写个定时任务也这么多BUG?
作者简介:大家好,我是码哥,前中兴通讯、美团架构师,现某互联网公司CTO
联系qq:184480602,加我进群,大家一起学习,一起进步,一起对抗互联网寒冬
学习必须往深处挖,挖的越深,基础越扎实!
阶段1、深入多线程
阶段2、深入多线程设计模式
阶段3、深入juc源码解析
阶段4、深入jdk其余源码解析
阶段5、深入jvm源码解析
在日常开发中,相信几乎每个人都写过定时任务。即使哪一天你离职了,你的定时任务可能都还在跑着:

通常来说,定时任务有一套固定的模式:
- 循环分页 ,直到没有符合条件的数据
- 处理符合条件的每一条数据
这种固定的模式体现在代码上就是:
@Slf4j
@Component
public class XxxTask {
@Resource
private XxxService xxxService;
/**
* 任务入口
*/
@XxlJob("xxxTask")
public void handle() {
// 时间条件 [当前时间, 当前时间+N分钟]
final DateTime notifyStart = xxx;
final DateTime notifyEnd = xxx;
// 分页条件
final int pageSize = 200;
int pageNo = 1;
while (true) {
// 分页获取符合条件的数据
List<XxxDO> list = this.xxxService.lambdaQuery()
.ge(XxxDO::getStartTime, notifyStart) // 条件:某个时间范围内、状态为 已发布 的数据
.le(XxxDO::getStartTime, notifyEnd)
.eq(XxxDO::getStatus, PUBLISHED.getStatus())
.page(new Page<>(pageNo, pageSize, false))
.getRecords();
if (CollectionUtils.isEmpty(list)) {
XxlJobHelper.log("task is done, ends at pageNo:{}", pageNo);
break;
}
for (XxxDO pojo : list) {
// 处理数据
this.processPageData(pojo);
}
// 下一轮
pageNo++;
XxlJobHelper.log("next round, pageNo:{}", pageNo);
}
}
}你会发现,上面的代码逻辑是很套路化的:按某种条件对数据库的某张表进行分页查询,然后处理数据,最后pageNo++进行下一轮数据处理,直到本次任务结束。
然而,即便是如此简单的代码,也可能会出现意想不到BUG。
警惕“一边修改一边分页”
通常来说,我们的定时任务极大概率会修改分页查询得到的XxxDO(查出来却不做任何操作几乎不可能,除非当前分页是为了处理另一张表做铺垫)。而修改XxxDO时,又有很大的概率恰好会修改“条件字段”。
什么是“条件字段”?比如
select * from t_user where status=1 limit 0, 4;
如果我们的需求是查询出所有status=1的数据,把它们修改为status=0(删除),那么此时 status作为条件字段,却刚好被修改了,会出现“数据被跳过”的BUG。
待处理数据:
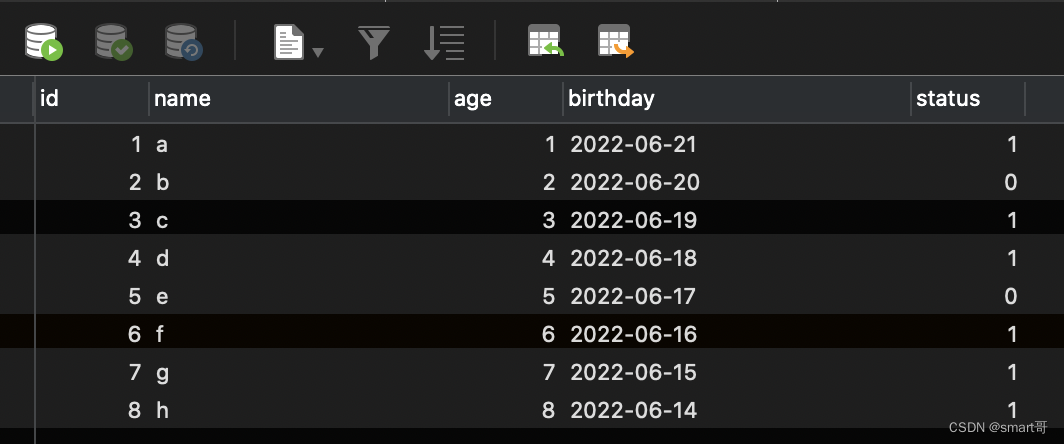
正常分页:limit 0, 4(第一页)

正常分页:limit 4, 4(第二页)

按照上面的分页套路,查询出 status=1 limit 0, 4的第一页数据,并把id为1、3、4、6的数据status更新为0:
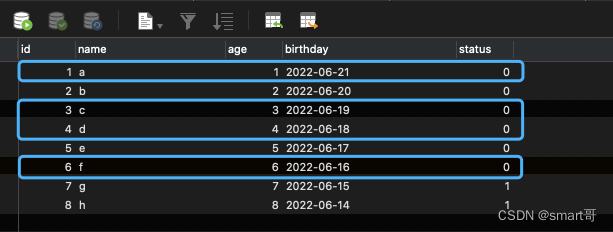
然后while(true){}会进入第二页:status=1 limit 4, 4 发现结果为空
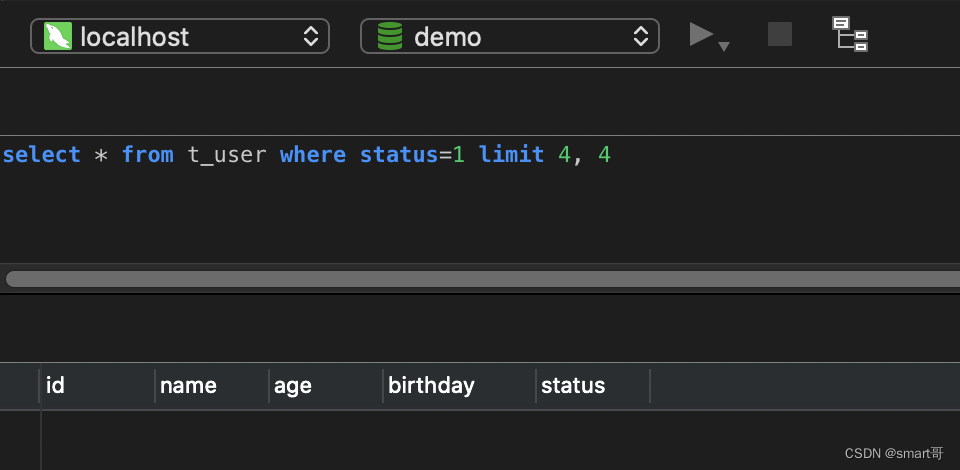
按我们的预期,应该会出现id为7、8的两条数据,但它们似乎被“跳过了”。原因很简单,对于status=1 limit 4, 4来说,由于上一次做了修改,导致原本status=1的4条数据已经变成status=0,所以id为7、8的数据前面已经没有status=1的数据了。此时我们拿着status=1 limit 4, 4做查询,实际的含义是:给我status=1、pageSize=4的第二页。现在整个表就两条status=1的数据(7和8),第1页都没满,而你居然想要第2页,当然就是空...整个定时任务结束后,会发现id为7、8的两条数据没有被处理。

解决办法很简单,就是用ID偏移查询(下一小节介绍),或者始终查询第一页:
while(true) {
// pageNo写死,永远查询第一页
List<XxxDO> list = this.page(1, pageSize);
if (CollectionUtils.isEmpty(list)) {
break;
}
// 允许随便更新条件字段
this.update(list);
}这种做法,其实就是相当于玩俄罗斯方块,上面的数据被处理了以后,下面的数据就会“上来填充”,这样我们只要一直在第一页等着就行了:
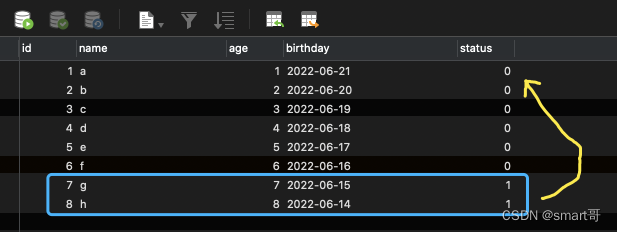
尽可能使用ID分页
我记得有一道面试是这样问的:如何保证“深分页”的性能?
什么是“深分页”?举个简单的例子,假设一张表总共2000w数据,其中 height>180 && weight>65 && city='杭州' 的共有1500w条。现在前台页面提供了一个分页,用来展示这些数据。即使pageSize=100,那么也有15w页。如果使用传统的limit offset, size,那么越往后性能会越差,这与limit分页的底层机制有关(比如 limit 10000, 10实际上会选取10010条数据然后丢弃前面1w条,返回10000~10010之间的数据)。
同理,如果定时任务要处理的数据很多,那么随着分页的不断进行,就会变成“深分页”:
while (true) {
// 分页获取符合条件的数据
List<XxxDO> list = this.xxxService.lambdaQuery()
.condition(...) // 条件:height>180 && weight>65 && city='杭州'
.page(new Page<>(pageNo, pageSize, false))
.getRecords();
if (CollectionUtils.isEmpty(list)) {
XxlJobHelper.log("task is done, ends at pageNo:{}", pageNo);
break;
}
for (XxxDO pojo : list) {
// 处理数据
this.processPageData(pojo);
}
// 下一轮
pageNo++; // 分页:总共1500w条,会出现深分页
XxlJobHelper.log("next round, pageNo:{}", pageNo);
}上面的定时任务,实际开发中的表现一般是:前面几千、几万条数据很快,大概几分钟就搞定了,但是到了10w、20w时,基本每100条要花十几秒甚至几分钟,最后任务会直接因为深分页卡死。
最简单的解决办法是:使用ID分页。
while (true) {
// 分页获取符合条件的数据
List<XxxDO> list = this.channelLiveConfIService.lambdaQuery()
.ge(XxxDO::getId, startId) // ID也作为分页条件
.condition(...) // 业务条件:height>180 && weight>65 && city='杭州'
.page(new Page<>(pageNo, pageSize, false))
.getRecords();
if (CollectionUtils.isEmpty(list)) {
XxlJobHelper.log("task is done, task id ends at:{}", startId);
break;
}
for (XxxDO pojo : list) {
// 处理数据
this.processPageData(pojo);
}
// 下一轮
startId = list.get(list.size() - 1).getId() + 1;
XxlJobHelper.log("task next round, startId:{}", startId);
}使用ID作为分页的条件时,MySQL在筛选数据时会直接跳到startId所在行,然后往后“数符合条件”的pageSize条数据,而下一轮的startId为上一轮筛选结果的最后一条dataId+1。

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【lesson18】MySQL内置函数(1)日期函数和字符串函数
- matlab抽取与插值
- MyBatis第四课动态SQL
- Matlab实现SMA-KELM| 黏菌优化算法优化核极限学习机分类预测
- 【并发】AtomicInteger很安全
- Spring Cloud Alibaba nacos配置中心
- 记redis5.x在windows上搭建集群(六主六从)
- 数模学习day01-层次分析法模型
- 生产环境的jenkins版本升级
- Matlab实现SMA-KELM| 黏菌优化算法优化核极限学习机分类预测