人工智能_机器学习080_KMeans聚类算法原理和流程_KMeans损失函数_随机聚类中心_对异常值_初始值敏感---人工智能工作笔记0120
发布时间:2023年12月27日

然后我们来看一下KMeans聚类算法的原理
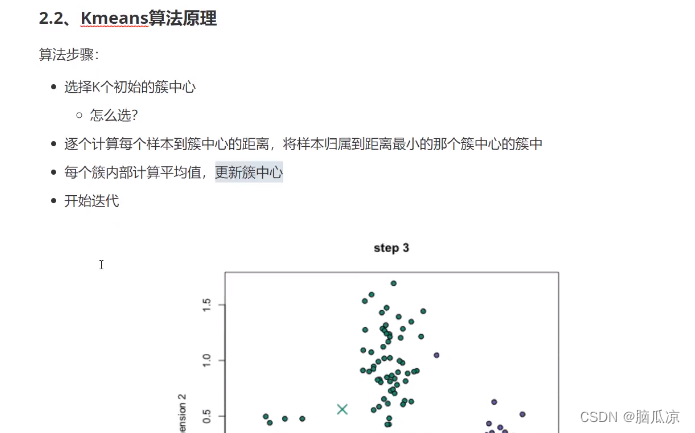
可以看到,聚类的过程是,首先1.将N个样本数据,映射到K个簇中,这个K就是我们指定的划分成几类,比如3对吧,那么
指定了K个类别以后,然后 我们再去随机指定K个,簇中心 然后再去计算,我们指定的这个簇中心,到簇中所有样本的距离的平均值,
我们得到平均值以后,再去移动这个簇中心,然后让簇中心到,这个簇中的点的距离变短,
然后移动簇中心以后,再去从新计算,这个簇中的,各个样本点到这个簇中心的距离,然后再去计算平均距离,然后再去
移动簇中心,这样迭代 最终会分开数据
上面是过程,我们看下面的解释
文章来源:https://blog.csdn.net/lidew521/article/details/135248640
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!