Multi-Task Learning based Video Anomaly Detection with Attention 论文阅读
Multi-Task Learning based Video Anomaly Detection with Attention
文章信息:

原文链接:https://ieeexplore.ieee.org/document/10208994/
源代码:无
发表于:CVPR 2023
Abstract
基于多任务学习的视频异常检测方法将多个代理任务结合在不同的分支中,以便在不同情境中检测视频异常。然而,大多数现有方法存在以下一些缺点:
I) 它们的代理任务组合方式不是以互补且可解释的方式进行的。
II) 对象的类别没有得到有效考虑。
III) 并未覆盖所有运动异常情况。
IV) 上下文信息未参与异常检测。
为了解决这些问题,我们提出了一种新颖的基于多任务学习的方法,它结合了互补的代理任务以更好地考虑运动和外观特征。在一个分支中,受语义分割和未来帧预测任务的能力启发,我们将它们合并成一个新任务,即未来语义分割预测,以学习正常对象类别和一致的运动模式,并同时检测相应的异常。在第二分支中,我们利用光流幅度估计进行运动异常检测,并提出了一种注意机制,以在正常运动建模中引入上下文信息,并关注对象部分、运动方向和对象与摄像机之间的距离,以检测运动异常。我们的定性结果表明,所提出的方法有效地考虑了对象类别,并注意了上述决定性因素,从而实现了精确的运动建模和更好的运动异常检测。此外,定量结果显示我们的方法相对于最先进的方法具有优越性。
1. Introduction
随着监控摄像头的增多,对视频内容的自动分析需求不断增加。通常,该分析的目的是检测视频中的异常事件(即在给定背景下不熟悉或意外的事件[10, 20]),这可能需要立即采取行动。由于异常事件的罕见性和多样性,通常很难获得足够的训练异常样本用于监督训练。因此,该领域的研究人员更加关注半监督方法,其中通过代理任务(即间接帮助实现目标目标的任务)学习正常情况,通过找到与正常情况的偏差来检测异常。例如,在视频异常检测(VAD)中,当前帧的重建或遮罩帧的预测是常见的代理任务,训练模型对于正常情况显示出对异常的较差的重建或预测结果,而估计的错误决定了异常分数。研究人员在他们的方法中的多个分支中采用不同的代理任务,以考虑不同的模态性(主要是外观和运动)。不同的代理任务旨在相互补充,因此被组合以实现更高的性能。例如,Nguyen和Meunier [47] 提出了一个两流网络,其中一个流模拟外观特征并检测基于外观的异常,而另一个流模拟运动模式并寻找运动异常。已经提出了多种类似的策略,每个工作都提出了不同的代理任务组合和不同的异常分数融合策略[7, 16, 20, 26, 47, 57]。最近,研究人员(例如 [11, 20, 29])提议添加更多的代理任务(即基于多任务学习的方法)以涵盖更多的时空模式。多任务学习方法中的关键问题是选择多少/哪些代理任务才能达到互补并提高性能。通常,添加更多的代理任务可能会导致更好的性能;但是,这会增加计算负担和运行时间。因此,设计目标是提出最少量的互补任务,考虑它们在检测多种异常类型中的能力和不足,以覆盖所有必要的属性。值得注意的是,可解释的异常检测要求在选择每个代理任务背后有一个强有力的解释。
尽管最近的方法取得了更好的结果,它们仍然要么没有充分考虑运动模式,要么没有明确分析对象类别进行异常检测。为了解决这些缺点,受到[20]的启发,我们提出了一种改进的基于多任务学习的视频异常检测(VAD)方法。与[20]不同,并借鉴语义分割任务在VAD中考虑对象类别的成功[7],我们在外观分支中以一种改进的方式利用语义分割代理任务的能力。此外,与[20]相反,后者在对象级别执行异常检测,我们提出了一种全面的VAD方法,避免了失去位置信息的缺点。
Nguyen等人[47]提出从单帧估计光流(OF)以建模运动模式并检测相关的异常。然而,从单帧估计光流可能对运动网络造成困扰。为了克服这个问题,Baradaran和Bergevin [7]提出使用每个对象的光流幅度(OFM)估计来检测运动异常。尽管他们的方法解决了上述问题,但他们的方法在运动估计中忽略了运动方向信息。因此,他们的方法不能有效检测由于突然的方向变化引起的异常(例如打斗、跳跃等)。此外,为了使每个对象与其运动幅度(即基于像素的对象在帧间位移)相对应,一些重要因素,如运动方向、对象部分和对象与摄像机的距离,未被考虑在内。
我们提出了一种解决先前问题的新方法。所提出的方法利用了两种不同的注意力机制。它利用了空间和通道注意力网络,并将其应用于编码器中间层的特征图,帮助网络考虑对象的部分(手、脚等)以进行运动幅度估计。此外,设计了一个新的注意力网络,帮助估计每个对象的运动幅度,关注其与摄像机的距离和运动方向(详见第3节的细节)。最后,利用未来帧预测作为另一个代理任务,以找到突发运动变化。为了减小网络的大小,语义分割和未来帧预测任务被合并成一个新颖的未来语义分割预测任务,由单个网络执行。
概括而言,我们的贡献是:
- 一种新颖的基于多任务学习的视频异常检测方法,以一种可解释的方式结合了三个互补的代理任务,即“未来帧预测”、“语义分割”和“光流幅值预测”,以更全面地考虑外观和运动特征进行异常检测。
- 将语义分割和未来帧预测任务结合成一个新颖的代理任务,以寻找外观和运动异常。据我们所知,这是首次引入未来语义分割预测代理任务用于视频异常检测的工作。
- 一种新颖的注意力网络,用于估计对象的精确运动幅度,关注其运动方向和与摄像机的距离。这引入了一种新颖的方式,在建模法线和检测相应异常时引入上下文信息。我们还在运动估计分支的主干部分采用了空间和通道注意力机制,以增强有意义的特征并生成特定于不同对象部分的估计。
我们提出的方法的总体视图如图1所示。
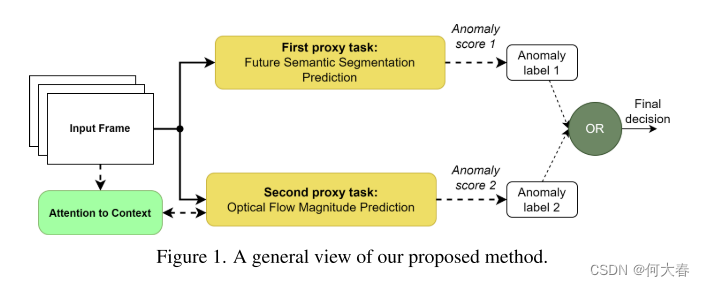
2. Previous work
研究人员通过各种代理任务,特别是帧重建[1, 3, 13, 18, 19, 22–25, 28, 30, 37, 38, 40, 43, 45, 48, 51, 52, 59, 60, 64]或预测任务[4, 5, 12, 15, 32–34, 36, 39, 42, 44, 46, 54, 56, 58, 62, 63, 65, 67]制定了视频异常检测,假设在法线上训练的无监督网络(例如UNet)生成的重建/预测误差较大表示异常。然而,所有先前提到的方法都考虑用于异常检测的低级特征(颜色、强度等),并且在评估中没有明确考虑对象的类别。以对象为中心的视频异常检测方法[9, 17, 21, 26, 27, 53, 55, 61]通过预训练的对象检测器从帧中检测和裁剪对象,但它们在训练和推断中只考虑低级特征。受[8, 31]的启发,Baradaran和Bergevin [7]提出了一种基于知识蒸馏的视频异常检测方法,使用语义分割作为代理任务,因此能够明确考虑对象的类别进行异常检测。
Baradaran和Bergevin [6]报告称,单分支方法(例如[13, 24])不能有效覆盖所有运动情况,通常被外观特征所主导。因此,为了解决单流方法的缺点,研究人员[7, 16, 26, 47]提出了双流视频异常检测方法,以在独立的分支中有效检测运动和外观。它们主要通过重建运动特征(例如光流特征、两图像梯度等)[35]来解决运动异常检测问题。其中最引人注目的相关工作之一是由Neygun和Meunier [47]提出的,其将运动学习构建为从输入帧到其相应的光流图的平移,试图考虑对象与其运动之间的对应关系,以进行运动异常检测。Baradaran和Bergevin [7]提出将输入帧翻译为其光流幅度(仅考虑运动的幅度),因为他们报告称,网络在从单帧预测完整光流时可能会混淆。尽管他们的方法解决了混淆问题,并学习了每个对象与其运动幅度之间的对应关系以检测相关的异常,但他们的方法忽略了方向信息。因此,他们的方法可能在检测由于方向突然变化而引起的异常时失败。此外,由于帧中感知到的运动也是相机距离(即相同的运动幅度在距离相机更远时看起来较小)和运动方向等因素的函数,因此他们的方法可能在精确的运动幅度预测方面失败,而这些重要因素在他们的方法中未被考虑。
受到多任务学习方法在考虑异常检测中的不同关键方面方面取得成功的启发,我们提出了一种改进的基于多任务学习的视频异常检测(VAD)方法,采用互补的代理任务来克服上述缺点,更有效地涵盖外观和运动异常。受到未来帧预测和语义分割预测任务在分别检测突发运动变化和对象类别感知外观异常方面的成功启发,我们将它们合并成一个单一任务,并引入未来语义分割预测作为视频异常检测的新代理任务。我们还设计了注意力层,通过学习运动并考虑关键的上下文信息,以及关注对象部分、运动方向和对象的距离来估计运动。
3. Method
我们提出了一种基于多任务学习的视频异常检测方法,利用两个独立分支中的三个自监督代理任务的能力来建模正常模式,从而检测异常。所提出方法的流程如图2所示,并在接下来的内容中进行了详细描述。
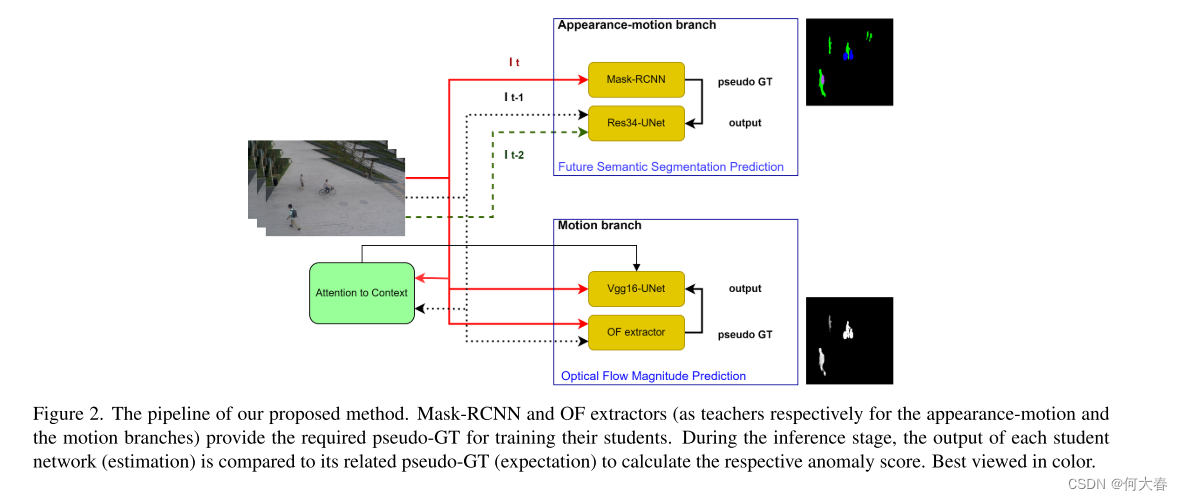
3.1. Multi-task learning
受到[20]的启发,我们提出了一种基于多任务学习的视频异常检测(VAD)方法,该方法利用两个分支中的三个代理任务进行异常检测。第一分支(命名为外观-运动分支)结合了两个不同的任务(语义分割和未来帧预测),以同时建模外观和运动。第二分支(即运动分支)负责学习每个正常对象及其正常运动幅度之间的对应关系,关注其与摄像机的距离、运动方向和身体部位。通过这种方式,三个任务相互补充,每个任务都试图找到其他任务可能不够优化的异常。
3.2. The appearance-motion branch
[7]中的实验证明,利用语义分割作为代理任务有助于有效地发现外观异常,考虑到对象的类别。此外,我们的实验证明(相关信息见第4节),未来帧预测是检测突发运动变化(例如方向变化、加速度)的一项合适任务,因为网络在训练时预测两个连续正常帧的未来帧时,无法准确预测具有突发运动变化的对象的位置(例如在打斗、跳跃等情况下)。为了利用这两个任务的能力,我们方法的第一个分支将语义分割和未来帧预测这两个不同的任务合并成一个新的单一任务,旨在通过观察两个连续帧来预测未来帧的语义分割图。通过这种方式,它不仅在训练期间学习了帧中正常对象的类别,还学习了两个正常帧之间的正常演变。该分支采用了一种师生策略进行异常检测。在训练期间,一个学生(在我们的方法中是resnet34-UNet)获取两个连续帧,并学习生成未来帧的语义分割图(即下一帧),假设在推断时,对异常而言,预测误差会更大。用于训练学生网络的伪Ground-Truth(GT)是通过在MS COCO上训练的Mask-RCNN生成的。
3.3. The motion branch
尽管第一个分支在一定程度上考虑了运动异常,但并未涵盖所有运动情况。因此,在第二个分支中,我们采用了[7]中提出的想法,即通过将输入帧翻译为其光流幅度图来为每个对象学习正常的运动幅度。这个分支也采用了一种师生策略,其中学生(在这里是vgg16-UNet)学习将输入帧翻译为其光流幅度图,由预训练的光流提取器生成(考虑到其过去的帧)作为伪GT。通过这种方式,在训练期间,学生网络学习了每个对象与其正常运动幅度之间的对应关系,假设对于运动速度快/慢于其正常运动的对象,它将进行不准确的运动估计。然而,原始方法存在一些挑战,如下所示:
1)一些对象(如人类)在其所有身体部位中的运动幅度并不恒定。例如,与胸部和头部相比,手和脚通常具有更大的运动幅度。这一因素在[7]中未被考虑。
2)在帧中感知到的运动幅度(对象的像素位移)是一些变量的函数,例如运动方向和对象距离相机的距离。与相机平行移动的对象显示出较大的运动(即生成较大的光流幅度),而与相机远离/接近的对象相比则较小。因此,没有考虑这些因素的运动建模和运动幅度估计将导致不准确的预测。
在我们的运动分支(图3)中,我们采用两种不同的注意力机制来解决前述的缺陷,并引入运动建模中的关键因素,以解决[7]中的问题。我们在主网络中使用了一个空间和通道注意力网络,以更多地关注特定的身体部位(如脚和手),同时我们还设计了一个新的注意力网络,帮助网络在考虑补充信息(如运动方向和相对距离信息)时进行预测。接下来提供注意力机制的详细信息。
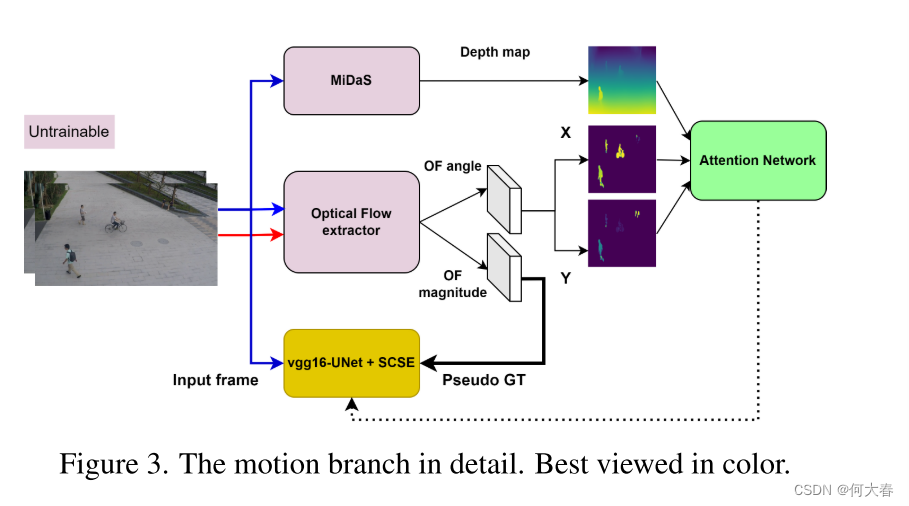
3.4. Spatial and channel attention
通过可视化运动分支中基础vgg16-UNet生成的特征图,我们观察到vgg16-UNet的编码器(半监督训练)通过不同层生成不同级别的特征,中间层生成的特征图对不同的对象部分被激活。因此,我们在中间层的特征图上应用了[2]中提出的空间和通道注意力(SCSE)机制,以帮助网络更多地关注不同的身体部位。
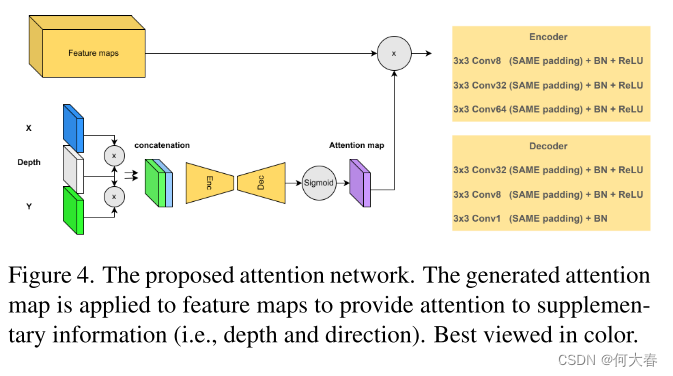
3.5. Attention to distance and direction
正常状态在特定环境中定义。因此,半监督异常检测方法中的关键点和挑战在于精确建模正常模式,并通过测量与正常情况的偏差来发现异常。先前的方法在运动建模(和估计)中未考虑重要因素(例如方向和距离相机的距离)。为了关注这些因素并为对象获取精确的运动模型,我们设计了另一个注意力网络,如图4所示。该网络使用方向和距离信息作为输入,并生成一个注意力图,以应用于具有关注机制的层。
在运动分支中,教师网络提取两个连续帧(
I
t
?
1
、
I
t
I_{t?1}、I_t
It?1?、It?)的光流,并将光流的幅度作为伪-GT提供给学生,以便学生将输入帧(
I
t
I_t
It?)映射到其光流幅度图(OFM)。教师生成的光流特征(在公式(1)中表示为OF)包括方向信息和幅度信息。在公式(1)中,Mag代表光流的幅度,Ang代表相对于帧水平轴的运动角度。Ang特征可以作为方向特征提供给我们的注意力网络。然而,我们计算Ang的Cosine和Sine以进行归一化,并生成两个不同的特征:相对于相机平行的运动(在公式(2)和图4中表示为X),以及相对于相机的运动(在公式(3)和图4中表示为Y)。
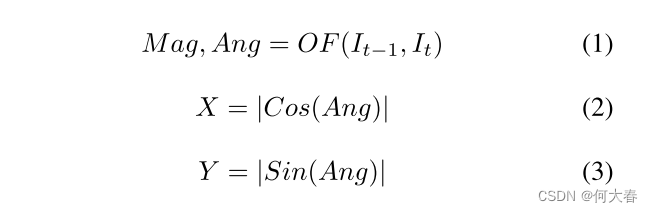
由于我们没有关于对象距离相机的实际信息,我们提取帧的深度图来表示对象相对于相机的相对距离信息。我们使用MiDaS [49,50]来估计输入帧的相对深度图。MiDaS通过在10个不同的数据集上进行多目标优化进行预训练,确保对于广泛的输入具有高质量的深度图生成。我们使用该方法的混合版本来平衡精度和执行时间。图4显示了如何在注意力网络内部组合和处理提取的信息以生成注意力图。
3.6. Inference
在推断阶段,我们将正常帧和异常帧分别提供给每个分支,然后将每个分支的估计与它们各自的期望值(即每个分支的教师生成的伪-GT)进行比较,以计算该帧的异常图。对于这两个分支中的每一个,我们计算异常图中激活的总和作为该分支对该帧的异常分数S(t)(公式(4))。
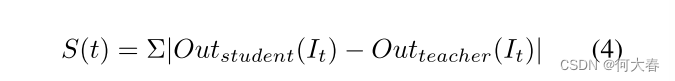
在公式(4)中,
O
u
t
s
t
u
d
e
n
t
(
I
t
)
Out_{student}(I_t)
Outstudent?(It?) 和
O
u
t
t
e
a
c
h
e
r
(
I
t
)
Out_{teacher}(I_t)
Outteacher?(It?) 分别表示给定分支的估计和期望。求和是在异常图中的所有像素上进行的(即学生和教师输出之间的差异)。
在我们的实验中,我们发现了一些误报,这是由于两个原因造成的:
1)由Mask-RCNN引起的误检测或误检测,它在异常图中产生了大的激活。
2)帧之间的跳跃,显然是由于录制或保存问题。这些跳跃在某些帧之间产生了虚假的大运动。
上述误报在一些帧的异常分数中产生了突然的跳跃/下降。然而,考虑到视频的帧率,我们假设相邻帧的异常分数应该是相似的。因此,为了放宽异常分数(即时间去噪),在异常分数上应用Savitzky–Golay滤波器(公式(5))[14]。
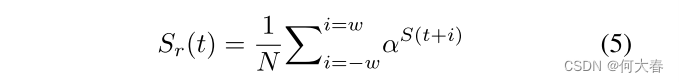
在这个方程中,
S
r
(
t
)
S_r(t)
Sr?(t)代表从嘈杂的异常分数S(t)生成的放松的异常分数。N是规范化因子,α和w分别是卷积系数和窗口大小。
最终,作为最终的决策,我们仅在分支1或分支2(或两者)的异常分数S(t)大于预定义的阈值时,将帧标记为异常。由于每个分支的网络都是通过正常帧进行训练的,如果输入帧包含与该分支特定的任何异常,我们期望在估计和期望之间观察到相当大的差异。这些异常图预计会在帧中异常位置处包含激活。
4. Experiments and results
我们在ShangahiTech Campus [32]和UCSD-Ped2 [41]数据集上训练和评估了我们提出的方法的性能以及每项贡献的有效性。实验的详细信息、定性和定量结果以及与最先进方法的比较将在接下来展示。
4.1. Datasets
ShanghaiTech Campus和UCSD-Ped2数据集是用于评估半监督视频异常检测方法的两个常用基准数据集。它们在训练子集中仅提供正常帧,在测试子集中提供正常和异常帧,同时提供基于帧和基于像素的注释。这两个数据集中正常和异常的定义相似。在这两个数据集中,行走在人行道上(可能携带包或背包)被视为正常,然而一些以前未见过的对象(如自行车、摩托车、汽车等)或一些以前未见过的运动模式(如跑步、追逐、打斗、骑行等)的存在被视为异常。与UCSD-Ped2相比,ShanghaiTech Campus是一个更复杂的数据集,因为它包含多个不同的场景(13个场景)和更多的异常情况。另一方面,低分辨率和灰度帧使得UCSD-Ped2数据集在分割任务中具有挑战性,并容易出现失败。
4.2. Evaluation metric
遵循该领域最先进方法(SOTA),我们通过测量帧级AUC(曲线下面积)来进行定量评估。该曲线是通过在将异常分数阈值从最小到最大变化的情况下,注册多个真正例率(TPR)和假正例率(FPR)来绘制的。更高的AUC表示更好的性能。
4.3. Implementation details
在我们的实验中,输入帧被调整为每个分支的256*256大小。为了更快地收敛,我们使用在Imagenet上训练的网络的参数初始化了两个学生网络(res34-UNet和vgg16-UNet)的编码器。两个分支的学习率初始化为0.001,并且每10个时期减半一次。我们使用带有Adam优化器的基于补丁的均方误差(MSE)损失(公式(6))[7](将输入帧划分为16个补丁)训练了两个分支的网络。我们使用在MS COCO上预训练的Mask-RCNN作为外观分支的教师,并使用OpenCV库中的Farneback算法作为从两个连续帧中提取伪GT光流特征的教师。最后,为了丢弃背景并更多地关注前景对象,我们使用相应的语义分割图对每个提取的光流图进行掩膜。
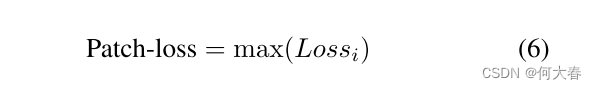
其中:
L
o
s
s
i
Loss_i
Lossi?是帧中第i个补丁中的MSE损失。
4.4. Future frame prediction
为了更详细地探讨未来帧预测代理任务的能力,我们进行了一项初步实验。我们训练了resnet-UNet通过观察两个连续帧来估计未来帧。

定性结果(图5)展示了未来帧预测代理任务在发现突然运动变化方面的能力。正如在这个图中所看到的,估计的未来帧和实际未来帧在追逐人物的位置上有差异(因此在异常图中产生更大的激活)。然而,网络能够在正常运动的对象位置生成精确的预测。值得注意的是,由于这个代理任务是在正常速度的运动上进行训练的,它也可以找到异常的快速运动。然而,由于CNN的高容量,未来预测的能力也可以推广到这些异常情况。换句话说,如果快速物体在帧之间单调快速移动且不显示方向的突然变化,CNN可以预测快速物体的精确位置。

在图6(a)中,滑板骑手通过相邻帧快速而均匀地移动,因此CNN在该位置不产生高异常激活。然而,当她突然将脚放在地面上加速时(图6(b)),生成的异常激活相对较高。在我们提出的方法中,这个缺点是由光流幅度图(OFM)预测代理任务处理的。
4.5. Qualitative evaluation
为了定性分析所提出方法的有效性,我们观察了多个正常和异常帧的异常图。图7和图8分别展示了外观-运动分支和运动分支的定性结果。图7包含由外观-运动分支生成的异常帧(顶行)和相应的异常图(底行)的多个样本。正如图中所示,异常图在异常对象(第1和第2列的自行车和摩托车)或甚至在正常对象上的异常突然运动(第3列的打斗者的腿和手以及第4和第5列的奔跑或追逐人员)处包含更高的激活。

在图8中,运动分支也可以观察到类似的结果。正如可以看到的那样,我们的方法在具有异常运动的对象上生成更大的激活,因为运动分支的估计与异常的期望相比差异相当大。

4.5.1 Importance of attention
图9展示了一个异常帧(9a)以及在应用和不应用注意力机制的情况下生成的异常图。可以注意到,在注意力存在的情况下,生成的异常图在正常移动对象的位置(绿色边界框)含有较弱的激活,相比于没有注意力的情况。这表明,在注意力机制激活时,对正常对象的运动估计更加精确。例如,对于靠近相机的行人(图9b中下面的绿色边界框),基本网络不考虑距离信息,估计的运动较小,导致估计和伪GT之间的差异较大(因此在异常图中的激活较大),相比于注意力机制激活时(图9c)。此外,当注意模块不激活时,观察到正常移动对象上部绿色边界框的脚部的激活较大。在这两种情况下,注意力机制减少了误报异常的可能性。
图10显示了带有注意力的运动分支的估计结果。可以观察到,网络能够识别对象的部分并对脚部估计出更大的运动,相比于其他部分。此外,对于靠近相机的对象,估计的运动也更大。

4.6. Quantitative evaluation
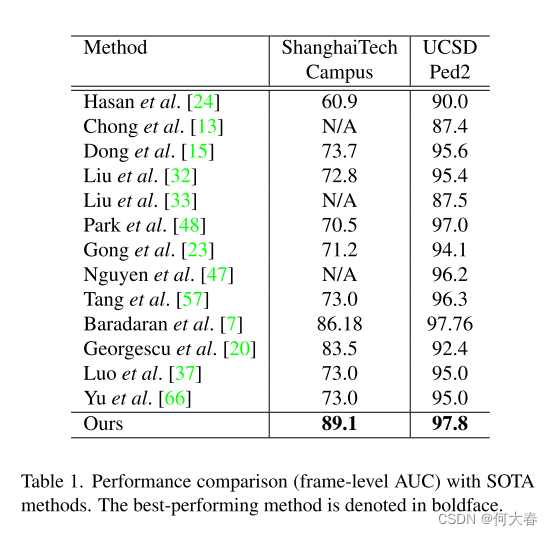
表格1比较了我们提出的方法与最先进的(SOTA)整体半监督视频异常检测方法在两个基准数据集(ShanghaiTech Campus和UCSD-Ped2)上的性能。比较基于帧级AUC。为了进行公正的比较,我们保持了原始论文的设置。
正如所见,与SOTA整体半监督视频异常检测方法相比,我们的方法提供了更优越的结果。值得注意的是,与UCSD-Ped2相比,我们的方法在ShanghaiTech Campus的性能提升(尤其是与[7]等以前的方法相比)更为显著。这可以解释为精确的运动建模在ShanghaiTech Campus中更为关键,因为它具有距离相机不同的对象和各种方向的运动,而UCSD-Ped2在运动方向和距离方面有限。因此,我们在运动建模方面的贡献(即通过注意力机制引入上下文信息)为ShanghaiTech Campus带来了更大的改进,验证了我们的方法成功解决了以前方法的已知限制。
上述的定性和定量结果足以表明我们的目标已经实现。然而,通过在其他数据集上进行实验证明我们方法的普适性可能会更有趣,而我们调查的一个可能性是Avenue数据集,该数据集在该领域中被广泛使用。尽管与SOTA方法相比,所得到的结果不如表1中的那些有意义,主要有两个原因:1)Avenue数据集中异常的概念(基于可用的注释)与我们方法的目标和公式并不完全兼容,导致一些无效的真正例和假正例。2)低摄像机高度导致产生相当多的场景遮挡,从而难以正确估计运动方向,而正确估计运动方向是解决以前方法的局限性所需的。
4.7. Ablation study
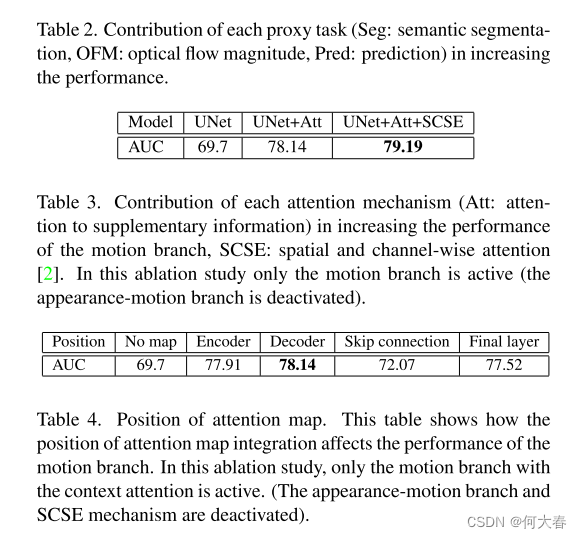
表2、表3和表4证实了每个提出的贡献在提高性能方面的有效性。正如在表2中所注意到的,所有代理任务彼此互补,组合使用时可以检测更多的异常。最重要的是,我们观察到通过将未来帧预测任务添加到我们的方法中,与仅使用OFM相比,它可以检测到更多的运动异常。
表3定量地展示了注意力机制在所提出的方法中的贡献。值得注意的是,为了集中精力研究每个注意力机制对改善运动建模和运动异常检测性能的贡献,我们只在运动分支上进行了这项消融研究。正如结果所示,向运动分支添加注意力机制会导致更高的性能。
最后,我们进行了另一项消融研究(表4)来分析注意力图的位置对运动分支性能的影响。为了集中精力研究这个因素的重要性,我们在这项研究中关闭了外观运动分支和SCSE机制。这个表格表明,在网络的任何位置(编码器、解码器、跳跃连接或最终层)添加注意力都可以提高性能。然而,与跳跃连接相比,对编码器、解码器和最终层位置观察到了更高的性能。
5. Conclusion
我们提出了一种改进的基于多任务学习的视频异常检测方法,引入了未来语义分割预测作为视频异常检测的一种新代理任务,并结合了多个互补的代理任务,以更好地考虑外观和运动异常。此外,我们引入了一种新的机制,通过关注上下文来提高运动建模的精度。实验证明,添加每个代理任务都会导致AUC方面的更高性能。重要的是,实验证明,我们提出的同时关注对象运动的方向和对象距相机的距离的思想引入了一种新的有意义的方式,以在视频异常检测中参与上下文信息,从而实现了更精确的运动估计和可能更少的误报。我们的定性结果展示了估计和检测的可解释性,以及每个贡献的有效性。在ShanghaiTech Campus和UCSD-Ped2数据集上的定量结果显示,与SOTA方法相比,我们的方法表现出更卓越的性能。
6.阅读总结
两个分支:
- 一个结合语义分割和未来帧预测,用于建模外观-运动信息
- 第二分支(即运动分支)负责学习每个正常对象及其正常运动幅度之间的对应关系,关注其与摄像机的距离、运动方向和身体部位,目的是加强对异常的运动信息分析。
感觉这篇论文的距离方向注意力还是很有意思的。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!