大数据技术在民生资金专项审计中的应用
一、应用背景
目前,针对审计行业,关于大数据技术的相关研究与应用一般包括大数据智能采集数据技术、大数据智能分析技术、大数据可视化分析技术以及大数据多数据源综合分析技术。其中,大数据智能采集数据技术是通过网络爬虫或者WebService接口实现跨部门在线数据交互;大数据的多数据源综合分析技术是目前审计领域应用大数据比较成熟和主流的内容,它是通过对采集来的各行、各业、各类大数据,采用数据查询等常用方法或其他大数据技术方法进行相关数据的综合比对和关联分析,从而可以发现更多隐藏的审计线索。本文以大数据智能采集数据技术和大数据多数据源综合分析技术为例,设计大数据审计案例。
二、方案设计
本次以失业保险基金专项审计为案例,设计大数据审计方案,由下图可以看出,大数据审计的流程是:首先广泛采集不同原始数据;原始数据存在噪声、异常值、缺失值等问题,所以需要对原始数据预处理,方便后面数据分析;接着根据业务需求,选择合适的数据分析模型,数据量大的话可以选择MySQL、oracle、SqlServer等SQL语言对数据进行查询分析,数据量小的话可以选择excel常用的内嵌函数,技术是服务项目的,能解决项目问题的技术就是好技术;最后根据数据分析结果发现审计疑点。
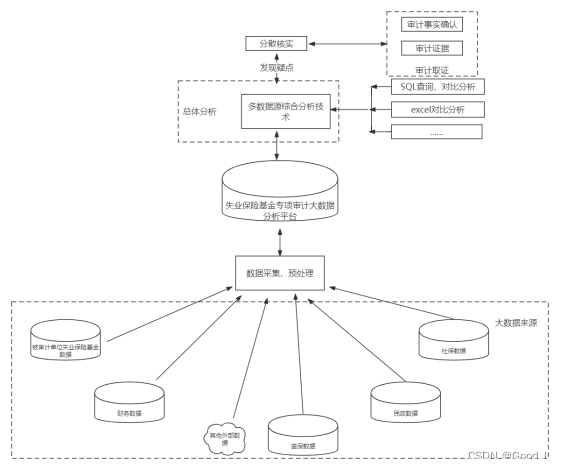
三、数据采集、预处理
在民生资金审计项目中,要根据审计实施方案明确数据采集范围。失业保险基金审计项目需要采集的数据有业务数据和外部关联数据。业务数据包含相关政策法规、公示公告信息、领取失业补助金明细表、技能提升补贴明细表等,这些数据由被审计单位提供,也可以通过网络爬虫的方式获取政策法规、公示公告等文本信息。外部关联数据包含社保缴费记录、死亡信息、移民境外数据、被判刑收监执行数据等,这些数据包含一些敏感信息,难以直接采集,有的信息需要逐条从相关信息系统查询,给大数据审计工作带来阻力。

1、网络爬虫应用背景
2、什么是网络爬虫
网络爬虫是一种自动化程序,可以从互联网上抓取数据。爬虫通过HTTP协议与互联网上的服务器进行通信,获取HTML页面或者其他格式的数据。这些数据可以用于各种用途,例如搜索引擎、数据挖掘、舆情监测等。
3、Java中的网络爬虫框架
Java中有很多优秀的网络爬虫框架,例如Jsoup、HttpClient、WebMagic等。本文将以WebMagic为例,介绍如何使用Java编写一个简单的网络爬虫程序。
4、WebMagic介绍
WebMagic是一个基于Java开发的分布式网络爬虫框架。它提供了简单易用的API接口,可以方便地进行定制化开发。WebMagic支持多线程下载和分布式处理,并且支持解析HTML、XML和JSON等多种页面格式。
5、WebMagic的基本使用
①、定义一个爬虫类,实现PageProcessor接口,并重写其process方法。②、在process方法中,编写抓取逻辑,包括解析页面、提取数据等操作。③、使用WebMagic提供的选择器(Selector)工具,可以通过CSS选择器、XPath等方式来定位页面元素。④、利用Page对象提供的方法,获取页面数据,并保存到自定义的数据结构中。⑤、在抓取逻辑完成后,将数据输出到文件、数据库或其他目标。
6、具体Java代码实现
package com.nzsjj.service;
import com.nzsjj.entity.Title;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.stereotype.Service;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.processor.PageProcessor;
import us.codecraft.webmagic.selector.Selectable;
import java.util.List;
import java.util.Random;
/**
* 功能:PageProcessor负责解析页面,抽取有用信息,以及发现新的链接
* 作者:郝xx
* 单位:xxx审计局
*/
@Service("sxsProcessor")
public class SXSProcessor implements PageProcessor {
private Logger logger = LoggerFactory.getLogger(this.getClass());
//xx县人民政府网网址
static String URL="http://www.xxx.gov.cn/xwzx/gsgg/index.shtml";
public String getURL(){
return URL;
}
//抓取网站的相关配置,包括编码、抓取间隔、重试次数等
private Site site=Site.me()
// 设置字符编码集
.setCharset("utf-8")
// 设置线程休眠时间
.setSleepTime(new Random()
.nextInt(20)*1000)
// 设置Http连接重试次数
.setRetryTimes(3);
//process是定制爬虫逻辑的核心接口,在这里编写抽取逻辑
@Override
public void process(Page page) {
String urlNum=null;
//获取页面页数
if (URL.contains("index_")){
urlNum=URL.substring(URL.indexOf("index_")+6,URL.indexOf("index_")+7);
}else {
urlNum="0";
}
logger.info("爬取南漳县人民政府网公示公告栏第"+(Integer.valueOf(urlNum)+1)+"页类容");
//解析页面内容
List<Selectable> nodes = page.getHtml().xpath("//div[@class='content-news']").nodes();
for (Selectable node:nodes
) {
//通过Xpath解析信息分析xx县人民政府网公示公告模块信息
//文章名称
String titleName = node.xpath("//h3[@class='ellipsis']/a/text()").get();
//文章的详细网址
String titleUrl=node.xpath("//a/@href").get();
//发布时间
String time=node.xpath("//span[@class='time']/text()").get();
if (titleName==null
// || !titleName.contains("技能提升补贴")
// || !titleName.contains("稳岗")
// || !titleName.contains("失业保险")
){
continue;
}
Title title = new Title();
title.setTitleName(titleName);
title.setTitleUrl(titleUrl);
title.setTime(time);
logger.info(title.toString());
}
//页数加一
Integer pageIndex=Integer.valueOf(urlNum)+1;
//停止爬虫的条件
if(pageIndex>100) return;
//替换掉url中的页数
if (URL.contains("index_")){
URL = URL.replace(URL.substring(URL.indexOf("index_"),URL.length()),"index_"+String.valueOf(pageIndex)+".shtml");
}else {
URL = URL.replace(URL.substring(URL.indexOf("index"),URL.length()),"index_"+String.valueOf(pageIndex)+".shtml");
}
//跳转下一页
page.addTargetRequest(URL);
}
/**
* 返回site对象
* site是站点配置 使用Site,me()创建site对象
* @return
*/
@Override
public Site getSite() {
return site;
}
}
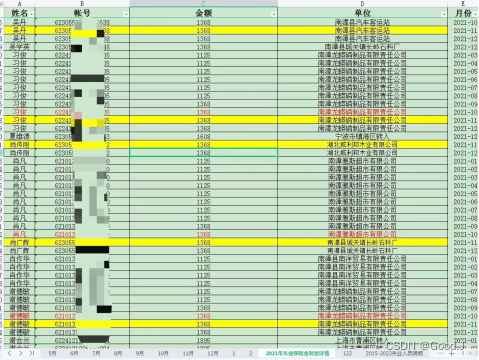
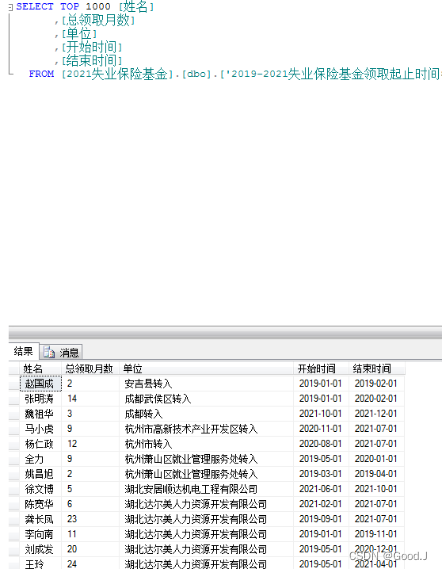
7、数据分析之前为什么要对原始数据进行预处理?
原始数据往往存在噪声、异常值、缺失值等问题,这些问题会对数据分析结果产生负面影响。通过数据预处理,可以除去噪声和异常值,填补缺失值,提高数据质量。
- 原始数据
- 预处理后的数据
四、数据分析
基于多数据源综合分析技术的失业保险基金大数据审计原理就是根据被审计单位提供的受补人员明细,与医保局、社保局、民政、公安等部门数据进行综合分析,从而发现相关审计线索,在此基础上,通过进一步的延伸取证,最终获得审计证据。其原理如图一所示,具体步骤如下:
以相关政策法规为依据 ,将领取失业保险金的人员明细与社保数据、民政数据、公安数据等关联对比分析,判断失业人员领取失业保险金补助的条件是否符合,领取补贴月数是否合规。
- SQL:
select * from 失业保险金受补明细表,社保数据
where 失业保险金受补明细表.身份证号=社保数据.身份证号
and 失业保险金受补明细表.身份证号=民政数据.身份证号
and ……
- EXCEL: vlookup函数
五、应用效果
在审计项目实施过程中,数据组成员根据大数据审计方案,采用网络爬虫方式采集非结构化数据(文本数据),爬虫能够获取全面的获取数据,提高了数据的精准性,同时节约人力和时间,大大提升了工作效率。根据项目具体实施情况,制定合适的数据分析模型,帮助审计人员快速发现审计疑点,在本次失业保险基金专项审计项目中,发现多个审计疑点,其中,苏某、赵某、王某三人在就业期间领取就业补助金,涉及金额共计27,000元。
六、应用特点
-
优点
网络爬虫采集数据快速、精准,审计人员操作简单,节省了人力、时间;制定大数据多数据源综合分析技术能够帮助审计人员快速发现审计疑点,缩小审计范围,提高了工作效率。
-
缺点
该爬虫程序访问受限。由于该程序部署在本地电脑,只有电脑开机并启动程序时审计人员才能访问该程序。其次,外围数据访问受限,不利于数据关联分析。
七、推广建议
在数据采集过程中。为了使网络爬虫技术更好的应用于审计项目中,需要计算机人员了解审计业务经常需要访问的网站,并对不同的网站进行分析设计出特有的爬虫程序,该程序可根据用户输入的网址选择特定的爬虫方式,这样就扩大了该项技术的应用范围,提高审计工作效率。
在数据应用过程中,审计部门是数据需求的主动方,数据拥有方处于被动配合的地位。想要更好的实现大数据多数据源综合分析技术,需要拥有者和使用者首先进行协商,然后由数据拥有方按照自身的责任和义务对所管理的数据进行业务功能归类,供数据需求方调用。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【推荐100个unity插件】3D物品描边效果——Quick Outline免费插件
- 指针(1)
- AcrelEMS-BP生物制药能效管理系统——安科瑞 顾烊宇
- Marin说PCB之关于1000 BASE-T1--ESD的处理知多少?
- 力扣刷题--设计链表707
- HTML生成图片
- 更便捷的访问共享盘方式 pyfilesystem
- jdk、tomcat及mysql的安装和windows项目部署
- 三、Kubernetes(K8s)入门(一)
- 【论文+在线运行】AnyText:能准确写汉字的AI绘图工具