server, Counter
import time
import random
RECORDS_PROCESSED = Counter('batch_job_records_processed_total', 'Total number of records processed by the batch job')
def process_record():
time.sleep(random.uniform(0.01, 0.1))
RECORDS_PROCESSED.inc()
def batch_job():
for _ in range(100):
process_record()
if __name__ == '__main__':
start_http_server(8000)
print("Metrics server started on port 8000")
batch_job()
print("Batch job completed")
while True:
time.sleep(1)此外,在使用客户端库时,HTTP 服务器prometheus_client端点中公开指标。/metrics
Prometheus 几乎为每种编程语言提供了客户端库,如果您想创建客户端库,也可以这样做。
要了解有关创建指南的更多信息并查看客户端库列表,您可以参考官方文档。
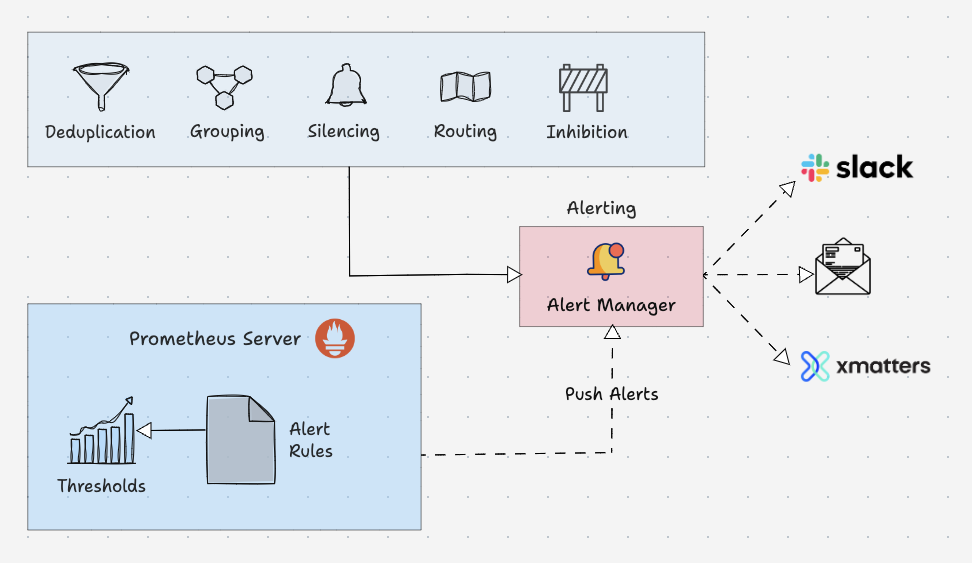
Prometheus 警报管理器
Alertmanager是Prometheus监控系统的关键部分。它的主要工作是根据?Prometheus 警报配置中设置的指标阈值发送警报。
警报由 Prometheus 触发并发送到 Alertmanager。它反过来将警报发送到警报管理器配置中配置的相应通知系统/接收器(电子邮件、松弛等)。
此外,警报管理器还负责以下工作。
- 警报重复数据删除:静默重复警报的过程。
- 分组:将相关警报分组到其他位置的过程。
- 静音:静音警报,用于维护或误报。
- 路由:根据严重性将警报路由到适当的接收器。
- 禁止:当存在中等高严重性警报时停止低严重性警报的过程。
下面是警报规则的示例配置。
groups:
- name: microservices_alerts
rules:
- record: http_latency:average_latency_seconds
expr: sum(http_request_duration_seconds_sum) / sum(http_request_duration_seconds_count)
- alert: HighLatencyAlert
expr: http_latency:average_latency_seconds > 0.5
for: 5m
labels:
severity: critical
annotations:
summary: "High latency detected in microservices"
description: "The average HTTP latency is high ({{ $value }} seconds) in the microservices cluster."
这是 Alertmanager 配置文件的路由配置示例
routes:
- match:
severity: 'critical'
receiver: 'pagerduty-notifications'
- match:
severity: 'warning'
receiver: 'slack-notifications'警报管理器支持大多数消息和通知系统,例如 Discord、电子邮件、Slack 等,以将警报作为通知发送给接收者。
PromQL系列
PromQL 是一种灵活的查询语言,可用于从 Prometheus 查询时间序列指标。
我们可以直接从用户界面使用查询,也可以使用命令通过命令行界面进行查询。Prometheuscurl
Prometheus 用户界面
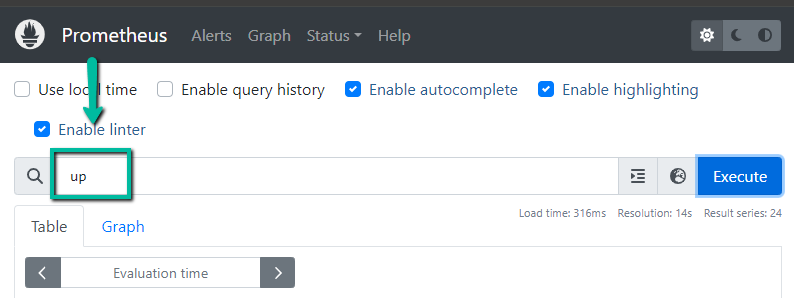
通过 CLI 查询
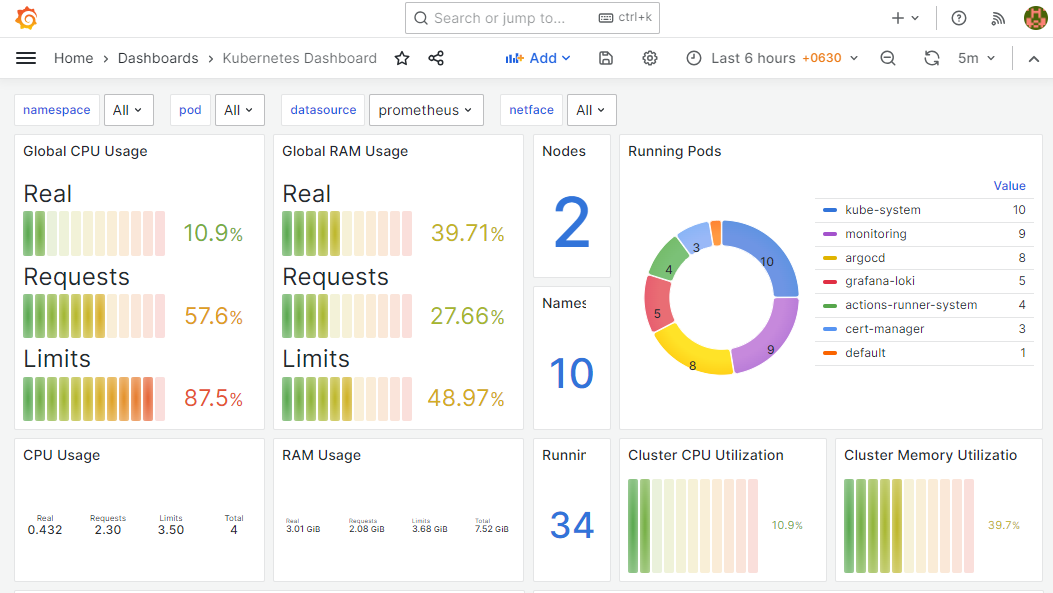
curl "http://54.186.154.78:30000/api/v1/query?query=$(echo 'up' | jq -s -R -r @uri)" | jq .此外,当您将 prometheus 作为数据源添加到 Grafana 时,您可以使用 PromQL 查询和创建 Grafana 仪表板,如下所示。
结论
本文解释了 Prometheus 架构的主要组件,并将提供 Prometheus 配置的基本概述,您可以使用该配置执行更多操作。
每个组织的要求都不同,Prometheus 在不同环境中的实现也各不相同,例如 VM 和 Kubernetes。如果您了解基础知识和关键配置,则可以在任何平台上轻松实现它。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!