图片速览 PoseGPT:基于量化的 3D 人体运动生成和预测(VQVAE)
| paper | code |
|---|---|
| https://arxiv.org/pdf/2210.10542.pdf | https://europe.naverlabs.com/research/computer-vision/posegpt/ |
方法 将动作压缩到离散空间。使用GPT类的模型预测未来动作的离散索引。使用解码器解码动作得到输出。
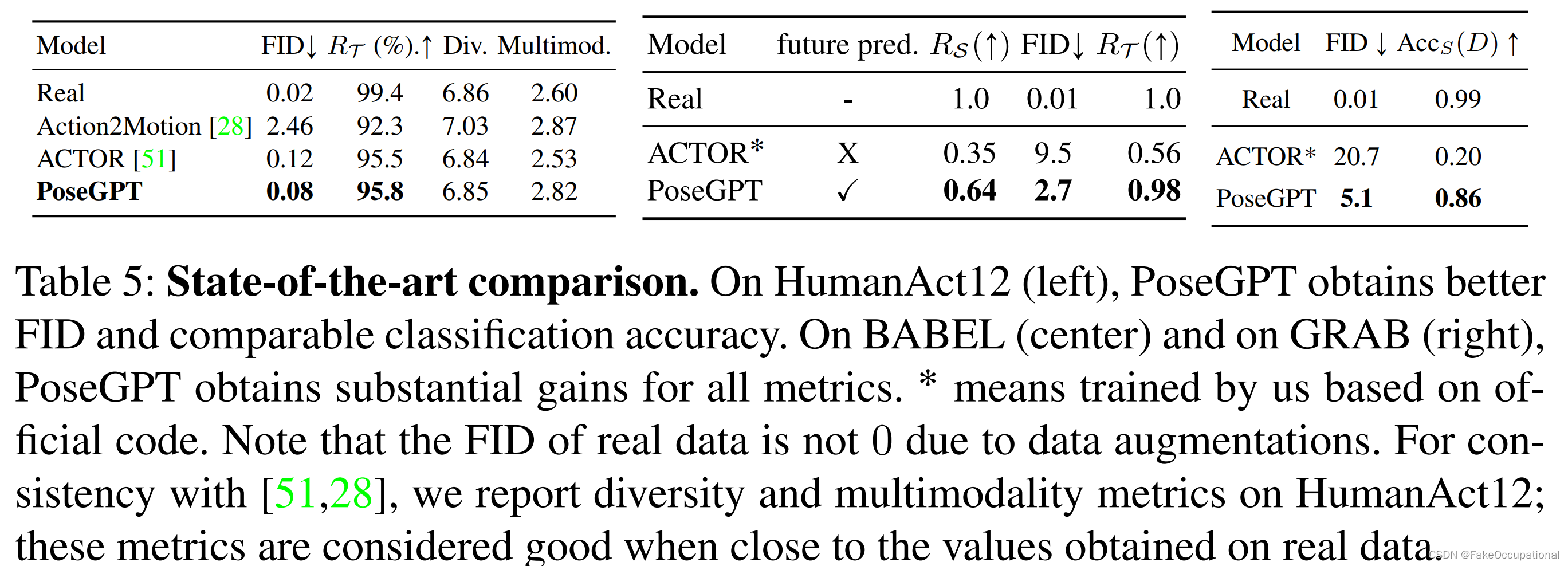
效果 提出的方法在HumanAct12(一个标准但小规模的数据集)以及BABEL(最近的大规模MoCap数据集)和GRAB(人-物体交互数据集)上取得了最先进的结果。
方法总览
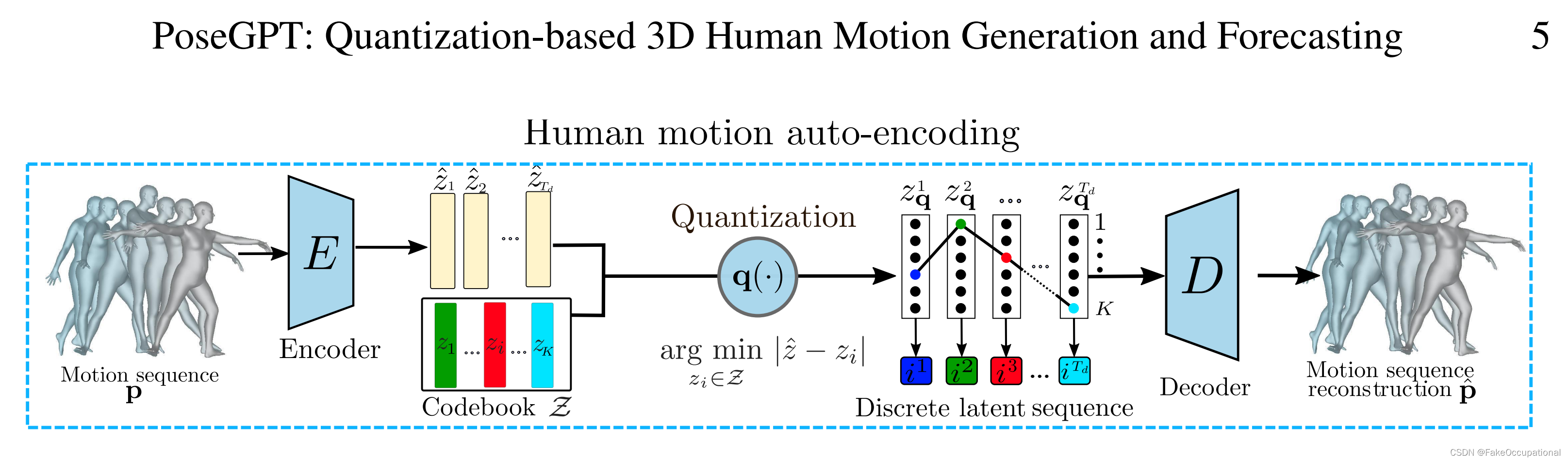
????????PoseGPT 生成一个人体运动序列,以动作标签、持续时间 T T T 为条件(观察到的过去人类运动为可选条件)。类似GPT[54]的模型G按顺序预测离散的潜在指数,这些指数使用解码器D解码为生成的人体运动。当也对过去的人体运动进行调节时,输入的人体运动用 E 编码,并使用 q ( ? ) q(\cdot) q(?) 量化到离散潜在空间中。

实现细节
VQVAE
????????潜在空间的离散性和压缩性使类似 GPT 的模型能够专注于长距离信号,因为它消除了输入信号中的低级冗余。编码器 E 将人体运动 p 映射到潜在表示
z
^
\hat z
z^,然后使用码本
Z
\mathcal Z
Z 对其进行量化。解码器 D 从量化的潜在序列
z
q
z_q
zq? 重建人体运动
p
^
\hat p
p^?。
Attention
????????屏蔽注意力图 :在编码器中屏蔽注意力图会导致模型可以根据过去的观察结果进行调节。在解码器中屏蔽注意力图也允许模型进行在线预测。
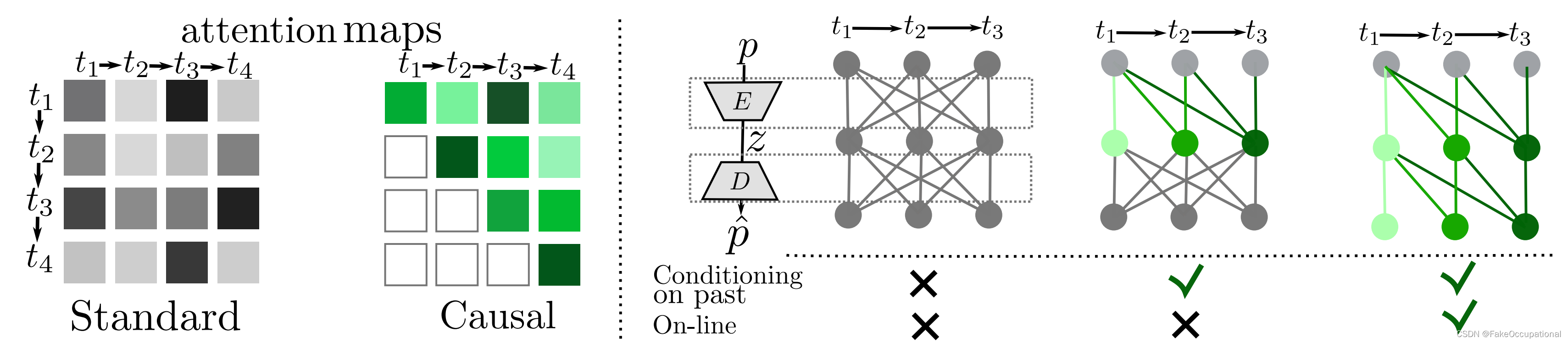
未来运动预测
????????在离散潜在空间中,自回归转换器模型 G 根据前一个潜在指数预测下一个潜在指数。我们以人体动作标签、序列持续时间和观察到的运动为条件。

结果
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- python学习笔记2(环境、职业方向、执行方式)
- 推荐系统模型(一) DFN 详解 Deep Feedback Network for Recommendation
- 使用C#如何监控选定文件夹中文件的变动情况?
- redis.conf配置文件常用配置项详解
- IspSrver-DNS
- 优化改进YOLOv5算法之AKConv(可改变核卷积),即插即用的卷积,效果秒杀DSConv
- 微服务实战系列之Filter
- c++ 字符串初始化和赋值
- 【华为OD机试真题2023C&D卷 JAVA&JS】高效货运
- 2024.1.14