2023.12.11 关于 MySQL 索引详解
发布时间:2023年12月17日
目录
基本概念
- MySQL 的索引是一种用于提高数据库检索效率的数据结构
- 类似于书籍的目录,可以帮助数据库系统快速定位并访问特定数据行
- 索引可以应用在数据库表的一个或多个列上,以加快查询和排序操作
总结:
- 本质上就是缩小扫描范围,以避免全表扫描,可以加快查找效率
- 进行数据库操作无非就是增、删、改、查
- 但是在多数场景中,查 的概率比 增、删、改 要多得多
- 所以在多数情况下,引入索引还是十分有必要的
负面影响:
- 索引提高查找效率的同时 也提高了 增、删、改的开销(此时进行增、删、改,就需要调整已经创建好的索引目录)
- 索引还提高了空间的开销(构造索引,需要额外的硬盘空间来保存)
建议:
- 不要随意添加索引,因为索引也是需要维护的
- 太多的花反而会降低系统的性能
- 建议通过主键查询,通过 unique 约束的字段进行查询,效率较高
操作索引?
- 创建一个 user 表
查看索引
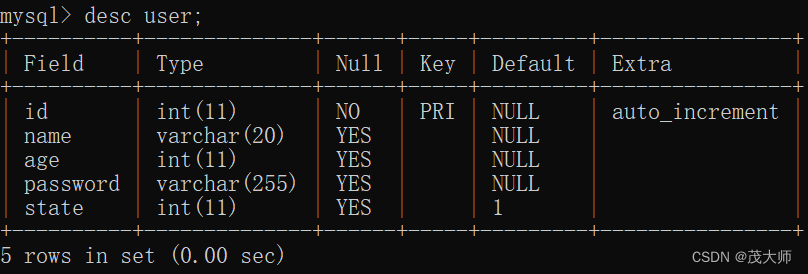
show index from user;
- 此处 user 表中的 id 字段为自增主键
- 所以 MySQL 数据库为 id 字段自动创建索引
创建索引
- 此处我们给 user 表中的? name 字段创建索引,起名为 name_index
create index name_index on user(name);
- 查看我们刚创建的 name_index 索引
注意:
- 创建索引,最好是在表创建之初就把索引给搞好
- 否则如果针对一个表中已经有很多很多记录的表,来创建索引,是一个很危险的操作
- 因为这个时候会吃掉大量的磁盘 IO,花很长的时间(看数据量,几十分钟到几个小时)
- 在这段时间里,数据库是无法被正常使用的
- 在最开始涉及数据库的时候,即创建表的时候,就要规划好给哪些字段创建索引
删除索引
- 此处我们将 user 表中的 name_index 索引删除
drop index name_index on user;
- 查看 user 表中的全部索引,发现 name_index 索引已删除


?索引的数据结构
- 索引的主要目的是为了加快查找速率
哈希表
- 哈希表的时间复杂度为 O(1)
- 但是哈希表并不适合用作数据库的索引
- 因为哈希表只能比较相等,无法进行范围查询
二叉搜索树
- 二叉搜索树的时间复杂度为 O(n)
- 时间复杂度考虑的是最坏情况,即单枝树,相当于一个链表
- 即使?二叉平衡树(AVL 树)、红黑树? 的时间复杂度为 O(logN),也并不适合用作数据库的索引
- 虽然可以进行范围查询
- 首先因为在删除或新增元素的时候 AVL 树或 红黑树 是要不断进行调整
- 其次二叉意味着当元素个数多了的时候,树的高度就会比较高,而树的高度就决定了查询的时候元素的比较次数
- 而数据库进行比较的时候都是要读取硬盘的,效率比较低
B 树
- 每个节点上有多个值,同时有多个分叉,能够有效降低树的高度
如下图所示:
- 比较次数虽然没怎么减少,第一个节点上可能需要比较多次
- 但是读写硬盘的次数减少了(每个节点都是在硬盘上的)
- B 树 相对于二叉搜索树更适合做数据库索引
- 但是针对 索引这个场景,还是量身定做了一个 B+ 树的数据结构
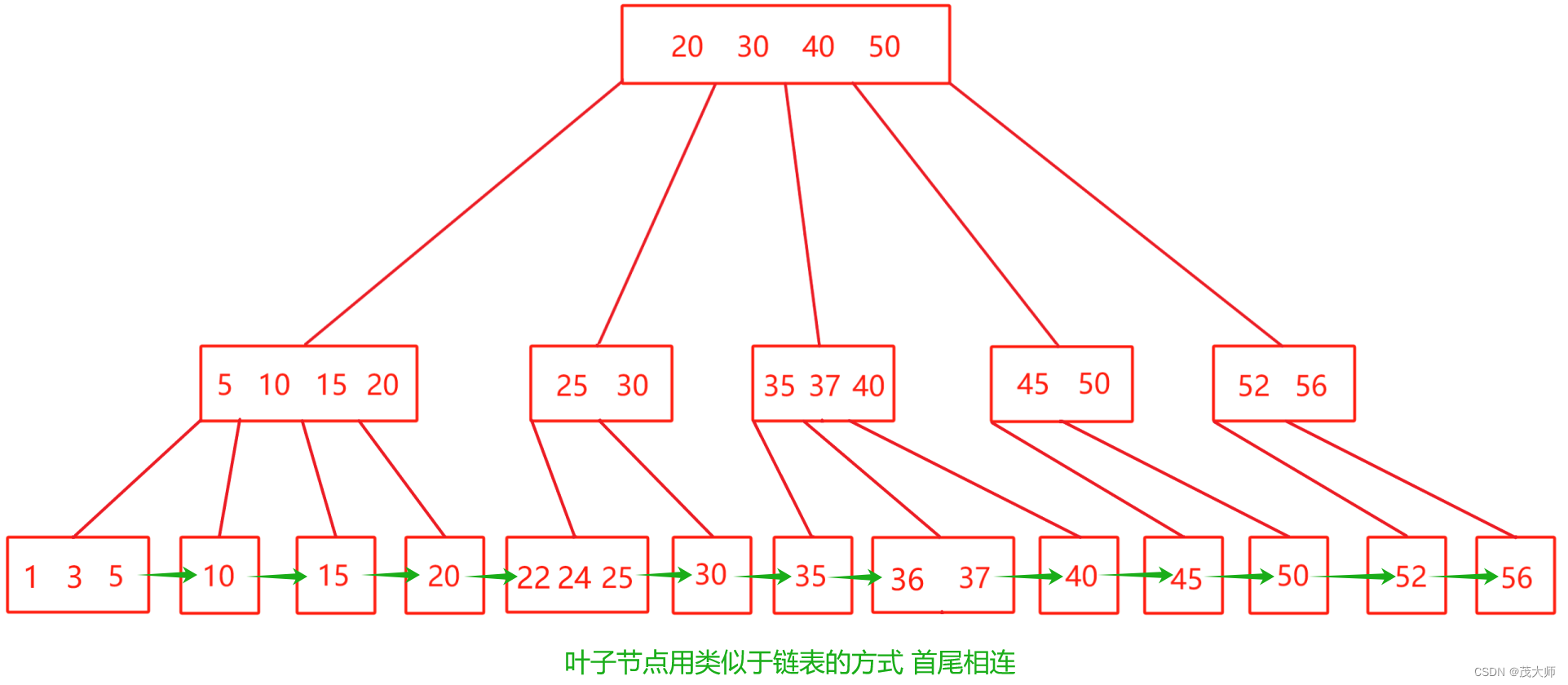
B+ 树
- B+ 树也是一种 N叉搜索树,每个节点上可能包含 N个 key
- N个 key 划分出 N个区间,最后一个? key 为所在区间的最大值
- 父元素的 key 会在子元素中重复出现,并且是以最大值出现的
- 这样的重复出现,导致叶子节点就包含了所有数据的全集,即?非叶子节点上的所有值都会在叶子节点中体现出来
- 会把叶子节点用类似于链表的方式,首尾相连
优势:
- 作为 N叉树搜索树,能有效降低高度,在比较的时候,减少了读写硬盘的次数(同B 树)
- 更适合范围查询
- 所有的查询都要落在叶子节点,无论查询哪个元素,中间比较的次数都差不多,查询操作比较均衡
- 对于 B树 来说,可能有的值查的快,有值的查的慢,十分不均衡了,即在根节点,或者深度不深的位置,查的快,而对于 B+树,大家都是一样的速度
- 由于 所有的 key 都会在叶子节点中体现,因此非叶子节点,不必存表的真实记录(数据行),数据库里的一条记录,是一行(有很多列,甚至几十列)
- 只需要把所有的数据行给放到叶子节点上即可,非叶子节点只需要存索引列的值(比如存个 id)
- 由于非叶子节点只存了简单 id 值,没有存整个数据行
- 因此大大降低了?非叶子节点 所占用的空间
- 由于非叶子节点的大小较小,相对于整个数据行而言,可以在内存中缓存更多的非叶子节点
- 提高查询速度,本质上就是在减少 读写硬盘的次数
注意:
- 有的表不只是主键索引,别的非主键列也有可能有索引
- 这个情况会构造另一个 B+ 树
- 该 B+ 树非叶子节点中存的都是这一列的Key (比如学生姓名)
- 到了叶子节点这层,不是像主键列的索引一样 存完整的数据行,而是存 主键 id
总结:
- 使用主键列查询,只需查一次 B+ 树即可
- 如果使用非主键列索引查询,则需要先查一遍索引列的 B+ 树,再查一遍主键列的 B+ 树(回表)
- 当前 B+ 树这个结构,只是针对 MySQL 的InnoDB 这个数据库引擎,里面所典型使用的数据结构
- 不同的数据库,不同的引擎,里面的存储数据的结构可能还存在差异


?
文章来源:https://blog.csdn.net/weixin_63888301/article/details/134946733
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- C++ //练习 1.25 借助网站上的Sales_item.h头文件,编译并运行本节给出的书店程序。
- MFC一次性开多个线程的简单示例
- 数据库备份与远程管理
- C++&数据结构——部分OJ题详解
- 用过都说好!这5个免费PPT模板下载网站千万不要错过!
- React中简单实现路由守卫(主要演示其原理)
- MySQL经典面试题
- 华为发布的工业软件三大难题: 面向装配场景,10万+零件的超大规模几何约束系统的求解问题
- SWUST OJ 15高精度加法
- PTGui Pro for Mac免费下载:打造完美全景照片的首选软件